
ホームページ >テクノロジー周辺機器 >AI >AIアルゴリズムによるデータベース異常監視システムの設計・導入
AIアルゴリズムによるデータベース異常監視システムの設計・導入

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-12 18:37:06969ブラウズ
著者: Cao Zhenweiyuan
美団データベース プラットフォームの研究開発チームは、データベースの異常を発見するというますます緊急なニーズに直面しています。より迅速かつインテリジェントに発見、特定、損失を阻止するために、データベースを開発しました。 AI アルゴリズムに基づく異常検出サービス。
1. 背景
データベースは、高い安定性要件と非常に低い例外許容度を備えた Meituan の中核ビジネス シナリオで広く使用されています。したがって、データベースの異常を迅速に発見し、位置を特定し、ストップロスを検出することがますます重要になります。異常監視の問題に対して、従来の固定しきい値アラーム方式では、ルールの設定に専門家の経験が必要であり、さまざまなビジネスシナリオに応じて柔軟かつ動的にしきい値を調整することができないため、小さな問題が簡単に大きな障害に変わる可能性があります。
AI ベースのデータベース異常検出機能は、データベースの履歴パフォーマンスに基づいて主要な指標を 7*24 時間検査し、異常の芽生えのリスクを検出できます。これにより、異常が明らかになり、研究開発担当者が問題が悪化する前に損失を特定して阻止できるようになります。上記の要因を考慮して、Meituan データベース プラットフォームの研究開発チームはデータベース異常検出サービス システムを開発することを決定しました。次に、この記事では、特徴分析、アルゴリズムの選択、モデルのトレーニング、リアルタイム検出などのいくつかの側面から、私たちの考えと実践のいくつかについて詳しく説明します。
2. 特徴分析
2.1 データの変化パターンを見つける
具体的な開発とコーディングに進む前に、非常に重要なタスクがあります。既存の履歴監視指標から、時系列データの変化パターンを発見し、データ分布の特性に基づいて適切なアルゴリズムを選択できます。以下は、過去のデータから選択したいくつかの代表的な指標分布図です: 
図 1 データベース指標フォーム
上の図よりを見ると、データ パターンが主にサイクル、ドリフト、定常の 3 つの状態を示していることがわかります[1]。したがって、初期段階でこれらの共通の特性を持つサンプルをモデル化でき、ほとんどのシナリオをカバーできます。次に、周期性、ドリフト、定常性の 3 つの観点から分析し、アルゴリズムの設計プロセスについて説明します。
2.1.1 周期的な変化
多くのビジネス シナリオでは、朝夕のピークやスケジュールされたタスクによって指標が定期的に変動します。これはデータの固有の規則的な変動であると考えており、モデルには周期的なコンポーネントを識別し、コンテキストの異常を検出する機能が必要です。長期トレンド コンポーネントを持たない時系列インジケーターの場合、インジケーターに周期コンポーネント 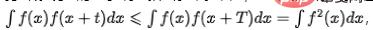 が含まれる場合、T は時系列の期間スパンを表します。自己相関図、つまり t が異なる値を取る場合の
が含まれる場合、T は時系列の期間スパンを表します。自己相関図、つまり t が異なる値を取る場合の 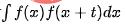 の値を計算し、自己相関ピークの間隔を分析することで周期性を決定できます。ステップ:
の値を計算し、自己相関ピークの間隔を分析することで周期性を決定できます。ステップ:
- トレンド成分を抽出し、残差シーケンスを分離します。移動平均法を使用して長期トレンド項を抽出し、元のシーケンスとの差をとって残差シーケンスを取得します (ここでの定期的な分析はトレンドとは何の関係もありません。トレンド成分が分離されていない場合、自己相関が大きく影響を受け、期間を特定することが困難になります。)。
- 残差の周期的自己相関 (ローリング相関) シーケンスを計算します。自己相関シーケンスは、残差シーケンスを周期的に移動した後、残差シーケンスとベクトル ドット乗算演算を実行することによって計算されます (巡回自己相関により遅延減衰を回避できます)。
- 自己相関シーケンスのピーク座標に基づいて周期 T を決定します。自己相関系列の一連の局所的な最高ピークを抽出し、横軸の間隔を周期とします (周期点に対応する自己相関値が所定の閾値未満の場合、有意な周期性がないとみなします) )。
具体的なプロセスは次のとおりです:

