
OpenAI と Microsoft Sentinel パート 3: DaVinci と Turbo

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-14 21:28:011728ブラウズ
OpenAI の大規模言語モデル (LLM) と Microsoft Sentinel に関するシリーズへようこそ。最初のパートでは、OpenAI と Sentinel の組み込み Azure Logic Apps コネクタを使用して基本的なプレイブックを構築し、イベントで見つかった MITRE ATT&CK 戦術を説明し、温度や温度など、OpenAI モデルに影響を与える可能性のあるさまざまなパラメーターのいくつかについて説明しました。周波数を罰する。次に、Sentinel の REST API を使用してこの機能を拡張し、スケジュールされた分析ルールを検索し、ルール検出ロジックの概要を返します。
注意を払っている方は、最初のプレイブックでは Sentinel イベントから MITRE ATT&CK 戦術を探していますが、GPT3 ヒントにはイベント テクニックがまったく含まれていないことに気づいたかもしれません。なぜだめですか?さて、OpenAI API Playground を起動して、ウサギの穴への旅に出かけましょう (ルイス キャロルには申し訳ありませんが)。
- モード: 完了
- モデル: text-davinci-003
- 温度: 1
- 最大長: 500
- 最大 P: 1
- 頻度ペナルティ: 0
- 存在ペナルティ: 0
- ヒント: 「次の MITRE ATT&CK 戦術とテクニックについて説明してください: ["防御回避"]、[ " T1564"]"
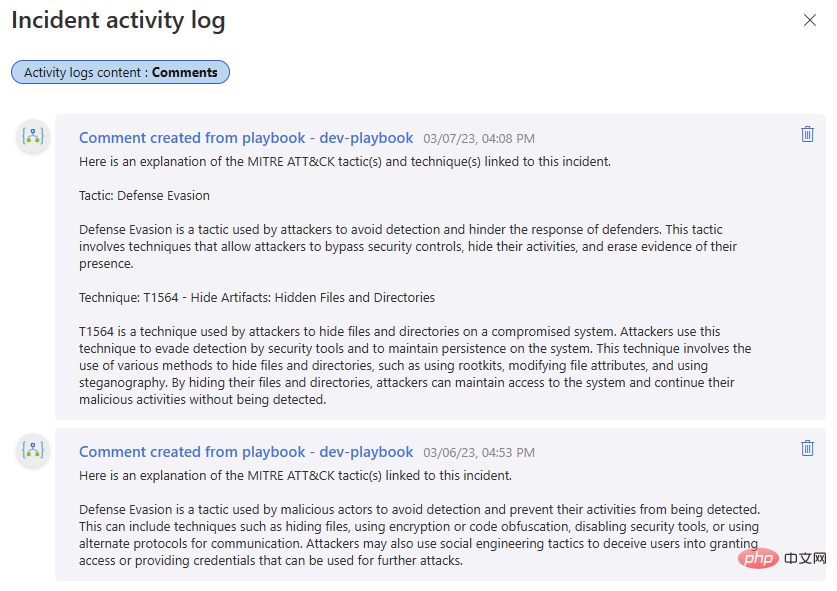
