
ホームページ >バックエンド開発 >Python チュートリアル >10 個のクラスタリング アルゴリズムの完全な Python 操作例
10 個のクラスタリング アルゴリズムの完全な Python 操作例

- 王林転載
- 2023-04-13 09:40:101284ブラウズ

- クラスタリングは、入力データの特徴空間で自然グループを見つける教師なし問題です。
- さまざまなクラスタリング アルゴリズムがあり、すべてのデータ セットに最適な単一の方法があります。
- scikit-learn 機械学習ライブラリを使用して、Python でトップレベルのクラスタリング アルゴリズムを実装、適応、使用する方法。
チュートリアルの概要
- このチュートリアルは 3 つの部分に分かれています:
- クラスタリング
- クラスタリング アルゴリズム
- クラスタリング アルゴリズムの例
- ライブラリのインストール
- クラスタリング データ セット
- アフィニティ伝播
- 集約クラスタリング クラス
- BIRCH
- DBSCAN
- K 平均値
- ミニバッチ K 平均値
- 平均シフト
- OPTICS
- スペクトル クラスタリング
- 混合ガウス モデル
- クラスタリング手法は、予測するクラスはないが、インスタンスが自然なグループに分割されている場合に適しています。
- #—出典: 「データ マイニング ページ: 実用的な機械学習ツールとテクニック」2016 年。
- クラスターは通常、特徴空間内の高密度領域であり、ドメインからのサンプル (観測値またはデータ行) が他のクラスターよりもクラスターに近い場所にあります。クラスターは、サンプルまたはポイント特徴空間である中心 (重心) を持つことができ、境界または範囲を持つことができます。
- #—出典: 「データ マイニング ページ: 実用的な機械学習ツールとテクニック」2016 年。
- クラスタリングは、パターン発見または知識発見として知られる、問題領域について詳しく知るためのデータ分析アクティビティとして役立ちます。例:
進化ツリーは人為的なクラスター分析の結果と考えることができます;
- 正常なデータを異常値または異常から分離することはクラスター化の問題と考えることができます;
- 自然な動作に基づいてクラスターを分離することは、市場セグメンテーションと呼ばれるクラスター化問題です。
- クラスタリングは、特徴量エンジニアリングの一種として使用することもできます。この場合、既存の例と新しい例をマッピングし、データ内で識別されたクラスターの 1 つに属するものとしてラベルを付けることができます。クラスター固有の定量的な尺度は数多く存在しますが、特定されたクラスターの評価は主観的なものであり、ドメインの専門家が必要になる場合があります。通常、クラスタリング アルゴリズムは、アルゴリズムが検出すると予想される事前定義されたクラスターを含む合成データセットで学術的に比較されます。
クラスタリングは教師なし学習手法であるため、特定のメソッドの出力の品質を評価するのは困難です。
#—出典: 「機械学習のページ: 確率論的な視点」2012 年。- 2. クラスタリング アルゴリズム
- クラスタリング アルゴリズムにはさまざまな種類があります。多くのアルゴリズムは、特徴空間内のサンプル間の類似性または距離の尺度を使用して、密な観察領域を検出します。したがって、多くの場合、クラスタリング アルゴリズムを使用する前にデータを拡張することをお勧めします。
#—「統計的学習の要素: データ マイニング、推論、予測」より (2016 年)
