
ホームページ >テクノロジー周辺機器 >AI >「位置情報の埋め込み」: Transformer の秘密
「位置情報の埋め込み」: Transformer の秘密

- 王林転載
- 2023-04-10 10:01:031035ブラウズ
翻訳者 | Cui Hao
査読者 | Sun Shujuan
目次
- #はじめに
- NLP への埋め込みコンセプト
- Transformers への位置埋め込みが必要
- さまざまなタイプの初期試行錯誤実験
- 周波数ベースの位置埋め込み
- まとめ
- 参考文献
ディープ ラーニングの分野における Transformer アーキテクチャの導入は、間違いなく、静かな革命 道路を滑らかにすることは、NLP の支部にとって特に重要です。 Transformer アーキテクチャの最も重要な部分は「位置埋め込み」です。これにより、ニューラル ネットワークは長文内の単語の順序と単語間の依存関係を理解できるようになります。
RNN と LSTM は Transformer よりも前に導入されており、位置埋め込みを使用しなくても単語の順序を理解する機能があることはわかっています。そうなると、なぜこの概念が Transformer に導入され、この概念の利点がそれほど強調されているのかという明らかな疑問が生じるでしょう。この記事では、これらの原因と結果について説明します。NLP における埋め込みの概念
埋め込みは、生のテキストを数学ベクトルに変換するために使用される自然言語処理のプロセスです。これは、機械学習モデルがテキスト形式を直接処理して、さまざまな内部コンピューティング プロセスに使用することができないためです。Word2vec や Glove などのアルゴリズムの埋め込みプロセスは、単語埋め込みまたは静的埋め込みと呼ばれます。
