
ホームページ >テクノロジー周辺機器 >AI >GPT3 と Google PaLM を完全に破壊します!検索強化モデル Atlas が知識ベースの小規模サンプル タスクを更新 SOTA
GPT3 と Google PaLM を完全に破壊します!検索強化モデル Atlas が知識ベースの小規模サンプル タスクを更新 SOTA

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-15 15:04:031296ブラウズ
無意識のうちに、小さなサンプルを含む大規模なモデルが、小さなサンプルの学習の分野で主流のアプローチになっています。多くのタスクのコンテキストでは、最初に小さなデータ サンプルにラベルを付けてから、大規模なデータの事前トレーニングから始めるという一般的な考え方が行われます。サンプル: モデルは小さなデータ サンプルに基づいてトレーニングされます。これまで見てきたように、大規模モデルは広範囲の小規模サンプル学習タスクで驚くべき結果を達成しましたが、当然のことながら、大規模モデルに固有の欠点の一部も小規模サンプル学習にスポットライトを当てています。
小規模サンプル学習では、モデルが少数のサンプルに基づいて独立した推論を完了する能力を備えていることが期待されます。言い換えれば、理想的なモデルは、問題を解決することによって問題解決のアイデアを習得する必要があります。質問によって、あるインスタンスから別のインスタンスに推論を引き出すことができます。しかし、大規模なモデルと小さなサンプルの理想的かつ実践的な学習能力は、問題を解決するプロセスを記憶するために大規模なモデルのトレーニング中に保存された大量の情報に依存しているようです。このように勉強する学生は本当に潜在的な学生なのでしょうか?

#Meta AI によって今日紹介された論文は、新しいアプローチを採用し、検索強化手法を小規模サンプル学習の分野に適用しています。 64 の例では、Naturalquestions データセット (Naturalquestions) で 42% の精度を達成し、大規模モデル PaLM と比較してパラメータ数を 50 分の 1 (540B->11B) 削減し、解釈可能性を向上させました。制御性や更新性など、他の大型モデルにはない大きなメリットがあります。
#論文のタイトル:検索拡張言語モデルを使用した少数ショット学習論文のリンク:https://arxiv.org/pdf/2208.03299.pdf
