
ホームページ >テクノロジー周辺機器 >AI >Meituan検索のラフランキング最適化の探索と実践
Meituan検索のラフランキング最適化の探索と実践

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-12 11:31:092049ブラウズ
著者: Xiaojiang Suogui Li Xiang 他
大まかなランキングは、業界で重要なシステムモジュール。大まかなランキング効果の最適化の探索と実践において、Meituan 検索ランキング チームは、詳細なランキングの連携と、実際のビジネス シナリオに基づく効果とパフォーマンスの共同最適化という 2 つの側面から大まかなランキングを最適化し、大まかなランキングの効果を向上させました。
1. はじめに
ご存知のとおり、検索、レコメンデーション、広告などの大規模な産業アプリケーション分野では、パフォーマンスのバランスを取るために、したがって、ランキング システムは、以下の図 1 に示すように、カスケード アーキテクチャ [1、2] が一般的に使用されます。 Meituan の検索ランキング システムを例に挙げると、全体のランキングは大まかな並べ替え、詳細な並べ替え、並べ替え、および混合並べ替えレベルに分かれており、大まかな並べ替えは再現と詳細な並べ替えの間に位置し、百レベルの項目をフィルタリングする必要があります。千段階の候補アイテムセットからセットして、繊細な漕ぎ層に与えてください。

図 1 ソートファネル
の完全なリンクの観点から大まかなランキング モジュールを調べます。 Meituan の検索ランキングでは、現在、粗い並べ替えレイヤーの最適化にいくつかの課題があります:
- サンプル選択のバイアス: カスケード並べ替えの下システムでは、大まかな並べ替えは最終結果の表示から遠く離れているため、大まかな並べ替えモデルのオフライン トレーニング サンプル空間と予測されるサンプル空間の間に大きな差が生じ、深刻なサンプル選択バイアスが生じます。
- 大まかなソートと詳細なソートの連携: 大まかなソートはリコールと詳細なソートの間にあります。大まかなソートには後続のチェーンのより多くの取得と利用が必要です。 . 効果を高めるための道路情報。
- パフォーマンスの制約: オンラインの大まかなランキング予測の候補セットは、詳細なランキング モデルの候補セットよりもはるかに高いですが、実際の検索システム全体には厳しい要件があります。パフォーマンスに影響を与えるため、粗い並べ替えでは予測パフォーマンスに重点を置く必要があります。
この記事では、上記の課題に焦点を当てて、Meituan 検索の大まかなランキング レイヤーの最適化に関する関連する調査と実践を共有します。その中で、サンプル選択のバイアスの問題をまとめます。ファインランキング連動問題を使って解きます。この記事は主に 3 つの部分に分かれており、最初の部分では Meituan 検索ランキングの大まかなランキング層の進化ルートを簡単に紹介し、2 番目の部分では大まかなランキング最適化の関連探索と実践を紹介します。精選するための蒸留と比較学習 粗選別効果を最適化するための粗選別と粗選別の連携 2番目のタスクは、粗選別のパフォーマンスと粗選別の効果のトレードオフの最適化を考慮することです 関連作業はすべて完全にオンライン化されており、効果は重要です; 最後の部分は概要と展望です。これらの内容が皆様にとって有益であり、インスピレーションを与えるものであることを願っています。
#2. 大まかなランキングの進化ルート
Meituan Search の大まかなランキング技術の進化は次の段階に分かれています:
- 2016: 相関性、品質、コンバージョン率などの情報に基づく線形重み付け。この方法は単純ですが、表現力が不十分です。機能が弱く、重みが手動で決定されるため、選別効果には改善の余地が多くあります。
- #2017: 機械学習に基づいた単純な LR モデルを使用した点単位の推定ランキング。
- #2018: ベクトル内積に基づく 2 タワー モデルを使用し、クエリ用語、ユーザー、コンテキスト特徴、販売者が入力されます。特徴としては、ディープネットワーク計算の後、ユーザーおよびクエリワードベクトルとマーチャントベクトルがそれぞれ生成され、ソートのための内積計算を通じて推定スコアが取得されます。この方法では、マーチャントのベクトルを事前に計算して保存できるため、オンライン予測は高速ですが、双方の情報を横断する機能には制限があります。
- 2019: ツインタワー モデルがクロスフィーチャをうまくモデル化できないという問題を解決するために、ツインタワー モデルの出力-タワー モデルは、機能が GBDT ツリー モデルを通じて他の相互機能と融合されるために使用されます。
- 2020 年から現在まで : コンピューティング能力の向上により、NN のエンドツーエンドの大まかなモデルの調査を開始し、NN モデルの反復を継続しました。 。
現段階では、2 タワー モデルは、Tencent [3] や iQiyi [4] などの産業用大まかなランキング モデルや対話型 NN モデルで一般的に使用されています。 、アリババババなど[1,2]。以下では、大まかなランキングを NN モデルにアップグレードするプロセスにおける Meituan Search の関連する最適化作業を主に紹介します。これには主に、大まかなランキング効果の最適化と効果とパフォーマンスの結合最適化の 2 つの部分が含まれます。
3. 粗いランキングの最適化の実践
Meituan Search Fine Rank NN モデルに実装された大量の効果最適化作業 [5,6] により、粗いランキングの最適化の検討も開始しました。 NNモデル。粗いソートには厳しいパフォーマンス制約があることを考慮すると、詳細なソートの最適化作業を粗いソートに直接再利用することは適用できません。以下では、ファインソートのソート機能を粗ソートに移行する際のファインソート連携の最適化作業と、ニューラルネットワーク構造に基づく自動検索の効果とパフォーマンスのトレードオフ最適化について紹介します。
3.1 細かいランキングの連動効果の最適化
大まかなランキング モデルはスコアリングのパフォーマンス制約によって制限されるため、モデル構造がより単純になり、数値が小さくなります。ファイン ランキング モデルよりも特徴量が少ないため、ファイン ソートよりもはるかに少ないため、ソートの効果はファイン ソートよりも悪くなります。大まかなランキングモデルの構造が単純で特徴が少ないことによる効果の損失を補うために、知識蒸留法[7]を用いて詳細ランキングをリンクさせて大まかなランキングを最適化することを試みた。
知識の蒸留は、モデル構造を簡素化し、効果の損失を最小限に抑えるための業界で一般的な方法であり、教師と生徒のパラダイム、つまり複雑な構造と強力な学習能力を備えたモデルを採用しています。比較的単純な構造のモデルを Student モデルとして使用し、Teacher モデルを使用して Student モデルのトレーニングを支援することで、Teacher モデルの「知識」を Student モデルに伝達して改善を図ります。 Student モデルの効果。細列蒸留と粗列蒸留の概略図を図 2 に示しますが、蒸留スキームは細列結果蒸留、細列予測スコア蒸留、特徴表現蒸留の 3 種類に分かれます。 Meituan検索ラフランキングにおけるこれらの蒸留スキームの実際の経験を以下に紹介します。