- 一部のクラスタリング アルゴリズムでは、検出するクラスターを指定または推測する必要があります。一方、他のアルゴリズムでは、サンプルが「閉じている」または「接続されている」とみなされる観測間の指定された最小距離が必要です。したがって、クラスター分析は、望ましい結果または適切な結果が達成されるまで、識別されたクラスターの主観的な評価がアルゴリズム構成の変更にフィードバックされる反復プロセスです。 scikit-learn ライブラリには、選択できるさまざまなクラスタリング アルゴリズムのセットが用意されています。以下に、最も人気のある 10 個のアルゴリズムを示します:
- アフィニティ伝播
- 集約クラスタリング
- BIRCH
- DBSCAN
- K-Means
- ミニバッチ K -平均値
- 平均値シフト
- 光学
- スペクトル クラスタリング
- ガウス混合率
各アルゴリズムは、データ内の自然なグループを発見するという課題。最適なクラスタリング アルゴリズムは存在せず、管理された実験を使用せずにデータに最適なアルゴリズムを見つける簡単な方法はありません。このチュートリアルでは、scikit-learn ライブラリにある 10 個の一般的なクラスタリング アルゴリズムのそれぞれの使用方法を確認します。これらの例は、例をコピーして貼り付け、独自のデータでメソッドをテストするための基礎となります。アルゴリズムがどのように機能するかという理論を掘り下げたり、アルゴリズムを直接比較したりするつもりはありません。もう少し深く掘り下げてみましょう。
3. クラスタリング アルゴリズムの例
このセクションでは、scikit-learn で 10 個の一般的なクラスタリング アルゴリズムを使用する方法を確認します。これには、モデルのフィッティングの例と結果の視覚化の例が含まれます。これらの例は、独自のプロジェクトに貼り付けてコピーし、メソッドを独自のデータに適用するためのものです。
1. ライブラリのインストール
まず、ライブラリをインストールしましょう。最新バージョンがインストールされていることを確認する必要があるため、この手順をスキップしないでください。以下に示すように、pip Python インストーラーを使用して scikit-learn リポジトリをインストールできます。
sudo pip install scikit-learn
次に、ライブラリがインストールされていること、および最新バージョンを使用していることを確認しましょう。次のスクリプトを実行して、ライブラリのバージョン番号を出力します。
# 检查 scikit-learn 版本 import sklearn print(sklearn.__version__)
サンプルを実行すると、次のバージョン番号以降が表示されるはずです。
0.22.1
2. クラスタリング データ セット
make _classification () 関数を使用して、テスト バイナリ分類データ セットを作成します。データセットには、クラスごとに 2 つの入力フィーチャと 1 つのクラスターを含む 1000 の例が含まれます。これらのクラスターは 2 次元で表示されるため、データを散布図にプロットし、指定したクラスターごとにプロット内の点に色を付けることができます。
これは、少なくともテスト問題に関して、クラスターがどの程度適切に識別されるかを理解するのに役立ちます。このテスト問題のクラスターは多変量ガウス分布に基づいており、すべてのクラスタリング アルゴリズムがこれらのタイプのクラスターの識別に効果的であるわけではありません。したがって、このチュートリアルの結果は、一般的な方法を比較するための基礎として使用しないでください。以下に、合成クラスタリング データセットの作成と要約の例を示します。
