
ホームページ >テクノロジー周辺機器 >AI >TabTransformer コンバーターにより、多層パーセプトロンのパフォーマンスの詳細な分析が向上
TabTransformer コンバーターにより、多層パーセプトロンのパフォーマンスの詳細な分析が向上

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-17 15:25:031870ブラウズ
現在、Transformers は、最先端の自然言語処理 (NLP) およびコンピューター ビジョン (CV) アーキテクチャの主要なモジュールです。ただし、表形式データの分野では、依然として勾配ブースト決定木 (GBDT) アルゴリズムが主流です。そこで、このギャップを埋める試みが行われました。その中で、最初のコンバーターベースの表形式データモデリングの論文は、2020年にHuangらによって出版された論文「TabTransformer: Tabular Data Modeling using Context Embedding」です。
この記事は、論文の内容の基本的な表示を提供するとともに、TabTransformer モデルの実装の詳細を掘り下げ、特に独自のデータに TabTransformer を使用する方法を示すことを目的としています。 。
1. 論文の概要
上記の論文の主な考え方は、コンバータを使用して従来の分類埋め込みをコンテキスト埋め込みに変換すると、従来のマルチ-層の認識 プロセッサー (MLP) のパフォーマンスが大幅に向上します。次に、この説明をさらに深く理解してみましょう。
1. カテゴリカル埋め込み
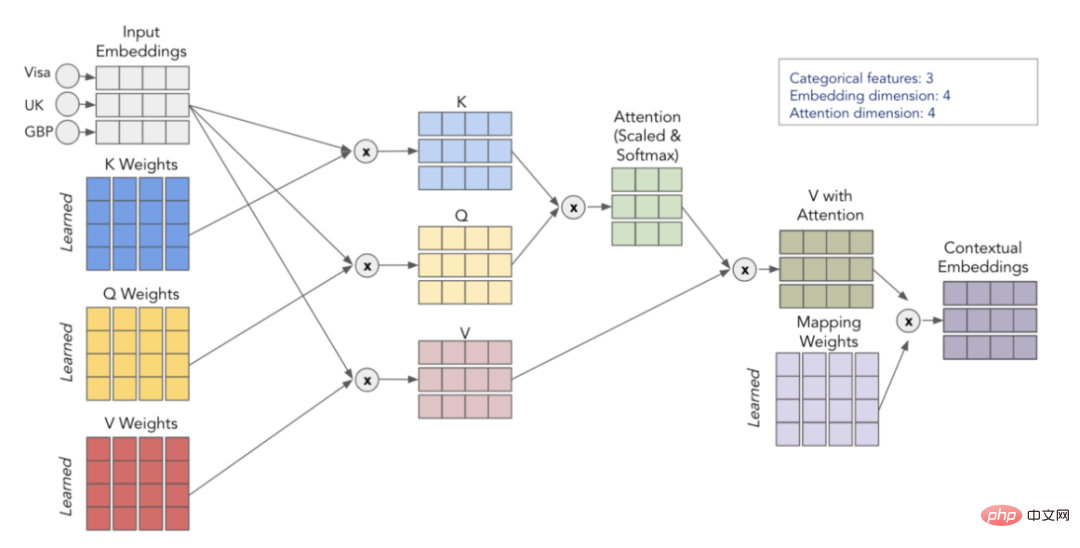
深層学習モデルでカテゴリ特徴量を使用する古典的な方法は、その埋め込みをトレーニングすることです。これは、各カテゴリ値が固有の密ベクトル表現を持ち、次の層に渡すことができることを意味します。たとえば、以下の画像から、各カテゴリ特徴量が 4 次元配列で表されていることがわかります。これらの埋め込みは数値特徴と連結され、MLP への入力として使用されます。
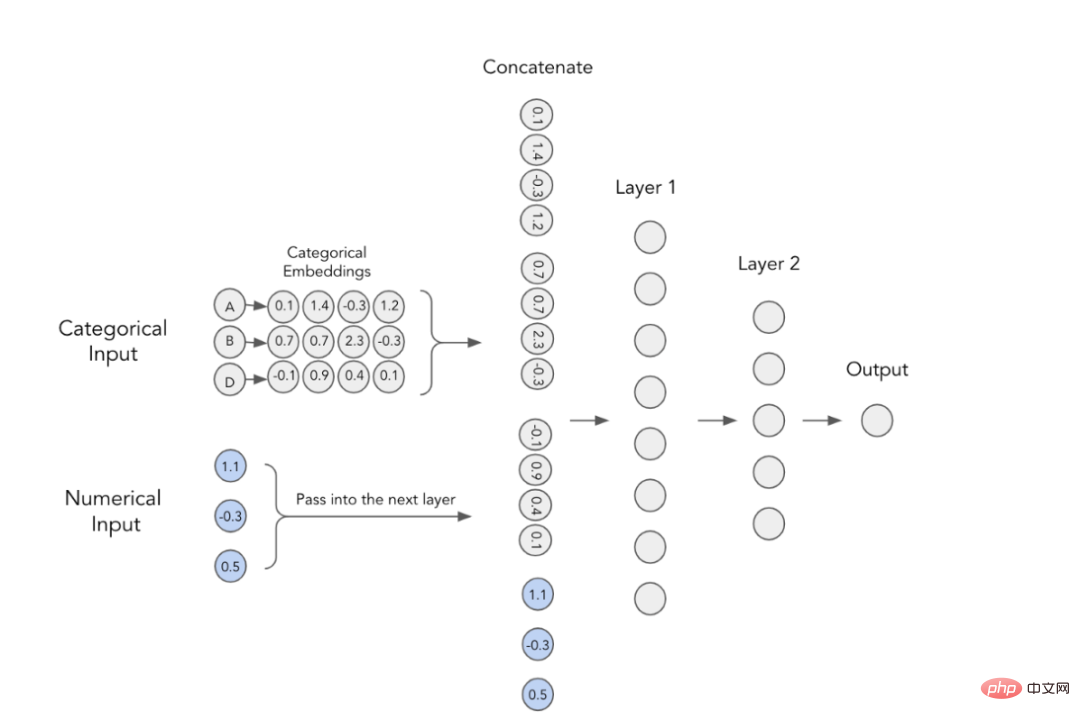
論文の著者らは、カテゴリカル埋め込みには文脈上の意味が欠けており、カテゴリ変数間の相互作用や関係情報はエンコードされていないと考えています。埋め込まれたコンテンツをより具体的にするために、現在 NLP 分野で使用されている変換器をこの目的に使用することが提案されています。
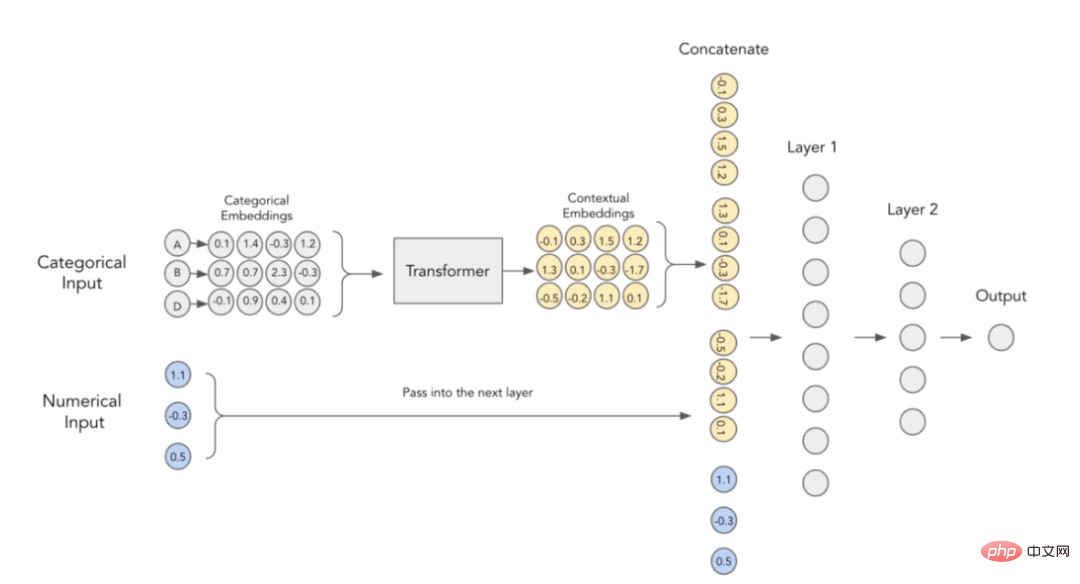
#3.TabTransformer アーキテクチャ
上記の目的を達成するために、論文の著者は次のアーキテクチャを提案しました。
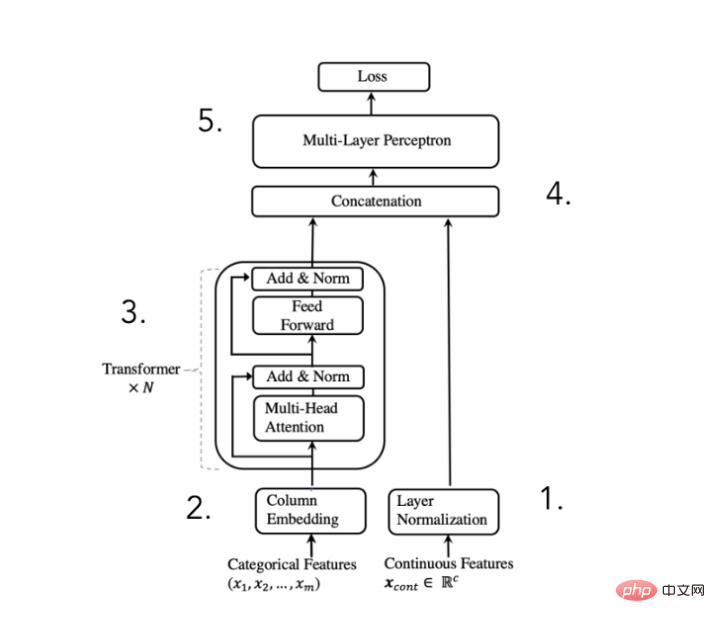 TabTransformer コンバーターのアーキテクチャ図
