
ホームページ >バックエンド開発 >Python チュートリアル >Python を使用した Excel での 14 の一般的な操作
Python を使用した Excel での 14 の一般的な操作

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-15 19:07:01941ブラウズ

df1=sale[['订单明细号','单据日期','地区名称', '业务员名称','客户分类', '存货编码', '客户名称', '业务员编码', '存货名称', '订单号', '客户编码', '部门名称', '部门编码']] df2=sale[['订单明细号','存货分类', '税费', '不含税金额', '订单金额', '利润', '单价','数量']]需要: df1 の各オーダーに対応する利益を知りたいです。 df2のテーブルに利益列が存在するので、df1の各オーダーに対応する利益を知りたいのです。 Excel を使用する場合、最初に注文明細番号が一意の値であることを確認してから、df1 に新しい列を追加して =vlookup(a2,df2!a:h,6,0) と記述し、それをプルダウンすると、大丈夫ですよ。 (残り 13 個は Excel は書きません)
#查看订单明细号是否重复,结果是没。 df1["订单明细号"].duplicated().value_counts() df2["订单明细号"].duplicated().value_counts() df_c=pd.merge(df1,df2,on="订单明细号",how="left")2. ピボット テーブル
pd.pivot_table(sale,index="地区名称",columns="业务员名称",values="利润",aggfunc=[np.sum,np.mean])3. 2 つの列の違いを比較します
sale["订单明细号2"]=sale["订单明细号"] #在订单明细号2里前10个都+1. sale["订单明细号2"][1:10]=sale["订单明细号2"][1:10]+1 #差异输出 result=sale.loc[sale["订单明细号"].isin(sale["订单明细号2"])==False]4. 重複値の削除
sale.drop_duplicates("业务员编码",inplace=True)5. 欠損値の処理#列的行数小于index的行数的说明有缺失值,这里客户名称329<335,说明有缺失值 sale.info()

#用0填充缺失值 sale["客户名称"]=sale["客户名称"].fillna(0) #删除有客户编码缺失值的行 sale.dropna(subset=["客户编码"])6. 複数条件のフィルタリング
sale.loc[(sale["地区名称"]=="北京")&(sale["业务员名称"]=="张爱")&(sale["订单金额"]>5000)]7. ファジー フィルタリング データ
sale.loc[sale["存货名称"].str.contains("三星|索尼")] 8. 分類と概要sale.groupby(["地区名称","业务员名称"])["利润"].sum()9. 条件計算
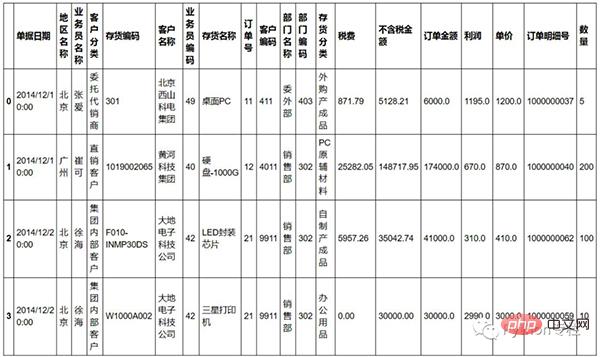
sale.loc[sale["存货名称"].str.contains("三星")&(sale["税费"]>=1000)][["订单明细号","利润"]].describe()
 #10. データ間のスペースを削除
#10. データ間のスペースを削除
要件: 削除インベントリー名の両側のスペース。
sale["在庫名"].map(lambda s:s.strip(""))
11. データ分離
sale=pd.merge(sale,pd.DataFrame(sale["单据日期"].str.split(" ",expand=True)),how="inner",left_index=True,right_index=True)12. 外れ値の置換sale.describe()
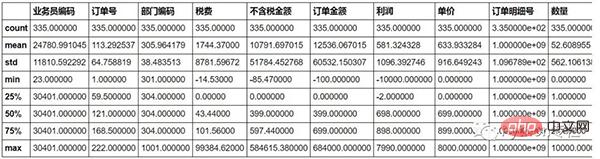
sale["订单金额"]=sale["订单金额"].replace(min(sale["订单金额"]),0)13. グループ化
sale.groupby("地区名称")["利润"].sum().describe()
#先建立一个Dataframe
sale_area=pd.DataFrame(sale.groupby("地区名称")["利润"].sum()).reset_index()
#设置bins,和分组名称
bins=[-10,7091,10952,17656,37556]
groups=["较差","中等","较好","非常好"]
#使用cut分组
#sale_area["分组"]=pd.cut(sale_area["利润"],bins,labels=groups) 14. ビジネス ロジックに従ってタグを定義します。
需要: 売上利益率 (つまり、利益/注文金額) が 30% を超えて高品質の製品としてマークされ、5% 未満が通常の製品としてマークされる製品情報。 , Excel には一般的に使用される操作がたくさんあります。一般的に使用される操作を 14 個列挙しました。他の操作を実装したい場合は、コメントして一緒に議論することができます。また、私の Python の記述が適切ではないこともわかっています。十分に簡潔なので、loc inertia を使用します (実際、クエリはより簡潔になります)。これらのいくつかに精通している場合、操作を記述するより良い方法がある場合は、必ずコメントして知らせてください。あなた! ######
14. ビジネス ロジックに従ってタグを定義します。
需要: 売上利益率 (つまり、利益/注文金額) が 30% を超えて高品質の製品としてマークされ、5% 未満が通常の製品としてマークされる製品情報。 , Excel には一般的に使用される操作がたくさんあります。一般的に使用される操作を 14 個列挙しました。他の操作を実装したい場合は、コメントして一緒に議論することができます。また、私の Python の記述が適切ではないこともわかっています。十分に簡潔なので、loc inertia を使用します (実際、クエリはより簡潔になります)。これらのいくつかに精通している場合、操作を記述するより良い方法がある場合は、必ずコメントして知らせてください。あなた! ###### 最後に、Excel と Python のどちらが使いやすいかを比較するのではなく、実際にはどちらもツールです。Excel は最も普及しているデータ処理ツールとして、素晴らしい、いくつかの操作は確かに Python の方が簡単ですが、Excel には Python よりも簡単な操作もたくさんあります。
たとえば、非常に単純な操作: 各列を合計し、それを最下行に表示します。Excel では、列に sum() 関数を追加し、それを左に引っ張って問題を解決します。 , while Python 次に、関数を定義する必要があります(Python は形式を決定する必要があり、数値データでない場合は直接エラーを報告するためです。)
以上がPython を使用した Excel での 14 の一般的な操作の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事は51cto.comで複製されています。侵害がある場合は、admin@php.cn までご連絡ください。