




WeChat の人気に伴い、WeChat を使い始める人が増えています。 WeChat は単なるソーシャル ソフトウェアから生活手段へと徐々に変化し、人々は日常のコミュニケーションに WeChat を必要とし、仕事上のコミュニケーションにも WeChat が必要とされています。 WeChat のすべての友人は、人々が社会で果たすさまざまな役割を表しています。

今日の記事では、Python に基づいて WeChat の友達のデータ分析を行います。ここで選択される主な要素は次のとおりです: 性別、アバター、署名、場所。主にグラフとワード クラウドを使用します。結果は 2 つの形式で表示され、そのうちテキスト情報については単語頻度分析とセンチメント分析が使用されます。ことわざにあるように、労働者が自分の仕事をうまくやりたいなら、まず自分の道具を研ぎ澄まさなければなりません。この記事を正式に開始する前に、この記事で使用されているサードパーティ モジュールを簡単に紹介します。
itchat: WeChat Web バージョン インターフェイスは、この記事で WeChat の友人情報を取得するために使用される Python バージョンをカプセル化します。
jieba: この記事でテキスト情報をセグメント化するために使用される、吃音単語セグメント化の Python バージョン。
matplotlib: Python のチャート描画モジュール。この記事では、縦棒グラフと円グラフを描画するために使用されます。
snownlp: Python の中国語単語分割モジュール。この記事では、テキスト情報を分析するために使用されます。感情的に判断してください。
PIL: この記事では、Python の画像処理モジュールを使用して画像を処理します。
numpy: Python の数値計算モジュール。この記事では wordcloud モジュールと組み合わせて使用します。
wordcloud: この記事では、Python のワード クラウド モジュールを使用して、ワード クラウドの図を描画します。
TencentYoutuyun: Tencent Youtuyun が提供する Python 版 SDK は、この記事で顔を認識し、画像タグ情報を抽出するために使用されます。
上記のモジュールは pip を通じてインストールできます。各モジュールの使用方法の詳細については、それぞれのドキュメントを参照してください。
1. データ分析
WeChat の友人データを分析するための前提条件は、友人情報を取得することです。itchat モジュールを使用すると、これはすべて非常に簡単になります。次の 2 つの方法で実現できます。コード行。:
itchat.auto_login(hotReload = True) friends = itchat.get_friends(update = True)
Web バージョンの WeChat にログインするのと同じように、携帯電話で QR コードをスキャンしてログインできます。ここで返される friends オブジェクトはコレクションであり、最初の要素です現在のユーザーです。したがって、次のデータ分析プロセスでは、常に friends[1:] を元の入力データとして使用します。コレクション内の各要素は辞書構造になっています。私を例にとると、Sex、City、Province があることがわかります。 、HeadImgUrl、および Signature は 4 つのフィールドです。次の分析はこれら 4 つのフィールドから開始します:

2. 友人の性別
最初に友人の性別を分析します。すべての友人の性別情報を取得する必要があります。ここでは、各友人の情報の性別フィールドを抽出し、男性、女性、Unkonw の数をそれぞれ数えます。これら 3 つの値をリストにまとめます。matplotlib を使用します。円グラフを描画するモジュールです。コードは次のように実装されています:
def analyseSex(firends): sexs = list(map(lambda x:x['Sex'],friends[1:])) counts = list(map(lambda x:x[1],Counter(sexs).items())) labels = ['Unknow','Male','Female'] colors = ['red','yellowgreen','lightskyblue'] plt.figure(figsize=(8,5), dpi=80) plt.axes(aspect=1) plt.pie(counts, #性别统计结果 labels=labels, #性别展示标签 colors=colors, #饼图区域配色 labeldistance = 1.1, #标签距离圆点距离 autopct = '%3.1f%%', #饼图区域文本格式 shadow = False, #饼图是否显示阴影 startangle = 90, #饼图起始角度 pctdistance = 0.6 #饼图区域文本距离圆点距离 ) plt.legend(loc='upper right',) plt.title(u'%s的微信好友性别组成' % friends[0]['NickName']) plt.show()
このコードについて簡単に説明します。WeChat の性別フィールドの値には、Unkonw、男性、女性、およびそれらに対応する値が含まれます値はそれぞれ 0、1、2 です。これら 3 つの異なる値は、Collection モジュールの Counter() を通じてカウントされ、その items() メソッドはタプルのコレクションを返します。
タプルの 1 次元要素はキー (0、1、2) を表し、タプルの 2 次元要素は数値を表し、タプルのセットはソートされます。つまり、キーは 0、1、2 に従って順番に配置されているため、これら 3 つの異なる値の数は、map() メソッドを通じて取得でき、描画のために matplotlib に渡すことができます。 3 つの異なる値は matplotlib によって決定されます。次の図は、matplotlib によって描画された友人の性別分布図です:

3. 友人のアバター
友人のアバターを 2 つの側面から分析します。これらの友人アバターのうち、人顔アバターを使用している友人の割合はどのくらいでしょうか? 次に、これらの友人アバターからどのような貴重なキーワードを抽出できるかです。
ここでは、HeadImgUrl フィールドに基づいてアバターをローカルにダウンロードし、Tencent Youtu が提供する顔認識関連の API インターフェイスを使用して、アバター画像に顔があるかどうかを検出し、アバター画像内のタグを抽出する必要があります。画像。このうち、前者は分類と集計であり、結果の提示には円グラフを使用し、後者はテキスト分析で、結果の提示にはワードクラウドを使用します。キーコードは次のとおりです:
def analyseHeadImage(frineds):
# Init Path
basePath = os.path.abspath('.')
baseFolder = basePath + '\HeadImages\'
if(os.path.exists(baseFolder) == False):
os.makedirs(baseFolder)
# Analyse Images
faceApi = FaceAPI()
use_face = 0
not_use_face = 0
image_tags = ''
for index in range(1,len(friends)):
friend = friends[index]
# Save HeadImages
imgFile = baseFolder + '\Image%s.jpg' % str(index)
imgData = itchat.get_head_img(userName = friend['UserName'])
if(os.path.exists(imgFile) == False):
with open(imgFile,'wb') as file:
file.write(imgData)
# Detect Faces
time.sleep(1)
result = faceApi.detectFace(imgFile)
if result == True:
use_face += 1
else:
not_use_face += 1
# Extract Tags
result = faceApi.extractTags(imgFile)
image_tags += ','.join(list(map(lambda x:x['tag_name'],result)))
labels = [u'使用人脸头像',u'不使用人脸头像']
counts = [use_face,not_use_face]
colors = ['red','yellowgreen','lightskyblue']
plt.figure(figsize=(8,5), dpi=80)
plt.axes(aspect=1)
plt.pie(counts, #性别统计结果
labels=labels, #性别展示标签
colors=colors, #饼图区域配色
labeldistance = 1.1, #标签距离圆点距离
autopct = '%3.1f%%', #饼图区域文本格式
shadow = False, #饼图是否显示阴影
startangle = 90, #饼图起始角度
pctdistance = 0.6 #饼图区域文本距离圆点距离
)
plt.legend(loc='upper right',)
plt.title(u'%s的微信好友使用人脸头像情况' % friends[0]['NickName'])
plt.show()
image_tags = image_tags.encode('iso8859-1').decode('utf-8')
back_coloring = np.array(Image.open('face.jpg'))
wordcloud = WordCloud(
font_path='simfang.ttf',
background_color="white",
max_words=1200,
mask=back_coloring,
max_font_size=75,
random_state=45,
width=800,
height=480,
margin=15
)
wordcloud.generate(image_tags)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()这里我们会在当前目录新建一个HeadImages目录,用于存储所有好友的头像,然后我们这里会用到一个名为FaceApi类,这个类由腾讯优图的SDK封装而来,这里分别调用了人脸检测和图像标签识别两个API接口,前者会统计”使用人脸头像”和”不使用人脸头像”的好友各自的数目,后者会累加每个头像中提取出来的标签。其分析结果如下图所示:
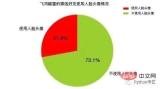
可以注意到,在所有微信好友中,约有接近1/4的微信好友使用了人脸头像, 而有接近3/4的微信好友没有人脸头像,这说明在所有微信好友中对”颜值 “有自信的人,仅仅占到好友总数的25%,或者说75%的微信好友行事风格偏低调为主,不喜欢用人脸头像做微信头像。
其次,考虑到腾讯优图并不能真正的识别”人脸”,我们这里对好友头像中的标签再次进行提取,来帮助我们了解微信好友的头像中有哪些关键词,其分析结果如图所示:

通过词云,我们可以发现:在微信好友中的签名词云中,出现频率相对较高的关键字有:女孩、树木、房屋、文本、截图、卡通、合影、天空、大海。这说明在我的微信好友中,好友选择的微信头像主要有日常、旅游、风景、截图四个来源。
好友选择的微信头像中风格以卡通为主,好友选择的微信头像中常见的要素有天空、大海、房屋、树木。通过观察所有好友头像,我发现在我的微信好友中,使用个人照片作为微信头像的有15人,使用网络图片作为微信头像的有53人,使用动漫图片作为微信头像的有25人,使用合照图片作为微信头像的有3人,使用孩童照片作为微信头像的有5人,使用风景图片作为微信头像的有13人,使用女孩照片作为微信头像的有18人,基本符合图像标签提取的分析结果。
4. 好友签名
分析好友签名,签名是好友信息中最为丰富的文本信息,按照人类惯用的”贴标签”的方法论,签名可以分析出某一个人在某一段时间里状态,就像人开心了会笑、哀伤了会哭,哭和笑两种标签,分别表明了人开心和哀伤的状态。
这里我们对签名做两种处理,第一种是使用结巴分词进行分词后生成词云,目的是了解好友签名中的关键字有哪些,哪一个关键字出现的频率相对较高;第二种是使用SnowNLP分析好友签名中的感情倾向,即好友签名整体上是表现为正面的、负面的还是中立的,各自的比重是多少。这里提取Signature字段即可,其核心代码如下:
def analyseSignature(friends):
signatures = ''
emotions = []
pattern = re.compile("1fd.+")
for friend in friends:
signature = friend['Signature']
if(signature != None):
signature = signature.strip().replace('span', '').replace('class', '').replace('emoji', '')
signature = re.sub(r'1f(d.+)','',signature)
if(len(signature)>0):
nlp = SnowNLP(signature)
emotions.append(nlp.sentiments)
signatures += ' '.join(jieba.analyse.extract_tags(signature,5))
with open('signatures.txt','wt',encoding='utf-8') as file:
file.write(signatures)
# Sinature WordCloud
back_coloring = np.array(Image.open('flower.jpg'))
wordcloud = WordCloud(
font_path='simfang.ttf',
background_color="white",
max_words=1200,
mask=back_coloring,
max_font_size=75,
random_state=45,
width=960,
height=720,
margin=15
)
wordcloud.generate(signatures)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
wordcloud.to_file('signatures.jpg')
# Signature Emotional Judgment
count_good = len(list(filter(lambda x:x>0.66,emotions)))
count_normal = len(list(filter(lambda x:x>=0.33 and x<=0.66,emotions)))
count_bad = len(list(filter(lambda x:x<0.33,emotions)))
labels = [u'负面消极',u'中性',u'正面积极']
values = (count_bad,count_normal,count_good)
plt.rcParams['font.sans-serif'] = ['simHei']
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel(u'情感判断')
plt.ylabel(u'频数')
plt.xticks(range(3),labels)
plt.legend(loc='upper right',)
plt.bar(range(3), values, color = 'rgb')
plt.title(u'%s的微信好友签名信息情感分析' % friends[0]['NickName'])
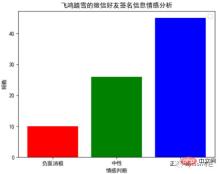
plt.show()通过词云,我们可以发现:在微信好友的签名信息中,出现频率相对较高的关键词有:努力、长大、美好、快乐、生活、幸福、人生、远方、时光、散步。