このようにして、多数の単語を含むテキスト コーパスをトレーニング用のモデルに渡すことができます。モデルは、より頻繁に出現する単語が類似していると仮定して、各単語に対応する数学的値を割り当てます。このプロセスの後、結果の数学的値はさらなる計算に使用されます。
たとえば、テキスト コーパスには次のような 3 つの文があるとします。
- 英国政府は毎年、年次報告書を送信しています。国王と王妃は多額の補助金を発行し、政権をある程度コントロールできると主張した。
- 王室メンバーには国王と王妃に加え、娘のマリー=テレサ・シャーロット(マダム・ロワイヤル)、国王の妹レディ・エリザベス、従者クレイ・リらも含まれる。 。
- この話はモルドレッドの裏切りの知らせによって中断され、ランスロットは最後の致命的な争いには参加せず、王と女王の両方から生き残ったため、円卓は衰退しました。
画像出典:著者提供イラスト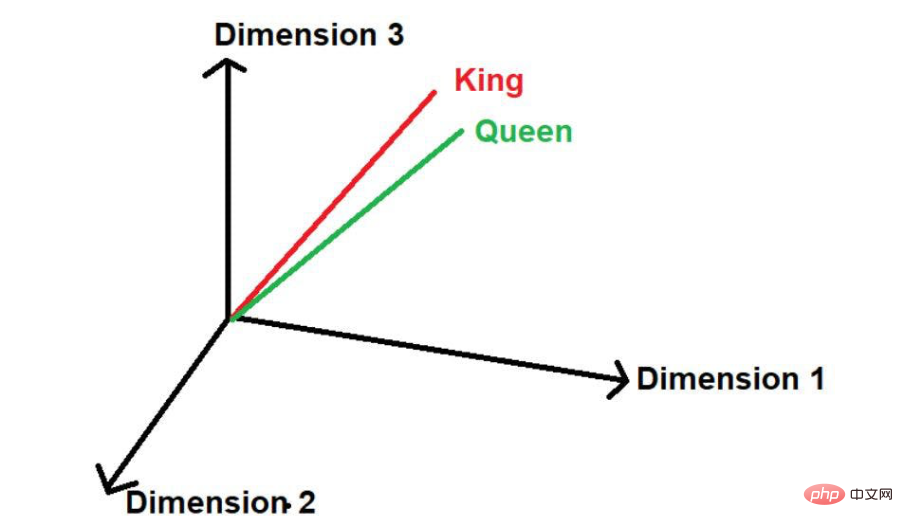
「道」という言葉がもう一つあると仮定して、論理的に言うと、この大規模なテキスト コーパスでは、「king」や「queen」ほど頻繁には現れません。したがって、この言葉は「キング」や「クイーン」から遠く離れた空間のどこか遠くに配置されることになります。
画像出典: 著者提供のイラスト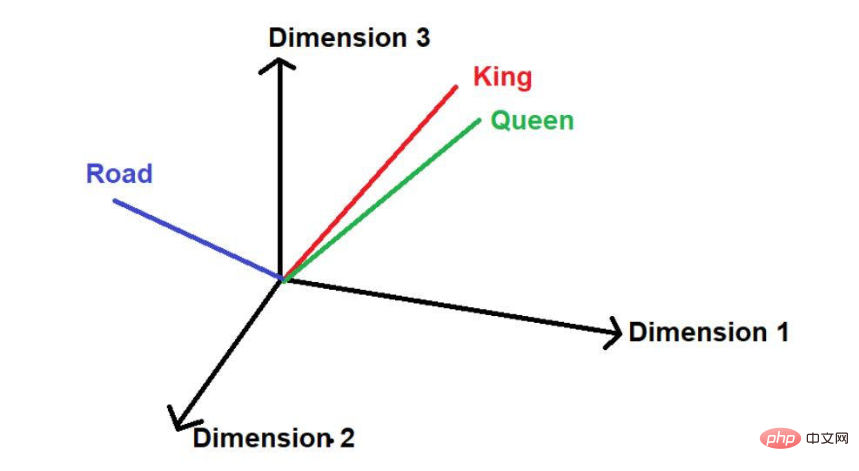 数学では、ベクトルは一連の数値で表され、各数値は単語のサイズを表します。特定の次元。例:ここでは
数学では、ベクトルは一連の数値で表され、各数値は単語のサイズを表します。特定の次元。例:ここでは
と入れていますので、「王」は 3 次元空間では [0.21, 0.45, 0.67] という形で表現されます。
「女王」という単語は、[0.24,0.41,0.62]と表すことができます。
「道路」という単語は、[0.97,0.72,0.36]と表現できます。
Transformer における位置埋め込みの必要性