検索の強化されたトレーサビリティの始まりこの論文では、「小規模サンプルの学習の分野では、情報を保存するために膨大な数のパラメータを使用する必要があるのでしょうか?」という質問を全員に投げかけました。大規模モデルの開発を見ると、連続した大規模モデルは引き続き作業を続けることができます。 SOTA: その理由の 1 つは、問題に必要な情報が膨大なパラメータに保存されていることです。 Transformer の誕生以来、NLP 分野では大規模モデルが主流のパラダイムとなってきましたが、徐々に大規模モデルが発展するにつれて常に「大きな」問題が露呈しており、「大きな」ことの必要性を問うことは非常に意味のあることです。論文の著者は、この質問から開始し、この質問に対して否定的な答えを与え、拡張モデルを取得する方法をとります。

当時、実際には別の方法があり、それが Cached LM でした。その中心的なアイデアは、RNN は試験室に入った直後にはそれを覚えていない可能性があるため、 RNN オープンブック試験では、トレーニング中に予測された単語をキャッシュに保存するキャッシュ メカニズムが導入されています。予測中に、クエリとキャッシュ インデックスの両方からの情報を組み合わせてタスクを完了することができ、それによって問題を解決します。当時の RNN モデルの欠点。
その結果、検索拡張技術は、パラメーター メモリ情報に依存する大規模モデルとはまったく異なる道を歩み始めました。検索強化に基づくモデルにより、さまざまなソースからの外部知識の導入が可能になり、これらの検索ソースには、トレーニング コーパス、外部データ、教師なしデータ、その他のオプションが含まれます。検索強化モデルは一般に、クエリに基づいて外部の検索ソースから関連知識を取得する取得器と、クエリと取得した関連知識を組み合わせてモデル予測を行うジェネレータで構成されます。
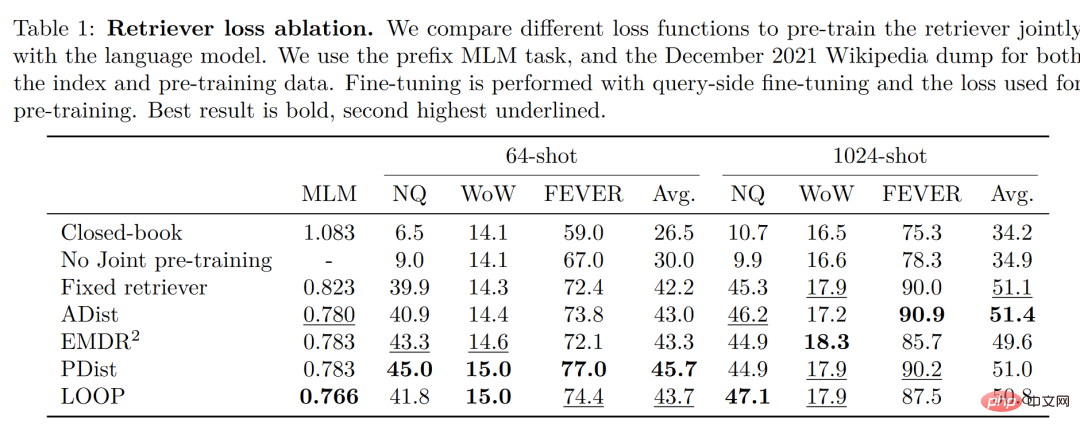
最終的な分析では、検索強化モデルの目標は、モデルがデータを記憶することを学習するだけでなく、データを自分で見つけることも学習することを期待することです。この機能には大きな利点があります。これらの分野では、多くの知識集約型タスクや検索強化モデルでも大きな成功が収められていますが、検索強化が少数ショット学習に適しているかどうかは不明です。 Meta AI のこの論文に戻ると、小規模サンプル学習における検索強化のアプリケーションのテストに成功し、Atlas が誕生しました。 Atlas には、レトリーバー モデルと言語モデルという 2 つのサブモデルがあります。タスクに直面すると、Atlas はサーチャーを使用して、入力された質問に基づいて大量のコーパスから最も関連性の高い上位 k 個のドキュメントを生成し、これらのドキュメントを質問クエリとともに言語モデルに入れて、必要な出力を生成します。 。 #Atlas モデルの基本的なトレーニング戦略は、同じ損失関数を使用してレトリーバーと言語モデルを共同でトレーニングすることです。レトリーバーと言語モデルは両方とも、事前トレーニングされた Transformer ネットワークに基づいています。 著者が 4 つの損失関数と、レトリーバーと言語モデルの共同トレーニングを行わない状況を比較およびテストしたことは注目に値します。結果は次のとおりです。 実験結果
