



ドキュメントの解析には、ドキュメント内のデータを調べて有用な情報を抽出することが含まれます。自動化により多くの手作業を削減できます。一般的な解析戦略は、文書を画像に変換し、認識にコンピューター ビジョンを使用することです。文書画像分析とは、文書の画像のピクセル データから情報を取得するテクノロジーを指しますが、場合によっては、期待される結果 (テキスト、画像、グラフ、数値、表、数式) について明確な答えがない場合があります。 ..)。

OCR (光学式文字認識) は、コンピューター ビジョンを通じて画像内のテキストを検出および抽出するプロセスです。第一次世界大戦中にイスラエルの科学者エマニュエル・ゴールドバーグが文字を読み取って電信コードに変換できる機械を開発したときに発明されました。現在この分野は、画像処理、テキストローカリゼーション、文字セグメンテーション、文字認識を組み合わせた非常に洗練されたレベルに達しています。基本的にはテキストのオブジェクト検出技術です。
この記事では、OCR を使用してドキュメントを解析する方法を説明します。他の同様の状況で簡単に使用できる (コピー、貼り付け、実行するだけ) 便利な Python コードをいくつか紹介し、完全なソース コードのダウンロードも提供します。
ここでは、上場企業のPDF形式の財務諸表を例に挙げます(下記リンク)。

- ドキュメントをテキストとして処理します。テキストの抽出には PyPDF2 を使用し、表の抽出には Camelot または TabulaPy を使用し、グラフィックの抽出には PyMuPDF を使用します。
- ドキュメントを画像に変換 (OCR): 変換には pdf2image を使用し、データの抽出には PyTesseract やその他の多くのライブラリを使用するか、単に LayoutParser を使用します。
# with pip pip install python-poppler # with conda conda install -c conda-forge popplerファイルは簡単に読み取ることができます:
# READ AS IMAGE
import pdf2imagedoc = pdf2image.convert_from_path("doc_apple.pdf")
len(doc) #<-- check num pages
doc[0] #<-- visualize a page これはスクリーンショットとまったく同じです。ページの画像をローカルに保存したい場合は、次のコードを使用できます:
# Save imgs import osfolder = "doc" if folder not in os.listdir(): os.makedirs(folder)p = 1 for page in doc: image_name = "page_"+str(p)+".jpg" page.save(os.path.join(folder, image_name), "JPEG") p = p+1最後に、使用する CV エンジンをセットアップする必要があります。 LayoutParser は、深層学習に基づく OCR の最初の汎用パッケージと思われます。タスクを完了するために 2 つのよく知られたモデルを使用します:
pip install layoutparser torchvision && pip install "git+https://github.com/facebookresearch/detectron2.git@v0.5#egg=detectron2"Tesseract: 最も有名な OCR システムは 1985 年に Hewlett-Packard によって作成され、現在は Google によって開発されています。
pip install "layoutparser[ocr]"これで、情報の検出と抽出のための OCR プログラムを開始する準備が整いました。
import layoutparser as lp import cv2 import numpy as np import io import pandas as pd import matplotlib.pyplot as plt検出
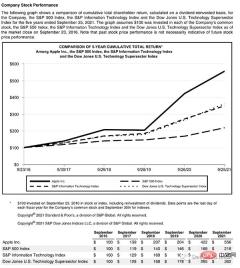 #このページはタイトルで始まり、テキスト ブロック、次に図と表があるため、これらのオブジェクトを認識するにはトレーニングされたモデルが必要です。幸いなことに、Detectron はこれを行うことができます。ここからモデルを選択し、コードでそのパスを指定するだけです。
#このページはタイトルで始まり、テキスト ブロック、次に図と表があるため、これらのオブジェクトを認識するにはトレーニングされたモデルが必要です。幸いなことに、Detectron はこれを行うことができます。ここからモデルを選択し、コードでそのパスを指定するだけです。
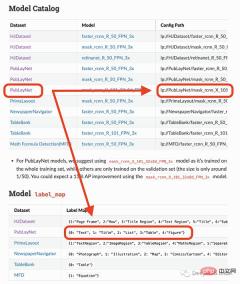 #私が使用しようとしているモデルは、4 つのオブジェクト (テキスト、タイトル、リスト、表、グラフ) のみを検出できます。したがって、他のもの (方程式など) を識別する必要がある場合は、他のモデルを使用する必要があります。