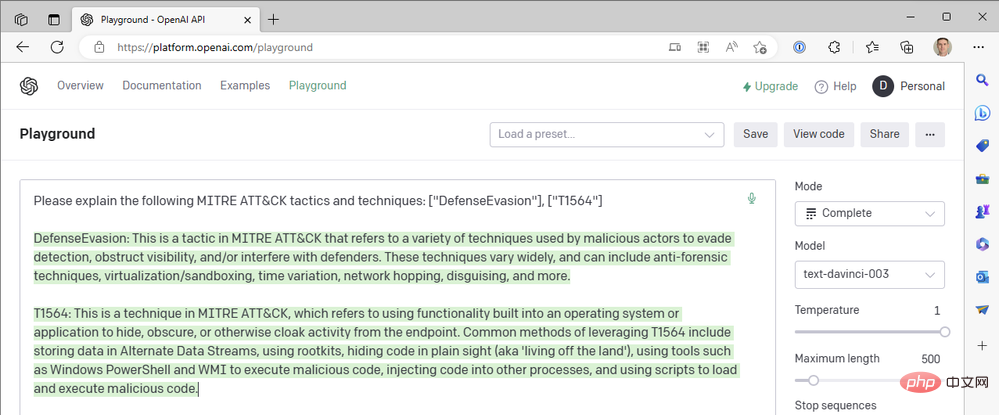 ##これは MITRE ATT&CK 戦術 TA0005、防御回避の優れた概要に対する素晴らしい回答です。しかし、技術的な説明はどうでしょうか? T1564 は、他の名前付きテクニックの中でも特に、アーティファクトの非表示 - プロセス インジェクション (T1055) およびルートキット (T1014) です。もう一度試してみましょう。
##これは MITRE ATT&CK 戦術 TA0005、防御回避の優れた概要に対する素晴らしい回答です。しかし、技術的な説明はどうでしょうか? T1564 は、他の名前付きテクニックの中でも特に、アーティファクトの非表示 - プロセス インジェクション (T1055) およびルートキット (T1014) です。もう一度試してみましょう。
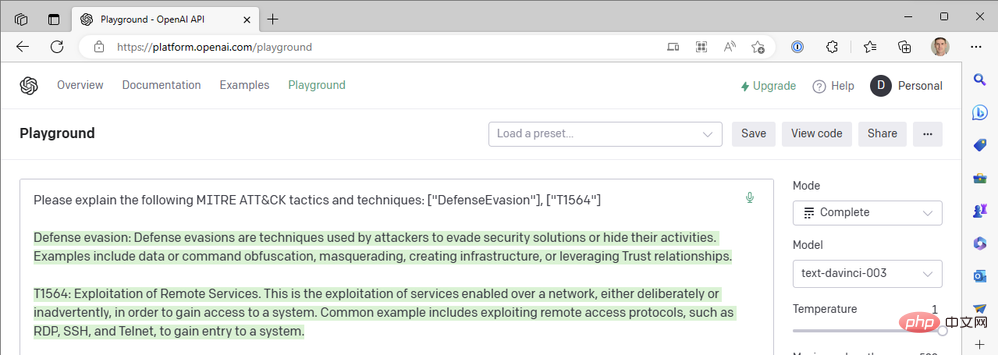 それは程遠い! 「リモート サービスの悪用」は、ラテラル ムーブメント戦略におけるテクニック T1210 です。もう一度言います:
それは程遠い! 「リモート サービスの悪用」は、ラテラル ムーブメント戦略におけるテクニック T1210 です。もう一度言います:
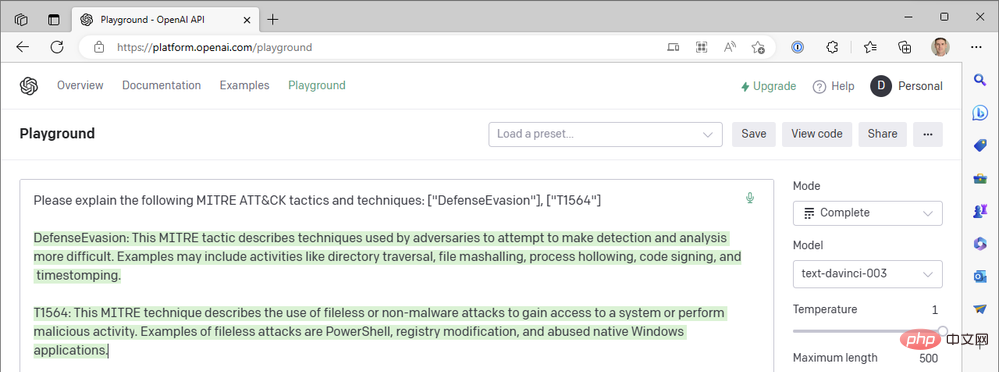 # それで何が起こったのでしょうか? ChatGPT の方が優れているのではないでしょうか? ! ######はい、そうです。 ChatGPT は MITRE ATT&CK 技術コードをうまく要約していますが、それについてはまだ尋ねていません。私たちは、OpenAI のもう 1 つのトップレベル生成事前トレーニング済み Transformer-3.5 (GPT-3.5) モデル「text-davinci-003」をテキスト補完モードで使用してきました。 ChatGPT は、チャット完了モードで「gpt-3.5-turbo」モデルを使用します。大きな違い。上記と同じクエリに対する ChatGPT の応答の例を次に示します。
