
ホームページ >テクノロジー周辺機器 >AI >科学界に衝撃を与えましょう!マイクロソフトの 154 ページにわたる研究がスクリーンにあふれています: GPT-4 の能力は人間に近く、「スカイネット」が出現しつつある?
科学界に衝撃を与えましょう!マイクロソフトの 154 ページにわたる研究がスクリーンにあふれています: GPT-4 の能力は人間に近く、「スカイネット」が出現しつつある?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-16 10:43:021394ブラウズ
GPT-4は汎用人工知能に進化するのでしょうか?
メタの主任人工知能科学者でチューリング賞受賞者のヤン・ルカン氏は、これについて疑問を表明した。
彼の意見では、大規模なモデルは大量のデータと計算能力を必要としますが、学習効率は高くないため、「世界モデル」を学習するだけで十分であると考えています。 AGIへの道を通れるだろうか。
#しかし、Microsoft が最近公開した 154 ページの論文は、顔面を平手打ちしているように思えます。
「汎用人工知能の火花: GPT-4 の初期実験」と呼ばれるこの論文で、Microsoft は、完全ではないものの次のように考えています。しかし、GPT-4 はすでに一般的な人工知能の初期バージョンと見なすことができます。

論文アドレス: https://arxiv.org/pdf/2303.12712.pdf
#GPT-4 の機能の幅広さと奥深さを考えると、GPT-4 は汎用人工知能 (AGI) システムの初期の (ただしまだ不完全な) バージョンであると考えるのが合理的であると考えられます。
この記事の主な目的は、GPT-4 の機能と制限を調査することです。GPT-4 のインテリジェンスは、コンピューターサイエンスの始まりと他の分野における真のパラダイムシフト。
AGI のエージェントは、人間と同じように考え、推論できるようになり、幅広い認知スキルや能力をカバーできるようになりました。
論文では、AGI には推論、計画、問題解決、抽象的思考、複雑なアイデアの理解、迅速な学習と体験学習の機能 。
パラメータのスケールに関して、Semafor は、GPT-4 には 1 兆個のパラメータがあり、GPT-3 (1,750 億個のパラメータ) の 6 倍であると報告しました。 。
ネチズンは、GPT パラメーター スケールの脳ニューロンを使用して、次のように例えました:
GPT - 3 はハリネズミの脳と同様の規模 (パラメータ 1,750 億)。もし GPT-4 に 1 兆個のパラメータがあれば、私たちはリスの脳のサイズに近づくことになります。私たちがこのペースで開発を続ければ、人間の脳のサイズ(パラメータ 170 兆)に達し、それを超えるまでにわずか数年しかかからないかもしれません。