図 2 サイクル抽出プロセスの概略図
2.1.2 ドリフトの変更
モデルの場合モデル化されるシーケンスには、通常、明らかな長期トレンドやグローバルドリフトがないことが要求されます。そうでない場合、生成されたモデルは通常、インジケーター[2]の最新トレンドにうまく適応できません。時系列の平均値が時間の経過とともに大きく変化する状況、または全体的な突然変異点が存在する状況を指し、総称してドリフト シナリオと呼ばれます。時系列の最新の傾向を正確に把握するには、モデリングの初期段階で履歴データにドリフトがあるかどうかを判断する必要があります。次の例に示すように、グローバル ドリフトと周期系列平均ドリフトは次のとおりです。

図 3 データ ドリフトの図
データベース指標は事業活動などの複雑な要因の影響を受けるため、多くのデータは非周期的に変化するため、モデリングではこれらの変化を許容する必要があります。したがって、古典的な変化点検出問題とは異なり、異常検出シナリオでは、データが履歴内で安定していてその後ドリフトする状況を検出するだけで済みます。アルゴリズムのパフォーマンスと実際のパフォーマンスに基づいて、メディアン フィルタリングに基づくドリフト検出方法を使用しました。メイン プロセスには次のリンクが含まれます:
1. メディアン スムージング
# a. 指定されたウィンドウのサイズに従って、ウィンドウ内の中央値を抽出して、時系列の傾向コンポーネントを取得します。
b. ウィンドウは、周期的要因の影響を回避し、フィルター遅延補正を実行するのに十分な大きさである必要があります。
c. 平均平滑化ではなく中央値を使用する理由は、異常サンプルの影響を避けるためです。
#2. 平滑化されたシーケンスが増加しているか減少しているかを判断します
#a. 中央値平滑化後のシリアル データ、各点が前の点より大きい ( が より小さい) 場合、シーケンスは増加 ( 減少 ) シーケンスになります。
b. シーケンスが厳密に増加または厳密に減少している場合、インジケーターには明らかに長期的な傾向があり、早期に終了する可能性があります。
3. スムーズ シーケンスをトラバースし、次の 2 つのルールを使用して、ドリフトがあるかどうかを判断します。
a。現在のサンプル ポイントの左側にあるシーケンスの最大値が、現在のサンプル ポイントの右側にあるシーケンスの最小値より小さい場合、突然のドリフト (Uptrend) が発生します。
b. 現在のサンプル ポイントの左側にあるシーケンスの最小値が、現在のサンプル ポイントの右側にあるシーケンスの最大値より大きい場合、突然の下落ドリフト (下降トレンド)。
2.1.3 定常的な変化
時系列インジケーターの場合、観測時間の変化によってそのプロパティがいかなる時点でも変化しない場合、これは次のことであると考えられます。時系列は安定してます。したがって、長期トレンド成分または循環成分を含む時系列の場合、それらはすべて非定常です。具体的な例を以下の図に示します。

