
ホームページ >テクノロジー周辺機器 >AI >CLIPを使用したビデオ検索エンジンの構築
CLIPを使用したビデオ検索エンジンの構築

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-12 13:43:031106ブラウズ
CLIP (Contrastive Language-Image Pre-training) は、画像と自然言語テキストを正確に理解して分類できる機械学習テクノロジーです。これは、画像と言語の処理に大きな影響を与え、一般的な基盤メカニズムとして使用されています。ディフュージョンモデルDALL-Eの。この投稿では、ビデオ検索を支援するために CLIP を適応させる方法について説明します。
この記事では、CLIP モデルの技術的な詳細については掘り下げませんが、(拡散モデルに加えて) CLIP の別の実際的なアプリケーションを示します。
まず知っておく必要があります: CLIP は画像デコーダーとテキスト エンコーダーを使用して、データ セット内のどの画像がどのテキストに一致するかを予測します。

CLIP を使用した検索
顔を抱きしめることで事前にトレーニングされた CLIP モデルを使用することで、自然言語機能を備えたシンプルかつ強力なビデオ検索エンジンを構築できます。特徴量エンジニアリングも必要ありません。
次のソフトウェアを使用する必要があります
Python≥= 3.8,ffmpeg,opencv
テキストからビデオを検索するためのテクニックはたくさんあります。検索エンジンは、インデックス作成と検索の 2 つの部分で構成されていると考えることができます。
インデックス作成
ビデオのインデックス作成には、多くの場合、手動プロセスと機械プロセスの組み合わせが含まれます。人間はタイトル、タグ、説明に関連するキーワードを追加することでビデオを前処理し、自動化されたプロセスは物体検出や音声転写などの視覚的および聴覚的機能を抽出します。ユーザー インタラクション メトリクスなど。ビデオのどの部分が最も関連性が高く、どのくらいの期間関連性が維持されるかを記録します。これらの手順はすべて、ビデオ コンテンツの検索可能なインデックスを作成するのに役立ちます。
インデックス作成プロセスの概要は次のとおりです
- ビデオを複数のシーンに分割します
- フレームのシーンをサンプリングします
- フレーム後のピクセル埋め込み処理
- インデックスの作成と保存
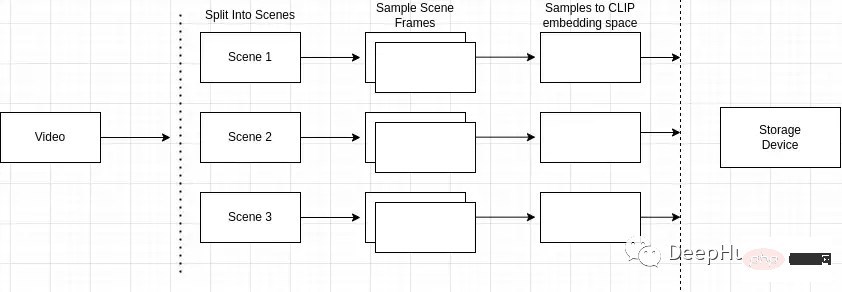
ビデオを複数のシーンに分割する
なぜシーン検出が重要ですか? ビデオは合成されますシーンは類似したフレームで構成されます。ビデオ内の任意のシーンだけをサンプリングすると、ビデオ全体のキーフレームが失われる可能性があります。
したがって、ビデオ内の特定のイベントやアクションを正確に識別して特定する必要があります。たとえば、「公園の犬」を検索し、検索しているビデオに自転車に乗っている男性のシーンや公園で犬のシーンなど複数のシーンが含まれている場合、シーン検出により次のことが可能になります。検索クエリに最も関連するものを特定し、シーンを閉じます。
「シーン検出」Python パッケージを使用して、この操作を実行できます。
mport scenedetect as sd video_path = '' # path to video on machine video = sd.open_video(video_path) sm = sd.SceneManager() sm.add_detector(sd.ContentDetector(threshold=27.0)) sm.detect_scenes(video) scenes = sm.get_scene_list()
シーンのフレームのサンプリング
次に、cv2 を使用してビデオをフレーム化する必要があります。
import cv2 cap = cv2.VideoCapture(video_path) every_n = 2 # number of samples per scene scenes_frame_samples = [] for scene_idx in range(len(scenes)): scene_length = abs(scenes[scene_idx][0].frame_num - scenes[scene_idx][1].frame_num) every_n = round(scene_length/no_of_samples) local_samples = [(every_n * n) + scenes[scene_idx][0].frame_num for n in range(3)] scenes_frame_samples.append(local_samples)
フレームをピクセル埋め込みに変換する
サンプルを収集した後、CLIP モデルで使用できるものにそれらを計算する必要があります。
まず、各サンプルを画像テンソル埋め込みに変換する必要があります。
from transformers import CLIPProcessor
from PIL import Image
clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def clip_embeddings(image):
inputs = clip_processor(images=image, return_tensors="pt", padding=True)
input_tokens = {
k: v for k, v in inputs.items()
}
return input_tokens['pixel_values']