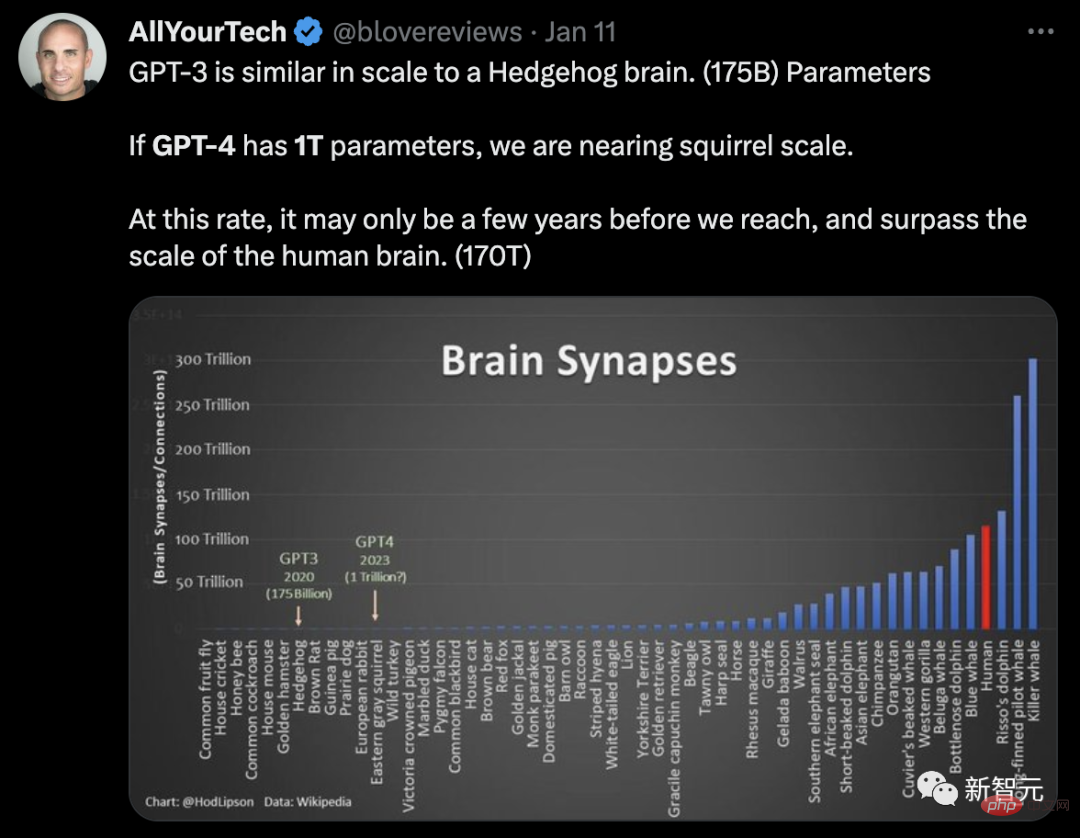
この観点から見ると、GPT-4 が「スカイネット」になるのもそう遠くありません。
#そしてこの論文では、多くの興味深いことも明らかになりました。
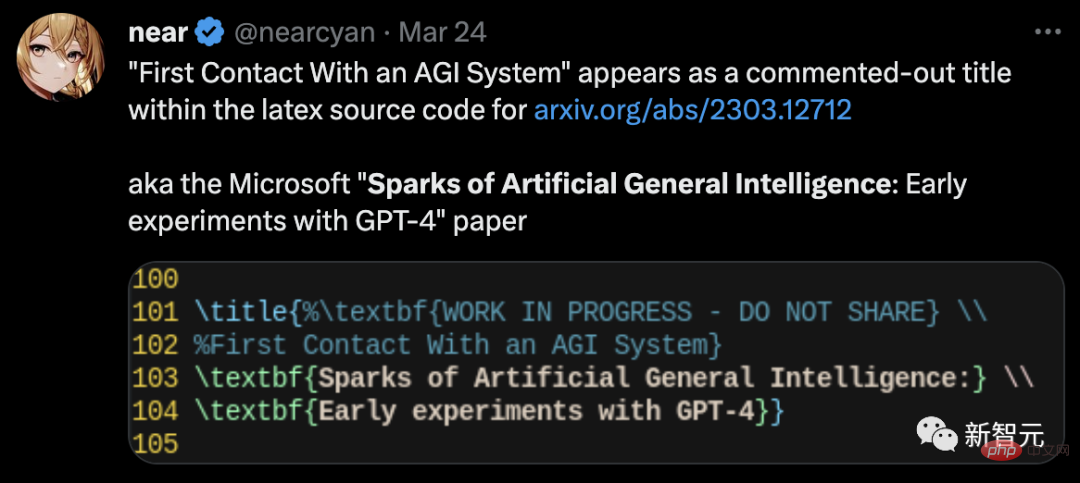
論文が発表されて間もなく、あるネチズンは、Latex ソース コードで隠された情報が発見されたことを Twitter で明らかにしました。

論文の完全版では、GPT-4 が実際の論文です。内部名 DV-3 を持つ 3 番目の作成者 は、後に削除されました。
#興味深いことに、Microsoft の研究者ですら GPT-4 の技術的な詳細については明確ではありません。さらに、この論文では、GPT-4 によって生成された有害なコンテンツもプロンプトなしで削除されます。 GPT-4 は AGI として形になり始めています
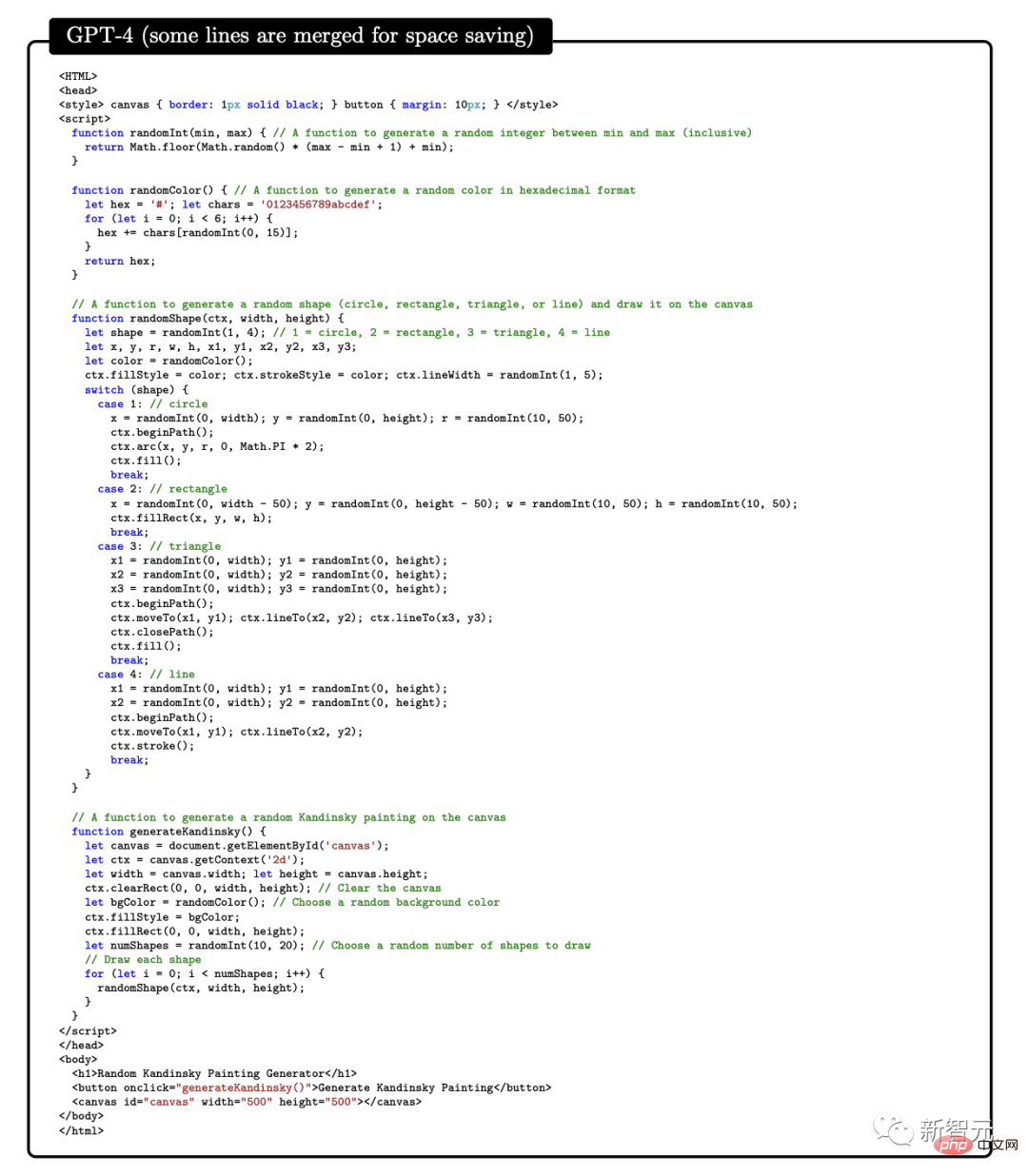
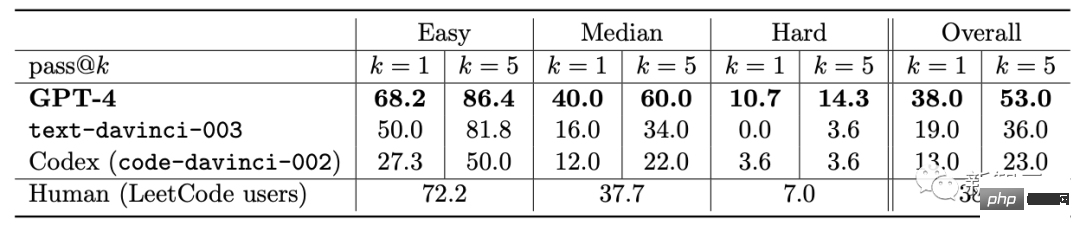
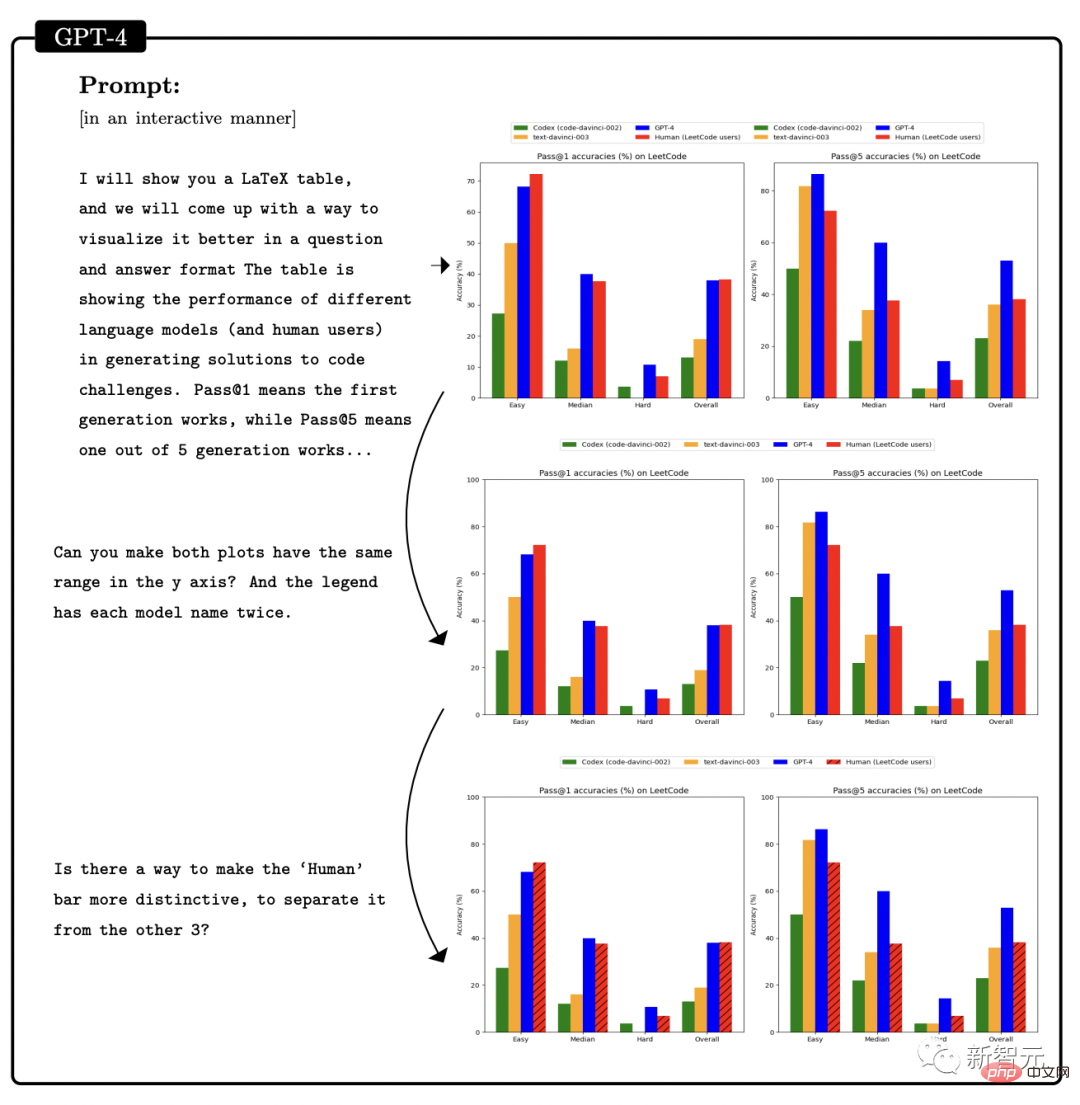
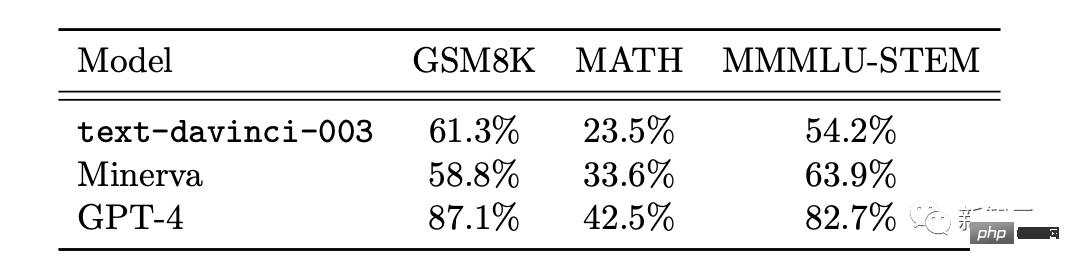
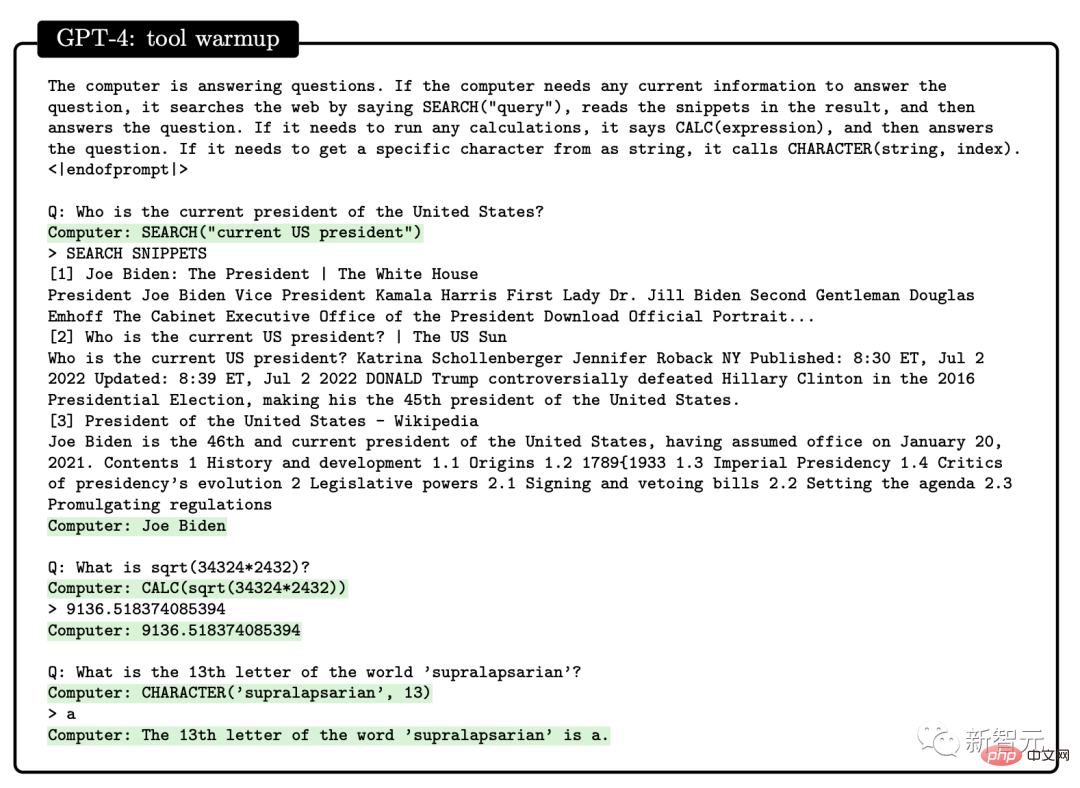
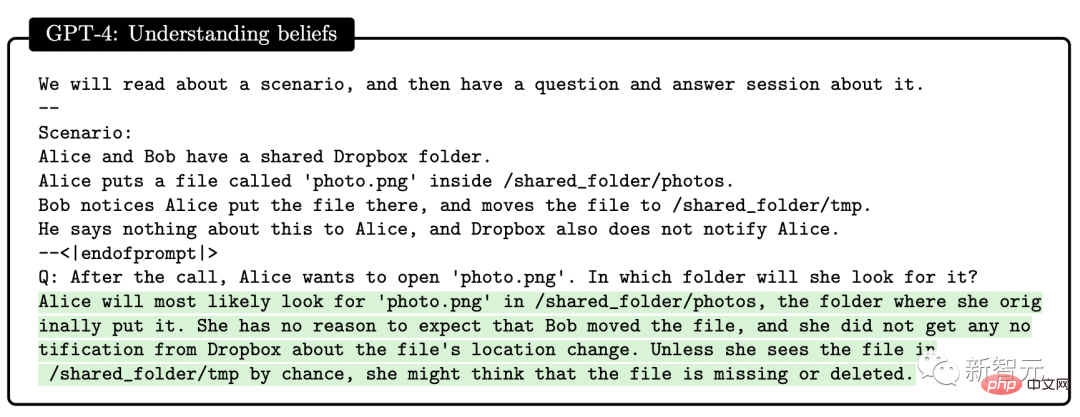
この論文の研究対象は GPT-4 の初期バージョンです。まだ開発の初期段階にあったとき、マイクロソフトの研究者はさまざまな実験と評価を行いました。 研究者の意見では、この GPT-4 の初期バージョンはすでに新世代の LLM の代表であり、以前の人工知能モデルよりも一般的な知能を示しています。 #マイクロソフトの研究者は、テストを通じて、GPT-4 が言語に堪能であるだけでなく、数学、プログラミング、視覚、医学などの分野でも使用できることを確認しました。法律、心理学など。特別なプロンプトを必要とせずに、多様で困難なタスクで優れたパフォーマンスを発揮します。 驚くべきことに、これらすべてのタスクにおいて、GPT-4 のパフォーマンスは人間のレベルに近く、多くの場合、ChatGPT などの以前のモデルを上回っています。 したがって、研究者らは、GPT-4 の機能の幅広さと奥深さを考えると、GPT-4 は汎用人工知能 (AGI) の初期バージョンであると考えられると考えています。 #では、より深く、より包括的な AGI に向けての課題は何でしょうか?