
ホームページ >テクノロジー周辺機器 >AI >Google、オープンソース ソフトウェア ライブラリで n 次元データの保存と操作の問題を解決
Google、オープンソース ソフトウェア ライブラリで n 次元データの保存と操作の問題を解決

- 王林転載
- 2023-04-15 10:52:051619ブラウズ
コンピューター サイエンスや機械学習 (ML) の多くのアプリケーションでは、座標系にまたがる多次元データ セットの処理が必要であり、単一のデータ セットにテラバイトまたはペタバイトのデータを保存する必要がある場合もあります。一方で、ユーザーは不規則な間隔や異なるスケールでデータを読み書きし、大量の並列作業を実行することが多いため、このようなデータセットの操作も困難です。
上記の問題を解決するために、Google は、n 次元データを保存および操作するために設計されたオープンソースの C および Python ソフトウェア ライブラリである TensorStore を開発しました。 Google AIの責任者であるJeff Dean氏も、TensorStoreが正式にオープンソースになったとツイートした。
TensorStore の主な機能は次のとおりです。
- 読み取りと読み取りのための統合 API を提供します。 zarr や N5 などの複数の配列形式の書き込み;
- Google Cloud Storage、ローカルおよびネットワーク ファイル システム、HTTP サーバー、メモリ ストレージなどの複数のストレージ システムのネイティブ サポート;
- 強力なアトミック性、分離性、一貫性、耐久性 (ACID) 特性を備えた読み取り/書き込みキャッシュとトランザクションをサポートします。
- スレーブの安全で効率的な同時アクセスをサポートします。複数のプロセスやマシンから;
- 非同期 API を提供して、高遅延のリモート ストレージへの高スループット アクセスを実現します。
- 高度な、完全に構成可能なインデックス操作と仮想ビュー。
TensorStore は、科学計算におけるエンジニアリングの課題を解決するために使用されており、分散トレーニング中の PaLM モデルの管理など、大規模な機械学習モデルの作成にも使用されています。 )。
GitHub アドレス: https://github.com/google/tensorstore
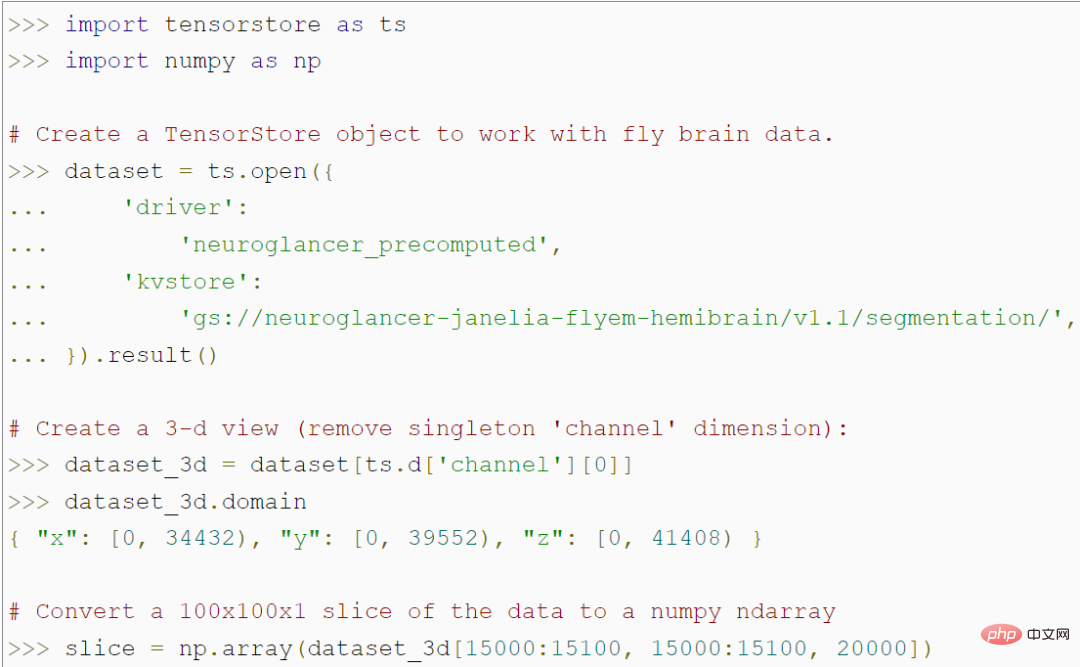
APIデータ アクセスと操作用TensorStore は、大規模な配列データのロードと操作のためのシンプルな Python API を提供します。たとえば、次のコードは、ハエの脳の 56 兆ボクセル 3D 画像を表す TensorStore オブジェクトを作成し、NumPy 配列内の 100x100 画像パッチ データへのアクセスを許可します。 #このプログラムは、特定の 100x100 パッチにアクセスするまではメモリ内の実際のデータにアクセスしないため、データ セット全体を変換することなく、任意の大きな基になるデータ セットをロードして操作できることに注目してください。メモリに保存されます。 TensorStore は、標準の NumPy と基本的に同じインデックス作成および操作構文を使用します。