# ...
scene_clip_embeddings = [] # to hold the scene embeddings in the next step
for scene_idx in range(len(scenes_frame_samples)):
scene_samples = scenes_frame_samples[scene_idx]
pixel_tensors = [] # holds all of the clip embeddings for each of the samples
for frame_sample in scene_samples:
cap.set(1, frame_sample)
ret, frame = cap.read()
if not ret:
print('failed to read', ret, frame_sample, scene_idx, frame)
break
pil_image = Image.fromarray(frame)
clip_pixel_values = clip_embeddings(pil_image)
pixel_tensors.append(clip_pixel_values)次のステップは、同じシーン内のすべてのサンプルを平均することです。これにより、サンプルの次元が削減され、単一サンプル内のノイズの問題も解決できます。
import torch
import uuid
def save_tensor(t):
path = f'/tmp/{uuid.uuid4()}'
torch.save(t, path)
return path
# ..
avg_tensor = torch.mean(torch.stack(pixel_tensors), dim=0)
scene_clip_embeddings.append(save_tensor(avg_tensor))このようにして、ビデオコンテンツを表すCLIP埋め込みテンソルリストが取得されます。
ストレージ インデックス
基盤となるインデックス ストレージには、LevelDB を使用します (LevelDB は、Google が管理するキー/値ライブラリです)。私たちの検索エンジンのアーキテクチャは 3 つの個別のインデックスで構成されます:
- ビデオ シーン インデックス: どのシーンが特定のビデオに属しているか
- シーン埋め込みインデックス: 特定のシーン データを保存
- ビデオメタデータインデックス:ビデオのメタデータを保存します。
最初に、ビデオ内のすべての計算されたメタデータとビデオの一意の識別子をメタデータ インデックスに挿入します。このステップは既成のもので、非常に簡単です。
import leveldb
import uuid
def insert_video_metadata(videoID, data):
b = json.dumps(data)
level_instance = leveldb.LevelDB('./dbs/videometadata_index')
level_instance.Put(videoID.encode('utf-8'), b.encode('utf-8'))
# ...
video_id = str(uuid.uuid4())
insert_video_metadata(video_id, {
'VideoURI': video_path,
})次に、シーン埋め込みインデックスに新しいエントリを作成して、ビデオに埋め込まれている各ピクセルを保存します。また、各シーンを識別するための一意の識別子も必要です。
import leveldb
import uuid
def insert_scene_embeddings(sceneID, data):
level_instance = leveldb.LevelDB('./dbs/scene_embedding_index')
level_instance.Put(sceneID.encode('utf-8'), data)
# ...
for f in scene_clip_embeddings:
scene_id = str(uuid.uuid4())
with open(f, mode='rb') as file:
content = file.read()
insert_scene_embeddings(scene_id, content)最後に、どのシーンがどのビデオに属しているかを保存する必要があります。
import leveldb
import uuid
def insert_video_scene(videoID, sceneIds):
b = ",".join(sceneIds)
level_instance = leveldb.LevelDB('./dbs/scene_index')
level_instance.Put(videoID.encode('utf-8'), b.encode('utf-8'))