# 综合分类数据集 from numpy import where from sklearn.datasets import make_classification from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 为每个类的样本创建散点图 for class_value in range(2): # 获取此类的示例的行索引 row_ix = where(y == class_value) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
この例を実行すると、合成クラスター化データセットが作成され、クラス ラベル (理想化されたクラスター) で色付けされた点を含む入力データの散布図が作成されます。 2 次元で 2 つの異なるデータ グループがはっきりと確認でき、自動クラスタリング アルゴリズムがこれらのグループを検出できることが期待されます。
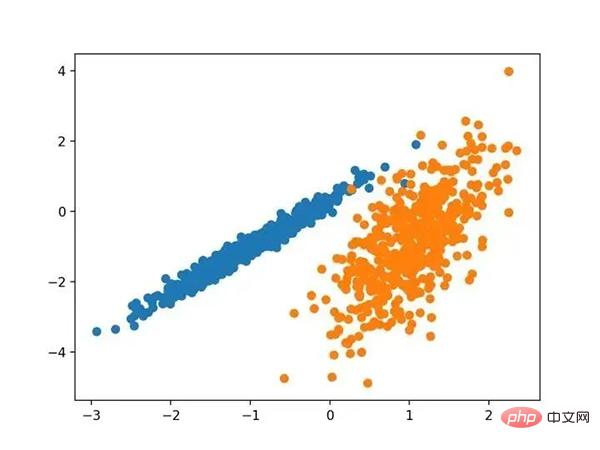
既知のクラスター化された色付き点の合成クラスター化データセットの散布図
次に、このデータセットに適用された結果の確認を開始できます (クラスター化アルゴリズムの例)。各メソッドをデータセットに適応させるために、最小限の試みをいくつか行いました。
3. アフィニティの伝播
アフィニティの伝播には、データを最もよく要約するサンプルのセットを見つけることが含まれます。
- 私たちは、2 組のデータポイント間の類似性の入力尺度として機能する「親和性伝播」と呼ばれるメソッドを設計しました。実際の値のメッセージは、一連の高品質のサンプルと対応するクラスターが徐々に出現するまで、データ ポイント間で交換されます。 #—「データ ポイント間でメッセージを渡すことによって」2007 年より。
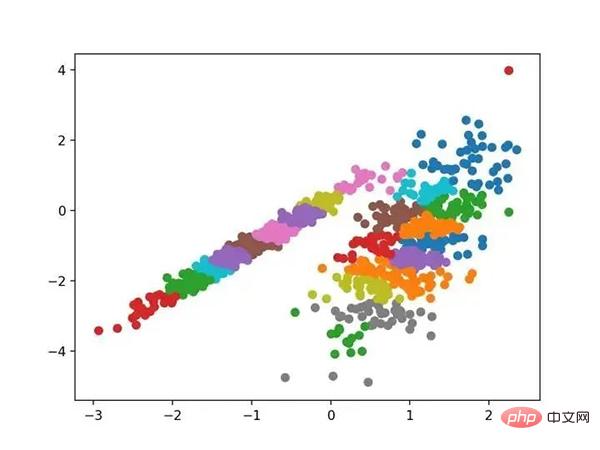
# 亲和力传播聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import AffinityPropagation from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = AffinityPropagation(damping=0.9) # 匹配模型 model.fit(X) # 为每个示例分配一个集群 yhat = model.predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()サンプルを実行してトレーニング データセットにモデルを適合させ、データセット内の各サンプルのクラスターを予測します。次に、割り当てられたクラスターごとに色付けされた散布図が作成されます。この場合、良い結果を得ることができません。
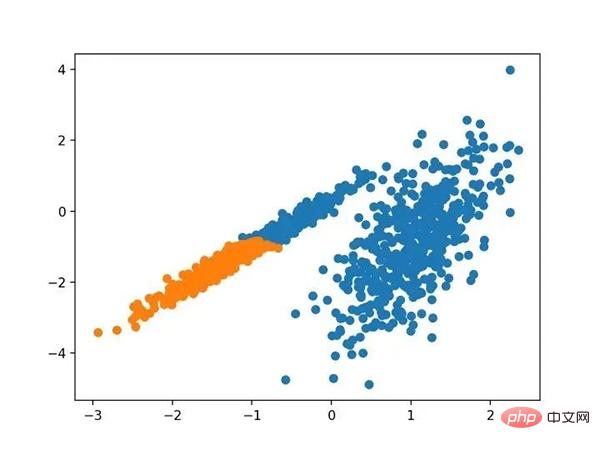
# 聚合聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import AgglomerativeClustering from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = AgglomerativeClustering(n_clusters=2) # 模型拟合与聚类预测 yhat = model.fit_predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()サンプルを実行してトレーニング データセットにモデルを適合させ、データセット内の各サンプルのクラスターを予測します。次に、割り当てられたクラスターごとに色付けされた散布図が作成されます。この場合、合理的なグループ化が見つかります。
5.BIRCH
