
ホームページ >テクノロジー周辺機器 >AI >sklearn の 2 つの半教師ありラベル伝播アルゴリズム: LabelPropagation と LabelSpreading
sklearn の 2 つの半教師ありラベル伝播アルゴリズム: LabelPropagation と LabelSpreading

- 王林転載
- 2023-04-12 19:28:041222ブラウズ
ラベル伝播アルゴリズムは、以前にラベルが付けられていないデータ ポイントにラベルを割り当てる半教師あり機械学習アルゴリズムです。このアルゴリズムを機械学習で使用するには、サンプルのごく一部のみにラベルまたは分類が必要です。これらのラベルは、アルゴリズムのモデリング、フィッティング、予測プロセス中にラベルのないデータ ポイントに伝播されます。

LabelPropagation
LabelPropagation は、グラフ内のコミュニティを見つけるための高速アルゴリズムです。これらの接続を検出するためのガイドとしてネットワーク構造のみを使用し、事前定義された目的関数や母集団に関する先験的な情報を必要としません。タグの伝播は、ネットワーク内でタグを伝播し、タグの伝播プロセスに基づいて接続を形成することによって実現されます。
終了タグには通常、同じタグが付けられます。単一のラベルは、密に接続されたノードのグループでは優位に立つことができますが、疎に接続された領域では問題が発生します。ラベルは密接に接続されたノードのグループに制限され、アルゴリズムが完了すると、同じラベルを持つノードは同じ接続の一部と見なすことができます。このアルゴリズムはグラフ理論を使用しており、次のとおりです。-
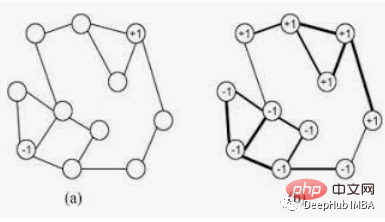
LabelPropagation アルゴリズムは次のように機能します。-
- 各ノードは一意のタグを使用します。初期化されます。
- これらのタグはインターネットを通じて広がります。
- 各伝播反復で、各ノードはそのラベルを、最大数の隣接ノードが属するラベルに更新します。
- ラベル伝播アルゴリズムは、各ノードが隣接ノードのラベルの大部分を持っているときに収束に達します。
- ラベル伝播アルゴリズムは、収束またはユーザー定義の最大反復回数に達すると停止します。
LabelPropagation アルゴリズムがどのように機能するかを示すために、ピマ インディアン データ セットを使用します。プログラムを作成するときに、その実行に必要なライブラリをインポートしました

データのコピーをコピーし、ラベル列をトレーニング ターゲットとして使用します

matplotlib 視覚化を使用します:

ランダムを使用する ナンバー ジェネレーターは、データセット内のラベルの 70% をランダム化します。次に、ランダムなラベルが割り当てられます -1:-
データの前処理後、従属変数と独立変数 (それぞれ y と X) を定義します。 y 変数は最後の列であり、
 ##それを見つける正確率は 76.9% です。
##それを見つける正確率は 76.9% です。
 別のアルゴリズムである LabelSpreading を見てみましょう。
別のアルゴリズムである LabelSpreading を見てみましょう。
LabelSpreading
LabelSpreading も人気のある半教師あり学習方法です。トレーニング データセット内のサンプルを接続するグラフを作成し、既知のラベルをグラフの端に伝播して、ラベルのないサンプルにラベルを付けます。 
L はラプラシアン行列、D は次数行列、A は隣接行列です。
以下は、無向グラフのラベル付けとそのラプラシアン行列の結果の簡単な例です。

この記事では、ソナー データ セットを使用して、次の方法を説明します。 sklearnのLabelSpreading関数を使用します。
ここには上記よりも多くのライブラリがあるため、簡単に説明します:
- Numpy は数値計算を実行し、Numpy 配列を作成します
- Pandas はデータを処理します
- Sklearn は機械学習操作を実行します #Matplotlib と seaborn を使用してデータを視覚化し、視覚データの統計情報を提供します
- #Warning、プログラムの実行中に発生する警告を無視するために使用されます
- #インポートが完了したら、pandas を使用してデータ セットを読み取ります:
seaborn を使用してヒート マップを作成しました:-
最初に簡単な前処理を実行し、相関性の高い列を削除して、列の数を 61 から 58 に減らします。 



 この方法を使用すると、87.98% の精度を達成できます:-
この方法を使用すると、87.98% の精度を達成できます:-
 単純な比較
単純な比較
1. ラベルスプレッドには alpha= 0.2 が含まれます。 , アルファはクランプ係数と呼ばれ、初期ラベルの代わりに隣接するラベルの情報を使用する相対的な量を指します。0 の場合、初期ラベル情報を保持することを意味します。1 の場合、すべてのラベルを置き換えることを意味します。初期情報; alpha=0.2 に設定、元のラベル情報の 80% が常に保持されることを意味します;
2. ラベル伝播は、データから構築された元の類似度行列を変更せずに使用します; ラベルスプレッドは、正則化特性を使用して損失関数を最小化しますノイズに対してより堅牢で、元のグラフの修正バージョンを反復処理し、正規化されたラプラシアン行列を計算することでエッジの重みを正規化します。
3. 同時に、LabelSpreading は多くの CPU を占有し、物理メモリ占有率は悪くありません。LabelPropagation の CPU 占有率は悪くありませんが、多くの物理メモリを占有し、問題が発生する可能性があります。高緯度のデータには問題がある可能性があります。 
以上がsklearn の 2 つの半教師ありラベル伝播アルゴリズム: LabelPropagation と LabelSpreadingの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。