
ホームページ >テクノロジー周辺機器 >AI >高精度でリソース消費量が少ない大規模モデル向けのこのスパース トレーニング方法が発見されました。
高精度でリソース消費量が少ない大規模モデル向けのこのスパース トレーニング方法が発見されました。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-13 19:01:011520ブラウズ
最近、大規模モデルのスパース トレーニングに関する Alibaba Cloud Machine Learning PAI の論文「Parameter-Efficient Sparsity for Large Language Models Fine-Tuning」が、人工知能のトップカンファレンスである IJCAI 2022 に採択されました。
この論文は、パラメータ効率の高いスパース トレーニング アルゴリズム PST を提案しており、重みの重要度指標を分析することにより、このアルゴリズムには低ランクと構造という 2 つの特徴があることが結論付けられています。この結論に基づいて、PST アルゴリズムでは、重みの重要性を計算するために 2 セットの小さな行列が導入され、重要度インデックスを保存および更新するために重みと同じくらい大きな行列が必要であったのに比べて、必要なパラメータの量が減少しています。スパーストレーニング用の更新は大幅に削減されます。一般的に使用されるスパース トレーニング アルゴリズムと比較して、PST アルゴリズムはパラメーターの 1.5% のみを更新しながら、同様のスパース モデルの精度を達成できます。
背景
近年、大手企業や研究機関では、数百億から数万のパラメータを持つさまざまな大規模モデルが提案されています。 . その範囲は数十億から数千億まであり、数十兆という超大型モデルも登場しています。これらのモデルはトレーニングと展開に大量のハードウェア リソースを必要とするため、実装が困難になります。したがって、大規模なモデルのトレーニングとデプロイに必要なリソースをいかに削減するかが緊急の課題となっています。
モデル圧縮テクノロジは、モデルのデプロイに必要なリソースを効果的に削減できます。一部の重みを削除することで、モデル内の疎な計算を密な計算から疎な計算に変換できるため、メモリ使用量が削減され、計算が高速化されます。同時に、他のモデル圧縮方法 (構造化枝刈り/量子化) と比較して、スパース性はモデルの精度を確保しながら高い圧縮率を実現でき、多数のパラメーターを持つ大規模なモデルに適しています。