BIRCH 聚类( BIRCH 是平衡迭代减少的缩写,聚类使用层次结构)包括构造一个树状结构,从中提取聚类质心。
- BIRCH 递增地和动态地群集传入的多维度量数据点,以尝试利用可用资源(即可用内存和时间约束)产生最佳质量的聚类。
- —源自:《 BIRCH :1996年大型数据库的高效数据聚类方法》
它是通过 Birch 类实现的,主要配置是“ threshold ”和“ n _ clusters ”超参数,后者提供了群集数量的估计。下面列出了完整的示例。
# birch聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import Birch from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = Birch(threshold=0.01, n_clusters=2) # 适配模型 model.fit(X) # 为每个示例分配一个集群 yhat = model.predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以找到一个很好的分组。
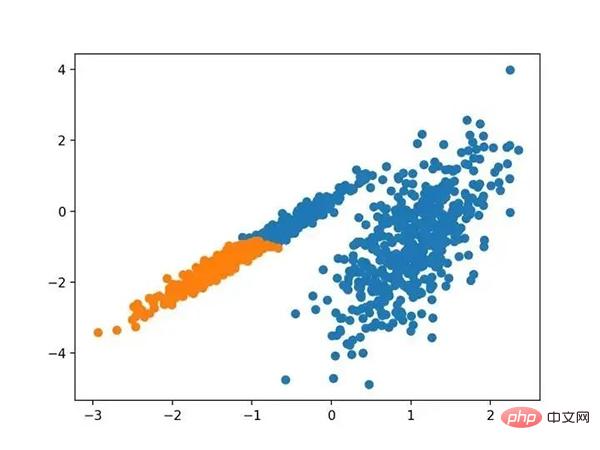
使用BIRCH聚类确定具有聚类的数据集的散点图
6.DBSCAN
DBSCAN 聚类(其中 DBSCAN 是基于密度的空间聚类的噪声应用程序)涉及在域中寻找高密度区域,并将其周围的特征空间区域扩展为群集。
- …我们提出了新的聚类算法 DBSCAN 依赖于基于密度的概念的集群设计,以发现任意形状的集群。DBSCAN 只需要一个输入参数,并支持用户为其确定适当的值
- -源自:《基于密度的噪声大空间数据库聚类发现算法》,1996
它是通过 DBSCAN 类实现的,主要配置是“ eps ”和“ min _ samples ”超参数。
下面列出了完整的示例。
# dbscan 聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import DBSCAN from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = DBSCAN(eps=0.30, min_samples=9) # 模型拟合与聚类预测 yhat = model.fit_predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,尽管需要更多的调整,但是找到了合理的分组。
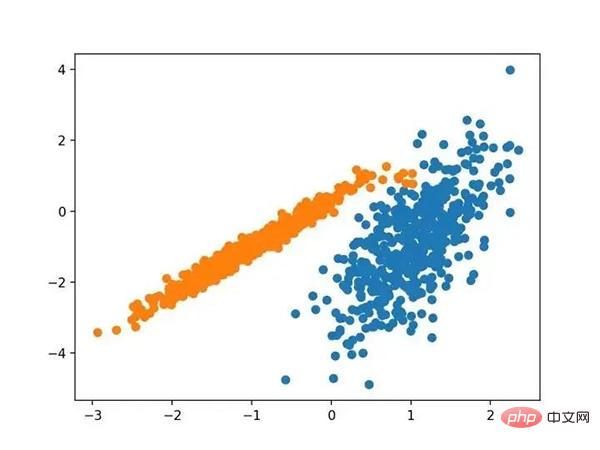
使用DBSCAN集群识别出具有集群的数据集的散点图
7.K均值
K-均值聚类可以是最常见的聚类算法,并涉及向群集分配示例,以尽量减少每个群集内的方差。
- 本文的主要目的是描述一种基于样本将 N 维种群划分为 k 个集合的过程。这个叫做“ K-均值”的过程似乎给出了在类内方差意义上相当有效的分区。
- -源自:《关于多元观测的分类和分析的一些方法》1967年
它是通过 K-均值类实现的,要优化的主要配置是“ n _ clusters ”超参数设置为数据中估计的群集数量。下面列出了完整的示例。
# k-means 聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import KMeans from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = KMeans(n_clusters=2) # 模型拟合 model.fit(X) # 为每个示例分配一个集群 yhat = model.predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以找到一个合理的分组,尽管每个维度中的不等等方差使得该方法不太适合该数据集。
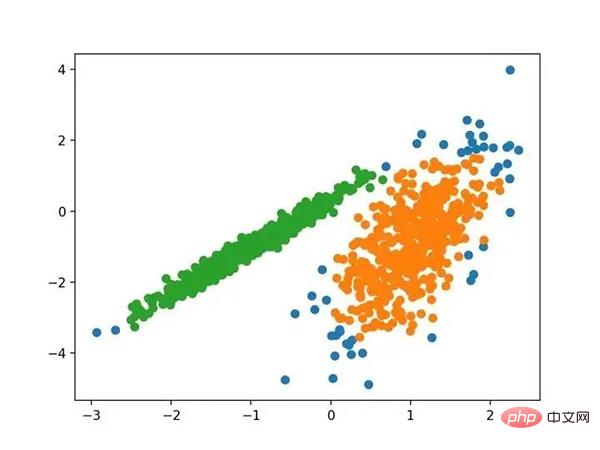
