



勾配ブースティング アルゴリズムは、最も一般的に使用されるアンサンブル機械学習手法の 1 つであり、このモデルは、一連の弱い決定ツリーを使用して、強力な学習器を構築します。これは XGBoost モデルと LightGBM モデルの理論的基礎でもあるため、この記事では勾配ブースティング モデルを最初から構築して視覚化します。
勾配ブースティング アルゴリズムの概要
勾配ブースティング アルゴリズム (勾配ブースティング) は、複数の弱分類器を構築し、それらを組み合わせて強分類器にすることでパフォーマンスを向上させるアンサンブル学習アルゴリズムです。モデル。
勾配ブースティング アルゴリズムの原理は、次のステップに分割できます。
- モデルの初期化: 一般的に、単純なモデル (デシジョン ツリーなど) を次のように使用できます。初期分類子。
- 損失関数の負の勾配を計算する: 現在のモデルの各サンプル ポイントの損失関数の負の勾配を計算します。これは、新しい分類器に現在のモデルに誤差を適合させるよう要求するのと同じです。
- 新しい分類器をトレーニングする: これらの負の勾配をターゲット変数として使用して、新しい弱分類器をトレーニングします。この弱分類器には、デシジョン ツリー、線形モデルなどの任意の分類器を使用できます。
- モデルの更新: 元のモデルに新しい分類子を追加し、加重平均またはその他の方法を使用してそれらを結合します。
- 反復を繰り返す: 事前に設定された反復回数に達するか、事前に設定された精度に達するまで、上記の手順を繰り返します。
勾配ブースティング アルゴリズムはシリアル アルゴリズムであるため、トレーニング速度が遅くなる可能性があります。実際の例で紹介しましょう:
特徴量 Set Xi と値 Yi があると仮定します。 、y の最良推定値を計算するには、y

 #ステップごとに、F_m(x) を y|x に近づけたいと考えます。
#ステップごとに、F_m(x) を y|x に近づけたいと考えます。
 各ステップで、x が与えられた場合に F_m(x) が y のより適切な近似値になるようにします。
各ステップで、x が与えられた場合に F_m(x) が y のより適切な近似値になるようにします。
まず、損失関数を定義します。

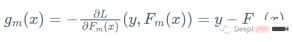
したがって、弱回帰木 h_m を使用して勾配関数 g_m を近似し、残差をトレーニングできます:
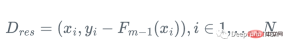
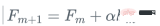
#つまり、次の手順を繰り返します
2 . 回帰木 h_m をトレーニング サンプルとその残差 (x_i, r_i) に当てはめる  #3. ステップ アルファでモデルを更新する
#3. ステップ アルファでモデルを更新する
 意思決定プロセスの視覚化
意思決定プロセスの視覚化
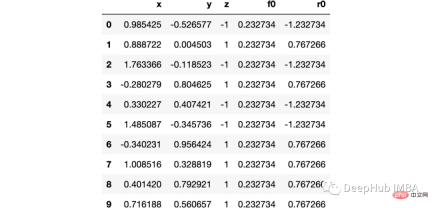
ここでは、sklearn の衛星データ セットを使用します。これは古典的な非線形カテゴリ データであるためです
import numpy as np import sklearn.datasets as ds import pandas as pd import matplotlib.pyplot as plt import matplotlib as mpl from sklearn import tree from itertools import product,islice import seaborn as snsmoonDS = ds.make_moons(200, noise = 0.15, random_state=16) moon = moonDS[0] color = -1*(moonDS[1]*2-1) df =pd.DataFrame(moon, columns = ['x','y']) df['z'] = color df['f0'] =df.y.mean() df['r0'] = df['z'] - df['f0'] df.head(10)
データを視覚化しましょう:
下图可以看到,该数据集是可以明显的区分出分类的边界的,但是因为他是非线性的,所以使用线性算法进行分类时会遇到很大的困难。

那么我们先编写一个简单的梯度增强模型:
def makeiteration(i:int):
"""Takes the dataframe ith f_i and r_i and approximated r_i from the features, then computes f_i+1 and r_i+1"""
clf = tree.DecisionTreeRegressor(max_depth=1)
clf.fit(X=df[['x','y']].values, y = df[f'r{i-1}'])
df[f'r{i-1}hat'] = clf.predict(df[['x','y']].values)
eta = 0.9
df[f'f{i}'] = df[f'f{i-1}'] + eta*df[f'r{i-1}hat']
df[f'r{i}'] = df['z'] - df[f'f{i}']
rmse = (df[f'r{i}']**2).sum()
clfs.append(clf)
rmses.append(rmse)上面代码执行3个简单步骤:
将决策树与残差进行拟合:
clf.fit(X=df[['x','y']].values, y = df[f'r{i-1}'])
df[f'r{i-1}hat'] = clf.predict(df[['x','y']].values)然后,我们将这个近似的梯度与之前的学习器相加:
df[f'f{i}'] = df[f'f{i-1}'] + eta*df[f'r{i-1}hat']最后重新计算残差:
df[f'r{i}'] = df['z'] - df[f'f{i}']步骤就是这样简单,下面我们来一步一步执行这个过程。
第1次决策