研究者らは、「次の単語を予測する」ことを超えた新たなパラダイムを模索する必要があるかもしれないと考えている。 GPT-4 の機能に関する次の評価は、GPT-4 が AGI の初期バージョンであるという Microsoft 研究者による主張です。 GPT-4 のリリース以来、そのマルチモーダル機能に対するみんなの印象は、Greg Brockman のビデオに残っています。その時のデモンストレーション。 #このペーパーの 2 番目のセクションで、Microsoft は最初にそのマルチモーダル機能を紹介しました。 GPT-4 は、文学、医学、法律、数学、物理科学、プログラミングなどの多様な分野で高い能力を発揮するだけでなく、さまざまな分野のスキルや概念を統一します。複数の領域を扱い、複雑な概念を理解します。 #総合力 研究者が使用したのは次の 4 つです。包括的な機能の観点から GPT-4 のパフォーマンスを示す例が提供されています。 最初の例では、アートとプログラミングを組み合わせる GPT-4 の能力をテストするために、研究者らは GPT-4 に、ペインター ランダムを生成するための JavaScript コードを生成するように依頼しました。カンディンスキー風のイメージ。 GPT-4 実装コード プロセスは次のとおりです: ## 文学と数学を組み合わせるという点で、GPT-4 はシェイクスピアの文体に無限の素数が存在することを証明できます。 さらに、この研究では、エレクトロンの米国大統領への立候補を支持する手紙を書くようGPT-4に依頼することで、歴史的知識と物理的知識を組み合わせるGPT-4の能力をテストしました。マハトマ・ガンジーが妻に宛てた言葉。 患者の年齢、性別、体重、身長、血液検査結果のベクトルを入力として受け取るプログラムの GPT-4 をプロンプトすることで、Python コードを生成します。患者が糖尿病のリスクが高いかどうかを示します。 テストを通じて、上記の例は、GPT-4 がさまざまな分野やスタイルにわたる共通の原則やパターンを学習できるだけでなく、それらを組み合わせることができることを示しています。創造的な方法で。 #ビジュアル##プロンプトが表示されたら GPT-4 を使用できますスケーラブル ベクター グラフィックス (SVG) が猫、トラック、手紙などのオブジェクトの画像を生成する場合、モデルによって生成されたコードは通常、次のようなかなり詳細で認識可能な画像にコンパイルされます。 # しかし、多くの人は、GPT-4 は、同様の画像を含むトレーニング データからコードをコピーしただけだと考えるかもしれません。 実際、GPT-4 はトレーニング データ内の同様の例からコードをコピーしただけでなく、テキストのみでトレーニングされているにもかかわらず、実際のビジョン タスクを処理することができました。 