使用K均值聚类识别出具有聚类的数据集的散点图
8.Mini-Batch K-均值
Mini-Batch K-均值是 K-均值的修改版本,它使用小批量的样本而不是整个数据集对群集质心进行更新,这可以使大数据集的更新速度更快,并且可能对统计噪声更健壮。
- ...我们建议使用 k-均值聚类的迷你批量优化。与经典批处理算法相比,这降低了计算成本的数量级,同时提供了比在线随机梯度下降更好的解决方案。
- —源自:《Web-Scale K-均值聚类》2010
它是通过 MiniBatchKMeans 类实现的,要优化的主配置是“ n _ clusters ”超参数,设置为数据中估计的群集数量。下面列出了完整的示例。
# mini-batch k均值聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import MiniBatchKMeans from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = MiniBatchKMeans(n_clusters=2) # 模型拟合 model.fit(X) # 为每个示例分配一个集群 yhat = model.predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,会找到与标准 K-均值算法相当的结果。
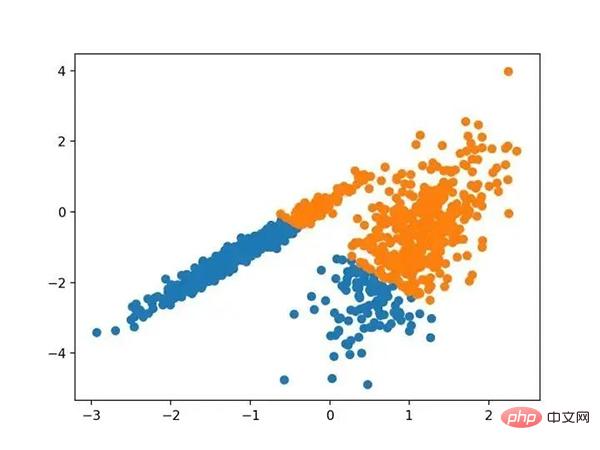
带有最小批次K均值聚类的聚类数据集的散点图
9.均值漂移聚类
均值漂移聚类涉及到根据特征空间中的实例密度来寻找和调整质心。
- 对离散数据证明了递推平均移位程序收敛到最接近驻点的基础密度函数,从而证明了它在检测密度模式中的应用。
- —源自:《Mean Shift :面向特征空间分析的稳健方法》,2002
它是通过 MeanShift 类实现的,主要配置是“带宽”超参数。下面列出了完整的示例。
# 均值漂移聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import MeanShift from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = MeanShift() # 模型拟合与聚类预测 yhat = model.fit_predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以在数据中找到一组合理的群集。
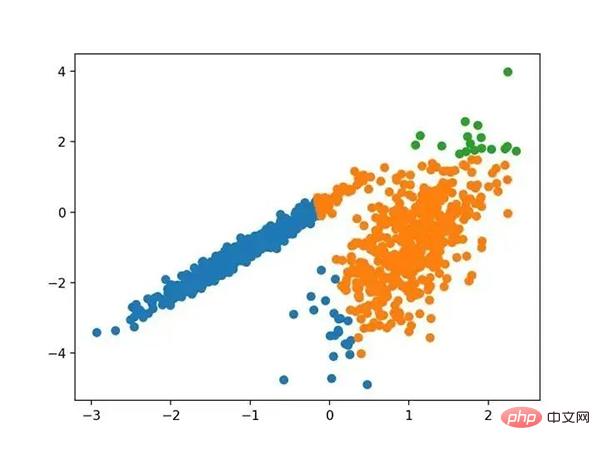
具有均值漂移聚类的聚类数据集散点图
10.OPTICS
OPTICS 聚类( OPTICS 短于订购点数以标识聚类结构)是上述 DBSCAN 的修改版本。
- 我们为聚类分析引入了一种新的算法,它不会显式地生成一个数据集的聚类;而是创建表示其基于密度的聚类结构的数据库的增强排序。此群集排序包含相当于密度聚类的信息,该信息对应于范围广泛的参数设置。
- —源自:《OPTICS :排序点以标识聚类结构》,1999
它是通过 OPTICS 类实现的,主要配置是“ eps ”和“ min _ samples ”超参数。下面列出了完整的示例。
