
ホームページ >テクノロジー周辺機器 >AI >AI を使用して、何億人もの目の見えない人々が再び「世界を見る」ことができるようにします。
AI を使用して、何億人もの目の見えない人々が再び「世界を見る」ことができるようにします。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-16 18:37:031826ブラウズ
かつては、目の見えない人の視力を回復することは医学的な「奇跡」とみなされることが多かった。
「マシンビジョン自然言語理解」に代表されるマルチモーダルインテリジェンス技術の爆発的な進歩により、AIは失明を支援する新たな可能性をもたらし、さらに多くの失明者がその知覚を利用するようになり、 AI によって提供される理解力と対話機能により、別の方法で「世界をもう一度見る」ことができます。
AI は視覚障害者を支援し、より多くの人が再び「世界を見る」ことができるようにします
一般的に、視覚障害者とは、視覚障害者を指します。目で見る 患者が外界を認識する経路は、視覚以外の聴覚、嗅覚、触覚などであり、これらの他の感覚から得られる情報は、視覚障害者が視覚障害によって引き起こされる問題をある程度軽減するのに役立ちます。しかし、科学的な研究によると、人間が得る外部情報のうち、視覚が70%~80%も占めることがわかっています。
したがって、視覚障害のある患者が視覚的に認識し、外部環境を視覚的に理解できるようにするために、AI に基づいたマシン ビジョン システムを構築することは、間違いなく最も直接的かつ効果的なソリューションです。
視覚認識の分野では、現在のシングルモーダル AI モデルは画像認識タスクにおいて人間のレベルを超えていますが、このタイプのテクノロジーは現時点では視覚モダリティ内での認識と認識しか実現できません。理解、他の感覚情報と交差するクロスモーダルな学習、理解、推論を完了することは困難であり、簡単に言うと、知覚することはできても理解することはできません。
この目的を達成するために、コンピューテーショナル ビジョンの創設者の 1 人であるデイビッド マーは、視覚システムを構築する必要があると考え、著書『Vision』の中で視覚理解研究の中核問題を提案しました。環境の 2 次元または 3 次元表現で、相互作用することができます。ここでのインタラクションとは、学習、理解、推論を意味します。
優れた AI 失明支援技術は、実際には、インテリジェントなセンシング、インテリジェントなユーザー意図推論、インテリジェントな情報提示を含む体系的なプロジェクトであることがわかります。この方法でのみ情報アクセシビリティを構築できます。インタラクティブなインターフェース。
AI モデルの一般化能力を向上させ、マシンがクロスモーダルな画像解析と理解能力を持てるようにするために、「マシン ビジョン ナチュラル」に代表されるマルチモーダル アルゴリズムが導入されました。 「言語理解」が急速に高まり、発展し始めました。
複数の情報モダリティの相互作用のためのこのアルゴリズム モデルは、AI の認識、理解、および相互作用の能力を大幅に向上させることができます。成熟して AI 失明支援の分野に適用されると、デジタル社会に利益をもたらすでしょう。何億もの視覚障害者が再び「世界を見る」ことができるようになりました。
WHOの統計によると、世界中で少なくとも22億人が視覚障害者または視覚障害者であり、私の国は世界で最も視覚障害者が多い国であり、その18%を占めています。 -世界の視覚障害者の総数の 20% 新たに視覚障害を持つ人の数は、毎年 450,000 人に達します。
視覚障害者の視覚的質疑応答タスクによって引き起こされる「ドミノ効果」
