
ホームページ >テクノロジー周辺機器 >AI >モジュール式機械学習システムは十分ですか?ベンジオの教師と生徒が答えを教えます
モジュール式機械学習システムは十分ですか?ベンジオの教師と生徒が答えを教えます

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-12 22:49:071230ブラウズ
ディープラーニングの研究者は、神経科学と認知科学からインスピレーションを得ており、隠れユニットや入力方法からネットワーク接続やネットワーク アーキテクチャの設計に至るまで、多くの画期的な研究が脳の動作戦略の模倣に基づいています。近年、モジュール性と注意力が人工ネットワークで頻繁に組み合わせて使用され、目覚ましい成果を上げていることは疑いの余地がありません。
実際、認知神経科学の研究によると、大脳皮質は、異なるモジュール間のコミュニケーションと、上で述べた内容選択のための注意メカニズムを備えたモジュール式の方法で知識を表現しています。前述のモジュール性とアテンションの組み合わせが使用されます。最近の研究では、脳内のこの通信モードが深層ネットワークにおける誘導バイアスに影響を与える可能性があることが示唆されています。これらの高レベルの変数間の依存関係がまばらであるため、知識が可能な限り独立した組み換え可能な断片に分割され、学習がより効率的になります。
最近の研究の多くはこのようなモジュール式アーキテクチャに依存していますが、研究者は、実際の使用可能なシステムの分析を可能にする多数の技術とアーキテクチャの変更を使用してきました。
機械学習システムは、よりスパースでモジュラー アーキテクチャの利点が徐々に明らかになりつつあります。モジュラー アーキテクチャは、汎化パフォーマンスが優れているだけでなく、分散外の分散も向上します。(OoD)一般化、スケーラビリティ、学習速度、解釈可能性。このようなシステムの成功の鍵は、現実世界の設定で使用されるデータ生成システムがまばらに相互作用する部品で構成されていると考えられており、モデルに同様の帰納的バイアスを与えると役立つことです。しかし、これらの実世界のデータ分布は複雑で未知であるため、この分野ではこれらのシステムの厳密な定量的評価が不足していました。
カナダのモントリオール大学の 3 人の研究者: Sarthak Mittal、Yoshua Bengio、Guillaume Lajoie によって書かれた論文。彼らは、シンプルで既知のモジュール データ分散を使用して、一般的なモジュールを分析しました。アーキテクチャの包括的な評価が実施されました。この調査では、モジュール性とスパース性の利点に焦点を当て、モジュール式システムを最適化する際に直面する課題についての洞察が明らかになります。筆頭著者であり責任著者であるサルタック・ミタルは、ベンジオとラジョイエの修士課程の学生です。

- #論文アドレス: https://arxiv.org/pdf/2206.02713.pdf
- GitHub アドレス: https://github.com/sarthmit/Mod_Arch
- この調査は、確率的選択ルールに基づいてベンチマーク タスクとメトリクスを開発し、ベンチマークとメトリクスを使用してモジュール性を定量化する システムにおける 2 つの重要な現象、崩壊と特殊化。
- この調査では、一般的に使用されるモジュラー誘導性バイアスを抽出し、一般的に使用されるアーキテクチャ特性を抽出するように設計された一連のモデル (モノリシック、モジュラー、モジュラーオペ、GT-モジュラー モデル) を通じてそれらを体系的に評価します。
- この研究では、タスク内に潜在的なルールが多数ある場合には、モジュラー システムの特殊化によりモデルのパフォーマンスが大幅に向上しますが、ルールが少ない場合にはそうではないことがわかりました。
- 調査では、標準的なモジュラー システムは、適切な情報に焦点を当てる能力と専門化する能力の両方の点で最適ではない傾向があることが判明し、追加の帰納的バイアスの必要性を示唆しています。
 #########ルール。モジュール式システムを適切に理解し、その利点と欠点を分析するために、研究者らは、さまざまなタスク要件をきめ細かく制御できる包括的なセットアップを検討しました。特に、ルールと呼ばれる操作は、以下の式 1-3 に示すデータ生成分布で学習する必要があります。
#########ルール。モジュール式システムを適切に理解し、その利点と欠点を分析するために、研究者らは、さまざまなタスク要件をきめ細かく制御できる包括的なセットアップを検討しました。特に、ルールと呼ばれる操作は、以下の式 1-3 に示すデータ生成分布で学習する必要があります。