課題
既存のスパース トレーニング方法は 2 つのカテゴリに分類できます。1 つは重みベースのデータフリー スパース アルゴリズムで、もう 1 つはデータベースのデータです。スパースアルゴリズムで駆動されます。重みベースのスパース アルゴリズムは、次の図に示されています。マグニチュード プルーニング [1] などです。これは、重みの L1 ノルムを計算することで重みの重要性を評価し、これに基づいて対応するスパース結果を生成します。重みベースのスパース アルゴリズムは計算効率が高く、トレーニング データの参加を必要としませんが、計算された重要度インデックスの精度が十分ではないため、最終的なスパース モデルの精度に影響します。
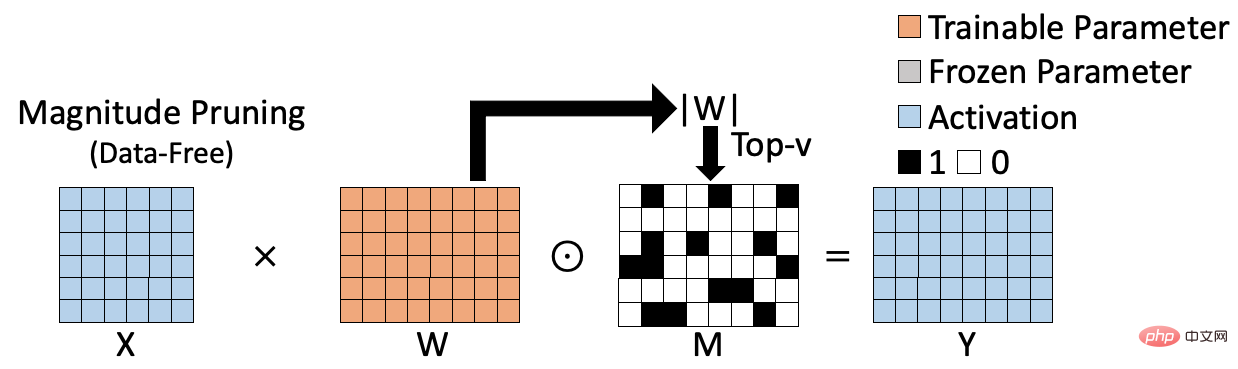
データベースのスパース アルゴリズムを以下の図に示します。たとえば、動きの枝刈り[2]などです。これは、次の方法で重みの重要性を測定します。体重と対応する勾配の積を計算します。このタイプの方法では、特定のデータセットに対する重みの役割が考慮されるため、重みの重要性をより正確に評価できます。ただし、このタイプの方法では、各重みの重要度を計算して保存する必要があるため、重要度インデックス (図の S) を保存するための追加のスペースが必要になることがよくあります。同時に、重みベースのスパース手法と比較して、計算プロセスがより複雑になることがよくあります。これらの欠点は、モデルのサイズが大きくなるにつれてより顕著になります。
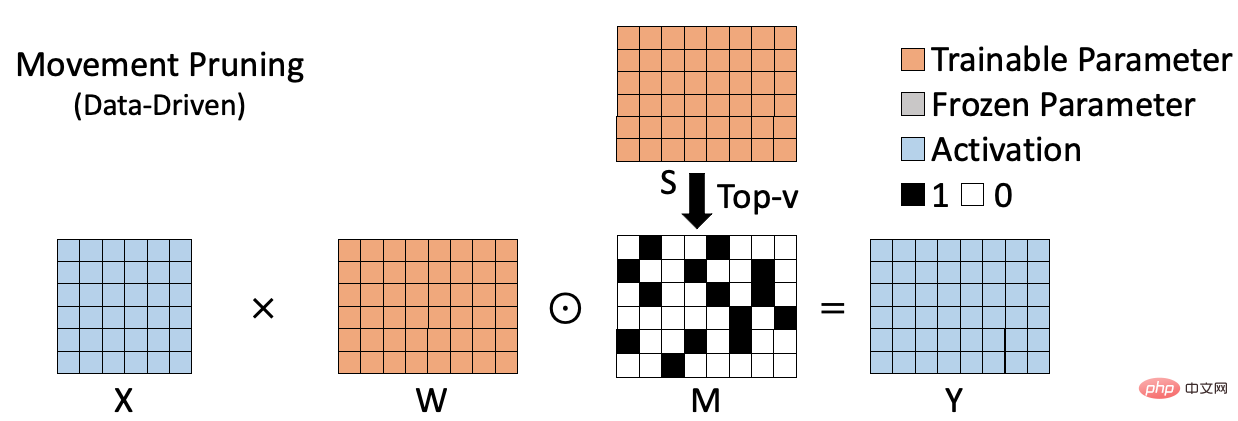
要約すると、以前のスパース アルゴリズムは効率的だが精度が十分ではない (重みベースのアルゴリズム)、または正確ではあるが効率が十分ではない (データベースのアルゴリズム)。アルゴリズム)。したがって、大規模なモデルに対して正確かつ効率的にスパース トレーニングを実行できる効率的なスパース アルゴリズムを提案したいと考えています。
速報
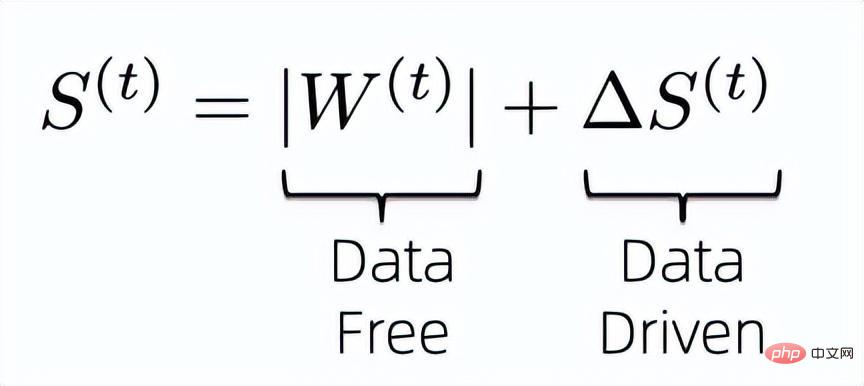