Tree Split for 0 and level 1.563690960407257

第2次决策

Tree Split for 1 and level 0.5143677890300751

第3次决策

Tree Split for 0 and level -0.6523728966712952

第4次决策

Tree Split for 0 and level 0.3370491564273834

第5次决策

Tree Split for 0 and level 0.3370491564273834

第6次决策

Tree Split for 1 and level 0.022058885544538498

第7次决策

Tree Split for 0 and level -0.3030575215816498

第8次决策

Tree Split for 0 and level 0.6119407713413239

第9次决策

可以看到通过9次的计算,基本上已经把上面的分类进行了区分

我们这里的学习器都是非常简单的决策树,只沿着一个特征分裂!但整体模型在每次决策后边的越来越复杂,并且整体误差逐渐减小。
plt.plot(rmses)

这也就是上图中我们看到的能够正确区分出了大部分的分类
如果你感兴趣可以使用下面代码自行实验:
https://www.php.cn/link/bfc89c3ee67d881255f8b097c4ed2d67
以上が勾配ブースティング アルゴリズムの意思決定プロセスの段階的な視覚化の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Microsoft Work Trend Index 2025は、職場の容量の緊張を示していますApr 24, 2025 am 11:19 AM
Microsoft Work Trend Index 2025は、職場の容量の緊張を示していますApr 24, 2025 am 11:19 AMAIの急速な統合により悪化した職場での急成長能力の危機は、増分調整を超えて戦略的な変化を要求します。 これは、WTIの調査結果によって強調されています。従業員の68%がワークロードに苦労しており、BURにつながります
 AIは理解できますか?中国の部屋の議論はノーと言っていますが、それは正しいですか?Apr 24, 2025 am 11:18 AM
AIは理解できますか?中国の部屋の議論はノーと言っていますが、それは正しいですか?Apr 24, 2025 am 11:18 AMジョン・サールの中国の部屋の議論:AIの理解への挑戦 Searleの思考実験は、人工知能が真に言語を理解できるのか、それとも真の意識を持っているのかを直接疑問に思っています。 チャインを無知な人を想像してください
 中国の「スマート」AIアシスタントは、マイクロソフトのリコールのプライバシーの欠陥をエコーしますApr 24, 2025 am 11:17 AM
中国の「スマート」AIアシスタントは、マイクロソフトのリコールのプライバシーの欠陥をエコーしますApr 24, 2025 am 11:17 AM中国のハイテク大手は、西部のカウンターパートと比較して、AI開発の別のコースを図っています。 技術的なベンチマークとAPI統合のみに焦点を当てるのではなく、「スクリーン認識」AIアシスタントを優先しています。
 Dockerは、おなじみのコンテナワークフローをAIモデルとMCPツールにもたらしますApr 24, 2025 am 11:16 AM
Dockerは、おなじみのコンテナワークフローをAIモデルとMCPツールにもたらしますApr 24, 2025 am 11:16 AMMCP:AIシステムに外部ツールにアクセスできるようになります モデルコンテキストプロトコル(MCP)により、AIアプリケーションは標準化されたインターフェイスを介して外部ツールとデータソースと対話できます。人類によって開発され、主要なAIプロバイダーによってサポートされているMCPは、言語モデルとエージェントが利用可能なツールを発見し、適切なパラメーターでそれらを呼び出すことができます。ただし、環境紛争、セキュリティの脆弱性、一貫性のないクロスプラットフォーム動作など、MCPサーバーの実装にはいくつかの課題があります。 Forbesの記事「人類のモデルコンテキストプロトコルは、AIエージェントの開発における大きなステップです」著者:Janakiram MSVDockerは、コンテナ化を通じてこれらの問題を解決します。 Docker Hubインフラストラクチャに基づいて構築されたドキュメント
 6億ドルのスタートアップを構築するために6つのAIストリートスマート戦略を使用するApr 24, 2025 am 11:15 AM
6億ドルのスタートアップを構築するために6つのAIストリートスマート戦略を使用するApr 24, 2025 am 11:15 AM最先端のテクノロジーと巧妙なビジネスの洞察力を活用して、コントロールを維持しながら非常に収益性の高いスケーラブルな企業を作成する先見の明のある起業家によって採用された6つの戦略。このガイドは、建設を目指している起業家向けのためのものです
 Googleフォトの更新は、すべての写真の見事なウルトラHDRのロックを解除しますApr 24, 2025 am 11:14 AM
Googleフォトの更新は、すべての写真の見事なウルトラHDRのロックを解除しますApr 24, 2025 am 11:14 AMGoogle Photosの新しいウルトラHDRツール:画像強化のゲームチェンジャー Google Photosは、強力なウルトラHDR変換ツールを導入し、標準的な写真を活気のある高ダイナミックレンジ画像に変換しました。この強化は写真家に利益をもたらします
 Descopeは、AIエージェント統合の認証フレームワークを構築しますApr 24, 2025 am 11:13 AM
Descopeは、AIエージェント統合の認証フレームワークを構築しますApr 24, 2025 am 11:13 AM技術アーキテクチャは、新たな認証の課題を解決します エージェントアイデンティティハブは、AIエージェントの実装を開始した後にのみ多くの組織が発見した問題に取り組んでいます。
 Google Cloud Next2025と現代の仕事の接続された未来Apr 24, 2025 am 11:12 AM
Google Cloud Next2025と現代の仕事の接続された未来Apr 24, 2025 am 11:12 AM(注:Googleは私の会社であるMoor Insights&Strategyのアドバイザリークライアントです。) AI:実験からエンタープライズ財団まで Google Cloud Next 2025は、実験機能からエンタープライズテクノロジーのコアコンポーネント、ストリームへのAIの進化を紹介しました


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

Dreamweaver Mac版
ビジュアル Web 開発ツール

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

ドリームウィーバー CS6
ビジュアル Web 開発ツール
ホットトピック
 7694
7694 15164014139352128725122929
15164014139352128725122929