 モデル アーキテクチャ。モデル アーキテクチャは、モジュラー システムの各モジュール、またはモノリシック システムの個々のモジュールにどのようなアーキテクチャが選択されるかを記述します。この論文では、研究者らは多層パーセプトロン (MLP)、マルチヘッド アテンション (MHA)、リカレント ニューラル ネットワーク (RNN) の使用を検討しています。ルール (またはデータ生成ディストリビューション) が、MLP ベースのルールなどのモデル アーキテクチャに適合するように調整されることが重要です。
モデル アーキテクチャ。モデル アーキテクチャは、モジュラー システムの各モジュール、またはモノリシック システムの個々のモジュールにどのようなアーキテクチャが選択されるかを記述します。この論文では、研究者らは多層パーセプトロン (MLP)、マルチヘッド アテンション (MHA)、リカレント ニューラル ネットワーク (RNN) の使用を検討しています。ルール (またはデータ生成ディストリビューション) が、MLP ベースのルールなどのモデル アーキテクチャに適合するように調整されることが重要です。
データ生成プロセス
研究者の目標は合成データを通じてモジュラー システムを探索することであるため、データ生成の説明を詳しく紹介しました。ルールスキームのプロセス。具体的には、研究者らは、ルールの異なるモジュールが異なる専門家に特化できることを期待して、単純な専門家混合 (MoE) スタイルのデータ生成プロセスを使用しました。
MLP、MHA、RNN という 3 つのモデル アーキテクチャのデータ生成プロセスについて説明します。さらに、各タスクの下には、回帰と分類という 2 つのバージョンがあります。
MLP。研究者らは、モジュール型 MLP システムに基づいた学習に適したデータ スキームを定義しました。この合成データ生成スキームでは、データ サンプルは 2 つの独立した数値と、何らかの分布からサンプリングされた通常の選択で構成されます。異なるルールにより 2 つの数値の異なる線形結合が生成され、出力が得られます。つまり、線形結合の選択は、以下の式 4-6 に示すように、ルールに従って動的にインスタンス化されます。
#MHA。今回、研究者らは、モジュール式 MHA システムでの学習用に調整されたデータ スキームを定義しました。したがって、彼らは次の特性を備えたデータ生成分布を設計しました。各ルールは、異なる検索、取得の概念、および取得された情報の最終的な線形結合で構成されます。研究者は、このプロセスを以下の式 7-11 で数学的に説明します。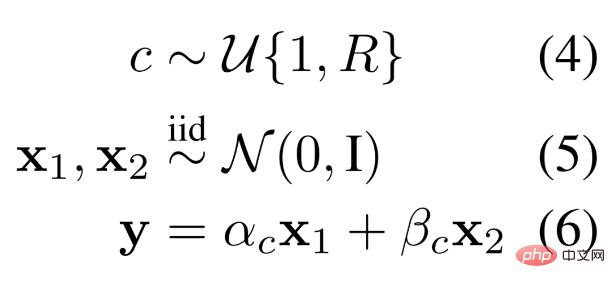


モデル
これまでの研究の中には、特に分散環境では、エンドツーエンドでトレーニングされたモジュール システムが単一システムよりも優れていると主張されたものもあります。ただし、これらのモジュラー システムの利点や、実際にデータ生成の分布に基づいて特化しているかどうかについては、詳細かつ詳細な分析は行われていません。
したがって、研究者らは、さまざまな程度の専門化を可能にする 4 つのタイプのモデル、すなわち Monolithic (単一)、Modular (モジュール式)、Modular-op、および GT-Modular を検討しました。以下の表 1 は、これらのモデルを示しています。