図 4 データ安定性の表示
表示中この状況では、単位根検定 (拡張ディッキー・フラー検定)[3] を通じて、特定の時系列が定常であるかどうかを判断できます。具体的には、特定の時間範囲インジケーターの履歴データについて、次の条件が同時に満たされる場合、時系列は安定していると考えられます。 業界で有名な企業のパフォーマンスを理解することによって時系列データの異常検出 インターネット上で公開されている製品紹介によると、当社の蓄積された歴史的経験といくつかの実際のオンライン指標のサンプリング分析と組み合わせて、その確率密度関数は次の分布に準拠しています。 上記の分布について、いくつかの一般的なアルゴリズムを調査し、箱ひげ図、絶対中央値の差、および極値を決定しました。究極の異常検出アルゴリズムとしての価値理論。以下は、一般的な時系列データ検出のためのアルゴリズムの比較表です。
) が使用されます。データ分布ごとに異なる検出アルゴリズムを使用します (さまざまなアルゴリズムの原理については、記事の最後にある付録を参照してください。ここでは詳しく説明しません):
アルゴリズムの全体的なモデリング プロセスを上の図に示します。主に次のブランチをカバーします: タイミング ドリフト検出、タイミング安定性性分析、時系列周期性分析、歪度計算。それぞれ以下を紹介します: ケース : 時系列 ts={t0,t1,⋯ を指定すると、 tn}、周期性があり、周期スパンが T であると仮定すると、時間インデックス j (j∈{0,1,⋯,T−1}) に対して、それをモデル化する必要があります。サンプル ポイントは間隔 [tj−kT−m, tj−kT m] で構成されます。ここで、m はウィンドウ サイズを表すパラメータ、k は整数です、j−kT −m≧0、j−kT m≤nを満たす。たとえば、指定された時系列が 2022/03/01 00:00:00 から 2022/03/08 00:00:00 まで始まり、指定されたウィンドウ サイズが 5、期間スパンが 1 日であると仮定すると、時間インデックス 30 つまり、モデル化に必要なサンプル ポイントは次の期間から取得されます: [03/01 00:25:00, 03/01 00:35:00] ここでは、上記のプロセスをより明確に理解できるように、データ分析とモデリングのプロセスを示すためにケースを選択します。図 (a) は元のシーケンス、図 (b) は日数に応じて折り畳まれたシーケンス、図 (c) は図 (b) の特定の時間インデックス間隔におけるサンプルの増幅されたトレンド パフォーマンスです。 d) ) は、図 (c) の時間インデックスに対応する下限しきい値です。以下は、特定の時系列の履歴サンプルをモデリングするケースです。 #図 7 モデリングのケース 上図の領域 (c) のサンプル分布ヒストグラムとしきい値 (一部の異常なサンプルは除外されています)。この非常に偏った分布シナリオでは、しきい値はEVT アルゴリズムはより合理的です。 4. モデルのトレーニングとリアルタイム検出 具体的なオフライン トレーニングとオンライン検出テクノロジの設計は次のとおりです: 図9 オフライントレーニングとオンライン検出テクノロジーの設計 異常検出アルゴリズムは全体として分割統治の考え方を採用しています。段階では、履歴データの識別に基づいて特徴が抽出され、適切な検出アルゴリズムを選択します。これはオフライン トレーニングとオンライン検出の 2 つの部分に分かれており、オフラインでは主にデータの前処理、時系列分類、履歴条件に基づく時系列モデリングが実行されます。オンラインでは主に、オンラインのリアルタイム異常検出のためにオフラインでトレーニングされたモデルをロードして使用します。具体的な設計を以下の図に示します。 #図 10 異常検出プロセス 最適化の反復アルゴリズムの効率を向上させ、精度と再現率を向上させるための運用を継続するために、Horae (Meituan の内部スケーラブルな 時系列データ) を使用します。異常検出システム ) の症例レビュー機能により、オンライン検出、症例保存、分析と最適化、結果評価、オンライン リリースの閉ループが可能になります。 #図 11 運用プロセス
絶対中央値差、つまり中央値絶対偏差(MAD#) ##) は、一変量数値データ [6] のサンプル偏差のロバストな尺度であり、通常は次の式で計算されます。 事前分布が正規分布の場合, 一般に C は 1.4826 を選択し、k は 3 を選択します。 MAD は、サンプルの中央の 50% が正常なサンプルであり、異常なサンプルは両側の 50% の領域内にあると想定します。サンプルが正規分布に従う場合、MAD インジケーターは標準偏差よりもデータセット内の外れ値に適応できます。標準偏差には、データから平均までの距離の 2 乗が使用されます。偏差が大きいほど、重みは大きくなります。結果に対する外れ値の影響は無視できません。MAD の場合、少量の外れ値は無視されます。実験の結果に影響を与えます。MAD アルゴリズムはデータには影響しません。正規性についてはより高い要件があります。 箱ひげ図は主に、次のようないくつかの統計を通じて標本分布の離散性と対称性を表します。 ##Q0: 最小値 (Minimum #Q1 と Q 間の距離は IQR と呼ばれますサンプルが上位四分位の 1.5 倍の IQR から逸脱している場合 ( または下位四分位の 1.5 倍の IQR から逸脱している)、サンプルを外れ値として扱います。