# それで何が起こったのでしょうか? ChatGPT の方が優れているのではないでしょうか? ! ######はい、そうです。 ChatGPT は MITRE ATT&CK 技術コードをうまく要約していますが、それについてはまだ尋ねていません。私たちは、OpenAI のもう 1 つのトップレベル生成事前トレーニング済み Transformer-3.5 (GPT-3.5) モデル「text-davinci-003」をテキスト補完モードで使用してきました。 ChatGPT は、チャット完了モードで「gpt-3.5-turbo」モデルを使用します。大きな違い。上記と同じクエリに対する ChatGPT の応答の例を次に示します。
#しかし、Azure Logic App の OpenAI コネクタではチャットベースのアクションが提供されず、 Turbo モデルのオプションがない場合、ChatGPT を Sentinel ワークフローに導入するにはどうすればよいでしょうか?パート II で Sentinel Logic App Connector を閉じて Sentinel REST API の HTTP 操作を直接呼び出したのと同じように、OpenAI の API を使用して同じことを行うことができます。テキスト補完モデルの代わりにチャット モデルを使用する Logic Apps ワークフローを構築するプロセスを見てみましょう。
OpenAI の 2 つの参考ドキュメント、「チャット作成 API リファレンス」と「チャット完了ガイド」を参照します。このブログ投稿を適切な長さに保つために、独自の環境でこの例を再現するために必要なセットアップ タスクのいくつかを要約します。