導入セクションで説明したように、位置埋め込みの必要性は、ニューラル ネットワークが文内の順序と位置の依存関係を理解するためです。
たとえば、次の文を考えてみましょう:
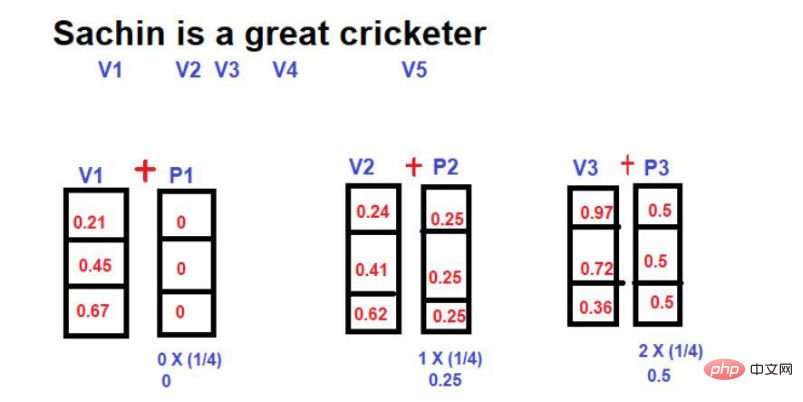
文 1--「サチン テンドゥルカールは今日 100 得点を記録できませんでしたが、彼はチームを勝利に導きました。」
文 2--「サチン テンドゥルカールは今日 100 得点を記録しましたが、チームを勝利に導くことができませんでした。」
この 2 つの文は、ほとんどの単語を共有しているため似ていますが、根底にある意味は大きく異なります。 「いいえ」のような単語の順序と配置により、メッセージが伝わる文脈が変わりました。
したがって、NLP プロジェクトでは、位置情報を理解することが非常に重要です。モデルが多次元空間で単純に数値を使用し、コンテキストを誤解すると、特に予測モデルにおいて深刻な結果を招く可能性があります。
この課題を克服するために、RNN (リカレント ニューラル ネットワーク) や LSTM (長期短期記憶) などのニューラル ネットワーク アーキテクチャが導入されました。これらのアーキテクチャは、位置情報を理解することにある程度成功しています。彼らの成功の主な秘密は、単語の順序を保って長文を学習することです。これに加えて、「注目の単語」に近い単語、「注目の単語」から遠い単語の情報も持っています。
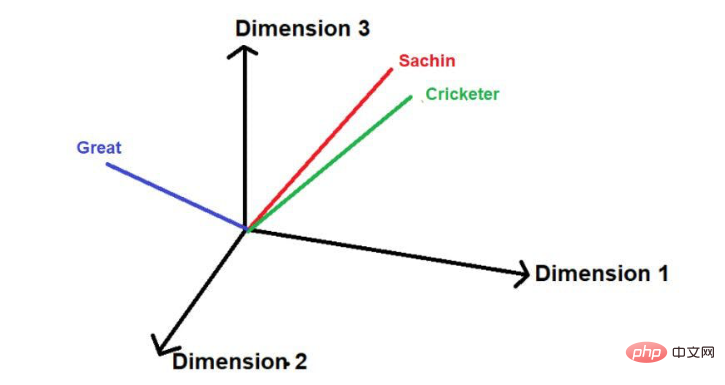
たとえば、次の文について考えてみましょう--
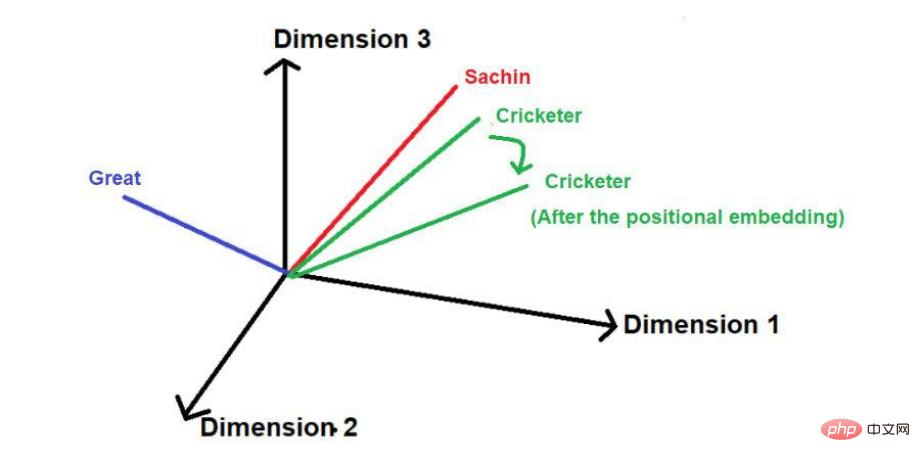
「サチンは史上最も偉大なクリケット選手です。」

画像出典:著者提供イラスト
赤下線部がこれです。ここでは、「注目の単語」が原文の順序でたどられていることがわかります。
