
 テクノロジー周辺機器AIAIの発展は70年後の統一をもたらすのか? Ma Yi、Cao Ying、Shen Xiangyang の最新 AI レビュー: 知能生成の基本原理と「標準モデル」を探る
テクノロジー周辺機器AIAIの発展は70年後の統一をもたらすのか? Ma Yi、Cao Ying、Shen Xiangyang の最新 AI レビュー: 知能生成の基本原理と「標準モデル」を探るAIの発展は70年後の統一をもたらすのか? Ma Yi、Cao Ying、Shen Xiangyang の最新 AI レビュー: 知能生成の基本原理と「標準モデル」を探る

人工知能は 70 年にわたって発展しており、テクニカル指標は常に更新されていますが、「知能」とは一体何なのか、またそれがどのように出現し、発展していくのかについては未だに答えがありません。
最近、マー・イー教授は、コンピューター科学者のシェン・シャンヤン博士および神経科学者の曹英教授と協力して、知能の出現と発達に関する研究レビューを発表し、研究を理論的に解明したいと考えています。統合して人工知能モデルの理解と解釈可能性を向上させます。

論文リンク: http://arxiv.org/abs/2207.04630
で紹介されました。記事 2 つの基本原則: 倹約と自己一貫性。
著者は、これが人工的であれ自然的であれ、知性の台頭の基礎であると信じています。古典文献にはこれら 2 つの原則のそれぞれについて数多くの議論と詳細が記載されていますが、この記事ではこれら 2 つの原則を完全に測定可能かつ計算可能な方法で再解釈します。
これらの 2 つの最初の原則に基づいて、著者らは効率的な計算フレームワーク、つまり現代の深層ネットワークと多くの人工知能の実践を統合し説明する圧縮閉ループ転写を導き出します。
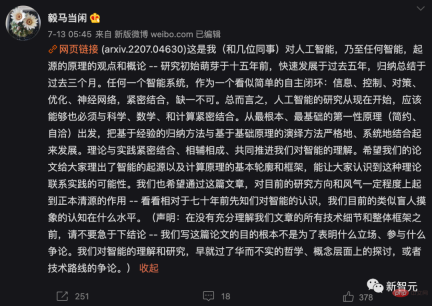
- 何を学ぶべきか: データから何を学ぶべきか、そして学習の質をどのように測定するか?
- 学習方法: 効率的かつ効果的なコンピューティング フレームワークを通じて、このような学習目標を達成するにはどうすればよいでしょうか?
「何を学ぶか」という最初の質問については、単純性の原則により次のようになります。
学生の学習目標インテリジェントシステムとは、外界の観測データから低次元構造を発見し、それらを最もコンパクトかつ構造化された方法で再編成して表現することから学びます。 これは「オッカムの剃刀」の原則です。必要な場合以外はエンティティを追加しないでください。この原則がなければ、インテリジェンスは不可能です。外界の観測データが低次元構造を持たない場合、学習や記憶に値するものは何もなく、良好な一般化や予測は不可能です。
また、インテリジェントシステムでは、エネルギー、空間、時間、材料などの資源をできる限り節約する必要があり、この原理は「圧縮原理」と呼ばれることもあります。ただし、インテリジェンスの節約は、最適な圧縮を達成することではなく、効率的な計算手段を通じて観測データの最もコンパクトで構造化された表現を取得することです。
では、シンプルさを測定するにはどうすればよいでしょうか?
一般的な高次元モデルの場合、一般的に使用される多くの数学的または統計的な「尺度」の計算コストは指数関数的であり、低次元構造のデータ分布の場合も同様です。最尤法、KL ダイバージェンス、相互情報量、ジェンセン・シャノン距離、ワッサーシュタイン距離など。
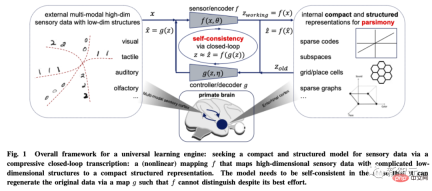
著者は、学習の目的は実際には、元の高次元入力から低次元表現を取得するためのマッピング (通常は非線形) を確立することであると考えています。