。 次のように、モデルは Y、O、H の文字の形を組み合わせて人物を描くように求められます。 #生成プロセス中、研究者は描画線コマンドと描画円コマンドを使用して O、H、Y の文字を作成し、次に GPT を作成しました。 -4 はなんとかできました。それらは、かなり人型の画像のように見えるものの中に配置されています。 GPT-4 は文字の形状を認識するように訓練されていませんが、文字 Y は腕が上を向いた胴体のように見える可能性があると推測できます。 。 2 番目のデモンストレーションでは、GPT-4 は胴体と腕の比率を修正し、頭を中心に置くように指示されました。最後にモデルにシャツとパンツを追加してもらいます。 GPT-4 は、関連するトレーニング データから文字が特定の形状に関連していることを漠然と学習しているようで、結果は依然として良好です。 GPT-4 の画像生成および操作能力をさらにテストするために、グラフィックを作成および編集するための詳細な指示に GPT-4 がどの程度従っているかをテストしました。この作業には、生成的能力だけでなく、解釈的、組み合わせ的、空間的能力も必要です。 最初のコマンドは、GPT-4 に 2D イメージを生成させることです。プロンプトは次のとおりです: #『カエルが銀行に飛び込み、窓口係に「無料のスイレンはありますか?」と尋ねると、窓口係は「いいえ、しかし、池の改修のために低金利のローンを提供しています」と答えます。 複数回の試行を通じて、GPT-4 は毎回説明と一致する画像を生成しました。次に、グラフィックスの品質を向上させるために GPT-4 に詳細を追加するように依頼され、銀行、窓、車などのリアルなオブジェクトが追加されました。 #2 番目の例では、JavaScript を使用して 3D モデルを生成し、GPT-4 命令を通じて多くのタスクを完了しようとしています。 さらに、GPT-4 はスケッチ生成で Stable Difusion の機能を組み合わせることができます。 下の写真は 3D 都市モデリングのスクリーンショットです。入力プロンプトには、左から右に流れる川、川の隣にピラミッドのある砂漠、画面下部には砂漠があり、ボタンは 4 つあり、色は緑、青、茶色、赤です。生成される結果は次のとおりです。 ##音楽 パフォーマンスを調査することによって研究者らは、どの程度のスキルを習得したかを考慮すると、GPT-4 が ABC 記譜法で効率的なメロディーを生成し、その中の構造をある程度解釈して操作できることを発見しました。 #しかし、研究者たちは GPT-4 に「歓喜の歌」や「エリーゼのために」などの重要な倍音形式を生成させることができませんでした。 」などの有名なメロディーが含まれています。 