さらに、覚えて学習することもできます

画像出典: 著者提供のイラスト
これらのテクニックを通じて、RNN / LSTM は、大規模なテキスト コーパス内の位置情報を理解できます。ただし、本当の問題は、大規模なテキスト コーパス内の単語を順次走査することです。 100 万語を含む非常に大きなテキスト コーパスがあり、各単語を順番に調べるには非常に長い時間がかかると想像してください。場合によっては、モデルのトレーニングにそれほど多くの計算時間を費やすことが現実的ではないことがあります。
この課題を克服するために、新しい高度なアーキテクチャである「Transformer」が導入されました。
Transformer アーキテクチャの重要な特徴は、すべての単語を並行して処理することでテキスト コーパスを学習できることです。テキスト コーパスに 10 単語が含まれているか、100 万単語が含まれているかは、Transformer アーキテクチャでは関係ありません。

 ##画像出典: 著者提供イラスト
##画像出典: 著者提供イラスト
次に、単語を並列処理するという課題に直面する必要があります。すべての単語が同時にアクセスされるため、単語間の依存関係に関する情報は失われます。したがって、モデルは特定の単語の関連情報を記憶できず、正確に保存できません。この疑問は、モデルの計算/トレーニング時間を大幅に短縮したにもかかわらず、コンテキストの依存関係を維持するという元の課題に再びつながります。
では、上記の問題を解決するにはどうすればよいでしょうか?解決策は、
継続的な試行錯誤です。
当初、この概念が導入されたとき、研究者は、Transformer 構造内の位置情報を保存できる最適化された方法を考え出すことに非常に熱心でした。試行錯誤実験の一環として、最初に試したアプローチは
でした。ここでのアイデアは、単語のインデックスを含む単語ベクトルを使用しながら、新しい数学的ベクトルを導入することです。