#私が使用しようとしているモデルは、4 つのオブジェクト (テキスト、タイトル、リスト、表、グラフ) のみを検出できます。したがって、他のもの (方程式など) を識別する必要がある場合は、他のモデルを使用する必要があります。
## load pre-trained model
model = lp.Detectron2LayoutModel(
"lp://PubLayNet/mask_rcnn_X_101_32x8d_FPN_3x/config",
extra_config=["MODEL.ROI_HEADS.SCORE_THRESH_TEST", 0.8],
label_map={0:"Text", 1:"Title", 2:"List", 3:"Table", 4:"Figure"})
## turn img into array
i = 21
img = np.asarray(doc[i])
## predict
detected = model.detect(img)
## plot
lp.draw_box(img, detected, box_width=5, box_alpha=0.2,
show_element_type=True)
结果包含每个检测到的布局的细节,例如边界框的坐标。根据页面上显示的顺序对输出进行排序是很有用的:
## sort
new_detected = detected.sort(key=lambda x: x.coordinates[1])
## assign ids
detected = lp.Layout([block.set(id=idx) for idx,block in
enumerate(new_detected)])## check
for block in detected:
print("---", str(block.id)+":", block.type, "---")
print(block, end='nn')
完成OCR的下一步是正确提取检测到内容中的有用信息。
提取
我们已经对图像完成了分割,然后就需要使用另外一个模型处理分段的图像,并将提取的输出保存到字典中。
由于有不同类型的输出(文本,标题,图形,表格),所以这里准备了一个函数用来显示结果。
'''
{'0-Title': '...',
'1-Text': '...',
'2-Figure': array([[ [0,0,0], ...]]),
'3-Table': pd.DataFrame,
}
'''
def parse_doc(dic):
for k,v in dic.items():
if "Title" in k:
print('x1b[1;31m'+ v +'x1b[0m')
elif "Figure" in k:
plt.figure(figsize=(10,5))
plt.imshow(v)
plt.show()
else:
print(v)
print(" ")首先看看文字:
# load model
model = lp.TesseractAgent(languages='eng')
dic_predicted = {}
for block in [block for block in detected if block.type in ["Title","Text"]]:
## segmentation
segmented = block.pad(left=15, right=15, top=5,
bottom=5).crop_image(img)
## extraction
extracted = model.detect(segmented)
## save
dic_predicted[str(block.id)+"-"+block.type] =
extracted.replace('n',' ').strip()
# check
parse_doc(dic_predicted)
再看看图形报表
for block in [block for block in detected if block.type == "Figure"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## save dic_predicted[str(block.id)+"-"+block.type] = segmented # check parse_doc(dic_predicted)
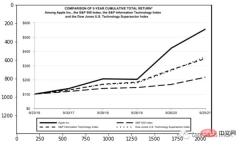
上面两个看着很不错,那是因为这两种类型相对简单,但是表格就要复杂得多。尤其是我们上看看到的的这个,因为它的行和列都是进行了合并后产生的。
for block in [block for block in detected if block.type == "Table"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## extraction extracted = model.detect(segmented) ## save dic_predicted[str(block.id)+"-"+block.type] = pd.read_csv( io.StringIO(extracted) ) # check parse_doc(dic_predicted)