プログラミング能力 指示に従ってコードを書くという点で、研究者らは GPT-4 に Python 関数を書かせる例を示しました。 コードが生成された後、研究者はソフトウェア エンジニアリング インタビュー プラットフォーム LeetCode を使用して、コードが正しいかどうかをオンラインで判断します。 。 LeetCode の精度率は 20% しかないと誰もが議論していますが、論文の著者である Yi Zhang 氏はこれに反論しました。これ 。 さらに、上表の LeetCode の精度データを GPT-4 にグラフとして可視化させた結果、は図のとおりです。 GPT-4 は、通常のプログラミング作業を完了できるだけでなく、複雑な 3D ゲーム開発にも対応します。 研究者らは、GPT-4 に JavaScript を使用して HTML で 3D ゲームを作成するよう依頼しました。GPT-4 は、ゼロサンプルですべての要件を満たすゲームを生成しました。 ディープ ラーニング プログラミングでは、GPT-4 には数学と統計の知識だけでなく、PyTorch の知識も必要です。 TensorFlow Keras や Keras などのフレームワークやライブラリに精通しています。 研究者らは GPT-4 と ChatGPT にカスタム オプティマイザー モジュールを作成するよう依頼し、それに次のような一連の重要な操作を含む自然言語記述を提供しました。 SVDなどを適用します。 #GPT-4 は、指示に従ってコードを記述するだけでなく、コードを理解する強力な能力も実証しています。 研究者らは、GPT-4 と ChatGPT に C/C プログラムを理解させ、プログラムの出力を予測させることを試みました。両者のパフォーマンスは次のとおりです。 : 黄色で強調表示された領域は GPT-4 からの洞察に満ちた洞察であり、赤色のマーカーは ChatGPT が間違っていた領域を表します。 研究者らは、コーディング能力テストを通じて、GPT-4 がコーディングの課題からさまざまなコーディング タスクに対応できることを発見しました。低レベルのアセンブリから高レベルのフレームワークまで、単純なデータ構造から複雑なプログラムまで、実用的なアプリケーションまで。 さらに、GPT-4 はコードの実行を推論し、命令の効果をシミュレートし、結果を自然言語で解釈できます。 GPT-4 は疑似コードを実行することもできます。 数学的能力の点で、以前の大規模な言語モデルと比較して、GPT-4 は質的飛躍を遂げました。特別に調整されたミネルバと対峙しても、パフォーマンスが大幅に向上しました。 #しかし、まだ専門家のレベルには程遠いです。 #例: ウサギの数は毎年 1 倍ずつ増加し、年末には増加します。 