TabTransformer コンバーターのアーキテクチャ図
#(2020 年に Huang らによって発表された論文からの抜粋)
私たちはできる このアーキテクチャは 5 つのステップに分かれています:
数値特徴を標準化し、それらを転送する- カテゴリ特徴を埋め込む
- 埋め込みでは、コンテキスト エンベディングを取得するために Transformer ブロックの処理を N 回実行します。
- コンテキスト カテゴリカル エンベディングと数値特徴を連結します。
- MLP を介して連結して、必要な予測を取得します。
モデル アーキテクチャは非常に単純ですが、論文の著者は、コンバーター層を追加するとコンピューティング パフォーマンスを大幅に向上できると述べています。もちろん、すべての「魔法」はこれらのコンバーター ブロック内で発生するため、実装をさらに詳しく見てみましょう。
4. コンバータ
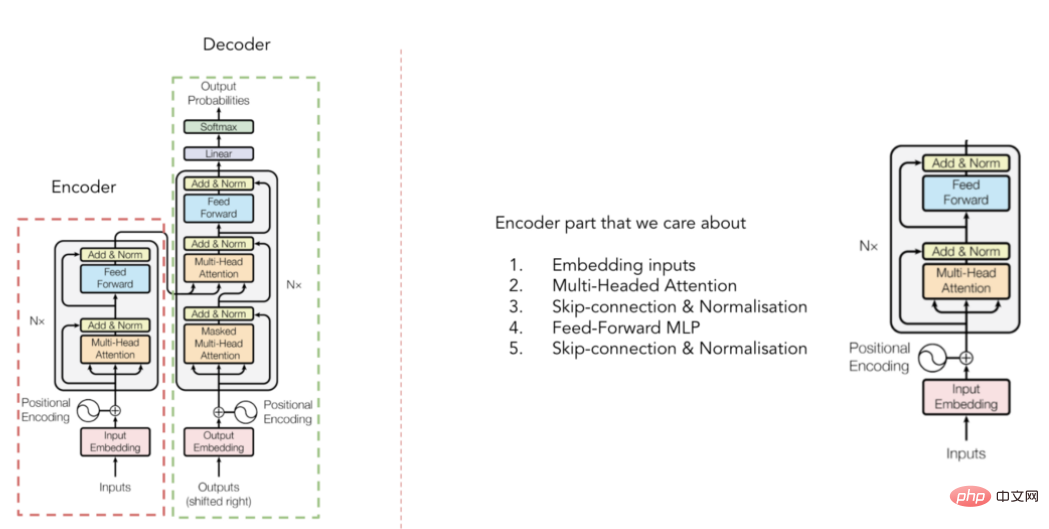 トランスのアーキテクチャ図
トランスのアーキテクチャ図
(Vaswani et al より) . 2017 論文)
コンバーターのアーキテクチャを以前に見たことがあるかもしれませんが、簡単に説明するために、コンバーターはエンコーダーで構成されていることを覚えておいてください。コンバーターは 2 つの部分で構成されています。デコーダとデコーダ(上の図を参照)。 TabTransformer の場合、入力エンベディングをコンテキスト化するエンコーダー部分のみを考慮します (デコーダー部分はこれらのエンベディングを最終出力結果に変換します)。しかし、それは具体的にどのように行われるのでしょうか?答えは、「マルチヘッド アテンション メカニズム」です。
5. マルチヘッド アテンション メカニズム
注意のメカニズムに関する私のお気に入りの記事の説明を引用すると、次のようになります:
「自己注意の背後にある重要な概念は、このメカニズムにより、ニューラル ネットワークがどのように学習するかが可能になるということです。入力シーケンスのさまざまな部分間で最適なルーティング スキームを使用して情報をスケジュールするためです。」
言い換えると、自己注意がモデルを助けます。入力のどの部分がより重要であるかを見つけます。特定の単語/カテゴリを表すときにどの部分がそれほど重要ではないか。そのために、上記で参照した記事を読んで、なぜ自己焦点が非常に効果的であるかをより直観的に理解することを強くお勧めします。
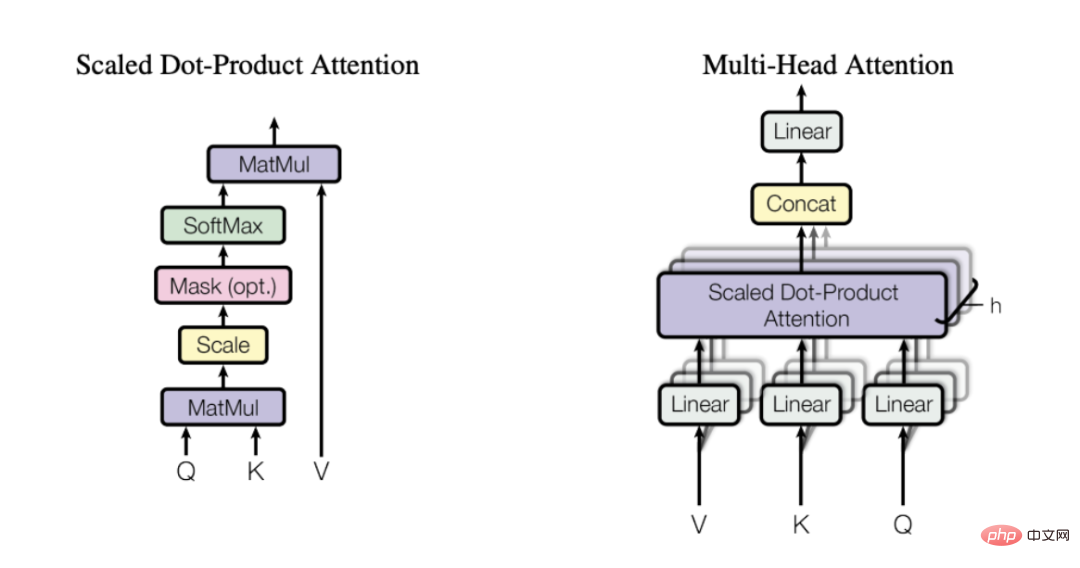
 #セルフフォーカスプロセスの可視化
#セルフフォーカスプロセスの可視化
このプロセスを h 回繰り返すことで (異なる Q を使用して、 K , V 行列)、最終的なマルチヘッド アテンションを形成する複数のコンテキストの埋め込みを取得できます。
6. 簡単なレビュー