通过以下柱状图,我们可以发现:在微信好友的签名信息中,正面积极的情感判断约占到55.56%,中立的情感判断约占到32.10%,负面消极的情感判断约占到12.35%。这个结果和我们通过词云展示的结果基本吻合,这说明在微信好友的签名信息中,约有87.66%的签名信息,传达出来都是一种积极向上的态度。
5. 好友位置
分析好友位置,主要通过提取Province和City这两个字段。Python中的地图可视化主要通过Basemap模块,这个模块需要从国外网站下载地图信息,使用起来非常的不便。
百度的ECharts在前端使用的比较多,虽然社区里提供了pyecharts项目,可我注意到因为政策的改变,目前Echarts不再支持导出地图的功能,所以地图的定制方面目前依然是一个问题,主流的技术方案是配置全国各省市的JSON数据。
这里我使用的是BDP个人版,这是一个零编程的方案,我们通过Python导出一个CSV文件,然后将其上传到BDP中,通过简单拖拽就可以制作可视化地图,简直不能再简单,这里我们仅仅展示生成CSV部分的代码:
def analyseLocation(friends):
headers = ['NickName','Province','City']
with open('location.csv','w',encoding='utf-8',newline='',) as csvFile:
writer = csv.DictWriter(csvFile, headers)
writer.writeheader()
for friend in friends[1:]:
row = {}
row['NickName'] = friend['NickName']
row['Province'] = friend['Province']
row['City'] = friend['City']
writer.writerow(row)下图是BDP中生成的微信好友地理分布图,可以发现:我的微信好友主要集中在宁夏和陕西两个省份。
6. 总结
这篇文章是我对数据分析的又一次尝试,主要从性别、头像、签名、位置四个维度,对微信好友进行了一次简单的数据分析,主要采用图表和词云两种形式来呈现结果。总而言之一句话,”数据可视化是手段而并非目的”,重要的不是我们在这里做了这些图出来,而是从这些图里反映出来的现象,我们能够得到什么本质上的启示,希望这篇文章能让大家有所启发。
以上がPython を使って WeChat の友達をクロールしました。彼らはこんな感じです...の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Pythonと時間:勉強時間を最大限に活用するApr 14, 2025 am 12:02 AM
Pythonと時間:勉強時間を最大限に活用するApr 14, 2025 am 12:02 AM限られた時間でPythonの学習効率を最大化するには、PythonのDateTime、時間、およびスケジュールモジュールを使用できます。 1. DateTimeモジュールは、学習時間を記録および計画するために使用されます。 2。時間モジュールは、勉強と休息の時間を設定するのに役立ちます。 3.スケジュールモジュールは、毎週の学習タスクを自動的に配置します。
 Python:ゲーム、GUIなどApr 13, 2025 am 12:14 AM
Python:ゲーム、GUIなどApr 13, 2025 am 12:14 AMPythonはゲームとGUI開発に優れています。 1)ゲーム開発は、2Dゲームの作成に適した図面、オーディオ、その他の機能を提供し、Pygameを使用します。 2)GUI開発は、TKINTERまたはPYQTを選択できます。 TKINTERはシンプルで使いやすく、PYQTは豊富な機能を備えており、専門能力開発に適しています。
 Python vs. C:比較されたアプリケーションとユースケースApr 12, 2025 am 12:01 AM
Python vs. C:比較されたアプリケーションとユースケースApr 12, 2025 am 12:01 AMPythonは、データサイエンス、Web開発、自動化タスクに適していますが、Cはシステムプログラミング、ゲーム開発、組み込みシステムに適しています。 Pythonは、そのシンプルさと強力なエコシステムで知られていますが、Cは高性能および基礎となる制御機能で知られています。
 2時間のPython計画:現実的なアプローチApr 11, 2025 am 12:04 AM
2時間のPython計画:現実的なアプローチApr 11, 2025 am 12:04 AM2時間以内にPythonの基本的なプログラミングの概念とスキルを学ぶことができます。 1.変数とデータ型、2。マスターコントロールフロー(条件付きステートメントとループ)、3。機能の定義と使用を理解する4。
 Python:主要なアプリケーションの調査Apr 10, 2025 am 09:41 AM
Python:主要なアプリケーションの調査Apr 10, 2025 am 09:41 AMPythonは、Web開発、データサイエンス、機械学習、自動化、スクリプトの分野で広く使用されています。 1)Web開発では、DjangoおよびFlask Frameworksが開発プロセスを簡素化します。 2)データサイエンスと機械学習の分野では、Numpy、Pandas、Scikit-Learn、Tensorflowライブラリが強力なサポートを提供します。 3)自動化とスクリプトの観点から、Pythonは自動テストやシステム管理などのタスクに適しています。
 2時間でどのくらいのPythonを学ぶことができますか?Apr 09, 2025 pm 04:33 PM
2時間でどのくらいのPythonを学ぶことができますか?Apr 09, 2025 pm 04:33 PM2時間以内にPythonの基本を学ぶことができます。 1。変数とデータ型を学習します。2。ステートメントやループの場合などのマスター制御構造、3。関数の定義と使用を理解します。これらは、簡単なPythonプログラムの作成を開始するのに役立ちます。
 プロジェクトの基本と問題駆動型の方法で10時間以内にコンピューター初心者プログラミングの基本を教える方法は?Apr 02, 2025 am 07:18 AM
プロジェクトの基本と問題駆動型の方法で10時間以内にコンピューター初心者プログラミングの基本を教える方法は?Apr 02, 2025 am 07:18 AM10時間以内にコンピューター初心者プログラミングの基本を教える方法は?コンピューター初心者にプログラミングの知識を教えるのに10時間しかない場合、何を教えることを選びますか...
 中間の読書にどこでもfiddlerを使用するときにブラウザによって検出されないようにするにはどうすればよいですか?Apr 02, 2025 am 07:15 AM
中間の読書にどこでもfiddlerを使用するときにブラウザによって検出されないようにするにはどうすればよいですか?Apr 02, 2025 am 07:15 AMfiddlereveryversings for the-middleの測定値を使用するときに検出されないようにする方法


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

ドリームウィーバー CS6
ビジュアル Web 開発ツール

WebStorm Mac版
便利なJavaScript開発ツール

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

