
ホームページ >テクノロジー周辺機器 >AI >NetEase Cloud Music アルゴリズム プラットフォームの研究開発専門家 Huang Bin 氏: NetEase Cloud Music オンライン予測システムの実践と考察
NetEase Cloud Music アルゴリズム プラットフォームの研究開発専門家 Huang Bin 氏: NetEase Cloud Music オンライン予測システムの実践と考察

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-10 19:21:011370ブラウズ
ゲスト | Huang Bin
コンピレーション | Tu Chengye
最近、51CTO が主催する AISummit グローバル人工知能テクノロジーカンファレンスで、NetEase クラウド ミュージック アルゴリズム プラットフォームの研究開発の専門家である Huang Bin が登壇しました。 、基調講演「NetEase Cloud Music Online 予測システムの実践と考察」では、技術研究と発達。
皆さんにインスピレーションを与えていただければと思い、スピーチの内容を以下のように整理しました。
全体的なシステム アーキテクチャ
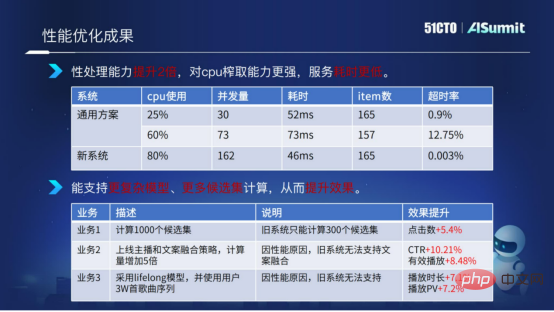
まず、次の図に示すように、推定システム全体のアーキテクチャを見てみましょう。
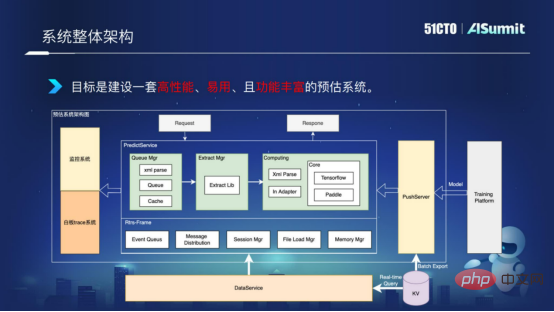
システム アーキテクチャ全体の中央にある予測サーバー
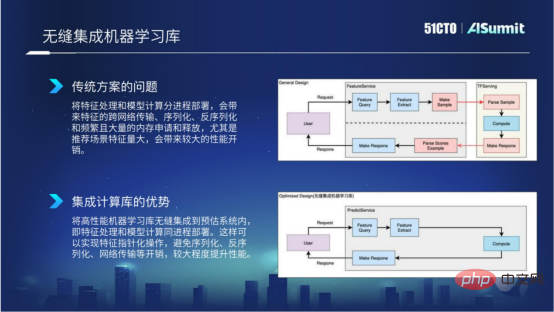
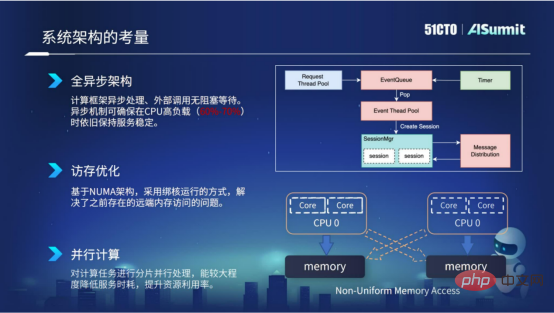
## は、クエリ コンポーネント、特徴処理コンポーネント、モデル計算コンポーネントを含む、予測システムのコア コンポーネントです。左側の監視システムは、システム ネットワークのスムーズな流れを確保するために回線ネットワーク サービスを監視するために使用されます。右側の PushServer はモデル プッシュに使用され、最新モデルをオンライン予測システムにプッシュして予測します。 目標は、高性能で使いやすく、機能が豊富な予測システムを構築することです。 ハイ パフォーマンス コンピューティングコンピューティング パフォーマンスを向上させるにはどうすればよいですか?私たちによくあるコンピューティング パフォーマンスの問題は何ですか? 3 つの側面から詳しく説明します。- 特徴処理
- モデルの更新
- コンピューティング スケジューリング
1 つ目は同期クエリです。これは主に、より重要な機能に適しています。もちろん、同期クエリのパフォーマンスはそれほど効率的ではありません。
2 番目のタイプは非同期クエリで、主に一部の「Aite ディメンション」機能をターゲットとしています。これらの機能はそれほど重要ではない可能性があるため、この非同期クエリ方法を使用できます。