上で紹介した内容を要約しましょう:
単純なカテゴリカル エンベディングにはコンテキスト情報は含まれません
- カテゴリカル エンベディングをトランスフォーマー エンコーダーに渡すことで、エンベディングをコンテキスト化できます
- トランスフォーマー部分はエンベディングをコンテキスト化できます。マルチヘッド アテンション メカニズムが使用されます
- マルチヘッド アテンション メカニズムは、行列 Q、K、V を使用して、変数をエンコードするときに有用な相互作用と相関情報を見つけます
- TabTransformer では、コンテキスト化されます。埋め込みは数値入力と連結され、単純な MLP 出力を通じて予測されます
TabTransformer の背後にある考え方は単純ですが、アテンション メカニズムを習得するには時間がかかる場合があります。したがって、上記の説明をもう一度読むことを強くお勧めします。少し迷った場合は、この記事内の推奨リンクをすべて読んでください。一度これを実行すれば、注意のメカニズムがどのように機能するかを理解するのは難しくないと保証します。
7. 実験結果の表示
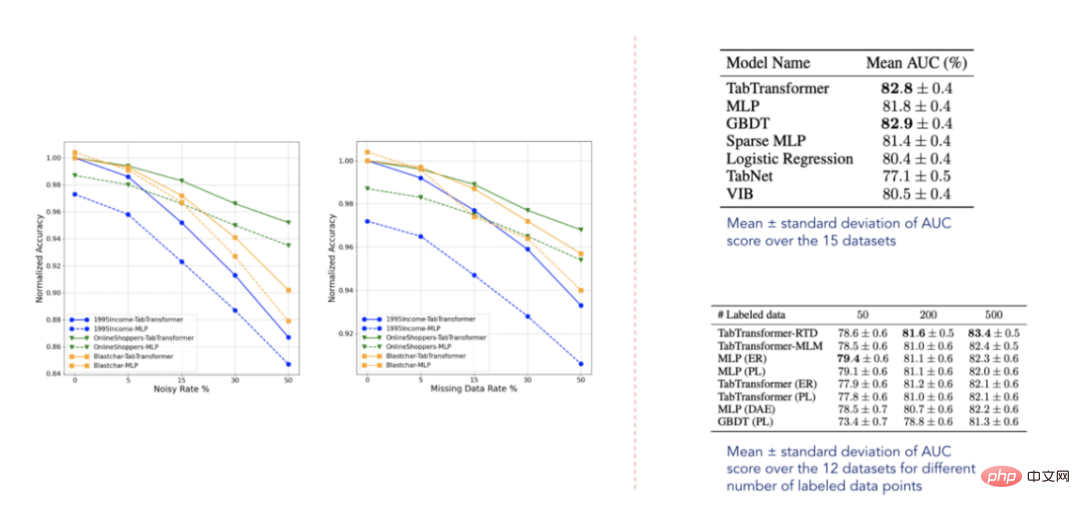 結果データ (Huang et al. 2020 Paper から選択)
結果データ (Huang et al. 2020 Paper から選択)
報告された結果によると、TabTransformer は他のすべての深層学習表形式モデルよりも優れたパフォーマンスを示し、さらに GBDT のパフォーマンス レベルに近く、非常に心強いものです。また、このモデルは欠損データやノイズの多いデータに対して比較的堅牢であり、半教師あり設定では他のモデルよりも優れています。ただし、これらのデータセットは明らかに網羅的ではなく、今後出版される多くの関連論文で確認されているように、まだ改善の余地がかなりあります。
2. 独自のサンプル プログラムを構築する
さあ、いよいよモデルを独自のデータに適用する方法を決定しましょう。次のデータ例は、有名な Tabular Playground Kaggle コンペティションから取得したものです。 TabTransformer コンバーターを使いやすくするために、tabtransformertf パッケージを作成しました。これは、
pip install tabtransformertf
のような pip コマンドを使用してインストールでき、大規模な前処理なしでモデルを使用できるようになります。
1. データの前処理
最初のステップは、適切なデータ型を設定し、トレーニング データと検証データを TF データ セットに変換することです。その中で、以前にインストールしたパッケージは、これを行うことができる優れたユーティリティを提供します。
