
ホームページ >バックエンド開発 >Python チュートリアル >Python でのシンプルで使いやすい並列アクセラレーション手法
Python でのシンプルで使いやすい並列アクセラレーション手法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-12 14:25:151739ブラウズ
1. はじめに

私たちが日常的に Python を使ってさまざまなデータの計算や処理を行う場合、明らかな計算高速化の効果を得たい場合は、最も簡単な方法が必要です。最も明確な方法は、デフォルトで単一プロセスで実行されるタスクを拡張して、複数のプロセスまたはマルチスレッドを使用する方法を見つけることです。
データ分析に携わる私たちにとって、プログラムの作成に時間をかけすぎないようにするために、最も簡単な方法で同等の高速化操作を実現することが特に重要です。フェイさん、今日の記事では、非常にシンプルで使いやすいライブラリである joblib の関連関数を使用して、並列コンピューティングの高速化効果を迅速に実現する方法を説明します。
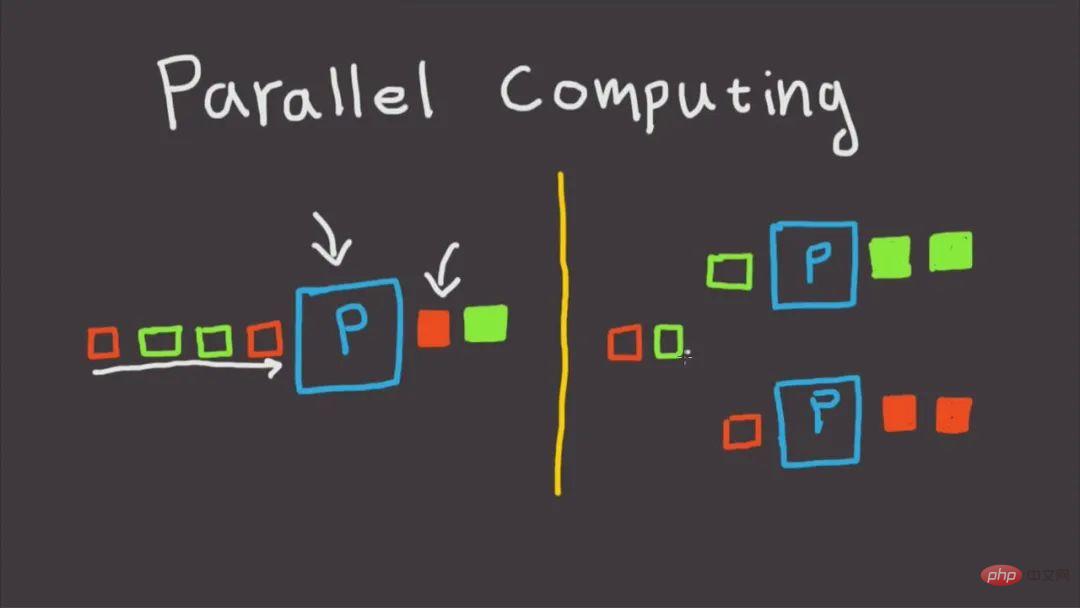
2. 並列コンピューティングには joblib を使用します
広く使用されているサードパーティの Python ライブラリとして (たとえば、joblib は scikit-learn で広く使用されています)プロジェクト フレームワーク (多くの機械学習アルゴリズムの並列アクセラレーション) をインストールするには、 pip install joblib を使用できます。インストールが完了したら、joblib での並列操作の一般的な方法について学びましょう:
2.1 Parallel と遅延並列アクセラレーション
joblib で並列コンピューティングを実装するには、その Parallel メソッドと遅延メソッドを使用するだけです。これは非常にシンプルで使いやすいです。小さな例で直接示してみましょう:
joblib 実装 並列コンピューティングの考え方は、マルチプロセスまたはマルチスレッド方式でループを通じて生成されたシリアル コンピューティング サブタスクのセットをスケジュールすることです。カスタム コンピューティング タスクに対して行う必要があるのは、それらを関数にカプセル化することだけです。はい例:
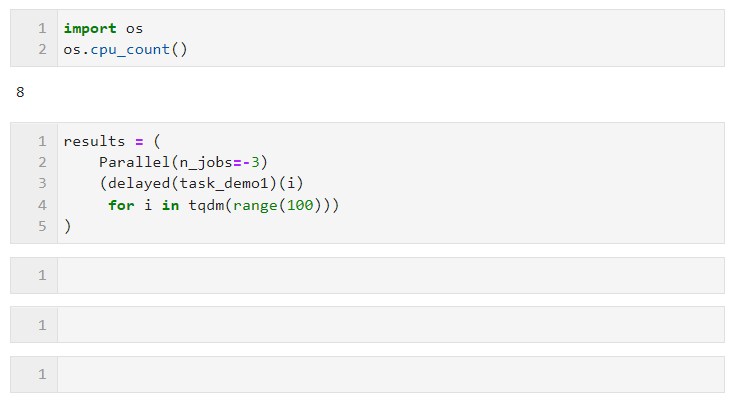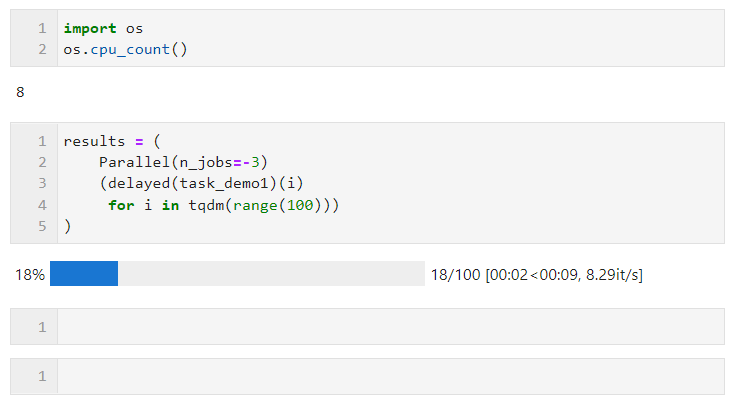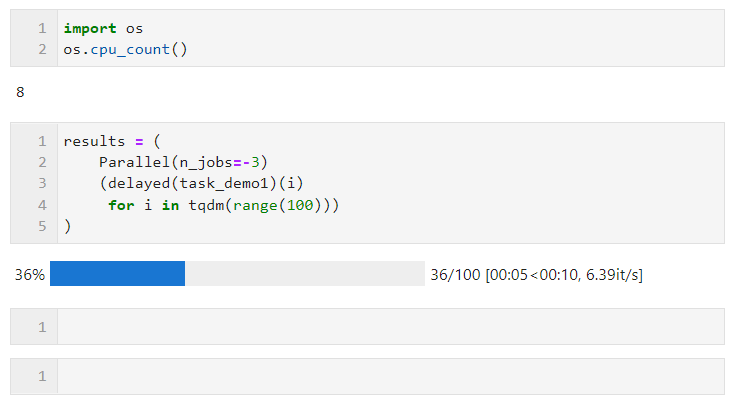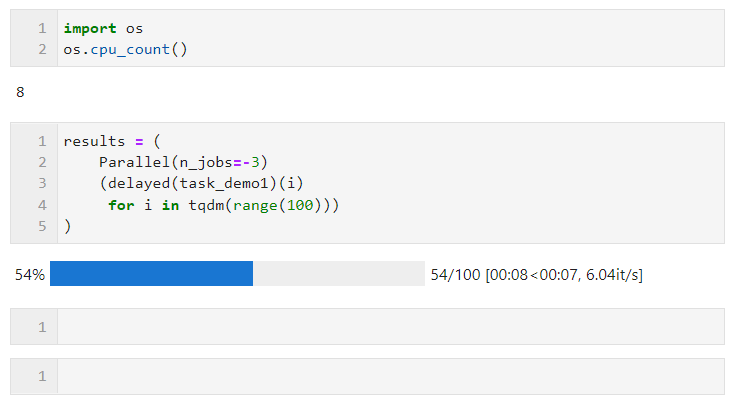
import time def task_demo1(): time.sleep(1) return time.time()
次に、以下に示すように Parallel() の関連パラメータを設定し、ループを接続してサブタスクのリスト導出プロセスを作成するだけで済みます。このプロセスでは、layed() が使用されます。カスタム タスク関数をラップします。次に、connect () を実行して、タスク関数に必要なパラメーターを渡します。