
ホームページ >テクノロジー周辺機器 >AI >ハーバード大学は大混乱:DALL-E 2 は単なる「接着モンスター」であり、その生成精度はわずか 22%
ハーバード大学は大混乱:DALL-E 2 は単なる「接着モンスター」であり、その生成精度はわずか 22%

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-15 17:40:031240ブラウズ
DALL-E 2 が最初にリリースされたとき、生成された絵画は入力されたテキストをほぼ完全に再現することができ、高精細な解像度と強力な描画イマジネーションにより、さまざまなネチズンからも「かっこよすぎる」と評されました。

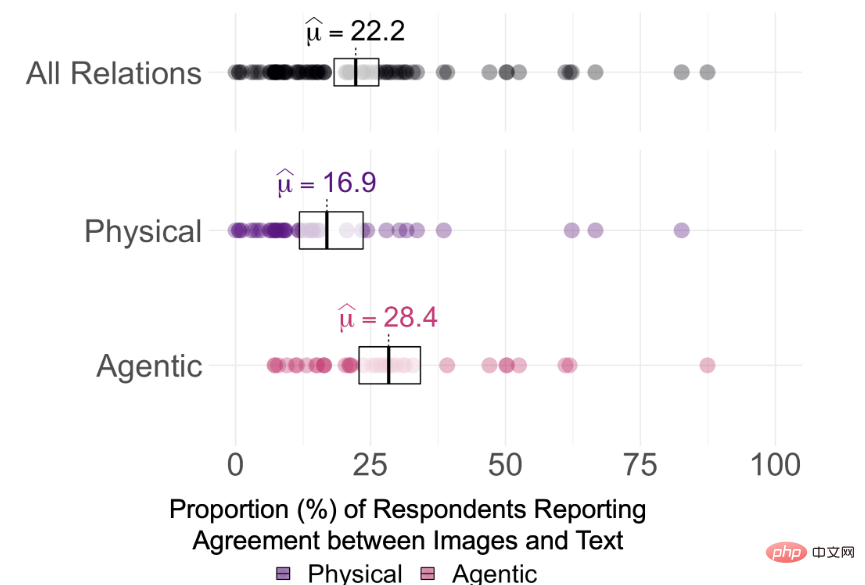
しかし、最近ハーバード大学が発表した新しい研究論文では、DALL-E 2 によって生成された画像は素晴らしいものの、テキスト内のいくつかのエンティティをつなぎ合わせているだけである可能性があることが示されています。総合すると、文章で表現されている空間関係さえ理解できません。

論文リンク: https://arxiv.org/pdf/2208.00005.pdf
データリンク: https://osf.io/sm68h/
たとえば、「スプーンの上にカップ」というテキスト プロンプトが与えられた場合、DALL-E 2 によって生成された画像の一部が「オン」関係を満たしていないことがわかります。
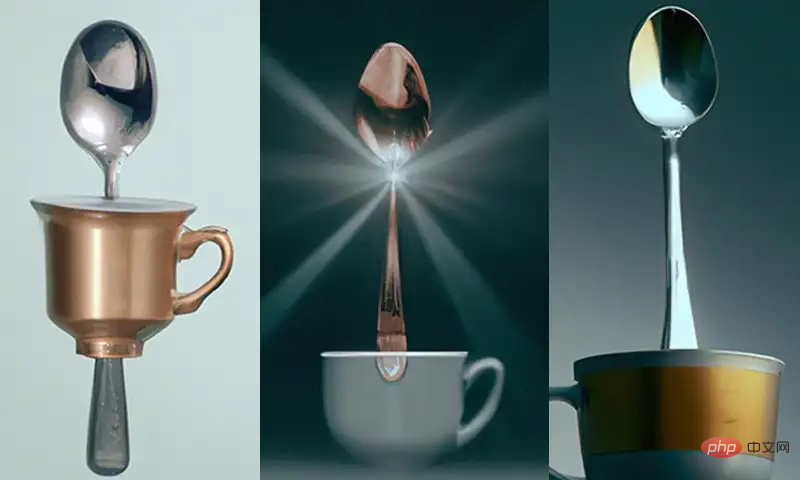
ただし、訓練セットでは、DALL-E 2 が目にする可能性のあるティーカップとスプーンの組み合わせはすべて「in」であり、「on」は比較的まれです。したがって、この 2 つの関係を生成するという点では、正解率も異なります。

