
ホームページ >バックエンド開発 >Python チュートリアル >1 行の Python コードで並列処理を実現
1 行の Python コードで並列処理を実現

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-12 19:04:29999ブラウズ

#Python は、プログラムの並列処理に関しては、やや悪い評判があります。スレッドの実装やGILなどの技術的な問題はさておき、間違った指導指導が一番の問題だと感じます。一般的な古典的な Python のマルチスレッドおよびマルチプロセスのチュートリアルは「重い」傾向があります。そして、日常業務で最も役立つ内容を深く掘り下げることなく、表面をなぞるだけのことがよくあります。
従来の例
「Python マルチスレッド チュートリアル」で簡単に検索すると、ほとんどのものが見つかります。すべてのチュートリアル クラスとキューに関する例が示されています。:
import os
import PIL
from multiprocessing import Pool
from PIL import Image
SIZE = (75,75)
SAVE_DIRECTORY = 'thumbs'
def get_image_paths(folder):
return (os.path.join(folder, f)
for f in os.listdir(folder)
if 'jpeg' in f)
def create_thumbnail(filename):
im = Image.open(filename)
im.thumbnail(SIZE, Image.ANTIALIAS)
base, fname = os.path.split(filename)
save_path = os.path.join(base, SAVE_DIRECTORY, fname)
im.save(save_path)
if __name__ == '__main__':
folder = os.path.abspath(
'11_18_2013_R000_IQM_Big_Sur_Mon__e10d1958e7b766c3e840')
os.mkdir(os.path.join(folder, SAVE_DIRECTORY))
images = get_image_paths(folder)
pool = Pool()
pool.map(creat_thumbnail, images)
pool.close()
pool.join()
ハッ、これは Java に似ていますね。
私は、マルチスレッド/マルチプロセスのタスクにプロデューサー/コンシューマー モデルを使用することが間違っていると言っているわけではありません (実際、このモデルには適切なところがあります)。ただし、日常的なスクリプト タスクを処理する場合は、より効率的なモデルを使用できます。
問題は...
まず、ボイラープレート クラスが必要です。
次に、オブジェクトを渡すにはキューが必要です;
さらに、その作業を支援するために、チャネルの両端に対応するメソッドを構築する必要もあります (双方向通信を実行する必要がある場合、または結果を保存する必要がある場合は、キュー)。
ワーカーが増えるほど、問題も増える
この考え方によると、ワーカー スレッドのスレッドが必要になります。プール。以下は、古典的な IBM チュートリアルの例です。Web ページを取得する際のマルチスレッドによる高速化です。
#Example2.py
'''
A more realistic thread pool example
'''
import time
import threading
import Queue
import urllib2
class Consumer(threading.Thread):
def __init__(self, queue):
threading.Thread.__init__(self)
self._queue = queue
def run(self):
while True:
content = self._queue.get()
if isinstance(content, str) and content == 'quit':
break
response = urllib2.urlopen(content)
print 'Bye byes!'
def Producer():
urls = [
'http://www.python.org', 'http://www.yahoo.com'
'http://www.scala.org', 'http://www.google.com'
# etc..
]
queue = Queue.Queue()
worker_threads = build_worker_pool(queue, 4)
start_time = time.time()
# Add the urls to process
for url in urls:
queue.put(url)
# Add the poison pillv
for worker in worker_threads:
queue.put('quit')
for worker in worker_threads:
worker.join()
print 'Done! Time taken: {}'.format(time.time() - start_time)
def build_worker_pool(queue, size):
workers = []
for _ in range(size):
worker = Consumer(queue)
worker.start()
workers.append(worker)
return workers
if __name__ == '__main__':
Producer()
このコードは正しく実行されますが、やるべきことを詳しく見てみましょう: さまざまなメソッドを構築し、一連のスレッドを追跡し、厄介なデッドロックを解決する必要があります。一連の結合操作を実行します。これはほんの始まりにすぎません...