##ロジック アプリが Key Vault Access に接続できるようにするネットワーク (私は(コネクタ ドキュメント内の適切な Azure リージョンに定義された IP アドレスと CIDR 範囲)
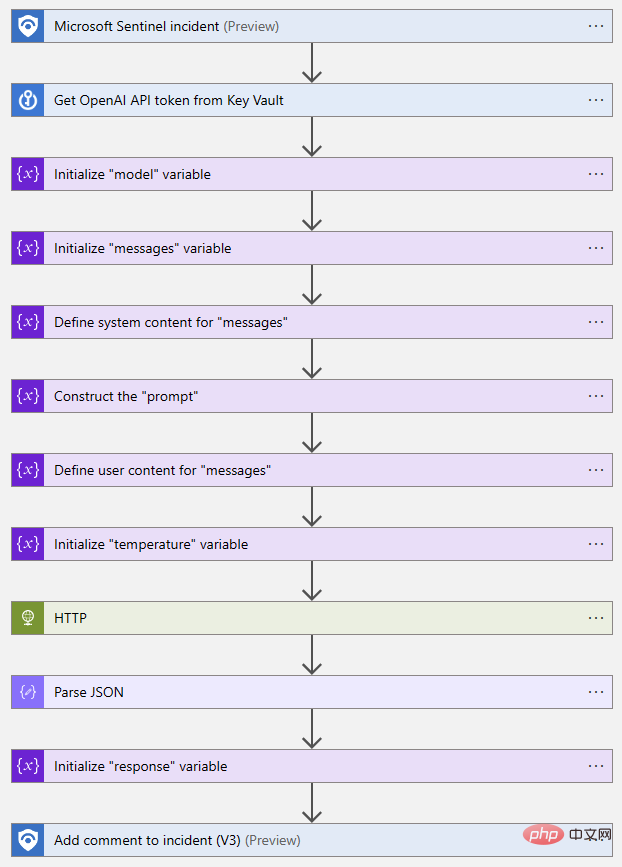
- 次に、Logic Apps デザイナーを開いて、機能の構築を開始しましょう。以前と同様に、Microsoft Sentinel イベント トリガーを使用しています。この後、Key Vault 操作「シークレットの取得」を実行します。この操作では、API キーが保存されているシークレット名を指定します。
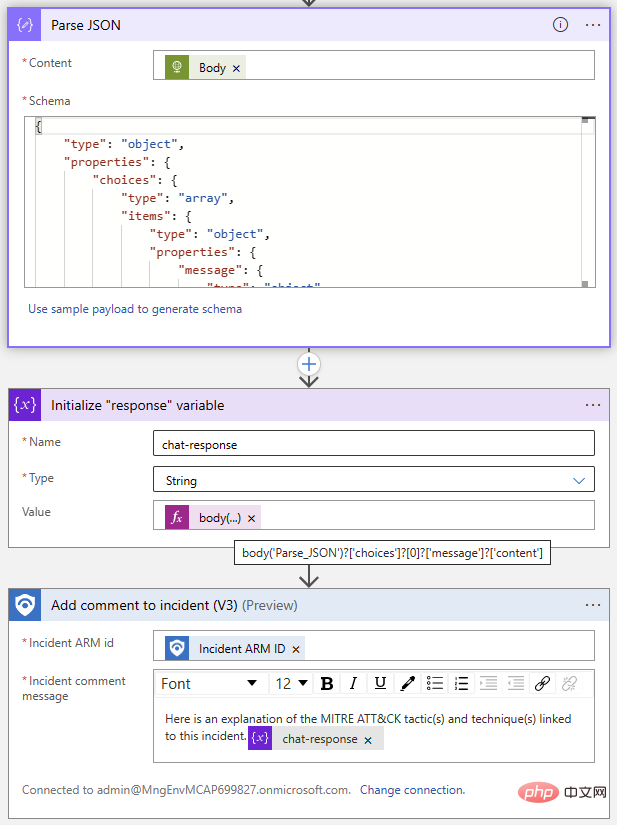
- #次に、次のことを行う必要があります。 API リクエストを作成し、いくつかの変数を初期化して設定します。これは厳密には必要ではありません。単純に HTTP アクションにリクエストを書き出すこともできますが、後でプロンプトやその他のパラメーターを変更するのがはるかに簡単になります。 OpenAI Chat API 呼び出しに必要な 2 つのパラメーターは「モデル」と「メッセージ」です。そのため、モデル名を格納する文字列変数とメッセージの配列変数を初期化しましょう。
「メッセージ」パラメータは、チャット モデルへの主な入力です。これは、「システム」や「ユーザー」などの役割とコンテンツをそれぞれ持つメッセージ オブジェクトのセットとして構築されます。 Playground の例を見てみましょう:
System オブジェクトを使用すると、このチャット セッションの AI モデルの動作コンテキストを設定できます。 User オブジェクトが質問であり、モデルは Assistant オブジェクトで応答します。必要に応じて、ユーザー オブジェクトとアシスタント オブジェクトに以前の応答を含めて、AI モデルに「会話履歴」を提供できます。