一人称視点認識技術は視覚障害者を支援する AI にとって非常に重要です。これは、視覚障害者がスマート デバイスを操作する参加者として参加する必要はありません。代わりに、視覚障害者の実際の視点から開始して、科学者が視覚障害者の認知により一致するアルゴリズム モデルを構築するのに役立ちます。これが、視覚障害者のための視覚的質問応答の基礎研究課題。
視覚障害者向けの視覚的な質疑応答タスクは、視覚障害者向けの AI 支援に関する学術研究の出発点であり、中心的な研究方向の 1 つです。しかし、現状の技術状況では、ブラインドビジュアル質疑応答課題は特殊なビジュアル質疑応答課題であるため、通常のビジュアル質疑応答課題に比べて精度を向上させることが困難である。
一方で、ブラインド視覚質疑応答の質問の種類は、ターゲット検出、テキスト認識、色、属性認識、その他の種類の問題など、より複雑です。冷蔵庫の中の肉の見分け方、薬の飲み方の相談、珍しい色のシャツの選び方、本の内容の紹介など。
一方、視覚インタラクションの主体としての視覚障害者の特殊性により、視覚障害者は携帯電話と物体との距離を把握することが困難である。写真を撮るときに焦点が合っていない状況が発生したり、オブジェクトは捕捉されても、そのすべてが捕捉されなかったり、重要な情報が捕捉されなかったりするため、効果的な特徴抽出が大幅に困難になります。
同時に、既存の視覚的な質問と回答のモデルのほとんどは、閉鎖された環境での質問と回答のデータ トレーニングに基づいており、サンプルの分布によって大幅に制限されており、オープンワールドでの質疑応答のシナリオに一般化するため、多段階の推論のために外部の知識を統合する必要があります。

ブラインド ビジュアル質疑応答データ
#第 2 に、ブラインド ビジュアル質疑応答の研究の開発です。 、科学者 研究の過程で、視覚的な質問応答では、ノイズの干渉によって引き起こされる派生的な問題が発生することが判明しました。したがって、ノイズを正確に特定し、完全なインテリジェントな推論を行う方法も大きな課題に直面しています。
視覚障害者は、外界を視覚的に認識できないため、画像とテキストのペアを含む視覚的な質疑応答タスクで多数の間違いを犯すことがよくあります。たとえば、目の見えない人がスーパーで買い物をするとき、酢の瓶を手に取り、酢の製造元を尋ねるなど、製品の外観や感触が似ているため、間違った質問をしてしまいがちです。醤油は。この種の言語ノイズは既存の AI モデルの失敗を引き起こすことが多く、AI にはノイズや複雑な環境から入手可能な情報を分析する能力が必要です。
最後に、AI 視覚支援システムは、視覚障害者の現在の疑問に答えるだけでなく、知的な意図を推論し、インテリジェントな情報を提示する機能も備えている必要があります。インテリジェントインタラクション技術は重要な研究方向ですが、アルゴリズム研究はまだ初期段階にあります。
インテリジェントな意図推論技術の研究の焦点は、機械が視覚障害のあるユーザーの言語と行動習慣を継続的に学習できるようにすることで、視覚障害のあるユーザーがインタラクティブな意図を表現したいと考えていると推測することです。例えば、視覚障害者が水グラスを持って座るという動作を通じて、水グラスをテーブルに置くという次の動作を予測したり、視覚障害者が服の色やスタイルについて質問したりすることで、旅行の可能性を予測するなど
この技術の難しさは、時間と空間におけるユーザーの表情や表現動作のランダム性により、インタラクティブな意思決定の心理モデルにもランダム性が生じることです。連続的なランダムな行動データからユーザーが入力した有効な情報を抽出し、動的で非決定的なマルチモーダル モデルを設計して、さまざまなタスクを最適に表現する方法が非常に重要です。