# ...
scene_ids = []
for f in scene_clip_embeddings:
# .. as shown in previous step
scene_ids.append(scene_id)
scene_embedding_index.insert(scene_id, content)
scene_index.insert(video_id, scene_ids)Search
ビデオのインデックスができたので、モデル出力に基づいてビデオを検索し、並べ替えることができます。
最初のステップでは、シーン インデックス内のすべてのレコードを走査する必要があります。次に、すべてのビデオとビデオ内の一致するシーン ID のリストを作成します。
records = []
level_instance = leveldb.LevelDB('./dbs/scene_index')
for k, v in level_instance.RangeIter():
record = (k.decode('utf-8'), str(v.decode('utf-8')).split(','))
records.append(record)次のステップでは、各ビデオに存在するすべてのシーン エンベディング テンソルを収集する必要があります。
import leveldb
def get_tensor_by_scene_id(id):
level_instance = leveldb.LevelDB('./dbs/scene_embedding_index')
b = level_instance.Get(bytes(id,'utf-8'))
return BytesIO(b)
for r in records:
tensors = [get_tensor_by_scene_id(id) for id in r[1]]ビデオを構成するすべてのテンソルを取得したら、それをモデルに渡すことができます。モデルへの入力は、ビデオ シーンを表すテンソルである「pixel_values」です。
import torch
from transformers import CLIPProcessor, CLIPModel
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
inputs = processor(text=text, return_tensors="pt", padding=True)
for tensor in tensors:
image_tensor = torch.load(tensor)
inputs['pixel_values'] = image_tensor
outputs = model(**inputs)次に、モデル出力の「logits_per_image」にアクセスして、モデルの出力を取得します。
ロジットは本質的に、ネットワークの正規化されていない生の予測です。ビデオ内のシーンを表すテキスト文字列とテンソルのみを提供するため、ロジットの構造は単一値の予測になります。
logits_per_image = outputs.logits_per_image probs = logits_per_image.squeeze() prob_for_tensor = probs.item()
各反復の確率を加算し、操作の終了時にそれをテンソルの総数で割って、ビデオの平均確率を取得します。
def clip_scenes_avg(tensors, text): avg_sum = 0.0 for tensor in tensors: # ... previous code snippets probs = probs.item() avg_sum += probs.item() return avg_sum / len(tensors)
最后在得到每个视频的概率并对概率进行排序后,返回请求的搜索结果数目。
import leveldb
import json
top_n = 1 # number of search results we want back
def video_metadata_by_id(id):
level_instance = leveldb.LevelDB('./dbs/videometadata_index')
b = level_instance.Get(bytes(id,'utf-8'))
return json.loads(b.decode('utf-8'))
results = []
for r in records:
# .. collect scene tensors
# r[0]: video id
return (clip_scenes_avg, r[0])
sorted = list(results)
sorted.sort(key=lambda x: x[0], reverse=True)
results = []
for s in sorted[:top_n]:
data = video_metadata_by_id(s[1])
results.append({
'video_id': s[1],
'score': s[0],
'video_uri': data['VideoURI']
})就是这样!现在就可以输入一些视频并测试搜索结果。
总结
通过CLIP可以轻松地创建一个频搜索引擎。使用预训练的CLIP模型和谷歌的LevelDB,我们可以对视频进行索引和处理,并使用自然语言输入进行搜索。通过这个搜索引擎使用户可以轻松地找到相关的视频,最主要的是我们并不需要大量的预处理或特征工程。
那么我们还能有什么改进呢?
- 使用场景的时间戳来确定最佳场景。
- 修改预测让他在计算集群上运行。
- 使用向量搜索引擎,例如Milvus 替代LevelDB
- 在索引的基础上建立推荐系统
- 等等
可以在这里找到本文的代码:https://github.com/GuyARoss/CLIP-video-search/tree/article-01。
以及这个修改版本:https://github.com/GuyARoss/CLIP-video-search。
以上がCLIPを使用したビデオ検索エンジンの構築の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。