ロジック アプリ デザイナーに戻り、2 つの「配列変数に追加」アクションと 1 つの「変数の初期化」アクションを使用して、「メッセージ」配列を構築しました。
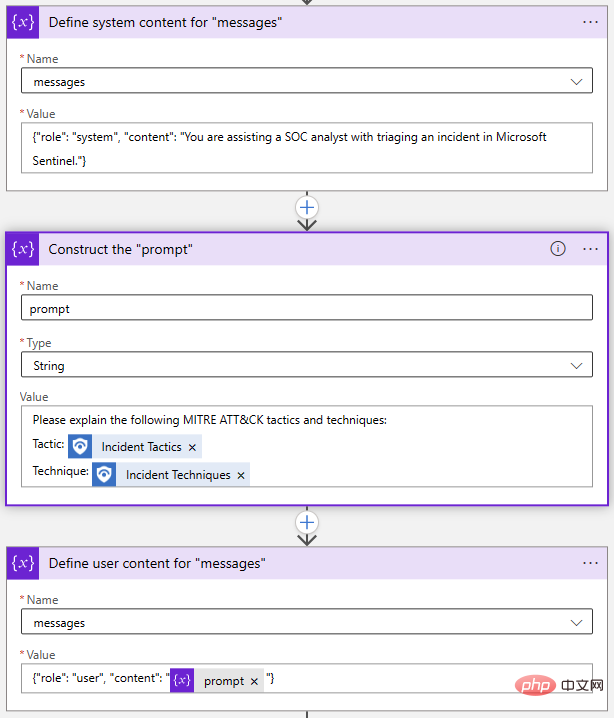
繰り返しますが、これはすべて 1 つのステップで実行できますが、各オブジェクトを個別に分解することにしました。プロンプトを変更したい場合は、Prompt 変数を更新するだけです。
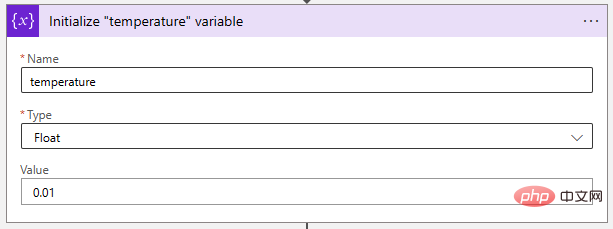
次に、温度パラメーターを非常に低い値に調整して、AI モデルをより決定論的にしましょう。 「浮動小数点」変数は、この値を保存するのに最適です。
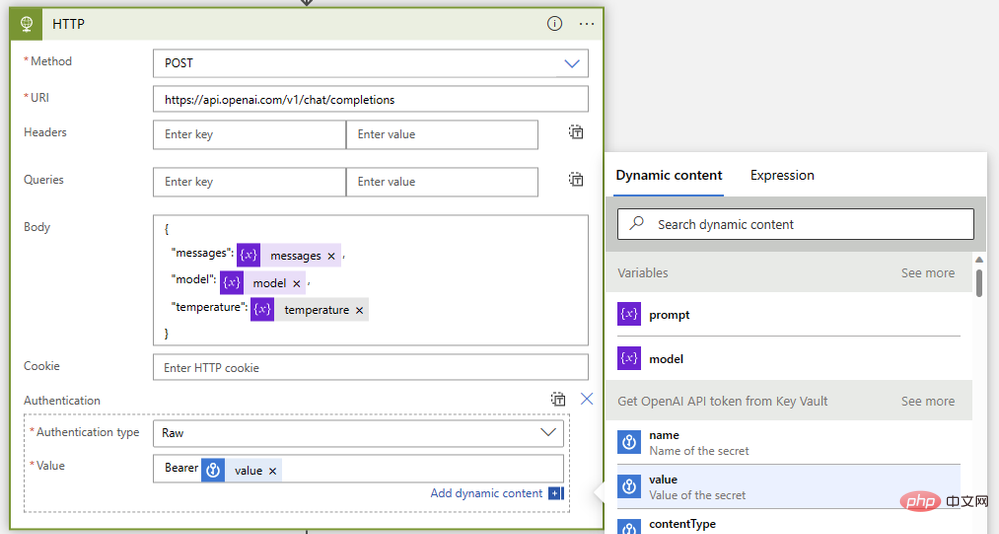
- Method: Mail
- Type: https: //api.openai.com/v1/chat/completions
- 本文:
{"model": @{variables('model')},"messages": @{variables('messages')},"temperature": @{variables('temperature')}} - 認証: オリジナル
- 値:
Bearer @{body('Get_OpenAI_API_token_from_Key_Vault')?['value']}
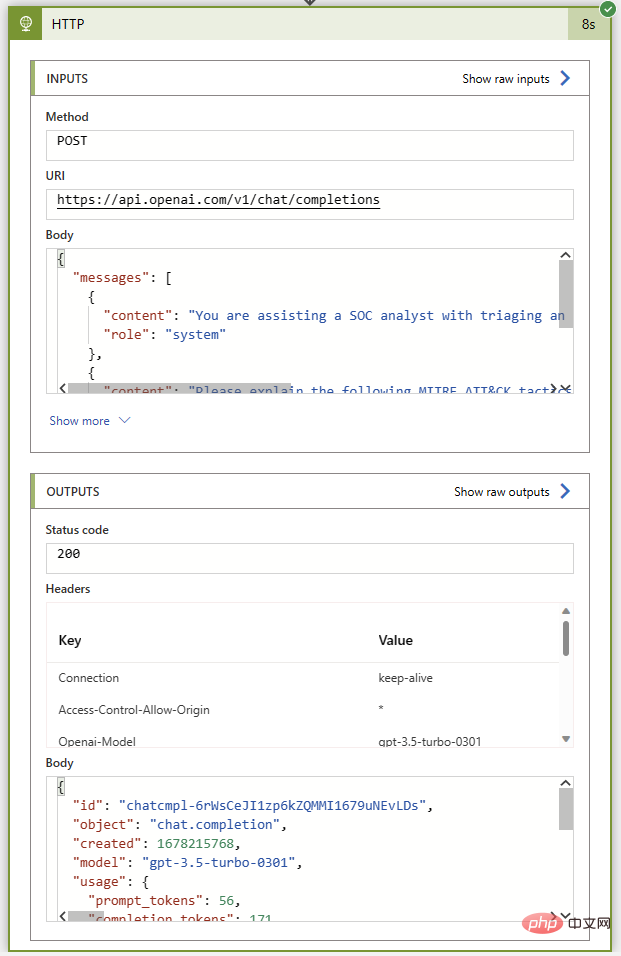
@{body('Parse_JSON')?['choices']?[0]?['message']?['content']}
以上がOpenAI と Microsoft Sentinel パート 3: DaVinci と Turboの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。