#画像ソース: 著者提供のイラスト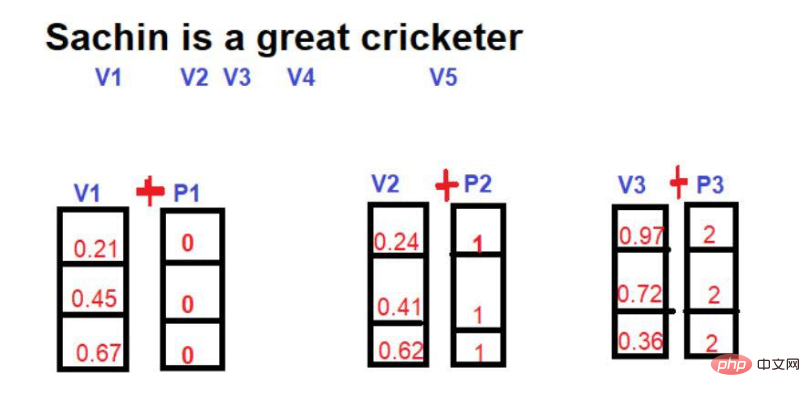
#画像出典: 著者提供のイラスト
 位置ベクトルを追加すると、そのサイズと方向により、以下に示すように各単語の位置が変化する場合があります。
位置ベクトルを追加すると、そのサイズと方向により、以下に示すように各単語の位置が変化する場合があります。
 この手法の欠点は、文が特に長い場合、位置ベクトルが比例して増加することです。文に 25 個の単語があるとします。最初の単語には大きさ 0 が追加された位置ベクトルが含まれ、最後の単語には大きさ 24 が追加された位置ベクトルが含まれます。この大きな不確実性は、これらの値を高次元に投影するときに問題を引き起こす可能性があります。
この手法の欠点は、文が特に長い場合、位置ベクトルが比例して増加することです。文に 25 個の単語があるとします。最初の単語には大きさ 0 が追加された位置ベクトルが含まれ、最後の単語には大きさ 24 が追加された位置ベクトルが含まれます。この大きな不確実性は、これらの値を高次元に投影するときに問題を引き起こす可能性があります。
位置ベクトルを削減するために使用される別の手法は、
です。ここでは、文の長さに対する各単語の小数値が位置ベクトルの大きさとして計算されます。
スコア値は、
Value=1/N-1
として計算されます。ここで、「N」は特定の単語の位置です。
たとえば、以下に示す例を考えてみましょう-
#画像出典: 著者提供のイラスト
この手法では、文の長さに関係なく、位置ベクトルの最大の大きさは 1 に制限できます。ただし、大きな抜け穴があります。長さの異なる 2 つの文を比較すると、特定の位置の単語の埋め込み値が異なります。特定の単語またはその対応する位置は、そのコンテキストの理解を容易にするために、テキスト コーパス全体で同じ埋め込み値を持つ必要があります。