



この記事の目的は、ソース コードの中間表現を回避し、ソース コードを画像として表現し、コードの意味情報を直接抽出して欠陥予測のパフォーマンスを向上させることです。
まず、以下に示す志望動機の例をご覧ください。 File1.java と File2.java の両方の例には 1 つの if ステートメント、2 つの for ステートメント、および 4 つの関数呼び出しが含まれていますが、コードのセマンティクスと構造的特徴は異なります。ソースコードを画像に変換することで異なるコードを区別できるかどうかを検証するために、著者は実験を行いました。ソースコードを文字のASCII 10進数に従ってピクセルにマッピングし、それらをピクセルマトリックスに配置して画像を取得します。ソースコード。著者は、さまざまなソース コード イメージ間に違いがあると指摘しています。

図 1 動機の例
この記事の主な貢献は次のとおりです:
コードを画像に変換して抽出するそこから得られる意味情報と構造情報 ;
セルフアテンション メカニズムと転移学習を組み合わせて欠陥予測を実現するエンドツーエンドのフレームワークを提案します。
この記事で提案されているモデル フレームワークは図 2 に示されており、ソース コードの視覚化と深層転移学習モデリングの 2 つの段階に分かれています。

図 2 フレームワーク
1. ソース コードの視覚化
この記事では、ソース コードを 6 つの画像に変換し、そのプロセスを示しています。図3に示されています。ソース コード文字の 10 進 ASCII コードを 8 ビットの符号なし整数ベクトルに変換し、これらのベクトルを行と列ごとに配置し、イメージ行列を生成します。 8 ビット整数はグレー レベルに直接対応します。元のデータセットが小さいという問題を解決するために、著者は記事の中で色強調に基づくデータセット拡張方法を提案しました。R、G、Bの3つのカラーチャネルの値が配置され、結合して 6 つのカラー画像を生成します。ここで非常に混乱しているように見えますが、チャネル値を変更すると、セマンティック情報と構造情報が変更されるはずです。しかし、図 4 に示すように、著者は脚注でそれを説明しています。

図 3 ソース コードの視覚化プロセス

図 4 記事の脚注 2
2 .深層転移学習モデリング
この記事では、DAN ネットワークを使用して、ソース コードのセマンティック情報と構造情報をキャプチャします。重要な情報を表現するモデルの能力を強化するために、作成者は元の DAN 構造にアテンション層を追加しました。トレーニングとテストのプロセスを図 5 に示します。conv1 ~ conv5 は AlexNet からのものであり、4 つの完全に接続された層 fc6 ~ fc9 が分類子として使用されています。著者は、新しいプロジェクトの場合、深層学習モデルのトレーニングには大量のラベル付きデータが必要であり、それが難しいと述べました。そこで、著者はまず ImageNet 2012 で事前トレーニングされたモデルをトレーニングし、事前トレーニングされたモデルのパラメータを初期パラメータとして使用してすべての畳み込み層を微調整することで、コード イメージと ImageNet 2012 のイメージ間の差を減らしました。

図 5 トレーニングとテストのプロセス
3. モデルのトレーニングと予測
ソース プロジェクトのタグ付きコードとターゲットの場合プロジェクト内のラベルのないコードは、コード イメージを生成し、同時にモデルにフィードします。両方とも畳み込み層とアテンション層を共有して、それぞれの特徴を抽出します。完全接続層のソースとターゲット間の MK-MDD (マルチ カーネル バリアントの最大平均不一致) を計算します。 Target にはラベルがないため、クロス エントロピーは Source に対してのみ計算されます。モデルは、ミニバッチの確率的勾配降下法を使用して、損失関数に沿ってトレーニングされます。 500 エポックの
実験部分では、作成者は PROMISE データ ウェアハウス内のすべてのオープン ソース Java プロジェクトを選択し、そのバージョン番号、クラス名、バグ タグの有無を収集しました。バージョン番号とクラス名に基づいて、github からソース コードをダウンロードします。最終的に、10 個の Java プロジェクトからデータが収集されました。データセットの構造を図 6 に示します。
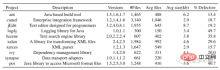
図 6 データセット構造
プロジェクト内の欠陥予測について、この記事では比較のために次のベースライン モデルを選択しています:

プロジェクト間の欠陥予測について、この記事では比較のために次のベースライン モデルを選択しています:

要約すると、この論文は 2 年前に書かれたものですが、そのアイデアは次のとおりです。まだ比較的目新しいものであり、AST などの一連のコード中間表現を回避し、コードを画像抽出機能に直接変換します。コードから変換された画像には、本当にソース コードの意味情報と構造情報が含まれているのでしょうか?あまり説明できないような気がします(笑)。後で実験的な分析を行う必要があります。
以上がソフトウェアの視覚化と転移学習をソフトウェア欠陥予測に使用するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Microsoft Work Trend Index 2025は、職場の容量の緊張を示していますApr 24, 2025 am 11:19 AM
Microsoft Work Trend Index 2025は、職場の容量の緊張を示していますApr 24, 2025 am 11:19 AMAIの急速な統合により悪化した職場での急成長能力の危機は、増分調整を超えて戦略的な変化を要求します。 これは、WTIの調査結果によって強調されています。従業員の68%がワークロードに苦労しており、BURにつながります
 AIは理解できますか?中国の部屋の議論はノーと言っていますが、それは正しいですか?Apr 24, 2025 am 11:18 AM
AIは理解できますか?中国の部屋の議論はノーと言っていますが、それは正しいですか?Apr 24, 2025 am 11:18 AMジョン・サールの中国の部屋の議論:AIの理解への挑戦 Searleの思考実験は、人工知能が真に言語を理解できるのか、それとも真の意識を持っているのかを直接疑問に思っています。 チャインを無知な人を想像してください
 中国の「スマート」AIアシスタントは、マイクロソフトのリコールのプライバシーの欠陥をエコーしますApr 24, 2025 am 11:17 AM
中国の「スマート」AIアシスタントは、マイクロソフトのリコールのプライバシーの欠陥をエコーしますApr 24, 2025 am 11:17 AM中国のハイテク大手は、西部のカウンターパートと比較して、AI開発の別のコースを図っています。 技術的なベンチマークとAPI統合のみに焦点を当てるのではなく、「スクリーン認識」AIアシスタントを優先しています。
 Dockerは、おなじみのコンテナワークフローをAIモデルとMCPツールにもたらしますApr 24, 2025 am 11:16 AM
Dockerは、おなじみのコンテナワークフローをAIモデルとMCPツールにもたらしますApr 24, 2025 am 11:16 AMMCP:AIシステムに外部ツールにアクセスできるようになります モデルコンテキストプロトコル(MCP)により、AIアプリケーションは標準化されたインターフェイスを介して外部ツールとデータソースと対話できます。人類によって開発され、主要なAIプロバイダーによってサポートされているMCPは、言語モデルとエージェントが利用可能なツールを発見し、適切なパラメーターでそれらを呼び出すことができます。ただし、環境紛争、セキュリティの脆弱性、一貫性のないクロスプラットフォーム動作など、MCPサーバーの実装にはいくつかの課題があります。 Forbesの記事「人類のモデルコンテキストプロトコルは、AIエージェントの開発における大きなステップです」著者:Janakiram MSVDockerは、コンテナ化を通じてこれらの問題を解決します。 Docker Hubインフラストラクチャに基づいて構築されたドキュメント
 6億ドルのスタートアップを構築するために6つのAIストリートスマート戦略を使用するApr 24, 2025 am 11:15 AM
6億ドルのスタートアップを構築するために6つのAIストリートスマート戦略を使用するApr 24, 2025 am 11:15 AM最先端のテクノロジーと巧妙なビジネスの洞察力を活用して、コントロールを維持しながら非常に収益性の高いスケーラブルな企業を作成する先見の明のある起業家によって採用された6つの戦略。このガイドは、建設を目指している起業家向けのためのものです
 Googleフォトの更新は、すべての写真の見事なウルトラHDRのロックを解除しますApr 24, 2025 am 11:14 AM
Googleフォトの更新は、すべての写真の見事なウルトラHDRのロックを解除しますApr 24, 2025 am 11:14 AMGoogle Photosの新しいウルトラHDRツール:画像強化のゲームチェンジャー Google Photosは、強力なウルトラHDR変換ツールを導入し、標準的な写真を活気のある高ダイナミックレンジ画像に変換しました。この強化は写真家に利益をもたらします
 Descopeは、AIエージェント統合の認証フレームワークを構築しますApr 24, 2025 am 11:13 AM
Descopeは、AIエージェント統合の認証フレームワークを構築しますApr 24, 2025 am 11:13 AM技術アーキテクチャは、新たな認証の課題を解決します エージェントアイデンティティハブは、AIエージェントの実装を開始した後にのみ多くの組織が発見した問題に取り組んでいます。
 Google Cloud Next2025と現代の仕事の接続された未来Apr 24, 2025 am 11:12 AM
Google Cloud Next2025と現代の仕事の接続された未来Apr 24, 2025 am 11:12 AM(注:Googleは私の会社であるMoor Insights&Strategyのアドバイザリークライアントです。) AI:実験からエンタープライズ財団まで Google Cloud Next 2025は、実験機能からエンタープライズテクノロジーのコアコンポーネント、ストリームへのAIの進化を紹介しました


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。
ホットトピック
 7696
7696 15164014139352128725122929
15164014139352128725122929