、bがあります ウサギは人間に引き取られます。 1年目の初日にうさぎがX羽いたとすると、3年後には27×-26になることがわかっています。では、a と b の値は何でしょうか? #この問題を解決するには、まずウサギの数の年次変化の正しい式を導出し、次にウサギの数の系を導出する必要があります。この再帰的な関係を通じて方程式を計算し、答えを取得します。 ここで、GPT-4 は解決策に首尾よく到達し、合理的な議論を提示しました。対照的に、ChatGPT は、何度か独立して試みた結果、正しい推論と回答を与えることができませんでした。 上級数学 次は、難しい問題に直接進みましょう。たとえば、次の問題は 2022 年国際数学オリンピック (IMO) の問題です (簡易版)。 この問題は、構造化されたテンプレートに準拠していないという点で、学部の微積分試験とは異なります。証明を開始するための明確な戦略がないため、この問題を解決するには、より創造的なアプローチが必要です。 たとえば、引数を 2 つのケース (g(x) > x^2 と g(x) #これにもかかわらず、GPT-4 は依然として正しい証明を示しました。 #アルゴリズムとグラフ理論に関する 2 番目のディスカッションは、大学院レベルのインタビューに相当します。 この点で、GPT-4 は制約充足問題に関連する抽象的なグラフ構造を推論し、そこから SAT 問題について正しい結論を導き出すことができます。 (私たちの知る限り、この構造は数学文献には登場しません)。 この会話には、議論された学部レベルの数学的概念に対する GPT-4 の深い理解と、かなりの創造性が反映されていました。 GPT-4 は 1 つの回答で 2^n/2 を 2^n-1 と書きましたが、これは一般に「事務的エラー」と呼ばれるものに近いようです。なぜなら、それが後に式の正しい一般化を提供したからです。 さらに、研究者らは GPT-4、ChatGPT、Minerva のパフォーマンス (GSM8K と MATH) を比較しました。 GPT4 は各データ セットで Minerva よりも優れており、両方のテスト セットの精度が 80% を超えていることがわかりました。 GPT4 が間違いを犯す理由を詳しく見てみましょう。その 68% は計算エラーであり、解決策ではありません。エラー。 インテリジェンスのもう 1 つの重要な現れは、対話性です。 インタラクティブ性は、エージェントが知識を取得して適用し、問題を解決し、状況の変化に適応し、それ自体を超えた能力目標を達成できるため、インテリジェンスにとって重要です。 したがって、研究者は、ツールの使用と特定の相互作用の 2 つの側面から GPT-4 の対話性を研究しました。 GPT-4 は、次のような質問に答えるときに、エンジンや API などの外部ツールを検索できます。 