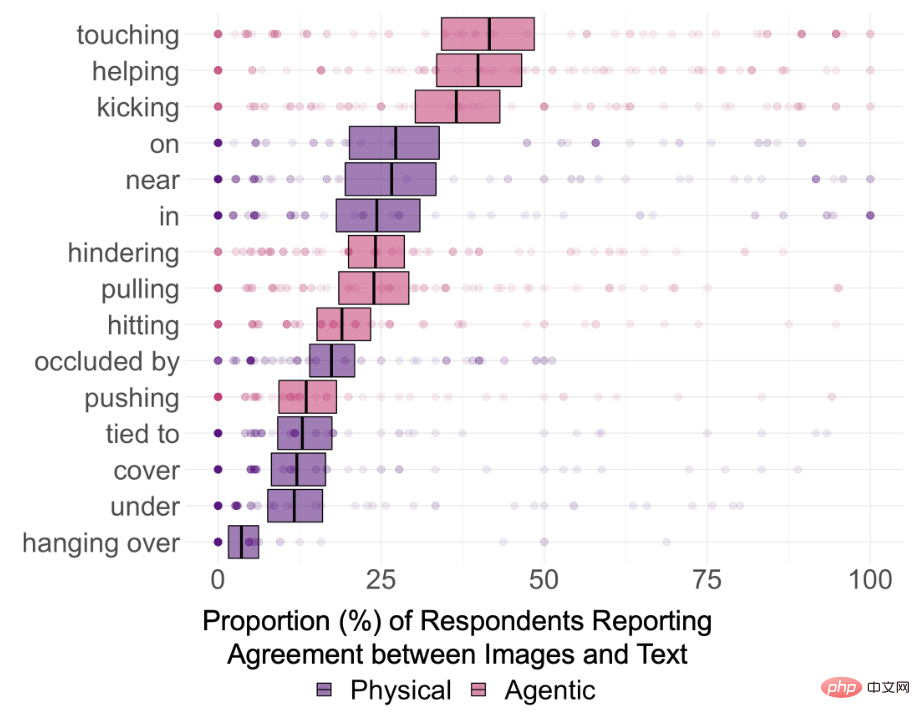
そこで、DALL-E 2 がテキスト内の意味関係を本当に理解できるかどうかを調査するために、研究者らは 15 種類の関係を選択し、そのうち 8 つは空間関係 (物理的関係)。)、中に、上に、下に、覆う、近くに、遮られる、ぶら下がる、縛られるなど、押す、引く、触れる、叩く、蹴る、助ける、隠すなどの 7 つの動作関係 (エージェント関係)。
##テキスト内のエンティティ セットは 12 に制限されており、選択されたアイテムは各データ セット内の単純で共通のアイテム、つまり、箱、円柱、毛布、ボウル、ティーカップ、ナイフ、男性、女性、子供、ロボット、サル、イグアナ。


DALL-E 2 には他にどのような問題がありますか?
実際、DALL-E 2 がリリースされるとすぐに、多くの専門家がその利点と欠点について詳細な分析を実施しました。

ブログリンク: https://www.lesswrong.com/posts/uKp6tBFStnsvrot5t/what-dall-e-2-can-and-cannot-do
GPT-3 で小説を書くのは少し単調ですが、DALL-E 2 ではテキストのイラストを生成したり、長いテキストの漫画を生成したりすることもできます。
たとえば、DALL-E 2 は、「アルフォンス ミュシャの絵を描いた、コーヒーショップでラップトップに取り組み、ヘッドフォンを着用している女性」などの機能を写真に追加でき、絵画スタイルやコーヒー ショップを正確に生成できます。 、ヘッドフォンを着用している、ラップトップなど。

ただし、テキスト内の機能の説明に 2 人が関与している場合、DALL-E 2 はどの機能がどの人に属しているかを忘れる可能性があります。たとえば、入力テキストは次のとおりです:
ベッドで休む黒髪の少年と、太陽が差し込む窓の下でベッドの横の椅子に座る白髪の年配の女性。ピクサー スタイルのデジタル アート。
黒髪の少年がベッドに横たわり、白髪の老婦人が窓の下のベッドの横の椅子に座っており、日光が差し込んでいます。ピクサー風のデジタルアートです。

DALL-E 2 は窓、椅子、ベッドを正しく生成できることがわかりますが、生成された画像は年齢、性別、髪の特徴の組み合わせがわずかに異なります。色が混乱しています。
もう 1 つの例は、「キャプテン アメリカとアイアンマンを並べて立たせる」です。生成された結果は明らかにキャプテン アメリカとアイアンマンの特徴を持っていますが、特定の要素が異なる人物に配置されていることがわかります。 . (たとえば、アイアンマンはキャプテン・アメリカの盾をかぶっています)。

前景や背景が特に細かい場合、モデルが生成されない場合があります。
たとえば、入力テキストは次のとおりです:
2 匹の犬は、スパイグラスを通してニューヨーク市を眺めている海賊船上のローマの兵士のような服装をしています。 2 匹の犬 犬は海賊船に乗ったローマ兵のように小型望遠鏡を通してニューヨーク市を眺めています。
今回は、DALL-E 2 が動作を停止しました。ブログの著者は 30 分ほど費やしましたが、原因を理解できませんでした。最終的には、「ニューヨーク市と海賊船」でプレイする必要がありました。 」または「望遠鏡を持った犬とローマ兵の制服」のどちらかを選択してください。
Dall-E 2 は、都市や図書館の本棚などの一般的な背景を使用して画像を生成できますが、それが画像の主な焦点ではない場合、より詳細な詳細を取得することは非常に困難になることがよくあります。
DALL-E 2 はさまざまな高級椅子などの一般的なオブジェクトを生成できますが、「アルト自転車」を生成するように依頼すると、結果として得られる画像は自転車に多少似ていますが、完全にではありません。
Google画像検索でのOtto Bicycleの検索は以下の通りです。
# と書かせるなど、まったくの偶然で単語を正しくスペルできることがあります。 . ##モデルは実際にいくつかの「認識可能な」英語文字を生成できますが、接続されたセマンティクスは期待される単語とは依然として異なります。これが、DALL-E 2 が第一世代の DALL-E ほど優れていない点です。 
DALL-E 2 は楽器に関連した画像を生成する際、演奏中の人間の手の位置を記憶しているようですが、弦がないと演奏は少しぎこちないです。

DALL-E 2 には編集機能もあります。たとえば、画像を生成した後、カーソルを使用してその領域を強調表示し、変更の完全な説明を追加できます。 。
しかし、この機能は常に効果があるわけではなく、例えば元の画像に「ショートヘア」を追加したい場合、編集機能では必ず変な場所に何かが追加されてしまいます。 
# テクノロジーはまだ更新および開発されており、DALL-E 3 を楽しみにしています。

以上がハーバード大学は大混乱:DALL-E 2 は単なる「接着モンスター」であり、その生成精度はわずか 22%の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。