



翻訳者|Li Rui
レビュアー|Sun Shujuan
BigScience 研究プロジェクトは最近、大規模言語モデル BLOOM をリリースしました。一見すると OpenAI のコピーのように見えますが、別の試みですGPT-3で。
しかし、BLOOM が他の大規模自然言語モデル (LLM) と異なる点は、機械学習モデルの研究、開発、トレーニング、公開における取り組みです。
近年、大手テクノロジー企業は大規模な自然言語モデル (LLM) を厳格な企業秘密のように隠してきましたが、BigScience チームはプロジェクトの当初から透明性とオープン性を BLOOM の中心に据えてきました。
結果として、研究や学習にすぐに使用でき、誰でも利用できる大規模な言語モデルが得られます。 BLOOM によって確立されたオープンソースとオープンコラボレーションの例は、大規模自然言語モデル (LLM) や人工知能の他の分野における将来の研究に非常に有益です。しかし、大規模な言語モデルに固有の、対処する必要のある課題がまだいくつかあります。
BLOOMとは

BLOOMとは「BigScience Large-Scale Open Science Open Access Multilingual Model」の略称です。データの観点からは、GPT-3 や OPT-175B と大きな違いはありません。これは、自然言語やソフトウェア ソース コードを含む 1.6 TB のデータを使用してトレーニングされた、1,760 億個のパラメーターを備えた非常に大規模な Transformer モデルです。
GPT-3 と同様に、テキスト生成、要約、質問応答、プログラミングなど、ゼロショットまたは数ショット学習を通じて多くのタスクを実行できます。
しかし、BLOOM の重要性は、その背後にある組織と構築プロセスにあります。
BigScienceは、機械学習モデルセンター「Hugging Face」が2021年に開始した研究プロジェクトです。ウェブサイトによると、このプロジェクトは「AI/NLP 研究コミュニティ内で大規模な言語モデルと大規模な研究成果物を作成、学習、共有するための代替方法を実証することを目的としています。」
この点で、ビッグサイエンスはインスピレーションを得ています。これは、CERN や大型ハドロン衝突型加速器 (LHC) などの科学創造イニシアチブからのものであり、そこではオープンな科学コラボレーションが創造の研究コミュニティ全体に役立つ大規模な成果物を推進しています。
2021 年 5 月からのこの 1 年間で、60 か国、250 以上の機関からの 1,000 人以上の研究者が BigScience で BLOOM を共同開発しました。
透明性、オープン性、包括性
ほとんどの主要な大規模自然言語モデル (LLM) は英語のテキストのみでトレーニングされますが、BLOOM のトレーニング コーパスには 46 の自然言語と 13 のプログラミング言語が含まれています。これは、主言語が英語ではない多くの地域で役立ちます。
BLOOM はまた、大手テクノロジー トレーニング会社のモデルへの実際の依存を打ち破ります。大規模な自然言語モデル (LLM) の主な問題の 1 つは、トレーニングとチューニングのコストが高いことです。この障壁により、1,000 億のパラメータを持つ大規模な自然言語モデル (LLM) は、豊富な資金を持つ大手テクノロジー企業の独占的な領域となっています。近年、人工知能研究所は、助成金付きのクラウド コンピューティング リソースを獲得し、研究に資金を提供するために、大手テクノロジー企業からの誘致を受けてきました。
対照的に、BigScience 研究チームは、スーパーコンピューター Jean Zay 上で BLOOM をトレーニングするために、フランス国立科学研究センターから 300 万ユーロの助成金を受けました。このテクノロジーの独占的ライセンスを営利企業に与える契約はなく、モデルを商業化して収益性の高い製品に変えるという約束もありません。
さらに、BigScience チームは、モデル トレーニング プロセス全体について完全に透明性を保っています。データセット、会議記録、ディスカッション、コードに加えて、トレーニング モデルのログや技術的な詳細も公開しています。
研究者たちはモデルのデータとメタデータを研究し、興味深い発見を発表しています。
たとえば、研究者の David McClure 氏は 2022 年 7 月 12 日にツイートしました、「私は Bigscience と Hugging Face の本当にクールな BLOOM モデルの背後にあるトレーニング データセットを調べてきました。英語コーパスには 1,000 万のサンプルがあります」 、全体の約 1.25%、「all-distilroberta-v1」でエンコードされ、その後 UMAP で 2D に変換されます。」