# optics聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import OPTICS from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = OPTICS(eps=0.8, min_samples=10) # 模型拟合与聚类预测 yhat = model.fit_predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,我无法在此数据集上获得合理的结果。
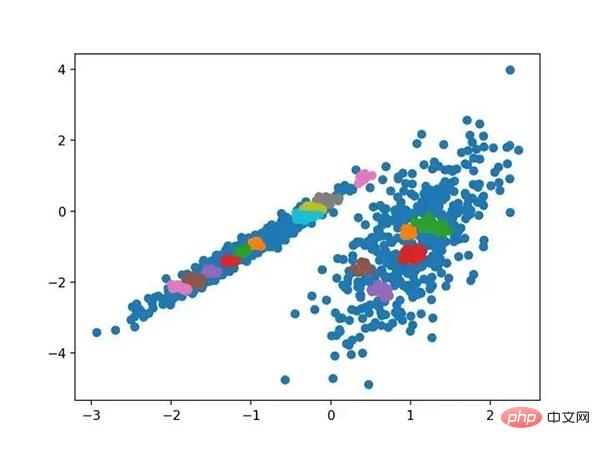
使用OPTICS聚类确定具有聚类的数据集的散点图
11.光谱聚类
光谱聚类是一类通用的聚类方法,取自线性线性代数。
- 最近在许多领域出现的一个有希望的替代方案是使用聚类的光谱方法。这里,使用从点之间的距离导出的矩阵的顶部特征向量。
- —源自:《关于光谱聚类:分析和算法》,2002年
它是通过 Spectral 聚类类实现的,而主要的 Spectral 聚类是一个由聚类方法组成的通用类,取自线性线性代数。要优化的是“ n _ clusters ”超参数,用于指定数据中的估计群集数量。下面列出了完整的示例。
# spectral clustering from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import SpectralClustering from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = SpectralClustering(n_clusters=2) # 模型拟合与聚类预测 yhat = model.fit_predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。
在这种情况下,找到了合理的集群。
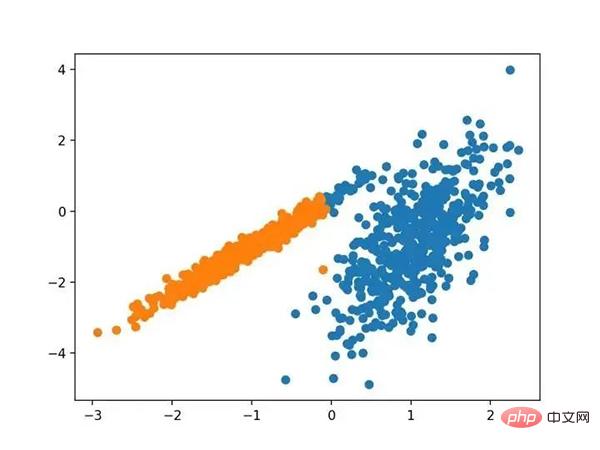
使用光谱聚类聚类识别出具有聚类的数据集的散点图
12.高斯混合模型
高斯混合模型总结了一个多变量概率密度函数,顾名思义就是混合了高斯概率分布。它是通过 Gaussian Mixture 类实现的,要优化的主要配置是“ n _ clusters ”超参数,用于指定数据中估计的群集数量。下面列出了完整的示例。
# 高斯混合模型 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.mixture import GaussianMixture from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = GaussianMixture(n_components=2) # 模型拟合 model.fit(X) # 为每个示例分配一个集群 yhat = model.predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,我们可以看到群集被完美地识别。这并不奇怪,因为数据集是作为 Gaussian 的混合生成的。
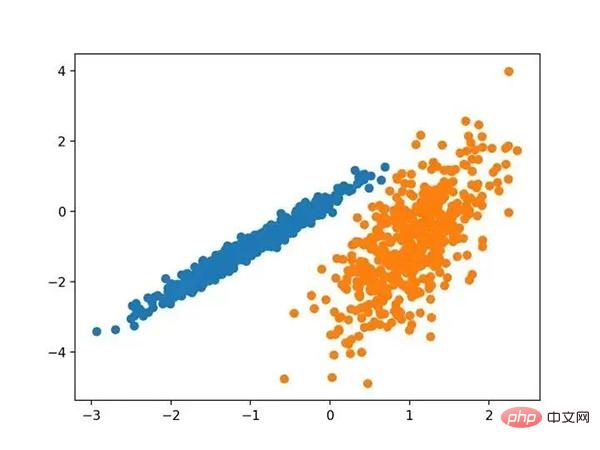
使用高斯混合聚类识别出具有聚类的数据集的散点图
三.总结
在本教程中,您发现了如何在 python 中安装和使用顶级聚类算法。具体来说,你学到了:
- 聚类是在特征空间输入数据中发现自然组的无监督问题。
- 有许多不同的聚类算法,对于所有数据集没有单一的最佳方法。
- 在 scikit-learn 机器学习库的 Python 中如何实现、适合和使用顶级聚类算法。
以上が10 個のクラスタリング アルゴリズムの完全な Python 操作例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。