




1. TransBigData の概要
TransBigData は、一般的な交通時空間ビッグデータ (タクシーの GPS データ、シェア自転車など) を処理します。データやバス GPS データなど)は、迅速かつ簡潔な方法を提供します。 TransBigData は、トラフィック時空間分析の各段階でさまざまな処理方法を提供し、コードは簡潔、効率的、柔軟で使いやすい、複雑なデータ タスクも簡潔なコードで実装できます。
現在、TransBigData は主に次のメソッドを提供しています。
- データ前処理: データセットのデータ量、期間、サンプリング間隔などの基本情報を迅速に計算するメソッドを提供します。この種のデータ ノイズは、対応するクリーニング方法を提供します。
- データ ラスター化: 調査エリア内で複数の種類の地理ラスター (長方形、三角形、六角形、およびジオハッシュ ラスター) を生成および照合するためのメソッド システムを提供します。これらのラスターは迅速にベクトル化できます。アルゴリズムは、空間点データをマップ上にマッピングします。地理ラスター。
- データ視覚化: 視覚化パッケージ keplergl に基づいて、簡単なコードを使用して Jupyter Notebook 上にデータを対話的かつ視覚的に表示できます。
- 軌跡処理: 軌跡データ GPS ポイント、密集軌跡点、疎軌跡点などから軌跡線種を生成します。
- 地図ベースマップ、座標変換と計算: 地図ベースマップとさまざまな特殊座標系の間の座標変換を読み込み、表示します。
- 具体的な処理手法:タクシーのGPSデータからの注文開始地点と終了地点の抽出、携帯電話の信号データや地下鉄網のGISデータからの居住地・勤務先の特定など、各種の具体的なデータに対応した処理手法を提供ネットワークトポロジの構築や最短経路の計算などを行います。
TransBigData は pip または conda を通じてインストールできます。コマンド プロンプトで次のコードを実行してインストールします:
pip install -U transbigdata
インストールが完了したら、Python で次のコードを実行してインポートしますトランスビッグデータバッグ。
import transbigdata as tbd
2. データの前処理
TransBigData は、データ処理で一般的に使用される Pandas および GeoPandas パッケージとシームレスに接続できます。まず、Pandas パッケージを導入し、タクシー GPS データを読み取ります。
import pandas as pd
# 读取数据
data = pd.read_csv('TaxiData-Sample.csv',header = None)
data.columns = ['VehicleNum','time','lon','lat','OpenStatus','Speed']
data.head()結果を図 2 に示します。

▲図 2 タクシー GPS データ
次に、GeoPandas パッケージを導入し、調査範囲の地域情報を読み取って表示します:
import geopandas as gpd # 读取研究范围区域信息 sz = gpd.read_file(r'sz/sz.shp') sz.plot()
結果を図 3 に示します:

▲図 3 調査範囲の地域情報
TransBigData パッケージには、交通時空間データの一般的な前処理方法がいくつか統合されています。このうち、tbd.clean_outofshapeメソッドはデータと調査範囲領域情報を入力し、調査範囲外のデータを削除することができます。 tbd.clean_taxi_status メソッドを使用すると、タクシー GPS データ内の乗客ステータスの瞬間的な変化の記録を削除できます。前処理メソッドを使用する場合は、データ テーブルの重要な情報列に対応する列名を渡す必要があります。コードは次のとおりです:
# 数据预处理 #剔除研究范围外的数据,计算原理是在方法中先栅格化后栅格匹配研究范围后实现对应。因此这里需要同时定义栅格大小,越小则精度越高 data = tbd.clean_outofshape(data, sz, col=['lon', 'lat'], accuracy=500) # 剔除出租车数据中载客状态瞬间变化的数据 data = tbd.clean_taxi_status(data, col=['VehicleNum', 'time', 'OpenStatus'])
上記のコードを処理した後、すでにタクシーのGPSは研究対象外でデータ化されており、乗客状況の瞬間的な変化などのデータはデータから削除されています。
3. データ ラスター化
ラスター形式 (地理空間内で同じサイズのグリッド) は、データ分布を表現する最も基本的な方法です。GPS データがラスター化された後、各データ ポイントには以下が含まれます。それらが配置されているラスターに関する情報。ラスターを使用してデータの分布を表現すると、ラスターが表す分布は実際の状況に近くなります。
TransBigData ツールは、完全で高速かつ便利なラスター処理システムを提供します。 TransBigData をラスター分割に使用する場合、最初にラスター化パラメーターを決定する必要があります (これは、ラスター座標系を定義すると理解できます)。パラメーターは、迅速なラスター化に役立ちます:
# 定义研究范围边界 bounds = [113.75, 22.4,114.62, 22.86] # 通过边界获取栅格化参数 params = tbd.area_to_params(bounds,accuracy = 1000) params
Output :
{'slon': 113.75,
'slat': 22.4,
'deltalon': 0.00974336289289822,
'deltalat': 0.008993210412845813,
'theta': 0,
'method': 'rect',
'gridsize': 1000}このとき出力されるラスタライズパラメータparamsの内容には、ラスタ座標系の原点座標(slon、slat)と、単一ラスタの経度、緯度が格納されます。 deltalon、deltalat)、グリッドの回転角 (theta)、グリッドの形状 (メソッド パラメーター、値は正方形、rect、三角形 tri、および hexagon hexa にすることができます)、およびグリッドのサイズ (gridsize パラメーター、メートル単位) )。
ラスター化パラメーターを取得した後、TransBigData で提供されるメソッドを使用して、GPS データのラスター マッチングや生成などの操作を実行できます。
完全なラスター処理方法システムを図 4 に示します。
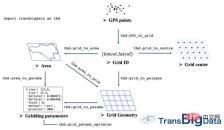
▲図 4 TransBigData が提供するラスター処理システム
Use各タクシーの GPS ポイントを生成する tbd.GPS_to_grid メソッド。このメソッドは数値列 LONCOL と LATCOL を生成し、一緒にグリッドを指定します:
# 将GPS数据对应至栅格,将生成的栅格编号列赋值到数据表上作为新的两列 data['LONCOL'],data['LATCOL']= tbd.GPS_to_grids(data['lon'],data['lat'],params)
下一步,聚合集计每一栅格内的数据量,并为栅格生成地理几何图形,构建GeoDataFrame:
# 聚合集计栅格内数据量 grid_agg=data.groupby(['LONCOL','LATCOL'])['VehicleNum'].count().reset_index() # 生成栅格的几何图形 grid_agg['geometry']=tbd.grid_to_polygon([grid_agg['LONCOL'],grid_agg['LATCOL']],params) # 转换为GeoDataFrame grid_agg=gpd.GeoDataFrame(grid_agg) # 绘制栅格 grid_agg.plot(column = 'VehicleNum',cmap = 'autumn_r')
结果如图5所示:

▲图5 数据栅格化的结果
对于一个正式的数据可视化图来说,我们还需要添加底图、色条、指北针和比例尺。TransBigData也提供了相应的功能,代码如下:
import matplotlib.pyplot as plt
fig =plt.figure(1,(8,8),dpi=300)
ax =plt.subplot(111)
plt.sca(ax)
# 添加行政区划边界作为底图
sz.plot(ax=ax,edgecolor=(0,0,0,0),facecolor=(0,0,0,0.1),linewidths=0.5)
# 定义色条位置
cax = plt.axes([0.04, 0.33, 0.02, 0.3])
plt.title('Data count')
plt.sca(ax)
# 绘制数据
grid_agg.plot(column = 'VehicleNum',cmap = 'autumn_r',ax = ax,cax = cax,legend = True)
# 添加指北针和比例尺
tbd.plotscale(ax,bounds = bounds,textsize = 10,compasssize = 1,accuracy = 2000,rect = [0.06,0.03],zorder = 10)
plt.axis('off')
plt.xlim(bounds[0],bounds[2])
plt.ylim(bounds[1],bounds[3])
plt.show()结果如图6所示:
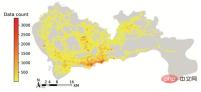
▲图6 tbd包绘制的出租车GPS数据分布
4、订单起讫点OD提取与聚合集计
针对出租车GPS数据,TransBigData提供了直接从数据中提取出出租车订单起讫点(OD)信息的方法,代码如下:
# 从GPS数据提取OD oddat=tbd.taxigps_to_od(data,col=['VehicleNum','time','Lng','Lat','OpenStatus']) oddata
结果如图7所示:

▲图7 tbd包提取的出租车OD
TransBigData包提供的栅格化方法可以让我们快速地进行栅格化定义,只需要修改accuracy参数,即可快速定义不同大小粒度的栅格。我们重新定义一个2km*2km的栅格坐标系,将其参数传入tbd.odagg_grid方法对OD进行栅格化聚合集计并生成GeoDataFrame:
# 重新定义栅格,获取栅格化参数 params=tbd.area_to_params(bounds,accuracy = 2000) # 栅格化OD并集计 od_gdf=tbd.odagg_grid(oddata,params) od_gdf.plot(column = 'count')
结果如图8所示:

▲图8 tbd集计的栅格OD
添加地图底图,色条与比例尺指北针:
# 创建图框
import matplotlib.pyplot as plt
fig =plt.figure(1,(8,8),dpi=300)
ax =plt.subplot(111)
plt.sca(ax)
# 添加行政区划边界作为底图
sz.plot(ax=ax,edgecolor=(0,0,0,1),facecolor=(0,0,0,0),linewidths=0.5)
# 绘制colorbar
cax=plt.axes([0.05, 0.33, 0.02, 0.3])
plt.title('Data count')
plt.sca(ax)
# 绘制OD
od_gdf.plot(ax = ax,column = 'count',cmap = 'Blues_r',linewidth = 0.5,vmax = 10,cax = cax,legend = True)
# 添加比例尺和指北针
tbd.plotscale(ax,bounds=bounds,textsize=10,compasssize=1,accuracy=2000,rect = [0.06,0.03],zorder = 10)
plt.axis('off')
plt.xlim(bounds[0],bounds[2])
plt.ylim(bounds[1],bounds[3])
plt.show()结果如图9所示:

▲ 图9 TransBigData绘制的栅格OD数据
同时,TransBigData包也提供了将OD直接聚合集计到区域间的方法:
# OD集计到区域 # 方法1:在不传入栅格化参数时,直接用经纬度匹配 od_gdf = tbd.odagg_shape(oddata,sz,round_accuracy=6) # 方法2:传入栅格化参数时,程序会先栅格化后匹配以加快运算速度,数据量大时建议使用 od_gdf = tbd.odagg_shape(oddata,sz,params = params) od_gdf.plot(column = 'count')
结果如图10所示:

▲图10 tbd集计的小区OD
加载地图底图并调整出图参数:
# 创建图框
import matplotlib.pyplot as plt
import plot_map
fig =plt.figure(1,(8,8),dpi=300)
ax =plt.subplot(111)
plt.sca(ax)
# 添加行政区划边界作为底图
sz.plot(ax = ax,edgecolor = (0,0,0,0),facecolor = (0,0,0,0.2),linewidths=0.5)
# 绘制colorbar
cax = plt.axes([0.05, 0.33, 0.02, 0.3])
plt.title('count')
plt.sca(ax)
# 绘制OD
od_gdf.plot(ax = ax,vmax = 100,column = 'count',cax = cax,cmap = 'autumn_r',linewidth = 1,legend = True)
# 添加比例尺和指北针
tbd.plotscale(ax,bounds = bounds,textsize = 10,compasssize = 1,accuracy = 2000,rect = [0.06,0.03],zorder = 10)
plt.axis('off')
plt.xlim(bounds[0],bounds[2])
plt.ylim(bounds[1],bounds[3])
plt.show()结果如图11所示:
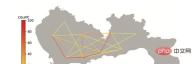
▲ 图11区域间OD可视化结果
5、交互可视化
在TransBigData中,我们可以对出租车数据使用简单的代码在jupyter notebook中快速进行交互可视化。这些可视化方法底层依托了keplergl包,可视化的结果不再是静态的图片,而是能够与鼠标响应交互的地图应用。
tbd.visualization_data方法可以实现数据分布的可视化,将数据传入该方法后,TransBigData会首先对数据点进行栅格集计,然后生成数据的栅格,并将数据量映射至颜色上。代码如下:
结果如图12所示:
# 可视化数据点分布 tbd.visualization_data(data,col = ['lon','lat'],accuracy=1000,height = 500)
▲ 图12数据分布的栅格可视化
对于出租车数据中所提取出的出行OD,也可使用tbd.visualization_od方法实现OD的弧线可视化。该方法也会对OD数据进行栅格聚合集计,生成OD弧线,并将不同大小的OD出行量映射至不同颜色。代码如下:
# 可视化数据点分布 tbd.visualization_od(oddata,accuracy=2000,height = 500)
结果如图13所示:
▲ 图13 OD分布的弧线可视化
对个体级的连续追踪数据,tbd.visualization_trip方法可以将数据点处理为带有时间戳的轨迹信息并动态地展示,代码如下:
# 动态可视化轨迹 tbd.visualization_trip(data,col = ['lon','lat','VehicleNum','time'],height = 500)
结果图14所示。点击其中的播放键,可以看到出租车运行的动态轨迹效果。
以上がすごいですね、Python で交通データの可視化が実現!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Python vs. C:比較されたアプリケーションとユースケースApr 12, 2025 am 12:01 AM
Python vs. C:比較されたアプリケーションとユースケースApr 12, 2025 am 12:01 AMPythonは、データサイエンス、Web開発、自動化タスクに適していますが、Cはシステムプログラミング、ゲーム開発、組み込みシステムに適しています。 Pythonは、そのシンプルさと強力なエコシステムで知られていますが、Cは高性能および基礎となる制御機能で知られています。
 2時間のPython計画:現実的なアプローチApr 11, 2025 am 12:04 AM
2時間のPython計画:現実的なアプローチApr 11, 2025 am 12:04 AM2時間以内にPythonの基本的なプログラミングの概念とスキルを学ぶことができます。 1.変数とデータ型、2。マスターコントロールフロー(条件付きステートメントとループ)、3。機能の定義と使用を理解する4。
 Python:主要なアプリケーションの調査Apr 10, 2025 am 09:41 AM
Python:主要なアプリケーションの調査Apr 10, 2025 am 09:41 AMPythonは、Web開発、データサイエンス、機械学習、自動化、スクリプトの分野で広く使用されています。 1)Web開発では、DjangoおよびFlask Frameworksが開発プロセスを簡素化します。 2)データサイエンスと機械学習の分野では、Numpy、Pandas、Scikit-Learn、Tensorflowライブラリが強力なサポートを提供します。 3)自動化とスクリプトの観点から、Pythonは自動テストやシステム管理などのタスクに適しています。
 2時間でどのくらいのPythonを学ぶことができますか?Apr 09, 2025 pm 04:33 PM
2時間でどのくらいのPythonを学ぶことができますか?Apr 09, 2025 pm 04:33 PM2時間以内にPythonの基本を学ぶことができます。 1。変数とデータ型を学習します。2。ステートメントやループの場合などのマスター制御構造、3。関数の定義と使用を理解します。これらは、簡単なPythonプログラムの作成を開始するのに役立ちます。
 プロジェクトの基本と問題駆動型の方法で10時間以内にコンピューター初心者プログラミングの基本を教える方法は?Apr 02, 2025 am 07:18 AM
プロジェクトの基本と問題駆動型の方法で10時間以内にコンピューター初心者プログラミングの基本を教える方法は?Apr 02, 2025 am 07:18 AM10時間以内にコンピューター初心者プログラミングの基本を教える方法は?コンピューター初心者にプログラミングの知識を教えるのに10時間しかない場合、何を教えることを選びますか...
 中間の読書にどこでもfiddlerを使用するときにブラウザによって検出されないようにするにはどうすればよいですか?Apr 02, 2025 am 07:15 AM
中間の読書にどこでもfiddlerを使用するときにブラウザによって検出されないようにするにはどうすればよいですか?Apr 02, 2025 am 07:15 AMfiddlereveryversings for the-middleの測定値を使用するときに検出されないようにする方法
 Python 3.6にピクルスファイルをロードするときに「__Builtin__」モジュールが見つからない場合はどうすればよいですか?Apr 02, 2025 am 07:12 AM
Python 3.6にピクルスファイルをロードするときに「__Builtin__」モジュールが見つからない場合はどうすればよいですか?Apr 02, 2025 am 07:12 AMPython 3.6のピクルスファイルのロードレポートエラー:modulenotFounderror:nomodulenamed ...
 風光明媚なスポットコメント分析におけるJieba Wordセグメンテーションの精度を改善する方法は?Apr 02, 2025 am 07:09 AM
風光明媚なスポットコメント分析におけるJieba Wordセグメンテーションの精度を改善する方法は?Apr 02, 2025 am 07:09 AM風光明媚なスポットコメント分析におけるJieba Wordセグメンテーションの問題を解決する方法は?風光明媚なスポットコメントと分析を行っているとき、私たちはしばしばJieba Wordセグメンテーションツールを使用してテキストを処理します...


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

ドリームウィーバー CS6
ビジュアル Web 開発ツール

WebStorm Mac版
便利なJavaScript開発ツール