この目的のために、著者は 3 つのサブ目標を達成するために線形判別表現 (LDR) を導入します。 圧縮: 高次元の感覚データ x を低次元表現 z にマッピングします;
線形化: 非線形サブサーフェスに分布する各タイプのオブジェクトを線形部分空間にマッピングします; スパース化:異なるカテゴリを相互に独立した、または関連性の低い部分空間にマッピングします。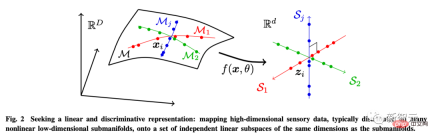
「学習方法」という 2 番目の質問については、自己一貫性の原則により次のようになります。 
自律型インテリジェント システムは、観察されたデータと再生成されたデータの内部表現の差異を最小限に抑えることにより、外界の観察に対して最も自己矛盾のないモデルを模索します。
倹約の原則だけでは、学習されたモデルが外界のデータに関するすべての重要な情報を確実に捕捉できるわけではありません。たとえば、クロスエントロピーを最小限に抑えて各カテゴリを 1 次元のワンホット ベクトルにマッピングすることは、倹約の一形態とみなすことができます。
優れた分類器を学習する可能性がありますが、学習された特徴がシングルトンに崩壊する可能性もあります (ニューラル崩壊とも呼ばれます)。このような学習された特徴には、元のデータを再生成するのに十分な情報が含まれなくなります。
より一般的な LDR モデルを考慮したとしても、コーディング レートの差を最大化するだけでは、環境特徴空間の正しい次元を自動的に決定することはできません。
特徴空間の次元が低すぎる場合、学習されたモデルはデータと一致せず、高すぎる場合、モデルが過剰に一致する可能性があります。
より一般的には、知覚学習は特定のタスクの学習とは異なると主張します。知覚の目標は、何が知覚されているかについて予測可能なすべてを学習することです。
アインシュタインはかつてこう言いました:「物事はシンプルに保つべきですが、シンプルすぎてもいけません。」
ユニバーサル学習エンジン
これら 2 つの原則に基づいて、この記事では、例として視覚画像データ モデリングを使用して、圧縮閉ループ転写フレームワークを導き出します。
非線形データ サブフロー パターンの圧縮閉ループ転写を内部で実行し、内部表現の違いを比較して最小限に抑えることで LDR を実現します。
エンコーダー/センサーとデコーダー/コントローラー間のチェイス アンド フライト ゲームにより、デコードされた表現によって生成されたデータの分布を追跡し、観察された実際のデータ分布と一致させることができます。
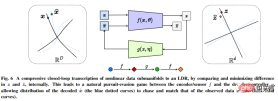
さらに、著者は、圧縮された閉ループ転写が増分学習を効果的に実行できることを指摘しました。
新しいデータ クラスの LDR モデルは、エンコーダーとデコーダーの間の制約付きゲームを通じて学習できます。過去に学習したクラスの記憶は自然に学習でき、制約として保持されます。ゲーム、つまり、閉ループ転写の「固定点」として。
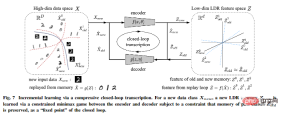
この記事では、このフレームワークの普遍性についてさらに推測的なアイデアを提案し、それを 3 つの次元に拡張します。強化学習、およびその神経科学、数学、高度な知能への影響の予測。