#図 2 細列蒸留概略図
3.1.1 細列蒸留結果リスト大まかな並べ替えは、細かい並べ替えのためのプレモジュールです。その目標は、最初に、より質の高い候補のセットを選別して、細かい並べ替えに入力することです。トレーニング サンプルの選択の観点から、通常のユーザーの行動に加えて ( クリック、注文、支払い ) をポジティブ サンプルとして、発生しなかった項目をネガティブ サンプルとして公開することにより、ファイン ソート モデルのソート結果を通じて構築されたいくつかのポジティブ サンプルとネガティブ サンプルを導入することもできます。モデルのサンプル選択バイアスにより、細かい選別の選別能力が粗い選別に移される可能性もあります。以下では、Meituan の検索シナリオで、詳細な並べ替えの結果を使用して粗い並べ替えモデルを抽出する実際の経験を紹介します。
戦略 1: ユーザーからフィードバックされた陽性サンプルと陰性サンプルに基づいて、詳細な並べ替えの下部にある少数の未曝露サンプルをランダムに選択して補足します。陰性サンプルの大まかな分類、図 3 に示すとおり。この変更では、オフライン Recall@150 ( インジケーターの説明については付録 を参照) 5PP、オンライン CTR は 0.1% です。

戦略 2 : 直接細かく分類されたセットでランダム サンプリングを実行してトレーニング サンプルを取得します。以下の図 4 に示すように、細かく分類された位置はトレーニング用のペアを構築するためのラベルとして使用されます。オフライン効果は、Strategy 1 Recall@150 2PP と比較され、オンライン CTR は 0.06% です。

戦略 3: 戦略 2 のサンプル セットの選択に基づいて、洗練された並べ替え位置を分類することによってラベルが構築され、分類されたラベルに従ってトレーニング用のペアが構築されます。 Strategy 2 Recall@150 3PP と比較すると、オフライン効果はオンライン CTR 0.1% です。 3.1.2 詳細なランキング予測スコアの抽出
これまでのソート結果の抽出の使用は、詳細なランキング情報を使用する比較的大まかな方法でした。予測スコア抽出 [8] では、以下の図 5 に示すように、大まかなランキング モデルによって出力されるスコアと詳細ランキング モデルによって出力されるスコア分布が可能な限り一致することが望まれます。##図 5 ファインランキング予測スコア構築補助損失