正如我们的预料提取的表格不是很好。好在Python有专门处理表格的包,我们可以直接处理而不将其转换为图像。这里使用TabulaPy 包:
import tabula
tables = tabula.read_pdf("doc_apple.pdf", pages=i+1)
tables[0]
结果要好一些,但是名称仍然错了,但是效果要比直接OCR好的多。
总结
本文是一个简单教程,演示了如何使用OCR进行文档解析。使用Layoutpars软件包进行了整个检测和提取过程。并展示了如何处理PDF文档中的文本,数字和表格。
以上がPython と OCR を使用したドキュメント解析の完全なコード デモ (コードは添付)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Python 文本终端 GUI 框架,太酷了Apr 12, 2023 pm 12:52 PM
Python 文本终端 GUI 框架,太酷了Apr 12, 2023 pm 12:52 PMCurses首先出场的是 Curses[1]。CurseCurses 是一个能提供基于文本终端窗口功能的动态库,它可以: 使用整个屏幕 创建和管理一个窗口 使用 8 种不同的彩色 为程序提供鼠标支持 使用键盘上的功能键Curses 可以在任何遵循 ANSI/POSIX 标准的 Unix/Linux 系统上运行。Windows 上也可以运行,不过需要额外安装 windows-curses 库:pip install windows-curses 上面图片,就是一哥们用 Curses 写的 俄罗斯
 五个方便好用的Python自动化脚本Apr 11, 2023 pm 07:31 PM
五个方便好用的Python自动化脚本Apr 11, 2023 pm 07:31 PM相比大家都听过自动化生产线、自动化办公等词汇,在没有人工干预的情况下,机器可以自己完成各项任务,这大大提升了工作效率。编程世界里有各种各样的自动化脚本,来完成不同的任务。尤其Python非常适合编写自动化脚本,因为它语法简洁易懂,而且有丰富的第三方工具库。这次我们使用Python来实现几个自动化场景,或许可以用到你的工作中。1、自动化阅读网页新闻这个脚本能够实现从网页中抓取文本,然后自动化语音朗读,当你想听新闻的时候,这是个不错的选择。代码分为两大部分,第一通过爬虫抓取网页文本呢,第二通过阅读工
 用Python写了个小工具,再复杂的文件夹,分分钟帮你整理!Apr 11, 2023 pm 08:19 PM
用Python写了个小工具,再复杂的文件夹,分分钟帮你整理!Apr 11, 2023 pm 08:19 PM糟透了我承认我不是一个爱整理桌面的人,因为我觉得乱糟糟的桌面,反而容易找到文件。哈哈,可是最近桌面实在是太乱了,自己都看不下去了,几乎占满了整个屏幕。虽然一键整理桌面的软件很多,但是对于其他路径下的文件,我同样需要整理,于是我想到使用Python,完成这个需求。效果展示我一共为将文件分为9个大类,分别是图片、视频、音频、文档、压缩文件、常用格式、程序脚本、可执行程序和字体文件。# 不同文件组成的嵌套字典 file_dict = { '图片': ['jpg','png','gif','webp
 用 WebAssembly 在浏览器中运行 PythonApr 11, 2023 pm 09:43 PM
用 WebAssembly 在浏览器中运行 PythonApr 11, 2023 pm 09:43 PM长期以来,Python 社区一直在讨论如何使 Python 成为网页浏览器中流行的编程语言。然而网络浏览器实际上只支持一种编程语言:JavaScript。随着网络技术的发展,我们已经把越来越多的程序应用在网络上,如游戏、数据科学可视化以及音频和视频编辑软件。这意味着我们已经把繁重的计算带到了网络上——这并不是JavaScript的设计初衷。所有这些挑战提出了对新编程语言的需求,这种语言可以提供快速、可移植、紧凑和安全的代码执行。因此,主要的浏览器供应商致力于实现这个想法,并在2017年向世界推出
 从头开始构建,DeepMind新论文用伪代码详解TransformerApr 09, 2023 pm 08:31 PM
从头开始构建,DeepMind新论文用伪代码详解TransformerApr 09, 2023 pm 08:31 PM2017 年 Transformer 横空出世,由谷歌在论文《Attention is all you need》中引入。这篇论文抛弃了以往深度学习任务里面使用到的 CNN 和 RNN。这一开创性的研究颠覆了以往序列建模和 RNN 划等号的思路,如今被广泛用于 NLP。大热的 GPT、BERT 等都是基于 Transformer 构建的。Transformer 自推出以来,研究者已经提出了许多变体。但大家对 Transformer 的描述似乎都是以口头形式、图形解释等方式介绍该架构。关于 Tra
 一文读懂层次聚类(Python代码)Apr 11, 2023 pm 09:13 PM
一文读懂层次聚类(Python代码)Apr 11, 2023 pm 09:13 PM首先要说,聚类属于机器学习的无监督学习,而且也分很多种方法,比如大家熟知的有K-means。层次聚类也是聚类中的一种,也很常用。下面我先简单回顾一下K-means的基本原理,然后慢慢引出层次聚类的定义和分层步骤,这样更有助于大家理解。层次聚类和K-means有什么不同?K-means 工作原理可以简要概述为: 决定簇数(k) 从数据中随机选取 k 个点作为质心 将所有点分配到最近的聚类质心 计算新形成的簇的质心 重复步骤 3 和 4这是一个迭代过程,直到新形成的簇的质心不变,或者达到最大迭代次数
 用 Python 实现导弹自动追踪,超燃!Apr 12, 2023 am 08:04 AM
用 Python 实现导弹自动追踪,超燃!Apr 12, 2023 am 08:04 AM大家好,我是J哥。这个没有点数学基础是很难算出来的。但是我们有了计算机就不一样了,依靠计算机极快速的运算速度,我们利用微分的思想,加上一点简单的三角学知识,就可以实现它。好,话不多说,我们来看看它的算法原理,看图:由于待会要用pygame演示,它的坐标系是y轴向下,所以这里我们也用y向下的坐标系。算法总的思想就是根据上图,把时间t分割成足够小的片段(比如1/1000,这个时间片越小越精确),每一个片段分别构造如上三角形,计算出导弹下一个时间片走的方向(即∠a)和走的路程(即vt=|AC|),这时
 集成GPT-4的Cursor让编写代码和聊天一样简单,用自然语言编写代码的新时代已来Apr 04, 2023 pm 12:15 PM
集成GPT-4的Cursor让编写代码和聊天一样简单,用自然语言编写代码的新时代已来Apr 04, 2023 pm 12:15 PM集成GPT-4的Github Copilot X还在小范围内测中,而集成GPT-4的Cursor已公开发行。Cursor是一个集成GPT-4的IDE,可以用自然语言编写代码,让编写代码和聊天一样简单。 GPT-4和GPT-3.5在处理和编写代码的能力上差别还是很大的。官网的一份测试报告。前两个是GPT-4,一个采用文本输入,一个采用图像输入;第三个是GPT3.5,可以看出GPT-4的代码能力相较于GPT-3.5有较大能力的提升。集成GPT-4的Github Copilot X还在小范围内测中,而


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

Dreamweaver Mac版
ビジュアル Web 開発ツール
ホットトピック
 7444
7444 15137152
15137152