3 番目のタイプは特徴量一括インポートで、主に特徴量がそれほど大きくない特徴量データに適しています。これらの機能をプロセスにバッチでインポートすることで、機能のローカライズされたクエリを実装でき、パフォーマンスが非常に効率的になります。
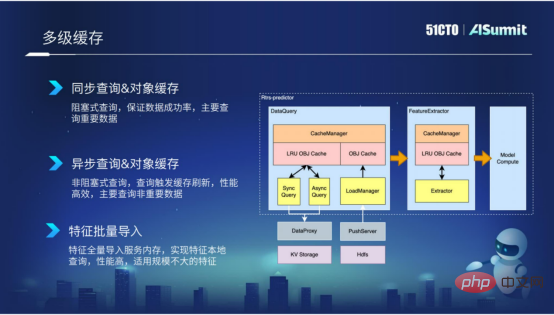
マルチレベル キャッシュ
4. モデル計算の最適化
キャッシュ メカニズムを導入した後、動作の最適化を見てみましょう。モデル計算のモデル計算では、主にモデル入力の最適化、モデル読み込みの最適化、カーネルの最適化の3つの側面から最適化を行います。
- モデル入力の最適化
モデル入力領域では、TF Servering が Example の入力を使用していることは誰もが知っています。 Example 入力には、Example の構築、Example のシリアル化と逆シリアル化、モデル内の Parse Example の呼び出しが含まれますが、これには比較的時間がかかります。
下の図では、[最適化前] のスクリーンショットを見て、モデルの計算と最適化の前のデータ統計を示します。解析に時間がかかる比較的長い解析例があり、解析例が解析される前に他の操作が並列スケジューリングを実行できないことがわかります。モデル ツリーのパフォーマンスの問題を解決するために、予測システムに高性能モデル入力ソリューションをカプセル化しました。新しいソリューションを通じて、フィーチャ入力のコピーをゼロにすることができるため、この例の時間のかかる構築と解析が削減されます。
下の図では、[最適化後] のスクリーンショットを見て、モデルの計算と最適化後のデータ統計を示しています。解析例の解析時間がなくなり、例の解析のみが行われていることがわかります。時間がかかります。

- モデル読み込みの最適化
- カーネルの最適化
上位インターフェイス層は主にハイレベル インターフェイスを提供しており、企業はこの層インターフェイスを実装するだけで済み、コード開発が大幅に軽減されます。
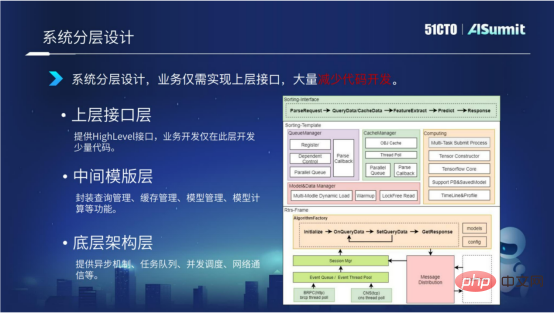
システムの階層構造設計により、最下層と中間層のコードを異なるビジネス間で再利用できるため、開発は小規模なシステムの開発のみに集中する必要があります。最上層のコード量。同時に、上位インターフェイス層のコード開発をさらに削減する方法はないか、ということも考えています。以下で詳しく紹介していきましょう。
2. ユニバーサルクエリのカプセル化
ダイナミック PB テクノロジーに基づく特徴クエリと特徴分析によって形成される一般的なソリューションのカプセル化を通じて、テーブル名、クエリ KEY、キャッシュを構成することができます。 XML 、クエリの依存関係などを介してのみ、機能のクエリ、解析、キャッシュのプロセス全体を実現できます。
下の図に示すように、数行の構成で複雑なクエリ ロジックを実装できます。同時に、クエリのカプセル化によってクエリ効率が向上します。

3. 特徴計算のカプセル化
特徴計算は、推定システム全体の中でコード開発の複雑さが最も高いモジュールであると言えます。特徴?計算についてはどうですか?
