


arXiv 論文「深層強化学習を使用した現実世界の自動運転への取り組み」、2022 年 7 月 5 日にアップロードされました。著者はイタリアのパルマ大学の Vislab および Ambarella (Vislab の買収) の出身です。

典型的な自動運転組立ラインでは、制御システムは 2 つの最も重要なコンポーネントを表し、センサーによって取得されたデータと認識アルゴリズムによって処理されたデータが安全性を実現するために使用されます。快適な自動運転動作。特に、計画モジュールは、適切な高レベルのアクションを実行するために自動運転車がたどるべき経路を予測し、制御システムはステアリング、スロットル、ブレーキを制御する一連の低レベルのアクションを実行します。
この研究では、モデルフリーの 深層強化学習 (DRL) プランナーを提案し、ニューラル ネットワークをトレーニングして加速度およびステアリング角度を予測し、それによって車の位置およびステアリング角度によって駆動される自律的なデータを取得します。認識アルゴリズムは、車両の個々のモジュールによって駆動されるデータを出力します。特に、完全にシミュレーションおよびトレーニングされたシステムは、シミュレーション環境および現実 (パルマ市エリア) のバリアフリー環境でスムーズかつ安全に走行でき、システムが優れた汎用化機能を備えており、トレーニング シナリオ以外の環境でも走行できることが証明されています。さらに、システムを実際の自動運転車に導入し、シミュレーションされたパフォーマンスと実際のパフォーマンスとのギャップを減らすために、著者らは、シミュレーショントレーニング中に実際の環境の動作を再現できる小型ニューラルネットワークで表されるモジュールも開発しました。 . 車の動的挙動。
過去数十年にわたり、シンプルなルールベースのアプローチから AI ベースのインテリジェント システムの実装に至るまで、車両自動化のレベル向上において大きな進歩が見られました。特に、これらのシステムは、ルールベースのアプローチの主な制限、つまり他の道路利用者との交渉や対話の欠如、およびシーンのダイナミクスの理解が不十分であることに対処することを目的としています。
強化学習 (RL) は、囲碁、Atari ゲーム、チェスなどの離散制御空間の出力を使用するタスクや、連続制御空間での自動運転を解決するために広く使用されています。特に、RL アルゴリズムは、自動運転の分野で、アクティブな車線変更、車線維持、追い越し操作、交差点、環状交差点の処理などの意思決定および操作実行システムを開発するために広く使用されています。
この記事では、いわゆる Actor-Critics アルゴリズム ファミリに属する D-A3C の遅延バージョンを使用します。具体的には、俳優と批評家の 2 つの異なるエンティティで構成されます。アクターの目的は、エージェントが実行する必要があるアクションを選択することですが、クリティックは状態値関数、つまりエージェントの特定の状態がどの程度良好であるかを推定することです。言い換えると、アクターはアクション全体の確率分布 π(a|s; θπ) (θ はネットワーク パラメーター) であり、クリティカルは推定状態値関数 v(st; θv) = E(Rt|st) であり、R は期待される収益。
社内で開発された高精細マップはシミュレーション シミュレーターを実装しており、そのシーンの例を図 a に示します。これは実際の自動運転車テスト システムの一部のマップ領域であり、図 B は実際の自動運転車テスト システムの一部のマップ領域です。エージェントが認識する周囲の景色を示します。50 × 50 メートルのエリアに対応し、障害物 (図 c)、走行可能スペース (図 d)、エージェントがたどるべき経路 (図e) と停止線 (図 f)。シミュレーターの高解像度地図では、位置や車線数、道路制限速度など、外部環境に関する複数の情報を取得できます。
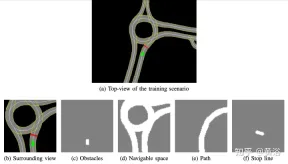
スムーズで安全な運転スタイルの実現に重点を置くことで、エージェントは静的シナリオでトレーニングされ、障害物や他の道路利用者を排除し、ルートに従い、制限速度を遵守することを学習します。
図に示すようにニューラル ネットワークを使用してエージェントをトレーニングし、100 ミリ秒ごとのステアリング角度と加速度を予測します。これは 2 つのサブモジュールに分割されています。最初のサブモジュールはステアリング角 sa を定義でき、2 番目のサブモジュールは加速度 acc を定義するために使用されます。これら 2 つのサブモジュールへの入力は、エージェントの周囲のビューに対応する 4 つのチャネル (走行可能スペース、経路、障害物、停止線) で表されます。各視覚入力チャネルには、エージェントに過去の状態の履歴を提供する 4 つの 84 × 84 ピクセル画像が含まれています。この視覚入力とともに、ネットワークは、目標速度 (道路制限速度)、エージェントの現在速度、現在の速度と目標速度の比、ステアリング角度と加速度に関連する最終アクションを含む 5 つのスカラー パラメーターを受け取ります。