モノリシック。モノリシック システムは、データ (x, c) のセット全体を入力として受け取り、それに基づいて予測 y^ を行う大規模なニューラル ネットワークです。システム内の明示的にベイクされたシステムのモジュール性またはスパース性は、誘導バイアスの影響を受けず、タスクを解決するために必要な関数形式を学習するために完全に逆伝播に依存します。 ############モジュラー。モジュラー システムは多くのモジュールで構成されており、各モジュールは特定のアーキテクチャ タイプ (MLP、MHA、または RNN) のニューラル ネットワークです。各モジュール m はデータ (x, c) を入力として受け取り、出力 y^_m と信頼度スコアを計算します。これらはモジュール全体で活性化確率 p_m に正規化されます。
モジュラー演算。モジュラー オペレーティング システムはモジュラー システムとよく似ていますが、1 つ違いがあります。研究者らは、モジュール m のアクティベーション確率 p_m を (x, c) の関数として定義する代わりに、アクティベーションがルール コンテキスト C によってのみ決定されるようにしました。
GT モジュラー。真の価値を持つモジュラー システムは、オラクルのベンチマークとして機能します。つまり、完全に特化されたモジュラー システムです。
研究者らは、モノリシックから GT-モジュラーに至るまで、モデルにはモジュール性とスパース性に対する誘導バイアスがますます含まれることを示しています。
メトリクス
モジュラー システムを確実に評価するために、研究者は、そのようなシステムのパフォーマンス上の利点を測定できるだけでなく、また、崩壊と専門化という 2 つの重要な形式を通じて評価することもできます。 ############パフォーマンス。評価メトリクスの最初のセットは、ディストリビューション内とディストリビューション外 (OoD) 設定の両方のパフォーマンスに基づいており、さまざまなタスクにおけるさまざまなモデルのパフォーマンスを反映しています。分類設定の場合は分類エラーを報告し、回帰設定の場合は損失を報告します。 ############崩壊。研究者らは、モジュラーシステムが遭遇する崩壊の量(つまり、モジュールが十分に活用されていない程度)を定量化するために、一連の指標「Collapse-Avg」と「Collapse-Worst」を提案しました。以下の図 2 は、モジュール 3 が使用されていないことがわかる例を示しています。
専門化。崩壊メトリクスを補完するために、モジュール式システムによって達成される特殊化の程度を定量化する、次のメトリクスのセット、すなわち (1) アラインメント、(2) 適応、および (3) 逆相互情報量も提案します。
実験
下の図は、GT-Modular システムがほとんどの場合に最適であることを示しています (左)。これは、特化することが有益であることを示しています。また、標準的なエンドツーエンドでトレーニングされたモジュラー システムとモノリシック システムの間では、前者の方が後者のパフォーマンスを上回っていますが、それほど優れているわけではありません。これら 2 つの円グラフを総合すると、エンドツーエンド トレーニング用の現在のモジュール式システムが十分な専門化を達成しておらず、したがってほとんど最適化されていないことがわかります。
調査では、特定のアーキテクチャ上の選択肢を検討し、増大する一連のルールのパフォーマンスと傾向にわたってそれらを分析します。 。
圖4 顯示,雖然完美的專業化系統(GT-Modular) 會帶來好處,但典型的端到端訓練的模組化系統是次優的,不能實現這些好處,特別是隨著規則數量的增加。此外,雖然這種端對端模組化系統的性能通常優於 Monolithic 系統,但通常只有很小的優勢。

在圖7 中,我們也看到不同模型的訓練模式在所有其他設定上的平均值,平均值包含分類錯誤和迴歸損失。可以看到,良好的專業化不僅可以帶來更好的性能,而且可以加快訓練速度。

下圖顯示了兩個崩潰量測:Collapse-Avg 、Collapse-Worst。此外下圖還顯示了針對不同規則數量的不同模型的三個專業化指標,對齊、適應和逆互資訊:

以上がモジュール式機械学習システムは十分ですか?ベンジオの教師と生徒が答えを教えますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。