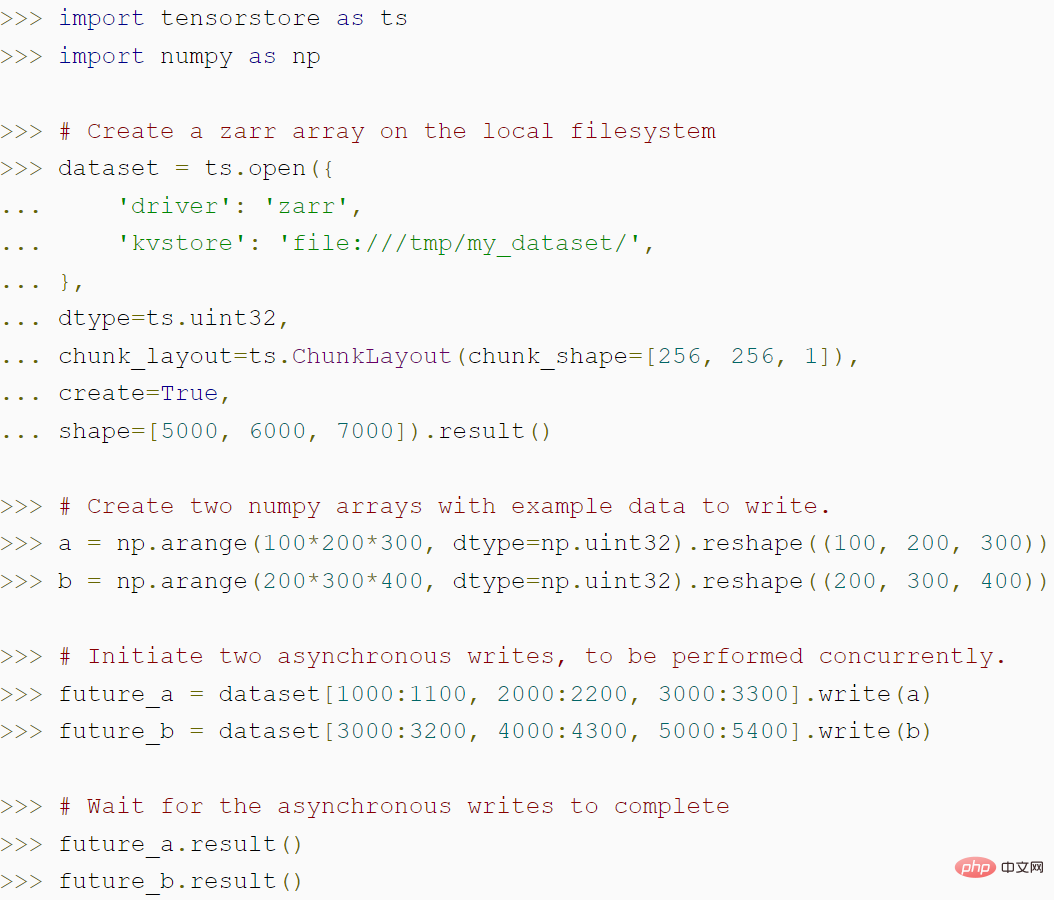
次のコードは、TensorStore を使用して zarr 配列を作成する方法と、TensorStore の非同期 API がどのようにしてより高いスループットを達成できるかを示します。
#セキュリティとパフォーマンスの拡張機能
大規模なデータ セットの分析と処理には大規模なコンピューティング リソースが必要であり、多くの場合、複数のマシンに分散された CPU またはアクセラレータ コアの並列化が必要になることはよく知られています。したがって、TensorStore の基本的な目標は、並列処理を実装して安全性と高性能の両方を実現することです。実際、Google データセンターでのテストでは、CPU の数が増加するにつれて、TensorStore の読み取りおよび書き込みパフォーマンスがほぼ直線的に向上することがわかりました。
#Google Cloud Storage (GCS) 上の zarr 形式のデータ セットの読み取りおよび書き込みパフォーマンスに関しては、読み取りおよび書き込みパフォーマンスはコンピューティング タスクの数に応じてほぼ直線的に増加します。
TensorStore は、プログラムが他の作業を完了している間、バックグラウンドで読み取りおよび書き込み操作を継続できるようにする、構成可能なメモリ キャッシュと非同期 API も提供します。 TensorStore の分散コンピューティングをデータ処理ワークフローと互換性のあるものにするために、Google は TensorStore を Apache Beam などの並列コンピューティング ライブラリと統合します。 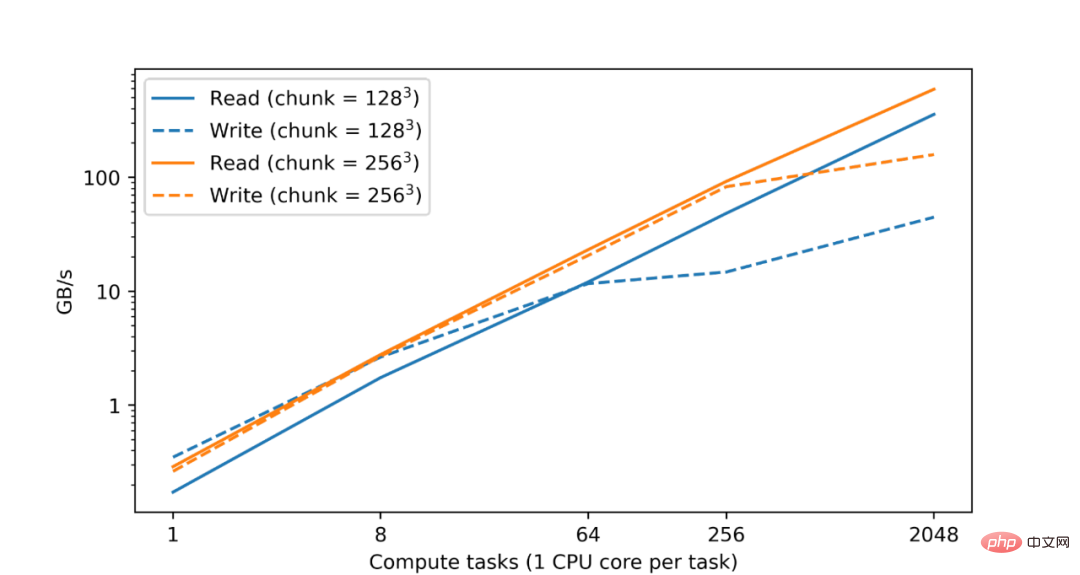
表示例
例 1 言語モデル: 最近、PaLM などの高度な言語モデルが機械学習の分野に登場しています。これらのモデルには数千億のパラメータが含まれており、自然言語の理解と生成において驚くべき能力を発揮します。ただし、これらのモデルはコンピューティング機能に課題をもたらし、特に PaLM のような言語モデルをトレーニングするには、数千の TPU を並行して動作させる必要があります。
モデル パラメーターの効率的な読み取りと書き込みは、トレーニング プロセスで直面する問題です。たとえば、トレーニングはさまざまなマシンに分散されますが、パラメーターは定期的にチェックポイントに保存する必要があります。別の例としては、モデル パラメーター セット全体 (数百 GB になる可能性がある) を読み込むために必要なオーバーヘッドを避けるために、1 つのトレーニングでは特定のパラメーター セットのみを読み取る必要があります。