もちろん、トレーニングされたモデル自体は Hugging Face のプラットフォームで使用できるため、研究者は次のような作業から解放されます。トレーニングに何百万ドルも費やす苦痛。
Facebook は先月、一部の制限の下で大規模自然言語モデル (LLM) の 1 つをオープンソース化しました。しかし、BLOOM によってもたらされる透明性は前例のないものであり、業界に新たな標準を確立することが約束されています。
BLOOM トレーニング共同リーダーの Teven LeScao 氏は、「産業用 AI 研究ラボの秘密主義とは対照的に、BLOOM は最も強力な AI モデルがより広範な研究コミュニティによって責任を持ってオープンに開発できることを実証しています。
課題は残る
人工知能研究と大規模言語モデルにオープン性と透明性をもたらす BigScience の取り組みは賞賛に値しますが、この分野には固有の課題があります。
大規模自然言語モデル (LLM) 研究はますます大規模なモデルに移行しており、トレーニングとランニングのコストはさらに増加します。 BLOOM は、トレーニングに 384 個の Nvidia Tesla A100 GPU (価格はそれぞれ約 32,000 ドル) を使用します。また、モデルが大きくなると、より大きなコンピューティング クラスターが必要になります。 BigScience チームは、他のオープンソースの大規模自然言語モデル (LLM) の作成を継続すると発表しましたが、チームがますます高価になる研究にどのように資金を提供するのかはまだ不明です。たとえば、OpenAI は非営利組織としてスタートしましたが、後に Microsoft からの資金に依存して製品を販売する営利組織になりました。
解決すべきもう 1 つの問題は、これらのモデルの実行にかかる莫大なコストです。圧縮された BLOOM モデルのサイズは 227 GB で、これを実行するには数百 GB のメモリを備えた特殊なハードウェアが必要です。比較のために、GPT-3 には Nvidia DGX 2 と同等のコンピューティング クラスターが必要で、そのコストは約 40 万ドルです。 Hugging Face は、研究者が 1 時間あたり約 40 ドルでモデルを使用できる API プラットフォームを立ち上げる予定ですが、これはかなりのコストです。
BLOOM の実行コストは、応用機械学習コミュニティ、スタートアップ企業、大規模な自然言語モデル (LLM) を活用した製品の構築を検討している組織にも影響を与えます。現在、OpenAI が提供する GPT-3 API の方が製品開発に適しています。開発者が貴重な研究に基づいて製品を構築できるようにするために、BigScience と Hugging Face がどのような方向に進むのかを見るのは興味深いでしょう。
これに関して、BigScience が将来のリリースでそのモデルのより小さなバージョンを用意することが期待されています。メディアでよく描かれている内容とは異なり、大規模自然言語モデル (LLM) は依然として「フリーランチなし」の原則を遵守しています。これは、機械学習を適用する場合、多くのタスクで平均的なパフォーマンスを発揮する非常に大規模なモデルよりも、特定のタスクに合わせて微調整されたよりコンパクトなモデルの方が効果的であることを意味します。たとえば、Codex は GPT-3 の修正バージョンであり、GPT-3 の数分の 1 のサイズとコストでプログラミングに優れた支援を提供します。 GitHub は現在、Codex ベースの製品 Copilot を月額 10 ドルで提供しています。
BLOOM が新しい文化を確立したいと考えているため、学術的および応用 AI が将来どこに向かうのかを調べるのは興味深いでしょう。
原題: BLOOM は AI 研究に新しい文化を築くことができますが、課題はまだ残っています 、著者:ベン・ディクソン
以上がBLOOM は AI 研究の新しい文化を生み出すことができますが、課題はまだ残っていますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 10 GPT-4Oの画像生成が今日試してみるようにプロンプトします!Apr 24, 2025 am 10:26 AM
10 GPT-4Oの画像生成が今日試してみるようにプロンプトします!Apr 24, 2025 am 10:26 AMAIの世界では絶対に野生のものが起こっています。 Openaiのネイティブイメージの生成は今、非常識です。私たちは顎を落とすビジュアル、恐ろしい良いディテール、そして洗練された出力について話しています。