以上がAIの発展は70年後の統一をもたらすのか? Ma Yi、Cao Ying、Shen Xiangyang の最新 AI レビュー: 知能生成の基本原理と「標準モデル」を探るの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Gemma Scope:AI'の思考プロセスを覗くためのGoogle'の顕微鏡Apr 17, 2025 am 11:55 AM
Gemma Scope:AI'の思考プロセスを覗くためのGoogle'の顕微鏡Apr 17, 2025 am 11:55 AMジェマの範囲で言語モデルの内部の仕組みを探る AI言語モデルの複雑さを理解することは、重要な課題です。 包括的なツールキットであるGemma ScopeのGoogleのリリースは、研究者に掘り下げる強力な方法を提供します
 ビジネスインテリジェンスアナリストは誰で、どのようになるか?Apr 17, 2025 am 11:44 AM
ビジネスインテリジェンスアナリストは誰で、どのようになるか?Apr 17, 2025 am 11:44 AMビジネスの成功のロック解除:ビジネスインテリジェンスアナリストになるためのガイド 生データを組織の成長を促進する実用的な洞察に変換することを想像してください。 これはビジネスインテリジェンス(BI)アナリストの力です - GUにおける重要な役割
 SQLに列を追加する方法は? - 分析VidhyaApr 17, 2025 am 11:43 AM
SQLに列を追加する方法は? - 分析VidhyaApr 17, 2025 am 11:43 AMSQLの変更テーブルステートメント:データベースに列を動的に追加する データ管理では、SQLの適応性が重要です。 その場でデータベース構造を調整する必要がありますか? Alter Tableステートメントはあなたの解決策です。このガイドの詳細は、コルを追加します
 ビジネスアナリストとデータアナリストApr 17, 2025 am 11:38 AM
ビジネスアナリストとデータアナリストApr 17, 2025 am 11:38 AM導入 2人の専門家が重要なプロジェクトで協力している賑やかなオフィスを想像してください。 ビジネスアナリストは、会社の目標に焦点を当て、改善の分野を特定し、市場動向との戦略的整合を確保しています。 シム
 ExcelのCountとCountaとは何ですか? - 分析VidhyaApr 17, 2025 am 11:34 AM
ExcelのCountとCountaとは何ですか? - 分析VidhyaApr 17, 2025 am 11:34 AMExcelデータカウントと分析:カウントとカウントの機能の詳細な説明 特に大規模なデータセットを使用する場合、Excelでは、正確なデータカウントと分析が重要です。 Excelは、これを達成するためにさまざまな機能を提供し、CountおよびCounta関数は、さまざまな条件下でセルの数をカウントするための重要なツールです。両方の機能はセルをカウントするために使用されますが、設計ターゲットは異なるデータ型をターゲットにしています。 CountおよびCounta機能の特定の詳細を掘り下げ、独自の機能と違いを強調し、データ分析に適用する方法を学びましょう。 キーポイントの概要 カウントとcouを理解します
 ChromeはAIと一緒にここにいます:毎日何か新しいことを体験してください!!Apr 17, 2025 am 11:29 AM
ChromeはAIと一緒にここにいます:毎日何か新しいことを体験してください!!Apr 17, 2025 am 11:29 AMGoogle Chrome'sAI Revolution:パーソナライズされた効率的なブラウジングエクスペリエンス 人工知能(AI)は私たちの日常生活を急速に変換しており、Google ChromeはWebブラウジングアリーナで料金をリードしています。 この記事では、興奮を探ります
 ai' s Human Side:Wellbeing and the Quadruple bottuntApr 17, 2025 am 11:28 AM
ai' s Human Side:Wellbeing and the Quadruple bottuntApr 17, 2025 am 11:28 AMインパクトの再考:四重材のボトムライン 長い間、会話はAIの影響の狭い見方に支配されており、主に利益の最終ラインに焦点を当てています。ただし、より全体的なアプローチは、BUの相互接続性を認識しています
 5ゲームを変える量子コンピューティングの使用ケースあなたが知っておくべきであるApr 17, 2025 am 11:24 AM
5ゲームを変える量子コンピューティングの使用ケースあなたが知っておくべきであるApr 17, 2025 am 11:24 AM物事はその点に向かって着実に動いています。量子サービスプロバイダーとスタートアップに投資する投資は、業界がその重要性を理解していることを示しています。そして、その価値を示すために、現実世界のユースケースの数が増えています


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

Dreamweaver Mac版
ビジュアル Web 開発ツール