異なる文内の同じ単語が異なる埋め込み値を持つ場合、多次元空間でテキスト コーパスの情報を表現することは非常に複雑な作業になります。このような複雑な空間を実装したとしても、過剰な情報の歪みによりモデルはいつか崩壊する可能性が非常に高いです。したがって、この手法は Transformer の位置埋め込みの開発から除外されました。
最後に、研究者らは Transformer アーキテクチャを提案し、有名なホワイトペーパーで「必要なのは注意だけです」と述べました。
周波数ベースの位置埋め込み
この技術によれば、研究者らは次の式を使用した波の周波数ベースのテキスト埋め込み方法を推奨しています---
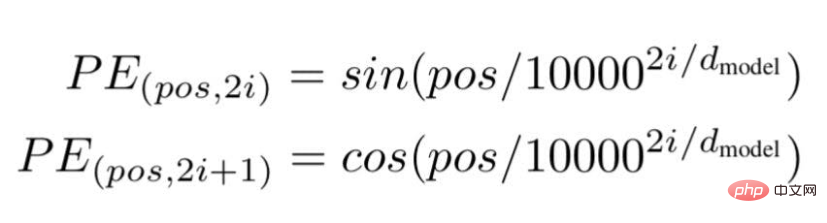
 #画像出典: 著者提供イラスト
#画像出典: 著者提供イラスト
##画像出典: 著者提供イラスト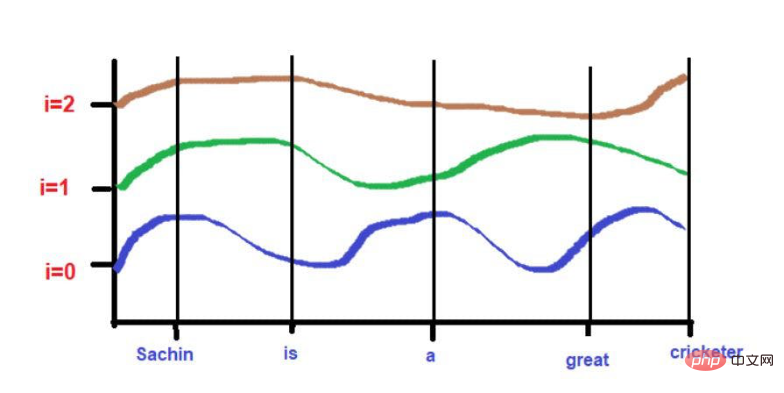
画像出典:作者提供イラスト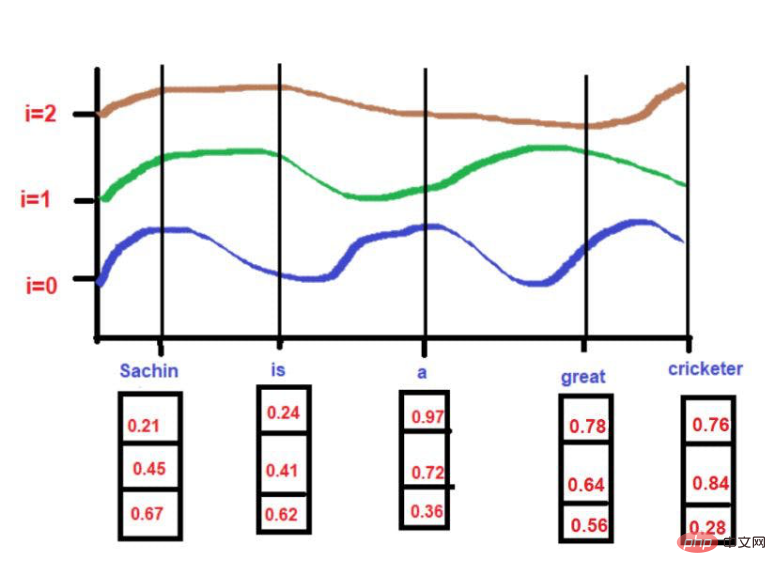
画像出典:著者提供イラスト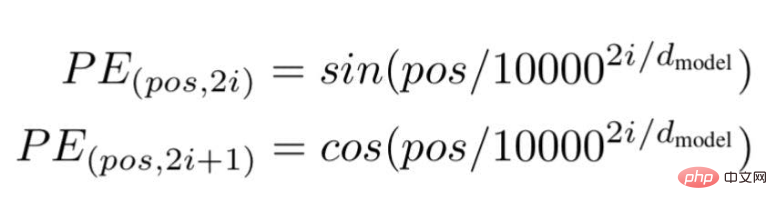
#PE(0,1) = cos(0)
PE(0,1) = 1
i =2の場合、
PE(0,2) = sin(0/10000^2(2)/3)
PE(0,2) = sin(0)
PE(0,2) = 0
for
pos = 3
d = 3
i[0] = 0.78、i[1] = 0.64、i[2] = 0.56
式を適用しながら。
画像出典:著者提供イラスト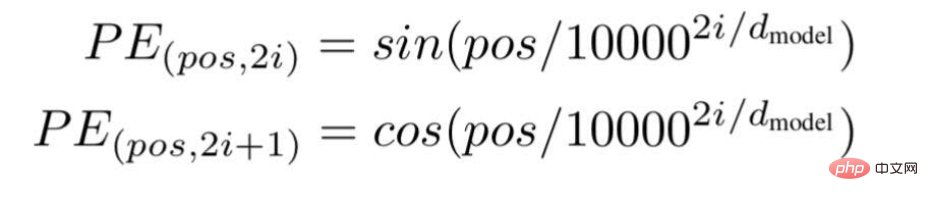 When i =0,
When i =0,
PE(3,0) = sin(3 / 10000^2(0)/3)