from tabtransformertf.utils.preprocessing import df_to_dataset, build_categorical_prep # 设置数据类型 train_data[CATEGORICAL_FEATURES] = train_data[CATEGORICAL_FEATURES].astype(str) val_data[CATEGORICAL_FEATURES] = val_data[CATEGORICAL_FEATURES].astype(str) train_data[NUMERIC_FEATURES] = train_data[NUMERIC_FEATURES].astype(float) val_data[NUMERIC_FEATURES] = val_data[NUMERIC_FEATURES].astype(float) # 转换成TF数据集 train_dataset = df_to_dataset(train_data[FEATURES + [LABEL]], LABEL, batch_size=1024) val_dataset = df_to_dataset(val_data[FEATURES + [LABEL]], LABEL, shuffle=False, batch_size=1024)
次のステップは、カテゴリデータの前処理層を準備することです。このカテゴリデータは、後でメイン モデルに渡されます。
from tabtransformertf.utils.preprocessing import build_categorical_prep
category_prep_layers = build_categorical_prep(train_data, CATEGORICAL_FEATURES)
# 输出结果是一个字典结构,其中键部分是特征名称,值部分是StringLookup层
# category_prep_layers ->
# {'product_code': <keras.layers.preprocessing.string_lookup.StringLookup at 0x7f05d28ee4e0>,
#'attribute_0': <keras.layers.preprocessing.string_lookup.StringLookup at 0x7f05ca4fb908>,
#'attribute_1': <keras.layers.preprocessing.string_lookup.StringLookup at 0x7f05ca4da5f8>}
これは前処理です。これで、モデルの構築を開始できます。
2. TabTransformer モデルを構築する
モデルの初期化は簡単です。その中には、指定する必要があるパラメータがいくつかありますが、最も重要なパラメータは、embedding_dim、 Depth、heads です。すべてのパラメータはハイパーパラメータ調整後に選択されます。