具体的な実装に関しては、2 段階の蒸留パラダイムを使用して、事前トレーニングされた詳細なランキング モデルに基づいて粗いランキング モデルを蒸留します。蒸留損失には、粗いランキング モデルの出力の最小二乗誤差が使用されます。式 (1) に示すように、詳細ランキング モデルの出力を計算し、最終損失に対する蒸留損失の影響を制御するパラメータ Lambda を追加します。精密な分別蒸留法を使用し、オフライン効果は Recall@150 5PP、オンライン効果 CTR は 0.05% です。
3.1.3 特徴表現の抽出
業界では、知識の抽出を使用して、詳細なランキング ガイダンスと大まかなランキング表現のモデリングを実現しています。モデル効果 [7] を改善しますが、従来の方法を直接使用して表現を蒸留することには次の欠点があります。 まず、大まかなソートと詳細なソートの間のソート関係を蒸留することは不可能であり、前述したように、我々のソート結果の蒸留は不可能です。シナリオ、オフライン、オンライン 効果は改善されました; 2 つ目は、表現メトリックとして KL 発散を使用する従来の知識抽出スキームであり、表現の各次元を独立して処理し、関連性の高い構造化された情報を効果的に抽出できません [9]。米国では、グループ検索シナリオでは、データが高度に構造化されているため、表現の蒸留に従来の知識の蒸留戦略を使用しても、この構造化された知識をうまく捕捉できない可能性があります。
対比学習技術を粗いランキングモデルに適用することで、細かいランキングモデルの表現を抽出する際に、粗いランキングモデルでも順序関係を抽出できるようになります。大まかなモデルを表すには 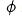 を使用し、詳細なモデルを表すには
を使用し、詳細なモデルを表すには 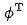 を使用します。 q がデータセット内のリクエストであるとします。
を使用します。 q がデータセット内のリクエストであるとします。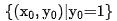 はリクエストの正の例であり、
はリクエストの正の例であり、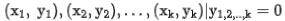 はリクエストに対応する k 個の負の例です。
はリクエストに対応する k 個の負の例です。
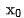 を粗いランキング ネットワークと詳細なランキング ネットワークにそれぞれ入力し、対応する表現
を粗いランキング ネットワークと詳細なランキング ネットワークにそれぞれ入力し、対応する表現  を取得します。同時に、
を取得します。同時に、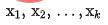 を粗いランキング ネットワークに入力し、粗いランキング モデルによってエンコードされた表現
を粗いランキング ネットワークに入力し、粗いランキング モデルによってエンコードされた表現 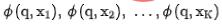 を取得します。対照学習のための負の例ペアの選択には、詳細なソートの順序をビンに分割するという戦略 3 の解決策を採用します。同じビン内の詳細なソートとラフなソートの表現ペアは正の例とみなされ、粗いソートの順序はビンに分割されます。表現ペアは負の例とみなされ、InfoNCE Loss がこの目標を最適化するために使用されます:
を取得します。対照学習のための負の例ペアの選択には、詳細なソートの順序をビンに分割するという戦略 3 の解決策を採用します。同じビン内の詳細なソートとラフなソートの表現ペアは正の例とみなされ、粗いソートの順序はビンに分割されます。表現ペアは負の例とみなされ、InfoNCE Loss がこの目標を最適化するために使用されます:
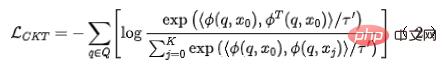
ここで、 は 2 つのベクトルの内積を表し、 は温度係数を表します。 InfoNCE 損失の特性を分析することによって、上記の式が本質的に、粗い表現と細かい表現の間の相互情報を最大化する下限と同等であることを見つけるのは難しくありません。したがって、この方法は本質的に相互情報レベルでの細かい表現と粗い表現の間の一貫性を最大化し、構造化された知識をより効果的に抽出することができます。