特徴量計算にはオフラインプロセスとオンラインプロセスが含まれます。オフライン プロセスは実際にはオフライン サンプルであり、TF Recocd の形式など、オフライン トレーニング プラットフォームに必要ないくつかの形式を取得するために処理されます。オンライン プロセスは主にオンライン リクエストに対していくつかの特徴計算を実行し、処理を通じてオンライン予測プラットフォームに必要ないくつかの形式を取得します。実際、特徴処理の計算ロジックはオフライン プロセスでもオンライン プロセスでもまったく同じです。しかし、オフライン処理とオンライン処理では計算プラットフォームが異なり、使用言語も異なるため、特徴量計算を実装するには複数のコードを開発する必要があり、以下の3つの問題があります。
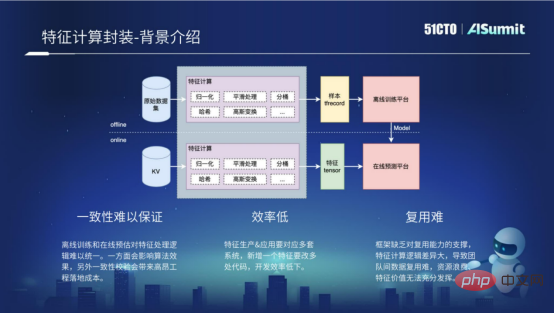
- #一貫性の保証が難しい
- 効率が悪い
- 再利用の難しさ

- 演算子の抽象化を実現するには、まずデータ プロトコルの統一を達成する必要があります。当社では、ダイナミック PB テクノロジーを使用して、フィーチャの元のデータ情報に基づく統一データに従ってフィーチャを処理し、オペレータ カプセル化のデータ基盤を提供します。次に、特徴処理プロセスをサンプリングしてカプセル化し、特徴計算プロセスを解析、計算、アセンブリ、例外処理に抽象化し、計算プロセス API を統合して演算子の抽象化を実現します。
- 演算子の抽象化が完了したら、演算子ライブラリを構築できます。オペレータ ライブラリは、プラットフォーム一般オペレータ ライブラリとビジネスカスタマイズ オペレータ ライブラリに分かれています。プラットフォームの一般的な演算子ライブラリは、主に企業レベルの再利用を実現するために使用されます。ビジネス カスタム オペレーター ライブラリは、グループ内での再利用を実現するために、ビジネスのいくつかのカスタム シナリオと特性を主な目的としています。演算子のカプセル化と演算子ライブラリの構築により、複数のシナリオでの特徴量計算の再利用を実現し、開発効率を向上します。
- 計算記述言語 DSL
特徴量計算の設定式とは、DSL と呼ばれる特徴量計算式を定義する設定済み言語を指します。設定言語により、演算子や四則演算などの多段の入れ子表現を実現できます。以下の最初のスクリーンショットは、構成された言語の特定の構文を示しています。

#特徴計算の構成言語を通じてどのようなメリットが得られるでしょうか?