n_jobs パラメーターは、並列タスクを同時に実行するワーカーの数を設定するために使用されます。したがって、この例では、次のことがわかります。プログレス バーが 4 つずつ増加していることがわかります。最終時間のオーバーヘッドでも並列加速効果が達成されていることがわかります。
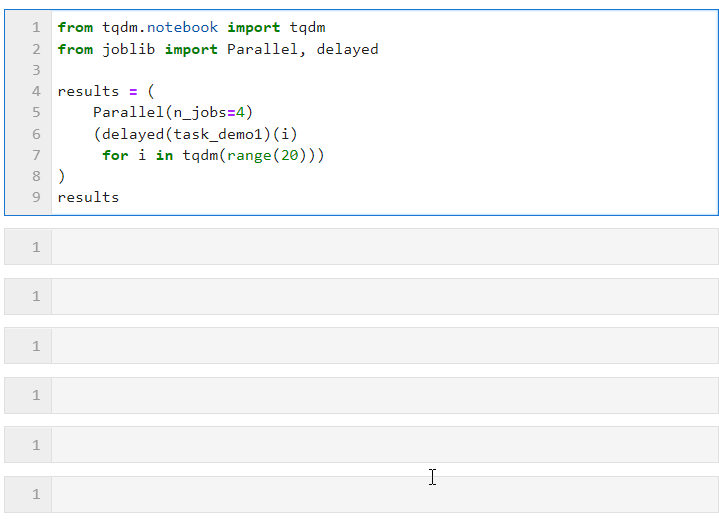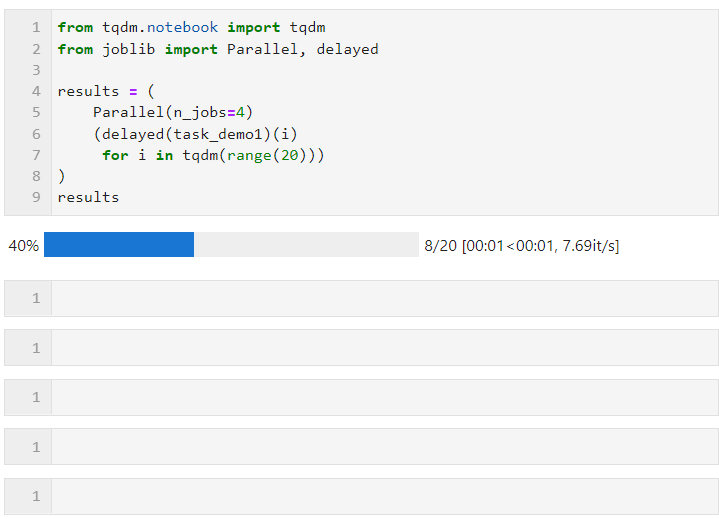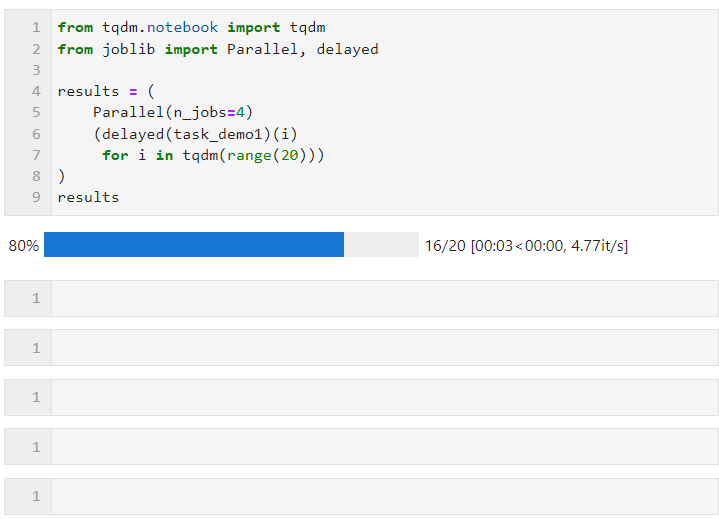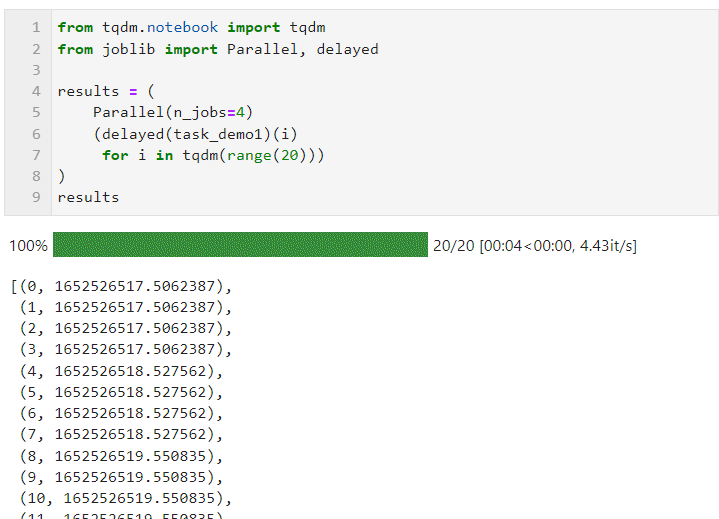
Parallel() のパラメーターは、次に従って調整できます。コンピューティング タスクの特定の条件とマシンの CPU コアの数コア パラメーターは次のとおりです:
- backend: は並列モードの設定に使用されます。 'loky' (より安定した) と 'multiprocessing' の 2 つのオプションがあり、マルチスレッド モードには 'threading' オプションがあります。デフォルトは「ローキー」です。
- n_jobs: 並列タスクを同時に実行するワーカー数を設定します。並列モードがマルチプロセスの場合、n_jobs は論理 CPU の数まで設定できます。マシンのコア数を超える場合は、すべてのコアをオンにするのと同じです。-1 に設定して、すべての論理コアをすぐに有効にすることもできます。