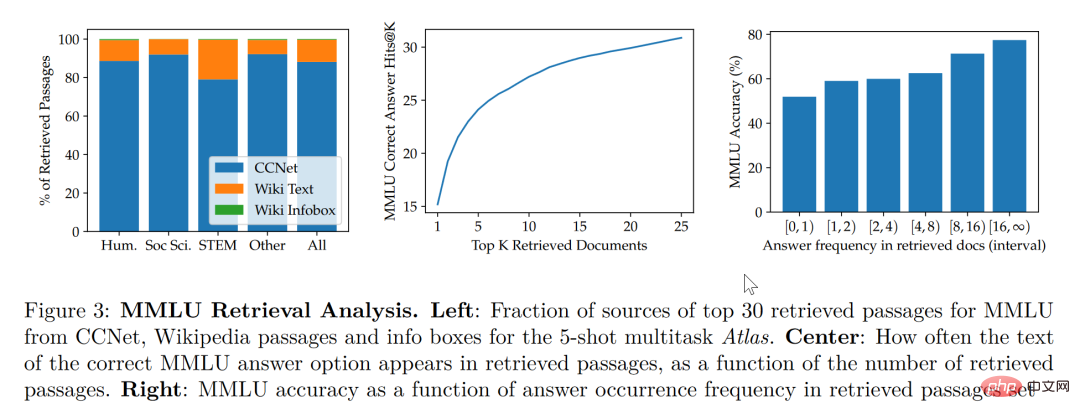
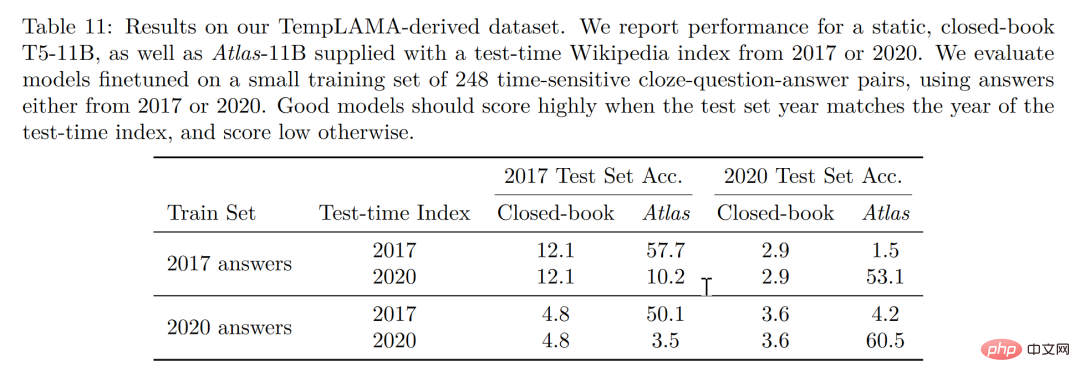
この論文の研究によると、検索拡張モデルは、より小さくより良いものだけでなく、解釈可能性の観点からも考慮されています。 、他の大型モデルにはない大きな利点もあります。大規模モデルはブラックボックスであるため、研究者が大規模モデルを使ってモデルの動作メカニズムを解析することは困難ですが、検索強化モデルでは検索された文書を直接抽出できるため、検索で得られた論文を解析することで、アトラスの仕事についての洞察を得ることができ、より深く理解できるようになります。たとえば、論文では、抽象代数の分野ではモデルのコーパスの 73% が Wikipedia に依存していることが判明しましたが、倫理関連の分野では、検索者が抽出した文書のうち Wikipedia からのものはわずか 3% であり、これは人間の知識と一致しています。直感。以下の図の左側の統計グラフに示されているように、モデルは CCNet データの使用を優先していますが、数式や推論に重点を置く STEM 分野では、Wikipedia 記事の使用率が大幅に増加しています。 上図の右側の統計グラフによると、正解を含む検索記事の数が増加するにつれて、モデルの精度が向上 正解率も上昇 記事に答えが含まれていない場合、正解率は 55% にとどまりますが、答えが 15 回以上言及されると、正解率は 77% に達します。さらに、50 の検索エンジンで検索された文書を手動で検査したところ、そのうちの 44% に有用な背景情報が含まれていることがわかりました。問題に関する背景情報を含むこれらの文書は、研究者に読みを広げる大きな機会を提供できることは明らかです。 一般的に、大規模なモデルにはトレーニング データの「漏洩」のリスクがあると考えられがちです。つまり、テストの質問に対する大規模なモデルの答えが、モデルの記憶能力は、大規模モデルで学習された大量のコーパスの中にテスト問題の答えが漏れていることを意味します。この論文では、著者が手動でコーパスを削除した後、情報漏洩の可能性がある場合、モデル精度は56.4%から低下し、わずか0.6%の低下で55.8%となり、検索強化手法によりモデル不正行為のリスクを効果的に回避できることがわかります。 最後に、更新可能性も検索強化モデルの独自の利点です。