PE(3,0) = sin(3/1)
PE(3,0) = 0.05
の場合i =1,
PE(3,1) = cos(3/10000^2(1)/3)
PE(3,1) = cos(3/436)
PE(3,1) = 0.99
i =2 の場合、
PE(3,2) = sin(3/10000^2(2)/3)
PE(3,2) = sin(3/1.4)
PE(3,2) = 0.03
画像ソース: イラスト提供: 著者提供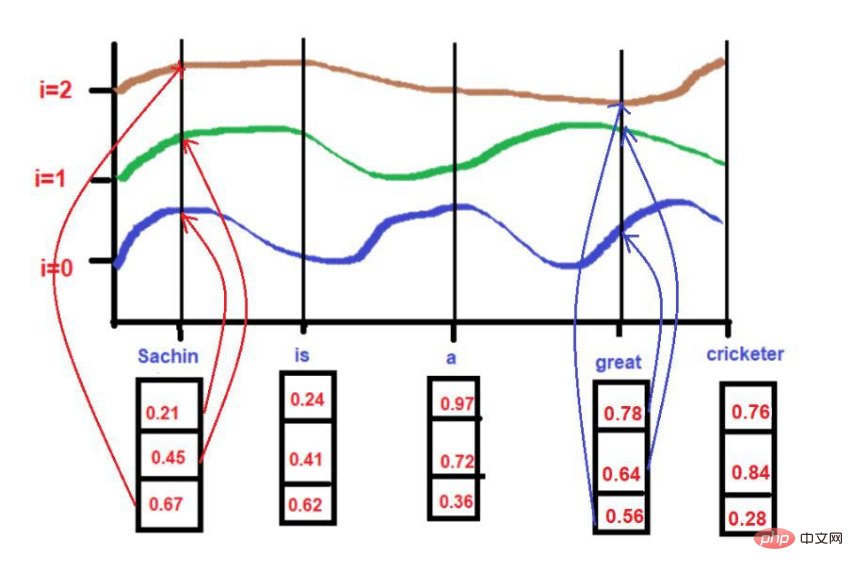 ここでは、最大値を 1 に制限します (sin/cos 関数を使用しているため)。したがって、以前の技術では、高振幅の位置ベクトルに関して問題はありません。
ここでは、最大値を 1 に制限します (sin/cos 関数を使用しているため)。したがって、以前の技術では、高振幅の位置ベクトルに関して問題はありません。
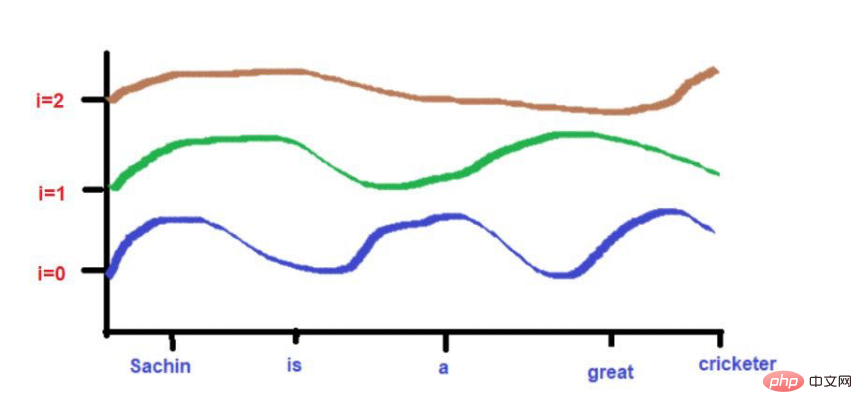
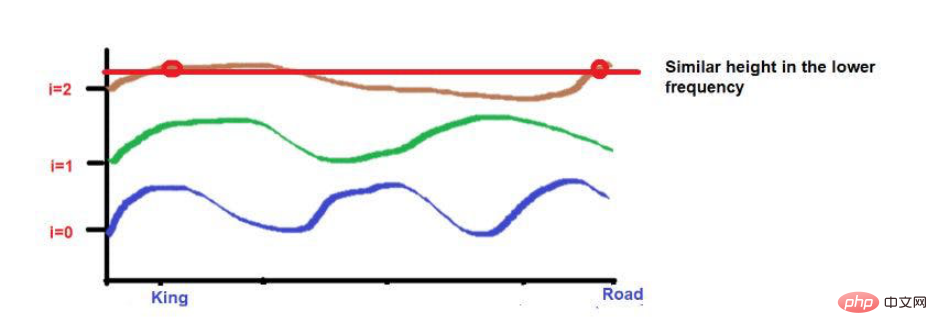
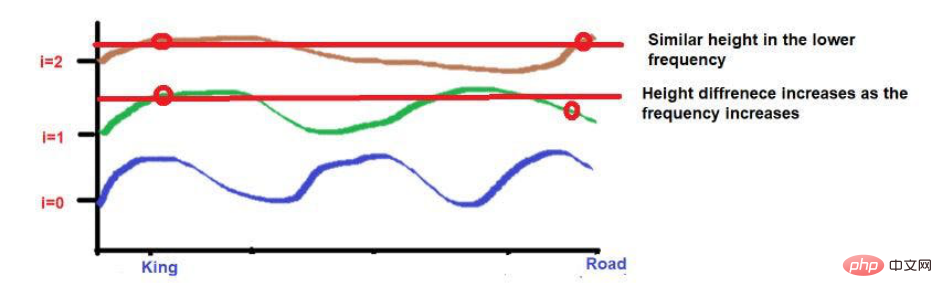
さらに、互いに非常に近い単語は、低頻度では同様の高さになりますが、高頻度では高さが少し異なります。
単語が互いに非常に近い場合、低い周波数でも単語の高さは大きく異なり、単語の高さの差は周波数とともに増加します。
たとえば、次の文について考えてみましょう。「王と王妃は道を歩いていました。」
「King」と「Road」の文字が遠くに配置されています。
波の周波数の公式を適用した後、2 つの単語の高さがほぼ同じになると考えてください。より高い周波数 (0 など) に近づくにつれて、それらの高さはさらに異なります。
 ##画像出典: 著者提供イラスト
##画像出典: 著者提供イラスト
 画像出典:著者提供イラスト