データベースのスパース アルゴリズムの問題は、通常、重みの重要性を学習するために重みと同じサイズの追加パラメータが導入されることです。ここでは、重みを計算するために追加のパラメーターを導入する重要性を軽減する方法を考えてみましょう。まず、既存の情報を最大限に活用して重みの重要度を計算するために、重みの重要度指数を次の式のように設計します。 # つまり、データフリーの指標とデータ駆動型の指標を組み合わせて、最終モデルの重みの重要性を共同で決定します。以前のデータフリー重要度指数は追加のパラメーターを保存する必要がなく、計算が効率的であることが知られているため、解決する必要があるのは、後のデータ駆動型重要度指数によって導入された追加のトレーニング パラメーターをどのように圧縮するかということです。
 以前のスパース アルゴリズムに基づいて、データ駆動型重要度インデックスは次のように設計できます
以前のスパース アルゴリズムに基づいて、データ駆動型重要度インデックスは次のように設計できます
#
そこで、この式で計算された重要度指標の冗長性の分析を開始しました。まず第一に、以前の研究に基づいて、重みと対応する勾配の両方が明らかな低ランク特性を持つことが知られています [3, 4]。そのため、重要度インデックスにも低ランク特性があると推測でき、次の 2 つを導入できます。低ランクのプロパティ 重みと同じくらい大きい、元の重要性インジケーター マトリックスを表す小さなマトリックス。
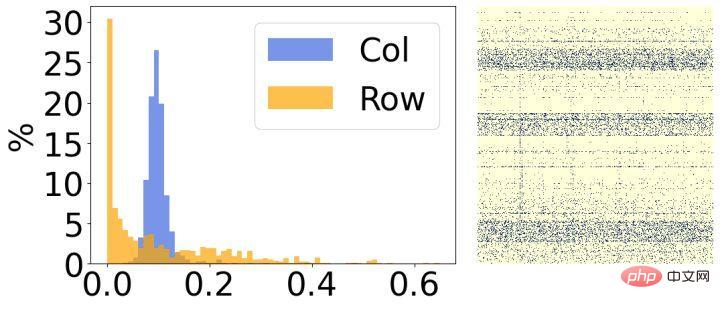
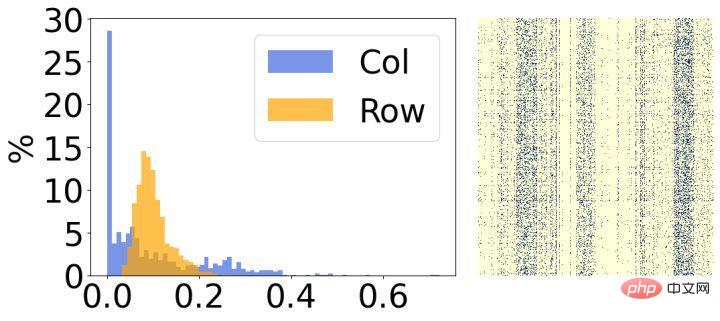
#第 2 に、モデルの疎化後の結果を分析したところ、明らかな構造的特徴があることがわかりました。上の図に示すように、各画像の右側は最終的なスパース重みの視覚化結果であり、左側は各行/列の対応するスパース率をカウントしたヒストグラムです。左の図の行の 30% の重みのほとんどが削除されており、逆に、右の図の列の 30% の重みのほとんどが削除されていることがわかります。この現象に基づいて、重みの各行/列の重要性を評価するために 2 つの小さな構造化行列を導入します。
#上記の分析に基づいて、データ駆動型重要度インデックスのランクと構造が低いことが判明したため、次の表現に変換できます:
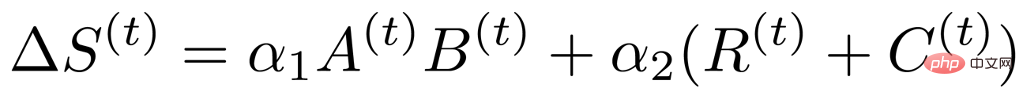
ここで、A と B は低ランクを表し、R と C は構造を表します。このような分析により、元々は重みと同じくらい大きかった重要度指標行列が 4 つの小さな行列に分解され、スパース トレーニングに含まれるトレーニング パラメータが大幅に削減されました。同時に、トレーニング パラメーターをさらに減らすために、前の方法に基づいて重み更新を 2 つの小さな行列 U と V に分解しました。そのため、最終的な重要度インデックスの式は次の形式になります。