#図 6 細かい順位付けの情報伝達の比較学習
上記の式 (1) に基づく) これに加えて、補足的な対比学習表現蒸留損失、オフライン効果 Recall@150 14PP、オンライン CTR 0.15%。関連研究の詳細については、論文 [10] (投稿中) を参照してください。
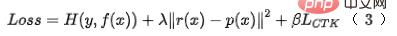
3.2 効果とパフォーマンスの統合最適化
前述したように、オンライン予測の大まかなランキング候補セットは比較的大きいため、システムの完全なリンク パフォーマンスの制約を考慮すると、大まかなランキングでは次の点を考慮する必要があります。予測効率。上記の作業はすべて、単純な DNN 蒸留のパラダイムに基づいて最適化されていますが、次の 2 つの問題があります。
- 現時点では、オンラインのパフォーマンスによって制限されており、単純な機能のみを使用しています。より豊富な相互特徴が導入されないため、モデル効果をさらに改善する余地が生じます。
- 固定された大まかなモデル構造を使用して蒸留すると、蒸留効果が失われ、次善の解決策が得られます [11]。
私たちの実際の経験によれば、ラフ層にクロスフィーチャを直接導入することはオンライン遅延要件を満たすことができません。そこで、上記の問題を解決するために、ニューラル ネットワーク アーキテクチャ検索に基づいて、ラフ ランキング モデルの効果とパフォーマンスを同時に最適化し、条件を満たす最適な機能の組み合わせとモデルを選択するラフ ランキング モデリング ソリューションを検討、実装しました。構造、全体的なアーキテクチャ図を以下の図 7 に示します:

図 7 NAS# に基づく機能とモデル構造
##Select 以下では、ニューラル ネットワーク アーキテクチャの検索 (NAS) と効率モデリングの導入の 2 つの主要な技術ポイントを簡単に紹介します。
- ニューラル ネットワーク アーキテクチャの検索: 上の図 7 に示すように、ProxylessNAS [12] に基づくモデリング手法を採用し、ネットワーク パラメーターに加えて、モデル全体のトレーニングによって機能が追加されます。マスクパラメータとネットワークアーキテクチャパラメータ これらのパラメータは微分可能であり、モデルターゲットとともに学習されます。特徴選択部分では、ベルヌーイ分布に基づくマスク パラメーターを各特徴に導入します (式 (4) を参照)。ベルヌーイ分布の θ パラメーターはバックプロパゲーションによって更新され、最終的に各特徴の重要度が取得されます。構造選択部分では、L 層 Mixop 表現が使用されます。Mixop の各グループには N 個のオプションのネットワーク構造単位が含まれます。実験では、隠れ層ニューラル ユニットの数が異なる多層パーセプトロンを使用しました。ここで、N= {1024 、 512, 256, 128, 64} と、隠れユニット番号 0 の構造ユニットも追加しました。これは、異なる層数のニューラル ネットワークを選択するために使用されます。

- # 効率モデリング: モデル目標で効率メトリクスをモデル化するには、微分可能な学習目標を採用する必要があります。モデルの消費時間を表すために、大まかなモデルの消費時間は、主に機能の消費時間とモデル構造の消費時間に分けられます。
はサーバーによって記録された各特性の遅延。 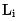
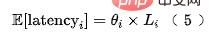 #実際の特性は 2 つに分類でき、1 つは上り透過型の特性であり、その遅延の主な原因は次のとおりです。アップストリーム伝送遅延時間; 別のタイプの特徴がローカル取得 (KV の読み取りまたは計算) から得られる場合、各特徴の組み合わせの遅延は次のようにモデル化できます:
#実際の特性は 2 つに分類でき、1 つは上り透過型の特性であり、その遅延の主な原因は次のとおりです。アップストリーム伝送遅延時間; 別のタイプの特徴がローカル取得 (KV の読み取りまたは計算) から得られる場合、各特徴の組み合わせの遅延は次のようにモデル化できます:
ここで、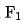 と
と 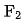 は、対応する機能セットの数
は、対応する機能セットの数 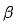 と
と 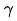 を表します。 システム機能プルの同時実行性のモデリング。
を表します。 システム機能プルの同時実行性のモデリング。
モデル構造の遅延モデリングについては、上の図 7 の右側を参照してください。これらの Mixop の実行はシーケンシャルに実行されるため、モデル構造の遅延を再帰的に計算できます。このとき、モデル部分全体の消費時間を Mixop の最後の層で表現することができ、その模式図を以下の図 8 に示します。 #図 8 モデル拡張時間の計算図
 #図 8 の左側は、ネットワーク アーキテクチャの選択を備えた大まかなネットワークです。ここで、 は、ニューラル ユニットの重みを表します。番目の層。右側はネットワーク遅延計算の概略図です。したがって、モデル全体の予測部分の消費時間は、式 (7) に示すように、モデルの最後の層で表すことができます。効率指標をモデルに導入します。モデルトレーニングの最終的な損失は次の式 (8) に示されます。ここで、f は細かいランキングネットワークを表し、
#図 8 の左側は、ネットワーク アーキテクチャの選択を備えた大まかなネットワークです。ここで、 は、ニューラル ユニットの重みを表します。番目の層。右側はネットワーク遅延計算の概略図です。したがって、モデル全体の予測部分の消費時間は、式 (7) に示すように、モデルの最後の層で表すことができます。効率指標をモデルに導入します。モデルトレーニングの最終的な損失は次の式 (8) に示されます。ここで、f は細かいランキングネットワークを表し、
はスコアリング出力を表します。それぞれ大まかなランキングと細かいランキングです。
ニューラル ネットワーク アーキテクチャ検索のモデリング、オフライン Recall@150 11PP、そして最後に、大まかなランキング モデルの効果と予測パフォーマンスを共同で最適化します。オンライン 遅延が増加しない場合、オンライン指標の CTR は 0.12% です。詳細な作業は [13] にあり、KDD 2022 によって承認されています。
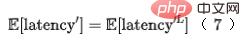
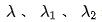