まず、特徴量計算全体をコンフィグレーションで完了できるため、開発効率が向上します。
2 番目に、構成された特徴計算の式を公開することで、特徴計算のホット アップデートを実現できます。
3 番目に、トレーニングと予測は同じ特徴計算構成を使用して、オンラインとオフラインの一貫性を実現します。
これが特徴量計算式によるメリットです。
- 特徴の一貫性
前述したように、特徴の計算はオフラインプロセスとオンラインプロセスに分かれています。オフラインとオンラインのマルチプラットフォームの理由により、論理計算に一貫性がありません。この問題を解決するために、特徴コンピューティング フレームワークのクロスプラットフォーム実行機能を特徴コンピューティング フレームワークに実装しました。コア ロジックは C で開発され、C インターフェイスと Java インターフェイスは外部に公開されます。パッケージ化と構築のプロセス中に、C の so ライブラリと jar パッケージをワンクリックで実装できるため、オンライン計算の場合は C プラットフォームで、オフラインの Spark プラットフォームまたは Flink プラットフォームでは特徴計算を実行でき、特徴計算で表現できるようになります。特徴量の計算 オンラインとオフラインのロジックの一貫性を実現します。
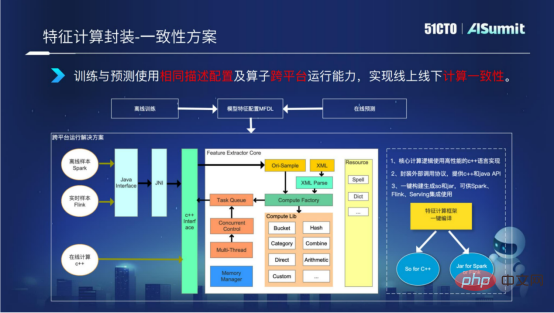
上記は、特徴量計算の具体的な状況を説明しています。特徴量コンピューティングがこれまでに達成した成果の一部を見てみましょう。
現在120社のオペレーターを蓄積しており、特徴量計算のDSL言語により設定を実現し、特徴量計算全体を完了することができます。当社が提供するクロスプラットフォーム操作機能により、オンラインとオフラインのロジックの不一致の問題が解決されます。
下図のスクリーンショットは、少ない構成で特徴量計算のプロセス全体を実現でき、特徴量計算の開発効率が大幅に向上することを示しています。

上記では、開発効率を向上させるための検討を紹介しました。一般に、システムの階層設計を通じてコードの再利用を改善し、クエリ、抽出、モデル計算をカプセル化することで構成可能な開発プロセスを実現できます。
4. モデル計算のカプセル化
モデル計算もカプセル化の形式を採用します。構成表現形式により、モデルの読み込み、モデルの入力構造、モデルの計算等を実現し、数行の構成でモデル計算全体の表現処理を実現します。

# モデルのリアルタイム実装
モデルのリアルタイム実装ケースを見てみましょう。
1. リアルタイム プロジェクトの背景
なぜこのようなモデル リアルタイム プロジェクトを行う必要があるのでしょうか?
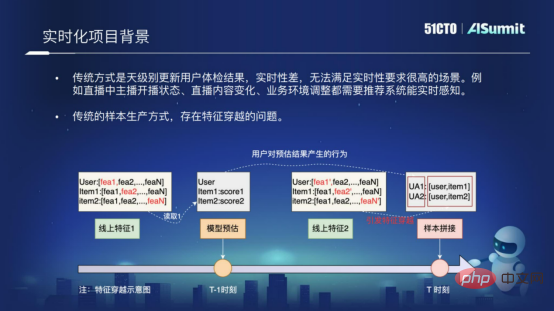
主な理由は、従来のレコメンド システムはユーザーのレコメンデーション結果を毎日更新するシステムであり、リアルタイム性が非常に低く、リアルタイム性が要求されるシナリオなどに対応できないためです。ライブ ブロードキャスト シーン、またはより高いリアルタイム要件が必要なその他のシナリオ。
もう 1 つの理由は、従来のサンプル作成方法には特徴の交差の問題があることです。機能交差とは何ですか?次の図は、特徴交差の根本的な理由を示しています. サンプルの結合のプロセスでは、「T-1」時点で推定されたモデルの構造を使用し、それを「T」時点の特徴と結合します。交差点が生じます。特徴の交差は回線ネットワークの推奨効果に大きく影響します。リアルタイム問題とサンプル交差の問題を解決するために、予測システムにそのようなモデルリアルタイムソリューションを実装しました。