#対応するアルゴリズム フレームワーク図は次のとおりです。 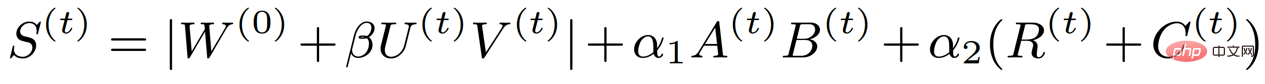
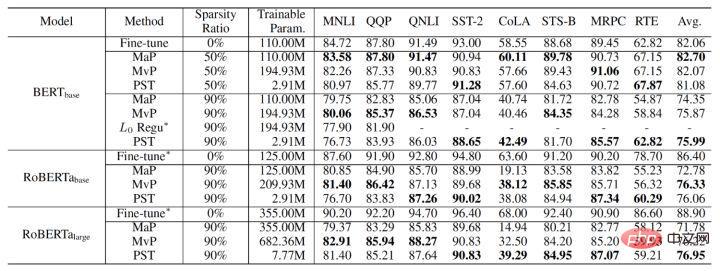
最終的な PST アルゴリズムの実験結果は次のとおりです。 NLU (BERT、RoBERTa) および NLG (GPT-2) タスクでのマグニチュード プルーニングと移動プルーニングと比較すると、90% のスパース率で、PST はほとんどのデータ セットで以前のアルゴリズムに匹敵するモデル精度を達成できます。ただし、トレーニングパラメータの 1.5% のみが必要です。 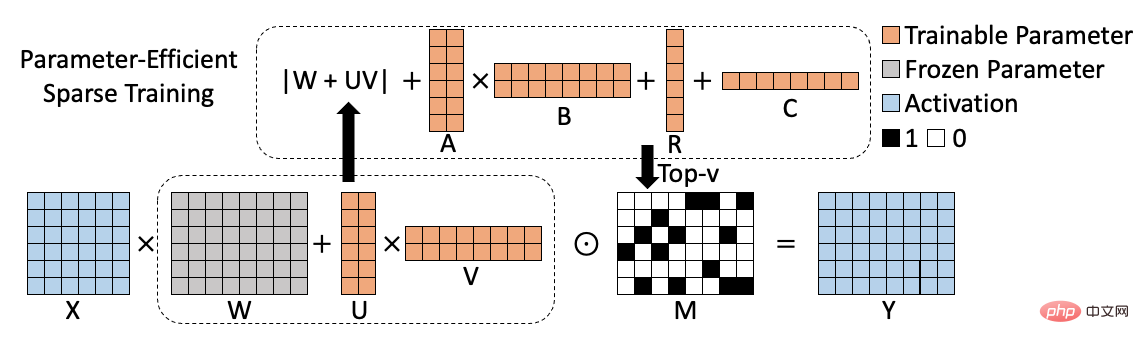
PST テクノロジーは、Alibaba Cloud Machine Learning PAI のモデル圧縮ライブラリに統合されています。アリスマインドプラットフォームの大規模モデル スパーストレーニング機能。 PST は、アリババ グループ内での大規模モデルの使用にパフォーマンスの高速化をもたらしました。数百億個の大規模モデル PLUG 上で、PST はモデルの精度を低下させることなく 2.5 倍高速化し、元のスパース トレーニングと比較してメモリ使用量を 10 倍削減できます。現在、Alibaba Cloud Machine Learning PAIはさまざまな業界で広く使用されており、フルリンクAI開発サービスを提供し、企業向けに独立した制御可能なAIソリューションを実現し、機械学習エンジニアリングの効率を包括的に向上させています。 
論文名: 大規模言語モデルのパラメータ効率的なスパース性の微調整
論文著者: Yuchao Li、Fuli Luo、Chuanqi Tan、 Mengdi Wang、Songfang Huang、Shen Li、Junjie Bai
論文の PDF リンク: https://arxiv.org/pdf/2205.11005.pdf
以上が高精度でリソース消費量が少ない大規模モデル向けのこのスパース トレーニング方法が発見されました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。