これまで、古典的なマルチスレッド チュートリアルをレビューしてきましたが、これはやや空っぽですよね。半分の労力で 2 倍の結果が得られるこのスタイルは、面倒でエラーが発生しやすいため、日常的な使用には明らかに適していません。
mapを試してみませんか
map この小さくて精巧な関数は、Python プログラムを簡単に並列化するための鍵です。 Map は Lisp などの関数型プログラミング言語に由来します。シーケンスを通じて 2 つの関数間のマッピングを実現できます。
urls = ['http://www.yahoo.com', 'http://www.reddit.com']
results = map(urllib2.urlopen, urls)
上記の 2 行のコードは、url シーケンスの各要素をパラメータとして urlopen メソッドに渡し、すべての結果を結果リストに保存します。結果は次とほぼ同等になります。
results = []
for url in urls:
results.append(urllib2.urlopen(url))
map 関数は、シーケンス操作、パラメーターの受け渡し、結果の保存などの一連の操作を単独で処理します。 ############何でこれが大切ですか?これは、マップ操作を適切なライブラリを使用して簡単に並列化できるためです。
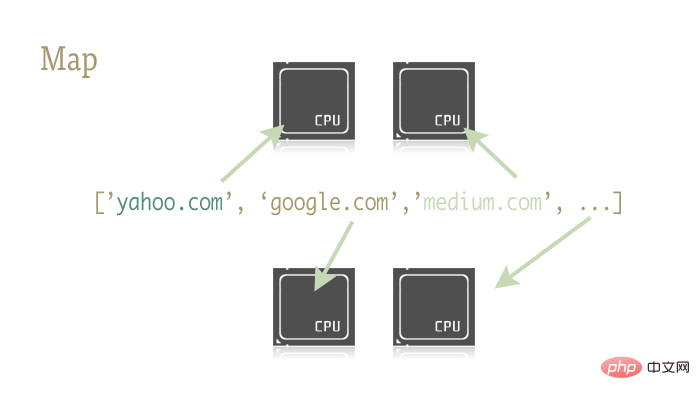 Python には、map 関数を含む 2 つのライブラリがあります。 multiprocessing と、あまり知られていないそのサブライブラリ multiprocessing です。 dummy.
Python には、map 関数を含む 2 つのライブラリがあります。 multiprocessing と、あまり知られていないそのサブライブラリ multiprocessing です。 dummy.
ここにさらにいくつかの文があります: multiprocessing.dummy? mltiprocessing ライブラリのスレッド クローン?これはエビですか?マルチプロセッシング ライブラリの公式ドキュメントでも、このサブライブラリに関する関連説明は 1 つだけです。そして、この説明を大人向けの言葉に翻訳すると、基本的には次のような意味になります。「まあ、そういうものがあるんだ、とにかく知っておいてください。」信じてください、この図書館はかなり過小評価されています。
dummy はマルチプロセッシング モジュールの完全なクローンです。唯一の違いは、マルチプロセッシングがプロセスで動作するのに対し、ダミー モジュールはスレッドで動作することです (したがって、Python の通常のマルチスレッド制限がすべて含まれます)。 。 したがって、これら 2 つのライブラリを置き換えるのは非常に簡単です。 IO 集中型のタスクと CPU 集中型のタスクに対して異なるライブラリを選択できます。
実際に手に取ってみましょう
次の 2 行のコードを使用して、並列化されたマップを含むライブラリを参照します。 function:
from multiprocessing import Pool from multiprocessing.dummy import Pool as ThreadPool
Pool オブジェクトをインスタンス化します:
pool = ThreadPool()
この単純なステートメントは、例 2 の buildworker
pool 関数を置き換えます。 .py 7 行のコードが機能します。一連のワーカー スレッドを生成して初期化し、簡単にアクセスできるように変数に格納します。Pool オブジェクトにはいくつかのパラメーターがあり、ここで注意する必要があるのは、その最初のパラメーターであるプロセスだけです。このパラメーターは、スレッド プール内のスレッドの数を設定するために使用されます。デフォルト値は、現在のマシンの CPU のコア数です。
一般的に、CPU を大量に使用するタスクを実行する場合、呼び出されるコアの数が増えるほど高速になります。ただし、ネットワークを集中的に使用するタスクを扱う場合は、状況が少し予測不能になるため、スレッド プールのサイズを決定するために実験することが賢明です。
pool = ThreadPool(4) # Sets the pool size to 4
线程数过多时,切换线程所消耗的时间甚至会超过实际工作时间。对于不同的工作,通过尝试来找到线程池大小的最优值是个不错的主意。
创建好 Pool 对象后,并行化的程序便呼之欲出了。我们来看看改写后的 example2.py
import urllib2
from multiprocessing.dummy import Pool as ThreadPool
urls = [
'http://www.python.org',
'http://www.python.org/about/',
'http://www.onlamp.com/pub/a/python/2003/04/17/metaclasses.html',
'http://www.python.org/doc/',
'http://www.python.org/download/',
'http://www.python.org/getit/',
'http://www.python.org/community/',
'https://wiki.python.org/moin/',
'http://planet.python.org/',
'https://wiki.python.org/moin/LocalUserGroups',
'http://www.python.org/psf/',
'http://docs.python.org/devguide/',
'http://www.python.org/community/awards/'