 Windsurfを使用したバイブコーディングのガイドApr 24, 2025 am 10:25 AM
Windsurfを使用したバイブコーディングのガイドApr 24, 2025 am 10:25 AMAIを搭載したコーディングコンパニオンであるCodeiumのWindsurfで、コーディングのビジョンを楽に命を吹き込みます。 Windsurfは、コーディングやデバッグから最適化まで、ソフトウェア開発ライフサイクル全体を合理化し、プロセスをINTUに変換します
 RMGB V2.0を使用した画像のバックグラウンド削除の調査Apr 24, 2025 am 10:20 AM
RMGB V2.0を使用した画像のバックグラウンド削除の調査Apr 24, 2025 am 10:20 AMBraiaiのRMGB V2.0:強力なオープンソースバックグラウンド除去モデル 画像セグメンテーションモデルはさまざまな分野に革命をもたらし、バックグラウンドの削除が進歩の重要な分野です。 BraiaiのRMGB V2.0は、最先端のオープンソースmとして際立っています
 大規模な言語モデルでの毒性の評価Apr 24, 2025 am 10:14 AM
大規模な言語モデルでの毒性の評価Apr 24, 2025 am 10:14 AMこの記事では、大規模な言語モデル(LLM)における毒性の重要な問題と、それを評価して軽減するために使用される方法について説明します。 LLMSは、チャットボットからコンテンツ生成までさまざまなアプリケーションを電力を供給し、堅牢な評価メトリック、ウィットを必要とします
 RagのRerankerに関する包括的なガイドApr 24, 2025 am 10:10 AM
RagのRerankerに関する包括的なガイドApr 24, 2025 am 10:10 AM検索拡張生成(RAG)システムは情報アクセスを変換していますが、その有効性は取得データの品質にかかっています。 これは、再審査員が重要になる場所です。
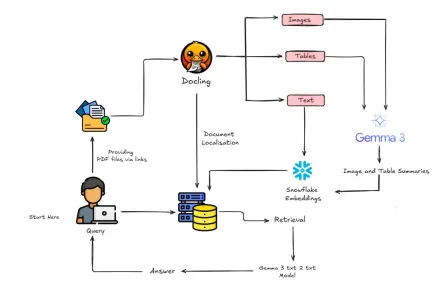 Gemma 3とDoclingでマルチモーダルラグを構築する方法は?Apr 24, 2025 am 10:04 AM
Gemma 3とDoclingでマルチモーダルラグを構築する方法は?Apr 24, 2025 am 10:04 AMこのチュートリアルでは、Google Colab内に洗練されたマルチモーダル検索の高性化(RAG)パイプラインを構築することを紹介します。 Gemma 3(言語とビジョンのため)、Docling(Document Conversion)、Langchainなどの最先端のツールを利用します
 スケーラブルなAIおよび機械学習アプリケーションのためのRayへのガイドApr 24, 2025 am 10:01 AM
スケーラブルなAIおよび機械学習アプリケーションのためのRayへのガイドApr 24, 2025 am 10:01 AMレイ:AIおよびPythonアプリケーションをスケーリングするための強力なフレームワーク Rayは、AIおよびPythonアプリケーションを簡単にスケーリングするように設計された革新的なオープンソースフレームワークです。 その直感的なAPIを使用すると、研究者と開発者がコードを移行することができます
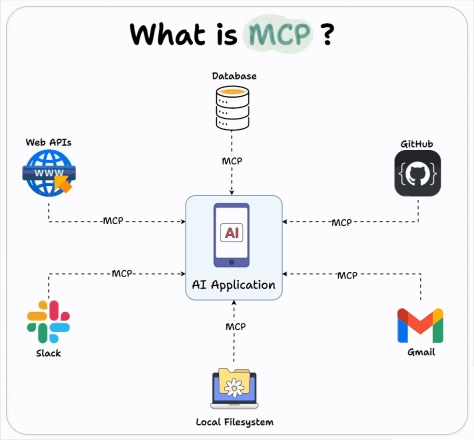 建築エージェントにOpenai MCP統合を使用する方法は?Apr 24, 2025 am 09:58 AM
建築エージェントにOpenai MCP統合を使用する方法は?Apr 24, 2025 am 09:58 AMOpenAIは、人類のモデルコンテキストプロトコル(MCP)をサポートすることにより、相互運用性を採用しています。これは、多様なデータシステムとのAIアシスタント統合を簡素化するオープンソース標準である。このコラボレーションは、AIアプリケーションのEFFへの統一されたフレームワークを促進します


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SublimeText3 中国語版
中国語版、とても使いやすい

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

WebStorm Mac版
便利なJavaScript開発ツール

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