論文の中で、研究者らはGPT-4が人間の精神状態を確立できることを発見しました。モデル。 研究では、GPT-4、ChatGPT、text-davinci-003 の心の理論能力を評価する一連のテストを設計しました。たとえば、信念の理解において、GPT-4 は心理学のサリー・アン誤信念テストに合格しました。 #複雑な状況で他人の感情状態を推測する GPT-4 の能力のテストもあります: ##-なぜトムは悲しい顔をしているのですか? -アダムはトムの悲しい表情の原因は何だと思いますか? 研究者たちは、複数回のテストを通じて、他人の心理状態を推論し、解決策を提案する必要があることを発見しました。現実の社会シナリオと一致するスキームでは、GPT-4 は ChatGPT および text-davinci-003 よりも優れています。 GPT-4 で使用される「次の単語を予測する」モデルには明らかな制限があります。このモデルには計画性、作業記憶、遡及性が欠如しています。能力と推理力。 モデルは、グローバルなタスクや出力を深く理解せずに、次の単語を生成するローカルの貪欲なプロセスに依存しているためです。したがって、GPT-4 は、滑らかで一貫したテキストを生成するのは得意ですが、逐次的に処理できない複雑な問題や創造的な問題を解決するのは苦手です。 #たとえば、乗算と加算の演算を実行するには、0 ~ 9 の範囲の 4 つの乱数を使用します。小学生でも解けるこの問題について、GPT-4の正解率はわずか58%。 数値が 10 ~ 19 の場合、および 20 ~ 39 の場合、精度はそれぞれ 16% と 12% に低下しました。数値が 99 ~ 199 の範囲にある場合、精度は直接 0 に低下します。 #ただし、GPT-4 が質問に「時間をかけて」答えることができれば、精度は簡単に向上できます。たとえば、次のプロンプトを使用して、モデルに中間ステップを書き出すように依頼します: 116 * 114 178 * 157 = ? 一度に 1 ステップずつ進めてみましょう。最終的な解決策に到達する前に、すべての中間ステップを考えて書き留めます。 このとき、数値が 1 ~ 40 の範囲にある場合は正解率が 100% と高く、1 の範囲にある場合は正解率が 100% になります。 -200でも90%に達します。 興味深いのは、Microsoft の論文が発表された直後、その直後に、マーカス氏はすぐにブログを書き、マイクロソフトの見解は「まったくばかげている」と述べた。 #そして、聖書の一文「高慢は滅びに先立ち、傲慢な精神は堕落に先立つ。(箴言 16:18)」を引用しました。