検索強化モデルは、再トレーニングせずに随時更新できますが、依存するコーパスを更新または置換することによってのみ可能です。の上。アトラスパラメータを更新せずに下図のような時系列データセットを構築したところ、2020年のコーパスアトラスだけで53.1%の精度を達成できました。 T5、T5もあまりパフォーマンスが良くありませんでしたが、その原因はT5の事前学習に使用したデータが2020年以前のデータであることが大きいと著者は考えています。 生徒が 3 人いて、1 人の生徒が暗記だけに頼っていると想像できます。問題を解決するために暗記する必要があります。数学の問題の答えは正確に暗唱できます。ある生徒は本を調べることに頼っています。問題に遭遇したとき、彼は最初に情報を検索して最適なものを見つけてから、次の方法で答えようとはしません。最後の生徒は才能があり賢く、簡単に学ぶことができるので、教科書である程度の知識があれば、自信を持って試験場に行って指示を与えることができます。 小規模サンプル学習の理想は 3 番目の生徒になることですが、現実は最初の生徒を上回る可能性が高くなります。大規模なモデルは使いやすいですが、「大きい」ことがモデルの最終目標ではありません。小規模なサンプル学習の本来の目的に立ち返って、モデルに人間と同様の推論判断と推論能力を期待すると、この論文は別の視点からのものであることがわかります。少なくとも、生徒が潜在的に冗長な知識を頭の中にあまりロードせず、教科書を手に取り、おそらく、学生が継続的に復習するために教科書を使ってオープンブック試験を受けることさえ許可すれば、学生が丸暗記するよりも知性に近づくことになるでしょう。 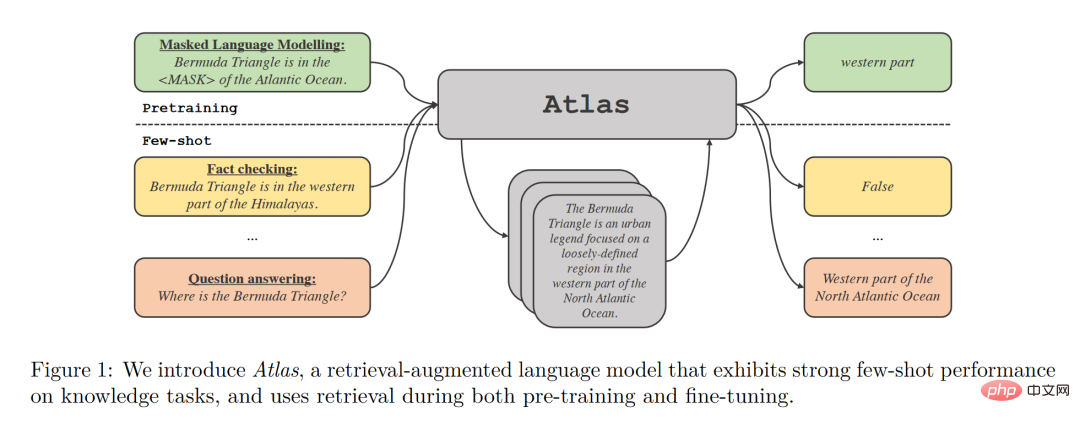
モデル構造

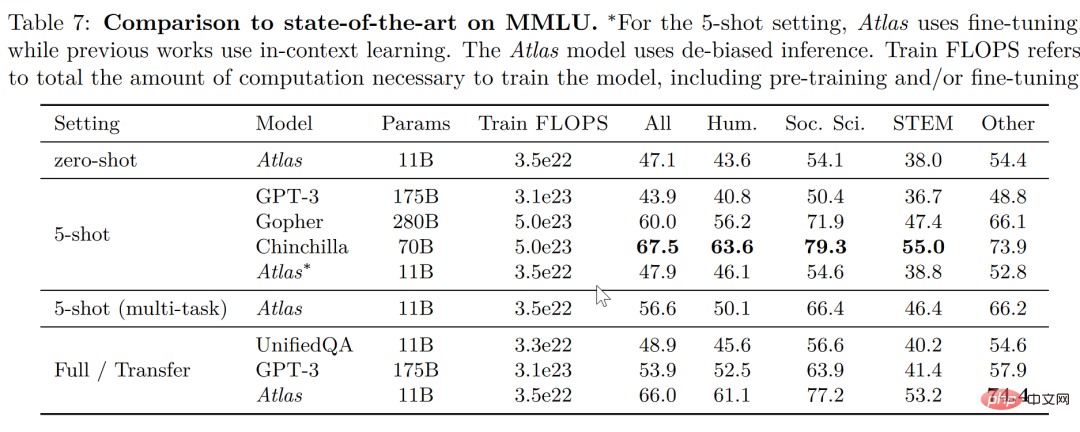
大規模マルチタスク言語理解タスク (MMLU) では、他のモデルと比較して、Atlas は 11B しかありませんこの場合、Atlas の 15 倍のパラメータ数を持つ GPT-3 よりも正解率が高く、マルチタスク トレーニングの導入後、5 ショット テストの正解率は Atlas の 15 倍に近くなります。 Gopher のパラメータは Atlas の 25 倍です。
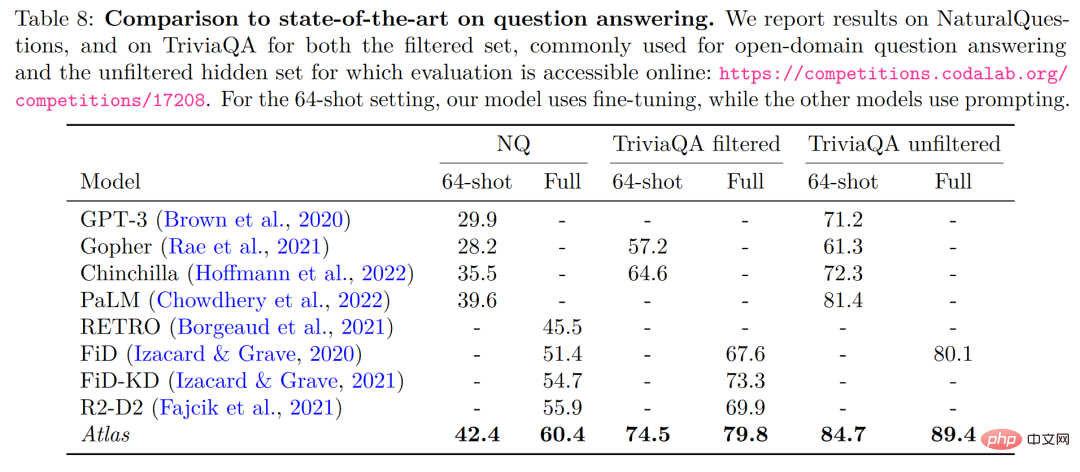

解釈可能性、制御可能性、更新可能性
#結論

以上がGPT3 と Google PaLM を完全に破壊します!検索強化モデル Atlas が知識ベースの小規模サンプル タスクを更新 SOTAの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。