視覚障害を支援する AI の基礎研究に焦点を当て、Inspur Information はその研究の多くで国際的な評価を獲得しています
AI が視覚障害における主要な進歩であることは疑いの余地がありません。上記基礎研究分野が失明支援技術の早期実用化の鍵となる。現在、Inspur Information の最先端の研究チームは、複数のアルゴリズムの革新、事前学習モデル、基本的なデータセットの構築を通じて、AI 失明支援研究のさらなる発展を促進するためにあらゆる努力を払っています。
ブラインド視覚的質疑応答課題研究の分野において、VizWiz-VQA は、カーネギーメロン大学などの学者が共同で立ち上げた、マルチモーダルの世界トップレベルの視覚的視覚的質疑応答課題です。 「VizWiz」視覚障害データセットを使用して AI モデルをトレーニングし、視覚障害者が提供するランダムな画像とテキストのペアに対して AI が回答を返します。視覚障害者向けの視覚的質疑応答タスクでは、Inspur 情報フロンティア研究チームは、視覚障害者向けの視覚的質疑応答タスクでよくある多くの問題を解決しました。
第一に、視覚障害者が撮影した写真はぼやけていて有効な情報が少ないため、質問は通常より主観的で曖昧なものになります。視覚障害者の魅力を理解し、答えを出すという課題。
チームは、デュアルストリーム マルチモーダル アンカー ポイント アライメント モデルを提案しました。これは、視覚ターゲット検出の主要なエンティティと属性をアンカー ポイントとして使用し、画像と質問を結び付けてマルチモーダルを実現します。セマンティックの強化。
第二に、目の見えない人が写真を撮るときに正しい方向を確保することが難しいという問題を考慮して、画像の角度と文字の意味を自動的に修正することにより、光学式文字検出および認識技術と組み合わせた機能強化により、「何が」という理解の問題を解決します。
最後に、視覚障害者が撮影した写真は通常、ぼやけていて不完全です。そのため、一般的なアルゴリズムで対象物の種類と目的を判断することが困難になります。ユーザーの真の意図を推論するのに十分な常識的能力。
この目的を達成するために、チームは、回答主導型の視覚的位置決めと、大きなモデルの画像およびテキストのマッチングを組み合わせたアルゴリズムを提案し、多段階のクロストレーニング戦略を提案しました。推論中、クロストレーニングされた視覚的位置決めモデルと画像とテキストのマッチング モデルを使用して、回答領域を推測して特定します。同時に、光学式文字認識アルゴリズムに基づいて地域の文字が決定され、出力テキストが送信されます。デコーダは、視覚障害者が助けを求めたという答えを得ました。マルチモーダル アルゴリズムの最終的な精度は、人間のパフォーマンスより 9.5 パーセント上回っていました。
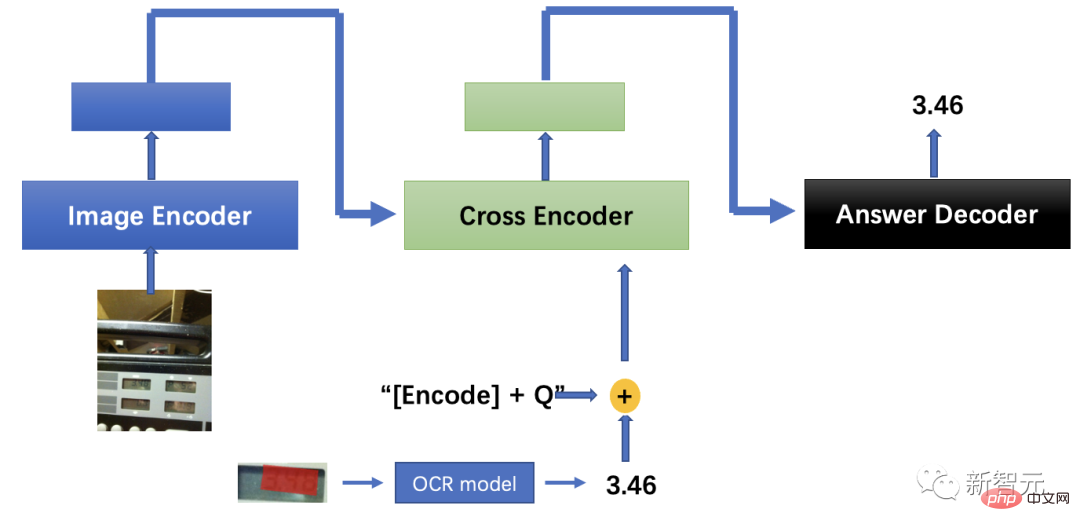
マルチモーダル視覚質問応答モデル ソリューション
視覚位置研究の現在の応用に対する最大の障害の 1 つは、ノイズのインテリジェントな処理です。実際のシーンでは、テキストの説明にノイズが含まれることがよくあります。 、人間の失言、曖昧さ、レトリックなど。実験の結果、テキストノイズによって既存の AI モデルが失敗する可能性があることが判明しました。
この目的を達成するために、Inspur 情報フロンティア研究チームは、現実世界における人間の言語エラーによって引き起こされるマルチモーダル不一致問題を調査し、視覚的位置決めテキストのノイズ除去推論タスク FREC を提案しました。モデルは、ノイズの説明に対応する視覚コンテンツを正確に特定し、テキストにノイズがあるという証拠についてさらに推論する必要があります。