from tabtransformertf.models.tabtransformer import TabTransformer tabtransformer = TabTransformer( numerical_features = NUMERIC_FEATURES,# 带有数字特征名称的列表 categorical_features = CATEGORICAL_FEATURES, # 带有分类特征名称的列表 categorical_lookup=category_prep_layers, # 带StringLookup层的Dict numerical_discretisers=None,# None代表我们只是简单地传递数字特征 embedding_dim=32,# 嵌入维数 out_dim=1,# Dimensionality of output (binary task) out_activatinotallow='sigmoid',# 输出层激活 depth=4,# 转换器块层的个数 heads=8,# 转换器块中注意力头的个数 attn_dropout=0.1,# 在转换器块中的丢弃率 ff_dropout=0.1,# 在最后MLP中的丢弃率 mlp_hidden_factors=[2, 4],# 我们为每一层划分最终嵌入的因子 use_column_embedding=True,#如果我们想使用列嵌入,设置此项为真 ) # 模型运行中摘要输出: # 总参数个数: 1,778,884 # 可训练的参数个数: 1,774,064 # 不可训练的参数个数: 4,820
モデルが初期化されたら、他の Keras モデルと同様にインストールできます。トレーニングパラメータも調整できるため、学習速度や早期停止を自由に調整できます。
LEARNING_RATE = 0.0001 WEIGHT_DECAY = 0.0001 NUM_EPOCHS = 1000 optimizer = tfa.optimizers.AdamW( learning_rate=LEARNING_RATE, weight_decay=WEIGHT_DECAY ) tabtransformer.compile( optimizer = optimizer, loss = tf.keras.losses.BinaryCrossentropy(), metrics= [tf.keras.metrics.AUC(name="PR AUC", curve='PR')], ) out_file = './tabTransformerBasic' checkpoint = ModelCheckpoint( out_file, mnotallow="val_loss", verbose=1, save_best_notallow=True, mode="min" ) early = EarlyStopping(mnotallow="val_loss", mode="min", patience=10, restore_best_weights=True) callback_list = [checkpoint, early] history = tabtransformer.fit( train_dataset, epochs=NUM_EPOCHS, validation_data=val_dataset, callbacks=callback_list )