TensorStore は上記の問題を解決できます。これは、大規模な (マルチポッド) モデルに関連するチェックポイントを管理するために使用され、T5X や Pathways などのフレームワークと統合されています。 TensorStore は、チェックポイントを zarr 形式のストレージに変換し、各 TPU のパーティションが並列かつ独立して読み書きできるようにブロック構造を選択します。

#チェックポイントを保存するとき、パラメーターは zarr 形式で書き込まれます。ブロックネットワーク ラティスは、TPU 上のパラメータ メッシュのためにさらに分割されます。ホストは、ホストの TPU に割り当てられた各パーティションに対して zarr ブロックを並行して書き込みます。 TensorStore の非同期 API を使用すると、データが永続ストレージに書き込まれている間でもトレーニングが続行されます。チェックポイントから回復するとき、各ホストは、そのホストに割り当てられたパーティション ブロックのみを読み取ります。
例 2 脳 3D マッピング: シナプス分解コネクトミクス 目標は、動物と人間の脳の配線を個々のシナプス接続のレベルでマッピングすることです。これを達成するには、ミリメートル以上の視野にわたって非常に高い解像度 (ナノスケール) で脳を画像化する必要があり、結果としてデータ量はペタバイトになります。しかし、現在でも、データセットはストレージや処理などの問題に直面しています。単一の脳サンプルですら、数百万ギガバイトのスペースを必要とする場合があります。
Google は TensorStore を使用して、大規模なコネクトミクス データセットに関連する計算上の課題を解決しました。具体的には、TensorStore は一部のコネクトミクス データセットの管理を開始し、基盤となるオブジェクト ストレージ システムとして Google Cloud Storage を使用します。
現在、人間の大脳皮質データセット H01 には TensorStore が使用されており、元の画像データは 1.4 PB (約 500000 * 350000 * 5000 ピクセル) です。次に、生データは 128x128x16 ピクセルの独立したブロックに分割され、「Neuroglancer precomputed」形式で保存され、TensorStore で簡単に操作できます。

TensorStore を使用すると、基になるデータに簡単にアクセスして操作できます (ハエの脳の再構築) ##これから始めたい人は、次の方法を使用して TensorStore PyPI パッケージをインストールできます:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">tensorstore</span>
以上がGoogle、オープンソース ソフトウェア ライブラリで n 次元データの保存と操作の問題を解決の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。