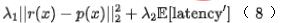 まず、業界で一般的に使用されている蒸留スキームを利用して、詳細ランキングをリンクして大まかなランキングを最適化し、3 つのレベルの詳細ランキング結果の蒸留、詳細ランキングの予測スコアを実行します。オンライン遅延を増加させることなく、ラフ レイアウト モデルの効果を向上させるために、多数の実験が実行されました。第二に、従来の蒸留方法では分類シナリオで特徴構造情報をうまく処理できないことを考慮して、対照学習に基づいて細かい分類情報を粗い分類に転送する独自のスキームを開発しました。
まず、業界で一般的に使用されている蒸留スキームを利用して、詳細ランキングをリンクして大まかなランキングを最適化し、3 つのレベルの詳細ランキング結果の蒸留、詳細ランキングの予測スコアを実行します。オンライン遅延を増加させることなく、ラフ レイアウト モデルの効果を向上させるために、多数の実験が実行されました。第二に、従来の蒸留方法では分類シナリオで特徴構造情報をうまく処理できないことを考慮して、対照学習に基づいて細かい分類情報を粗い分類に転送する独自のスキームを開発しました。
最後に、大まかな最適化は本質的に効果とパフォーマンスのトレードオフであるとさらに検討し、効果とパフォーマンスを同時に最適化するために多目的モデリングのアイデアを採用しました。ニューラル ネットワーク アーキテクチャを自動的に実装し、検索テクノロジを使用して問題を解決し、モデルが最高の効率と効果で特徴セットとモデル構造を自動的に選択できるようにします。今後も、次の側面から粗層技術を繰り返していきます。
- 粗い行の多目的モデリング: 現在の粗い行は本質的に単一目的モデルです。現在、細かい行レイヤーの多目的モデリングを適用しようとしています。粗い行へ。
- 大まかなソートとリンクされたシステム全体の動的なコンピューティング能力の割り当て: 大まかなソートは、再現のコンピューティング能力と詳細なソートのコンピューティング能力を制御できます。 , モデルが必要とする計算能力は異なるため、動的な計算能力の割り当てにより、オンライン効果を低下させることなくシステムの計算能力消費を削減できます。現時点では、この面で一定のオンライン効果を達成しています。
5. 付録
従来のソートオフラインインジケーターは主にNDCG、MAP、AUCインジケーターに基づいていますが、大まかなソートの場合、その本質はより重要です。セットの選択を対象とした再現タスクに偏っているため、従来のランキング指標は、大まかなランキング モデルの反復効果の測定には役に立ちません。粗いソートのオフライン効果の尺度として、[6] のリコール指標を参照します。つまり、粗いソートと詳細なソートの TopK 結果の整合度を測定するためのグラウンド トゥルースとして詳細なソート結果を使用します。リコール指標の具体的な定義は次のとおりです:
この式の物理的な意味は、大まかな並べ替えの上位 K と詳細な並べ替えの上位 K の間の重複を測定することです。インジケーターは、大まかなソート セットの選択とより一貫性があります。
6. 著者紹介
Xiao Jiang、Suo Gui、Li Xiang、Cao Yue、Pei Hao、Xiao Yao、Dayao、Chen Sheng、Yun Sen、Li Qianなど、すべて Meituan プラットフォーム/検索推奨アルゴリズム部門からのものです。
以上がMeituan検索のラフランキング最適化の探索と実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。