3. 評価
コンテストで最も重要な指標は ROC AUC です。そこで、PR AUC メトリクスと一緒に出力して、モデルのパフォーマンスを評価しましょう。
val_preds = tabtransformer.predict(val_dataset)
print(f"PR AUC: {average_precision_score(val_data['isFraud'], val_preds.ravel())}")
print(f"ROC AUC: {roc_auc_score(val_data['isFraud'], val_preds.ravel())}")
# PR AUC: 0.26
# ROC AUC: 0.58您也可以自己给测试集评分,然后将结果值提交给Kaggle官方。我现在选择的这个解决方案使我跻身前35%,这并不坏,但也不太好。那么,为什么TabTransfromer在上述方案中表现不佳呢?可能有以下几个原因:
- 数据集太小,而深度学习模型以需要大量数据著称
- TabTransformer很容易在表格式数据示例领域出现过拟合
- 没有足够的分类特征使模型有用
三、结论
本文探讨了TabTransformer背后的主要思想,并展示了如何使用Tabtransformertf包来具体应用此转换器。
归纳起来看,TabTransformer的确是一种有趣的体系结构,它在当时的表现明显优于大多数深度表格模型。它的主要优点是将分类嵌入语境化,从而增强其表达能力。它使用在分类特征上的多头注意力机制来实现这一点,而这是在表格数据领域使用转换器的第一个应用实例。
TabTransformer体系结构的一个明显缺点是,数字特征被简单地传递到最终的MLP层。因此,它们没有语境化,它们的价值也没有在分类嵌入中得到解释。在下一篇文章中,我将探讨如何修复此缺陷并进一步提高性能。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文链接:https://towardsdatascience.com/transformers-for-tabular-data-tabtransformer-deep-dive-5fb2438da820?source=collection_home---------4----------------------------
以上がTabTransformer コンバーターにより、多層パーセプトロンのパフォーマンスの詳細な分析が向上の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。