# etc..
]
# Make the Pool of workers
pool = ThreadPool(4)
# Open the urls in their own threads
# and return the results
results = pool.map(urllib2.urlopen, urls)
#close the pool and wait for the work to finish
pool.close()
pool.join()
实际起作用的代码只有 4 行,其中只有一行是关键的。map 函数轻而易举的取代了前文中超过 40 行的例子。为了更有趣一些,我统计了不同方法、不同线程池大小的耗时情况。
# results = [] # for url in urls: # result = urllib2.urlopen(url) # results.append(result) # # ------- VERSUS ------- # # # ------- 4 Pool ------- # # pool = ThreadPool(4) # results = pool.map(urllib2.urlopen, urls) # # ------- 8 Pool ------- # # pool = ThreadPool(8) # results = pool.map(urllib2.urlopen, urls) # # ------- 13 Pool ------- # # pool = ThreadPool(13) # results = pool.map(urllib2.urlopen, urls)
结果:
# Single thread: 14.4 Seconds # 4 Pool: 3.1 Seconds # 8 Pool: 1.4 Seconds # 13 Pool: 1.3 Seconds
很棒的结果不是吗?这一结果也说明了为什么要通过实验来确定线程池的大小。在我的机器上当线程池大小大于 9 带来的收益就十分有限了。
另一个真实的例子
生成上千张图片的缩略图
这是一个 CPU 密集型的任务,并且十分适合进行并行化。
基础单进程版本
import os
import PIL
from multiprocessing import Pool
from PIL import Image
SIZE = (75,75)
SAVE_DIRECTORY = 'thumbs'
def get_image_paths(folder):
return (os.path.join(folder, f)
for f in os.listdir(folder)
if 'jpeg' in f)
def create_thumbnail(filename):
im = Image.open(filename)
im.thumbnail(SIZE, Image.ANTIALIAS)
base, fname = os.path.split(filename)
save_path = os.path.join(base, SAVE_DIRECTORY, fname)
im.save(save_path)
if __name__ == '__main__':
folder = os.path.abspath(
'11_18_2013_R000_IQM_Big_Sur_Mon__e10d1958e7b766c3e840')
os.mkdir(os.path.join(folder, SAVE_DIRECTORY))
images = get_image_paths(folder)
for image in images:
create_thumbnail(Image)
上边这段代码的主要工作就是将遍历传入的文件夹中的图片文件,一一生成缩略图,并将这些缩略图保存到特定文件夹中。
这我的机器上,用这一程序处理 6000 张图片需要花费 27.9 秒。
如果我们使用 map 函数来代替 for 循环:
import os
import PIL
from multiprocessing import Pool
from PIL import Image
SIZE = (75,75)
SAVE_DIRECTORY = 'thumbs'
def get_image_paths(folder):
return (os.path.join(folder, f)
for f in os.listdir(folder)
if 'jpeg' in f)
def create_thumbnail(filename):
im = Image.open(filename)
im.thumbnail(SIZE, Image.ANTIALIAS)
base, fname = os.path.split(filename)
save_path = os.path.join(base, SAVE_DIRECTORY, fname)
im.save(save_path)
if __name__ == '__main__':
folder = os.path.abspath(
'11_18_2013_R000_IQM_Big_Sur_Mon__e10d1958e7b766c3e840')
os.mkdir(os.path.join(folder, SAVE_DIRECTORY))
images = get_image_paths(folder)
pool = Pool()
pool.map(creat_thumbnail, images)
pool.close()
pool.join()
5.6 秒!
虽然只改动了几行代码,我们却明显提高了程序的执行速度。在生产环境中,我们可以为 CPU 密集型任务和 IO 密集型任务分别选择多进程和多线程库来进一步提高执行速度——这也是解决死锁问题的良方。此外,由于 map 函数并不支持手动线程管理,反而使得相关的 debug 工作也变得异常简单。
到这里,我们就实现了(基本)通过一行 Python 实现并行化。
译者:caspar
译文:https://www.php.cn/link/687fe34a901a03abed262a62e22f90dbm/a/1190000000414339
原文:https://medium.com/building-things-on-the-internet/40e9b2b36148
以上が1 行の Python コードで並列処理を実現の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。