FREC は、30,000 枚の画像と 250,000 を超えるテキスト注釈を提供し、失言、あいまいさ、主観的な逸脱などのさまざまなノイズをカバーします。また、解釈可能なノイズ補正、ノイズの多いノイズ修正も提供します。証拠などのラベル。
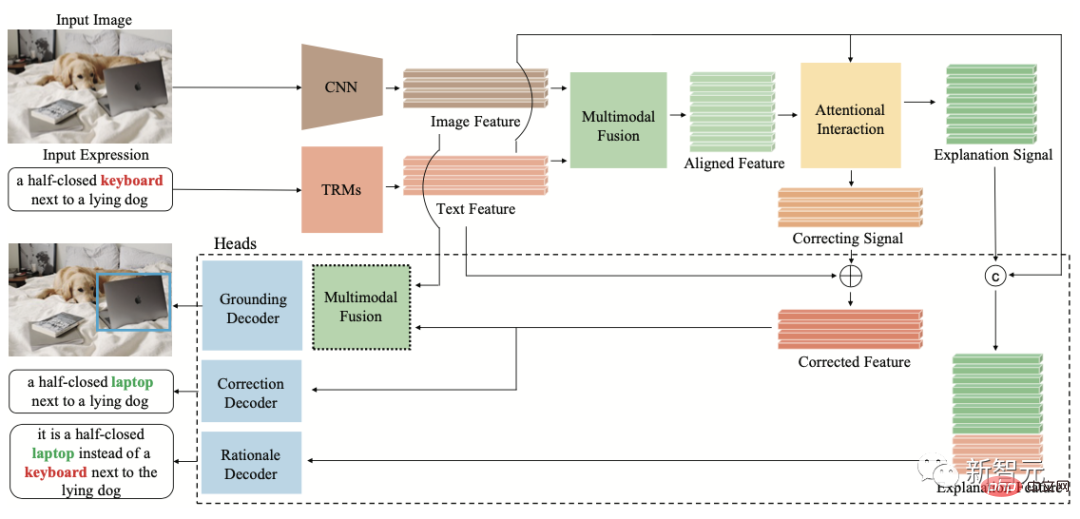
FCTR 構造図
チームは同時に、最初の解釈可能なノイズ除去視覚位置決めモデル FCTR は、ノイズのあるテキスト記述条件下で従来のモデルと比較して精度を 11 パーセント向上させます。
この研究成果は、国際マルチメディア分野のトップカンファレンスであり、この分野でCCFが推奨する唯一のクラスA国際カンファレンスであるACM Multimedia 2022カンファレンスで発表されました。

紙のアドレス: https://www.php.cn/link/9f03268e82461f179f372e61621f42d9 ##画像とテキストに基づいて思考と対話する AI の能力を調査するために、Inspur 情報フロンティア研究チームは、業界に新しい研究の方向性を提案し、説明可能なエージェントの視覚的インタラクションの質問と回答タスク AI-VQA を提案しました。論理的なリンクを確立して巨大な知識ベースを検索し、画像やテキストの既存のコンテンツを拡張します。
現在、チームは AI-VQA 用のオープンソース データ セットを構築しました。これには、144,000 を超える大規模イベントのナレッジ ベース、完全に手動で注釈が付けられた 19,000 のインタラクティブな行動認知推論の質問が含まれています。オブジェクト、裏付けとなる事実、推論パスなどの主要な解釈可能な注釈。
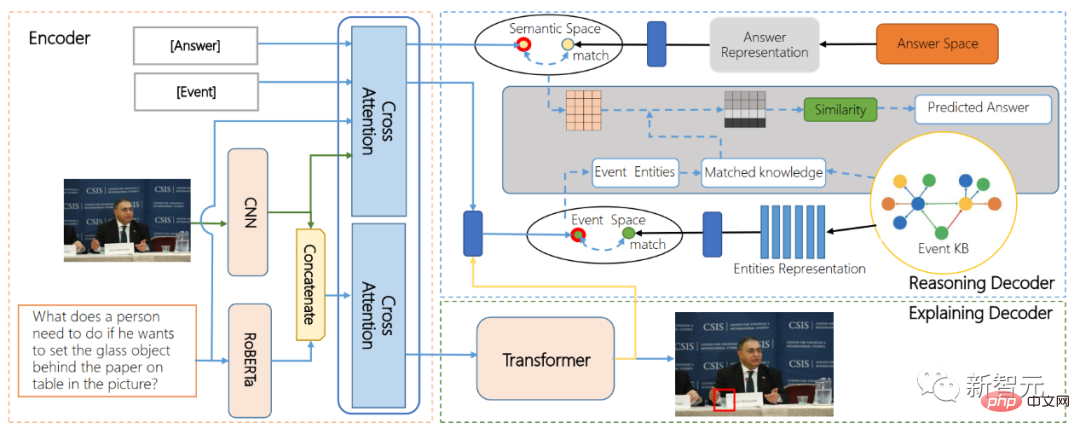 #ARE 構造図
#ARE 構造図
同時に、最初のスマートチームが提案した電話による身体インタラクション行動理解アルゴリズムモデルARE (代替理由と説明のためのエンコーダ-デコーダモデル) は、エンドツーエンドのインタラクション動作位置特定とインタラクション動作影響推論を初めて実現します。テキスト融合技術と知識グラフ検索アルゴリズムにより、長期にわたる因果連鎖推論能力のための視覚的な質問応答モデルを実現します。
テクノロジーの偉大さは、世界を変えるだけではなく、より重要なのは、どのようにして人類に利益をもたらし、より不可能なことを可能にするかということです。
視覚障害者にとって、視覚障害者を支援するAI技術によって、特別扱いされるのではなく、他の人と同じように自立して生活できることは、テクノロジーの最大の善意を反映しています。
AI が現実に輝き始めた今、テクノロジーはもはや山のように冷たいものではなく、人間的な配慮の温かさに満ちています。
AI テクノロジーの最前線に立つ Inspur Information は、人工知能テクノロジーの研究がより多くの人々を惹きつけ、人工知能テクノロジーの実装を促進し続け、マルチモーダル AI が実現されることを望んでいます。失明の波は、AI 詐欺対策、AI 診断と治療、AI 災害早期警報などのより多くのシナリオに広がり、私たちの社会により多くの価値を生み出します。
参考リンク:
##https://www.php.cn/link/9f03268e82461f179f372e61621f42d9
以上がAI を使用して、何億人もの目の見えない人々が再び「世界を見る」ことができるようにします。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。