すべての CPU リソースが並列タスクによって占有されることを望まない場合は、 、適切なアイドル コアを保持するには、より小さい負の数値を設定できます。たとえば、-2 に設定すると、すべてのコア (1 コア) がオンになり、-3 に設定すると、すべてのコア (2 コア) がオンになります。
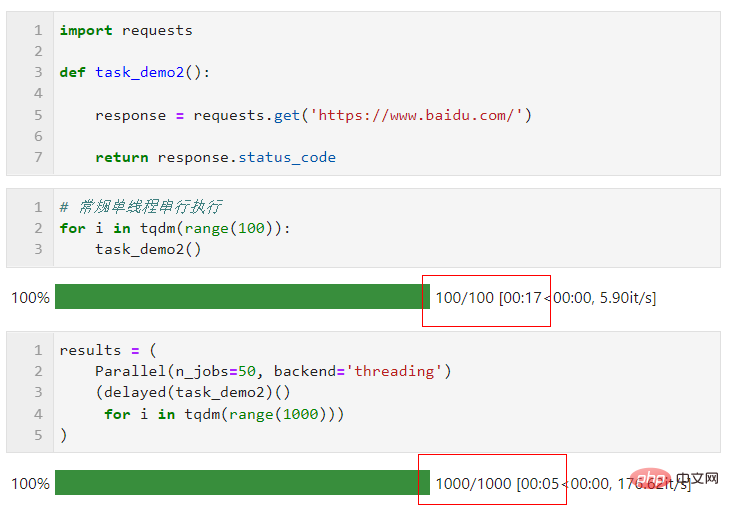
たとえば、次の例では、8 つの論理コアを持つ私のマシンでは、2 つのコアが並列コンピューティング用に予約されています。並列モードの選択。Python でのマルチスレッド時のグローバル インタプリタ ロックの制限により、タスクが計算集約的である場合、高速化するためにデフォルトのマルチプロセス モードを使用することをお勧めします。タスクが IO 集約的である場合は、次のようになります。ファイルの読み取り、書き込み、ネットワーク リクエストなどでは、マルチスレッドの方が優れており、n_jobs を非常に大きく設定できます。簡単な例として、マルチスレッドの並列処理により、1,000 件のリクエストを 5 秒で完了したことがわかります。 、単一スレッドで 17 秒間に 100 件のリクエストを実行した結果よりもはるかに高速です (この例は参考用です。学習中や試用中は他の人の Web サイトに頻繁にアクセスしないでください):
joblib を上手に活用すると、実際のタスクに応じて日々の作業をスピードアップできます。
以上がPython でのシンプルで使いやすい並列アクセラレーション手法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。