正規性の仮定に基づく 3 つの標準偏差とは異なり、箱ひげ図は通常、サンプルの基礎となるデータ分布についていかなる仮定も行わず、サンプルの個別の状況を記述することができ、サンプルに含まれる潜在的な異常サンプルに対してより高い信頼度を持ちます。 。 許容範囲。偏ったデータの場合、箱ひげ図の調整されたモデリングはデータ分布##[7]とより一貫性があります。 7.3 極値理論 現実世界のデータは、たとえば一部の極端なイベント (異常) など、既知の分布で一般化することが困難です。 )、確率モデル (ガウス分布など) では、確率が 0 になることがよくあります。極値理論 #[8] 相補累積分布関数式): ここで、 t はサンプルの経験的閾値を表します。一般化パレート分布の形状パラメータとスケールパラメータである、シナリオごとに異なる値を設定できます。特定のサンプルが人為的に設定された経験的閾値を超えた場合しきい値 t の場合、確率変数 X-t は一般化パレート分布に従います。最尤推定法により、パラメータ推定値 と を計算し、次の式でモデルのしきい値を取得できます。 上記の式では、 qはリスクパラメータ、nは全サンプル数、Ntはx-t>0を満たすサンプル数を表す。通常、経験的閾値 t を推定するための先験的な情報は存在しないため、サンプル経験的分位点を数値 t の代わりに使用できます。ここでの経験的分位点の値は、実際の状況に応じて選択できます。 [1] Ren, H.、Xu, B.、Wang, Y.、Yi, C.、Huang, C.、Kou , X., ... & Zhang, Q. (2019 年 7 月). Microsoft の時系列異常検出サービス. 知識発見とデータ マイニングに関する第 25 回 ACM SIGKDD 国際会議の議事録 (pp. 3009-3017) 。 [2] Lu, J.、Liu, A.、Dong, F.、Gu, F.、Gama, J.、および Zhang, G. (2018). 概念ドリフトの下での学習: レビュー. IEEE Transactions on Knowledge and Data Engineering, 31(12), 2346-2363. [3] Mushtaq, R. (2011). 拡張ディッキー フラー テスト. [4] Ma, M.、Yin, Z.、Zhang, S.、Wang, S.、Zheng, C.、Jiang, X.、... & Pei, D. (2020) 。クラウド データベースにおける断続的な遅いクエリの根本原因の診断. Proceedings of the VLDB Endowment, 13(8), 1176-1189. [5] Holzinger, A. (2016). 対話型機械学習健康情報学: 人間の関与が必要になるのはいつですか?. Brain Informatics、3(2)、119-131. [6] Leys, C.、Ley, C. 、Klein, O.、Bernard, P.、& Licata, L. (2013). 異常値の検出: 平均値の周囲の標準偏差を使用しないで、中央値の周囲の絶対偏差を使用します。実験社会心理学ジャーナル、49(4) 、 764-766. [7] Hubert, M.、& Vandervieren, E. (2008). 歪んだ分布の調整された箱ひげ図. 計算統計とデータ分析、52(12)、5186 - 5201. [8] Siffer, A.、Fouque, P. A.、Termier, A.、および Largouet, C. (2017、8 月). 極値理論によるストリームの異常検出. 議事録内第 23 回 ACM SIGKDD 知識発見とデータ マイニング国際会議の (pp. 1067-1075).
3. アルゴリズムの選択
3.1 配信ルールとアルゴリズムの選択
 図 5 分布の歪度の表現
図 5 分布の歪度の表現 3Sigma を選択しなかった主な理由は、理論的には、絶対中央差の方が異常に対する許容度が高いため、データが高度に対称的な分布を示す場合、検出には 3Sigma の代わりに絶対中央差 (
3Sigma を選択しなかった主な理由は、理論的には、絶対中央差の方が異常に対する許容度が高いため、データが高度に対称的な分布を示す場合、検出には 3Sigma の代わりに絶対中央差 (低い歪みと高い対称性の分布
 図 6 アルゴリズム モデリング プロセス
図 6 アルゴリズム モデリング プロセス
[03/02 00] :25:00、03/02 00:35:00]
...
[03/07 00:25:00、03/07 00:35:00]
3.2 ケースサンプルのモデリング


4.1 データ フロー プロセス
大規模な第 2 レベルのデータをリアルタイムで検出するために、Flink に基づくリアルタイム ストリーム処理から開始し、次の技術ソリューションを設計しました:

4.2 異常検出プロセス


6. 今後の見通し現在、Meituan のデータベース異常監視機能は基本的に完成しており、引き続き取り組んでまいります。将来の製品の最適化と拡張、具体的な方向性には次のものが含まれます:
7. 付録
7.1 絶対中央値差
図 12 箱ひげ図
EVD
) です。その数式は次のとおりです (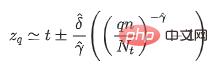
8. 参考文献
以上がAIアルゴリズムによるデータベース異常監視システムの設計・導入の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。