


arXiv 論文「ST-P3: 時空間特徴学習によるエンドツーエンドのビジョンベースの自動運転」、7 月 22 日、上海交通大学、上海 AI 研究所、カリフォルニア大学サンディエゴ校、JD の著者。 com 北京研究所。

ST-P3 と呼ばれる、知覚、予測、計画タスクのためのより代表的な特徴のセットを同時に提供できる時空間特徴学習スキームを提案します。具体的には、BEV 変換を感知する前に 3 次元空間に幾何学的情報を保持する自己中心的調整累積手法が提案されており、著者は、将来の予測のために過去の動きの変化が考慮されるように二重経路モデルを設計しています。計画された視覚要素の認識を補うために、洗練ユニットが導入されました。ソース コード、モデル、プロトコルの詳細はオープン ソースhttps://github.com/OpenPerceptionX/ST-P3.
先駆的な LSS 手法は、マルチビュー カメラから遠近感特徴を抽出し、深さ推定を通じてそれらを 3D に引き上げ、BEV 空間に融合します。 2 つのビュー間の特徴変換。潜在深度予測が重要です。
2 次元の平面情報を 3 次元にアップグレードするには、追加の次元、つまり 3 次元の幾何学的自動運転タスクに適した深さが必要です。ほとんどのシーンにはビデオ ソースが割り当てられているため、特徴表現をさらに改善するには、時間情報をフレームワークに組み込むのが自然です。
図で説明されているST- P3全体的なフレームワーク: 具体的には、周囲のカメラ ビデオのセットが与えられると、それらをバックボーンに入力して、予備的な正面図の特徴を生成します。補助的な深度推定を実行して、2D フィーチャを 3D 空間に変換します。自己中心位置合わせ累積スキームは、まず過去のフィーチャを現在のビュー座標系に位置合わせします。その後、現在および過去のフィーチャが 3 次元空間に集約され、BEV 表現に変換する前に幾何学的情報が保存されます。一般的に使用される prediction 時間領域モデルに加えて、過去の動きの変化を説明する 2 番目のパスを構築することで、パフォーマンスがさらに向上します。このデュアルパス モデリングにより、将来のセマンティックな結果を推測するためのより強力な特徴表現が保証されます。軌道 計画 という最終目標を達成するために、ネットワークの初期機能の事前知識が統合されます。改良モジュールは、HD マップがない場合でも高レベルのコマンドを使用して最終的な軌道を生成するように設計されました。

図は、知覚の自己中心的調整蓄積法を示しています。 (a) 深度推定を利用して現在のタイムスタンプの特徴を 3D に引き上げ、位置合わせ後に BEV 特徴にマージします; (b-c) 前のフレームの 3D 特徴を現在のフレーム ビューと位置合わせし、過去および現在のすべての状態と融合します。特徴表現を強化します。

図に示されているのは、prediction に使用される 2 方向モデルです。 (i) 潜在コードは特徴マップからの分布です。 (ii iii) ロード a には、将来のマルチモダリティを示す不確実性分布が組み込まれていますが、パス b は過去の変化から学習し、パス a の情報を補うのに役立ちます。

#最終的な目標として、目標点に到達するための安全で快適な軌道を計画する必要があります。このモーション プランナーは、さまざまな軌道のセットをサンプリングし、学習されたコスト関数を最小化する軌道を選択します。ただし、ターゲット ポイントや信号機からの情報をタイム ドメイン モデルを通じて統合すると、追加の最適化手順が追加されます。
この図は、計画のための事前知識の統合と改良を示しています。全体のコスト図には 2 つのサブコストが含まれています。カメラ入力からのビジョンベースの情報を集約する将来予測機能を使用して、最小コストの軌道がさらに再定義されます。

大きな横加速度、ジャーク、または曲率を伴う軌道にペナルティを与えます。この軌道が効率的に目的地に到達し、前進が報われることを願っています。ただし、上記のコスト項目には、通常ルートマップで提供されるターゲット情報は含まれません。前進、左折、右折などの高レベルのコマンドを使用し、対応するコマンドのみに基づいて軌道を評価します。
さらに、SDV にとって信号機は、GRU ネットワークを通じて軌道を最適化するために不可欠です。隠れ状態はエンコーダ モジュールのフロント カメラ機能で初期化され、コスト項の各サンプル ポイントが入力として使用されます。
実験結果は次のとおりです:




 #
#
以上がST-P3: 自動運転のためのエンドツーエンドの時空間特徴学習ビジョン手法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AM
オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AMOpenaiは、強力なGPT-4.1シリーズを発表しました。実際のアプリケーション向けに設計された3つの高度な言語モデルのファミリー。 この大幅な飛躍は、より速い応答時間、理解の強化、およびTと比較した大幅に削減されたコストを提供します
 LLMベンチマークとは何ですか?Apr 26, 2025 am 10:13 AM
LLMベンチマークとは何ですか?Apr 26, 2025 am 10:13 AM大規模な言語モデル(LLM)は最新のAIアプリケーションに不可欠になっていますが、その機能を評価することは依然として課題です。従来のベンチマークは長い間LLMパフォーマンスを測定するための標準でしたが、RAでは
 7タスクGemini 2.5 Proは他のどのチャットボットよりも優れています!Apr 26, 2025 am 10:00 AM
7タスクGemini 2.5 Proは他のどのチャットボットよりも優れています!Apr 26, 2025 am 10:00 AMAIチャットボットはより賢くなり、その日までにますます洗練されています。 Google Deepmindの最新の実験モデルであるGemini 2.5 Proは、AIチャットボット機能における大きな前進を表しています。 Contexが改善されています
 6 O3プロンプト今日試してみる必要があります-AnalyticsVidhyaApr 26, 2025 am 09:56 AM
6 O3プロンプト今日試してみる必要があります-AnalyticsVidhyaApr 26, 2025 am 09:56 AMOpenaiのO3:推論とマルチモーダル機能における前進 OpenaiのO3モデルは、AI推論能力の大きな進歩を表しています。複雑な問題解決、分析タスク、および自律的なツールの使用のために設計されたO3
 Canva Codeを試しましたが、ここでそれがどのように進んだかを試しました。Apr 26, 2025 am 09:53 AM
Canva Codeを試しましたが、ここでそれがどのように進んだかを試しました。Apr 26, 2025 am 09:53 AMCanva Create2025:Canva CodeとAIを使用してデザインを革新する CanvaのCreate 2025イベントは、AIを搭載したツール、エンタープライズソリューション、特に開発者ツールにプラットフォームを拡大し、重要な進歩を発表しました。 キーアップデートにはentが含まれています
 タスク用のAIチャットボット:AIエージェントがどのように静かにアプリを交換しているかApr 26, 2025 am 09:50 AM
タスク用のAIチャットボット:AIエージェントがどのように静かにアプリを交換しているかApr 26, 2025 am 09:50 AM簡単なタスクのためのApp-Hoppingの時代は終わりです。 1回の会話で休暇を予約したり、請求書を自動的に交渉したりすることを想像してください。 これはAIエージェントの力です - あなたのニーズを予測する新しいデジタルアシスタント、JUSではなく
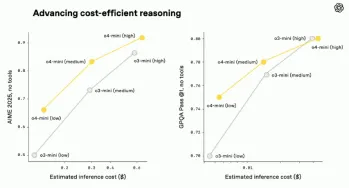 O3およびO4-MINI:Openaiの最も高度な推論モデルApr 26, 2025 am 09:46 AM
O3およびO4-MINI:Openaiの最も高度な推論モデルApr 26, 2025 am 09:46 AMOpenaiの画期的なO3およびO4-MINI推論モデル:AGIへの巨大な飛躍 GPT 4.1ファミリーの打ち上げのかかとで、Openaiは、AIであるO3およびO4-MINI推論モデルでの最新の進歩を発表しました。 これらは単なるAIモデルではありません。
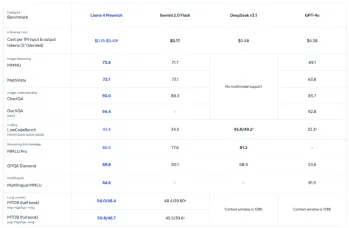 Llama 4とAutogenでAIエージェントを構築しますApr 26, 2025 am 09:44 AM
Llama 4とAutogenでAIエージェントを構築しますApr 26, 2025 am 09:44 AMインテリジェントAIエージェントを構築するためにLlama 4とオートゲンの力を活用する MetaのLlama 4ファミリのモデルはAIの景観を変換しており、インテリジェントなシステム開発に革命をもたらすためにネイティブのマルチモーダル機能を提供しています。 この記事の探検


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

メモ帳++7.3.1
使いやすく無料のコードエディター
ホットトピック
 7723
7723 15164314139652129025123329
15164314139652129025123329