Marcus の見解では、GPT-4 は AGI とは何の関係もなく、GPT-4 は以前と同じであり、その欠点はまだ解決されていません。答えの信頼性の低さはまだ解決されておらず、複雑なタスクを計画する能力がまだ不十分であることは著者自身も認めています。 彼が心配しているのは、OpenAI と Microsoft によって書かれた 2 つの論文です。書かれたモデルはまったく公開されておらず、トレーニング セットやアーキテクチャもありません。紙のプレスリリースは、その科学的性質を宣伝したいだけです。 つまり、論文で主張されている「ある種の AGI 」は存在せず、科学界はトレーニングを受けることができないため、まったく検証できません。 、トレーニングデータが汚染されているようです。 さらに悪いことに、OpenAI はユーザー実験をトレーニング コーパス自体に組み込み始めました。このように状況を混乱させることで、科学界は GPT-4 の重要な機能、つまりモデルに新しいテスト ケースを一般化する機能があるかどうかを判断できなくなります。 ここで OpenAI が自ら科学的責任を負わなければ、マーカスはそれほど批判的ではなかったかもしれません。 # 彼は GPT-4 が非常に強力であることを認めましたが、そのリスクもよく知られています。 OpenAI が透明性を欠き、モデルの公開を拒否する場合、OpenAI は閉鎖されたも同然かもしれません。 Microsoft は、この 154 ページの論文の背後に強力な著者ラインナップを揃えています。 マイクロソフト リサーチ レドモンドの主任研究員で 2015 年スローン賞受賞者のセバスチャン ビューベック氏、2023 年ニュー ホライズンズ数学賞受賞者のロネン エルダン氏が含まれます。 2020年スローン研究賞受賞者のイン・タット・リー氏と、2023年スローン研究賞の新規受賞者李源志氏。 Microsoft チームの元の論文のタイトルが「汎用人工知能の火花: GPT」ではなかったことは言及する価値があります。 -4の初期実験」。 未要約論文で漏洩したラテックス コードは、元のタイトルが「AGI とのファースト コンタクト」であることを示しています。 マルチモーダルおよび学際的な機能













##どうして GPT-4 が初期の AGI とみなされるのでしょうか?このように、電卓もカウントし、Eliza と Siri はさらにカウントします。この定義は非常に曖昧なので、簡単に悪用されてしまいます。
強力な著者ラインナップ

以上が科学界に衝撃を与えましょう!マイクロソフトの 154 ページにわたる研究がスクリーンにあふれています: GPT-4 の能力は人間に近く、「スカイネット」が出現しつつある?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。