2. リアルタイム ソリューションの紹介
モデル リアルタイム ソリューションは 3 つの次元から精緻化されています。
- サンプルのリアルタイム生成
- 増分モデル トレーニング
- リアルタイム予測システム
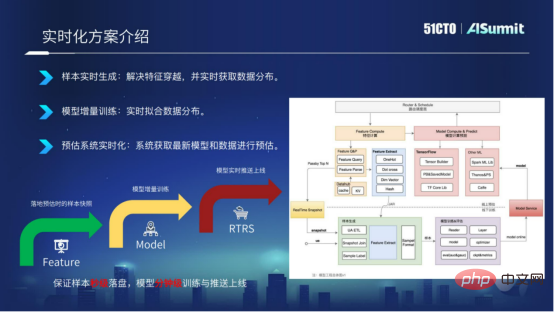
サンプルはリアルタイムで生成されます。オンライン予測システムに基づいて、予測システムの機能をリアルタイムで Kafka に実装し、RACE ID の形式で関連付けることにより、サンプルが数秒以内にディスクに配置されることを保証し、問題を解決できます。機能交差。
モデルの増分トレーニング。サンプルが数秒でディスクに配置された後、トレーニング モジュールを変更してモデルの増分トレーニングを実装し、モデルの分単位の更新を実現できます。
予測システムはリアルタイムです。分単位でモデルをエクスポートした後、モデルプッシュサービス「Push Server」を通じて最新モデルをオンライン予測システムにプッシュすることで、現場予測システムが最新モデルを予測に利用できるようになります。
一般的に言えば、リアルタイム モデル ソリューションは、数秒でサンプル配置、分レベルのトレーニング、分レベルのモデルのオンライン更新を実現することです。
当社の現在のモデルのリアルタイム ソリューションは、複数のシナリオに実装されています。リアルタイムモデルソリューションにより、業績は大幅に向上しました。
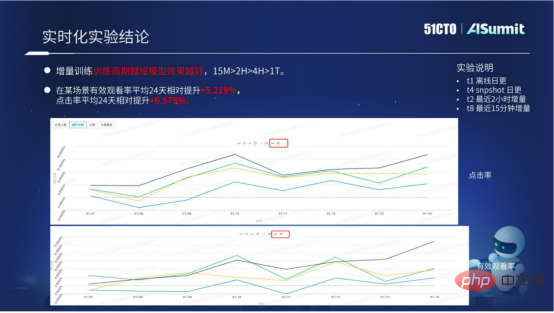
上の図は、主にモデル リアルタイム ソリューションの具体的な実験データを示しています。段階的なトレーニングが見られ、トレーニング期間は短いほど良いことがわかります。具体的なデータから、15 分のサイクルの効果が 2 時間、10 時間、または 1 日の効果よりもはるかに大きいことがわかります。現在のモデルのリアルタイム ソリューションには、標準化されたアクセス プロセスがすでに組み込まれており、バッチ処理でビジネスにより良い結果をもたらすことができます。
上記では、予測システムがコンピューティングのパフォーマンスを向上させる方法、開発効率を向上させる方法、エンジニアリング手段を通じてプロジェクトのアルゴリズムを改善する方法の 3 つの側面での探求と試みを紹介しています。
見積りシステム全体のプラットフォーム価値、あるいは見積りシステム全体のプラットフォームの目的は、「速い、良い、経済的」の 3 つの言葉に要約できます。
「クイック」とは、先ほど紹介したアプリケーション構築のことです。継続的にアプリケーションを構築することで、ビジネスの繰り返しがより効率化されることを期待しています。
「良好」とは、リアルタイム モデル ソリューションや特徴量計算によるオンラインおよびオフラインの論理的一貫性ソリューションなどのエンジニアリング手段を通じて、ビジネスにより良い結果をもたらすことを期待していることを意味します。
「保存」とは、推定されたシステムのより高いパフォーマンスを使用することを意味します。これにより、より多くのコンピューティング リソースが節約され、コンピューティング コストが節約されます。
以上がNetEase Cloud Music アルゴリズム プラットフォームの研究開発専門家 Huang Bin 氏: NetEase Cloud Music オンライン予測システムの実践と考察の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。