画像出典:著者提供イラスト
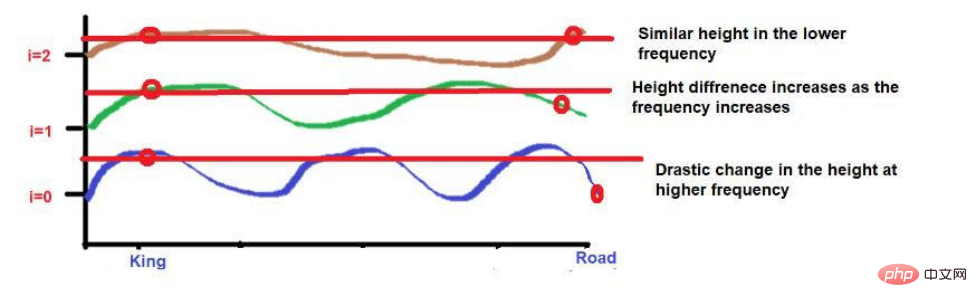
「King」と「Queen」の文字が近くに配置されています。
これら 2 つの単語は、より低い周波数で同様の高さに配置されます (ここでは 2 のように)。より高い周波数 (0 など) に近づくと、それらの高さの差が少し大きくなり、区別できるようになります。
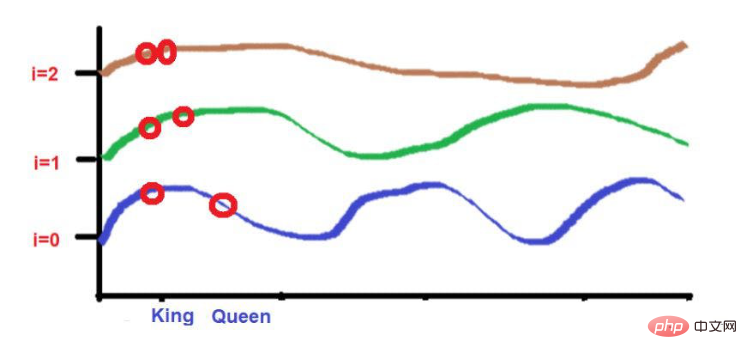 画像出典:イラスト提供:著者提供
画像出典:イラスト提供:著者提供
ただし、注意が必要なのは、これらの単語の近接性が低い場合、開発時に高周波に向かうにつれて、それらの高さは大きく異なります。単語が互いに非常に近い場合、より高い周波数に移動するにつれて、単語の高さの差はわずかになります。
概要
この記事を通じて、機械学習における位置埋め込みの背後にある複雑な数学的計算を直感的に理解していただければ幸いです。つまり、特定の目標を達成する必要性について話し合いました。
「自然言語処理」に興味のあるテクノロジー愛好家にとって、これらの内容は複雑なコンピューティング手法を理解するのに役立つと思います。さらに詳細な情報については、有名な研究論文「Attention is All You Need」を参照してください。
翻訳者紹介
Cui Hao は、51CTO コミュニティ編集者兼シニア アーキテクトであり、ソフトウェア開発とアーキテクチャに 18 年の経験と、分散アーキテクチャに 10 年の経験があります。
元のタイトル: 位置埋め込み: トランスフォーマー ニューラル ネットワークの精度の秘密 、著者: Sanjay Kumar
以上が「位置情報の埋め込み」: Transformer の秘密の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。