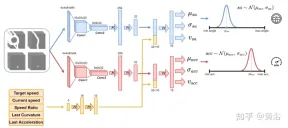
探索を確実にするために、2 つのガウス分布を使用して 2 つのサブモジュールの出力をサンプリングし、相対加速度 (acc=N (μacc, σacc)) を取得します。 ) とステアリング角度 (sa=N(μsa,σsa))。標準偏差 σacc と σsa は、トレーニング段階でニューラル ネットワークによって予測および調整され、モデルの不確実性が推定されます。さらに、ネットワークは、それぞれ加速度およびステアリング角度に関連する 2 つの異なる報酬関数 R-acc-t および R-sa-t を使用して、対応する状態値推定値 (vacc および vsa) を生成します。
ニューラル ネットワークは、パルマ市の 4 つのシーンでトレーニングされました。シナリオごとに複数のインスタンスが作成され、エージェントはこれらのインスタンス上で互いに独立しています。各エージェントは、ステアリング角 [-0.2, 0.2] と加速度 [-2.0 m, 2.0 m] の運動学的自転車モデルに従います。セグメントの開始時に、各エージェントはランダムな速度 ([0.0, 8.0]) で運転を開始し、道路制限速度を遵守して意図した経路をたどります。この市街地の道路制限速度は 4 ミリ秒から 8.3 ミリ秒です。
最後に、トレーニング シーンには障害物がないため、クリップは次のいずれかの最終状態で終了する可能性があります:
- 目標の達成:インテリジェンスは最終目標位置に到達します。
- 道路外運転: エージェントが意図した経路を逸脱し、ステアリング角度を誤って予測します。
- 時間切れ: フラグメントを完了する時間が経過しました。これは主に、道路制限速度未満で走行中の加速出力を慎重に予測したためです。
シミュレーション環境と実際の環境で車をうまく運転できる戦略を取得するには、望ましい動作を達成するために報酬の形成が重要です。特に、2 つの異なる報酬関数が 2 つのアクションをそれぞれ評価するために定義されています。R-acc-t と R-sa-t はそれぞれ加速度およびステアリング角度に関連しており、次のように定義されます:
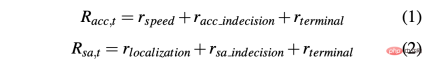
where
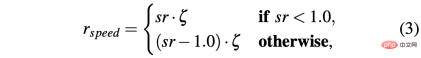
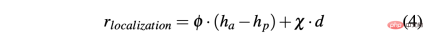
R-sa-t と R-acc-t の両方に、ペナルティの式に要素があります。加速度および操舵角の差がそれぞれ特定のしきい値 δacc および δsa より大きい 2 つの連続したアクション。特に、2 つの連続する加速度の差は次のように計算されます: Δacc=| acc (t) − acc (t− 1) | 、一方、rac_indecion は次のように定義されます:
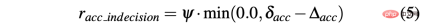
対照的に、ステアリング角の 2 つの連続した予測間の差は、Δsa=| sa(t) − sa(t− 1)| として計算され、一方、rsa_indecion は次のように定義されます:
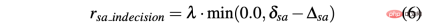
最後に、R-acc-t と R-sa-t は、エージェントが達成した最終状態に依存します。
- 目標達成: エージェントが目標位置に到達したため、2 つの報酬が得られます。 rterminal は 1.0 に設定されています;
- DRIVE OFF ROAD: エージェントは、主にステアリング角度の不正確な予測が原因で、その経路から逸脱します。したがって、負の信号 -1.0 を Rsa,t に割り当て、負の信号 0.0 を R-acc-t に割り当てます。
- Time is up: 主にエージェントの加速予測が原因で、セグメントを完了するために使用できる時間が期限切れになります。あまりにも注意してください; したがって、rterminal は R-acc-t に -1.0、R-sa-t に 0.0 を仮定します。
シミュレータに関連する主な問題の 1 つは、シミュレートされたデータと実際のデータの違いです。これは、シミュレータ内で現実世界の条件を正確に再現することが難しいために発生します。この問題を解決するには、合成シミュレーターを使用してニューラル ネットワークへの入力を簡素化し、シミュレートされたデータと実際のデータの間のギャップを減らします。実際、ニューラル ネットワークへの入力として 4 つのチャネル (障害物、走行空間、経路、停止線) に含まれる情報は、実際の自動運転車に埋め込まれた知覚および位置特定アルゴリズムと高解像度マップによって簡単に再現できます。
さらに、シミュレーターの使用に関連するもう 1 つの問題は、シミュレートされたエージェントがターゲット アクションを実行する方法と自動運転車がコマンドを実行する 2 つの方法の違いに関係しています。実際、時間 t で計算されたターゲット アクションは、理想的には、シミュレーション内の正確な瞬間に即座に有効になります。違いは、これが実際の車両では起こらないことです。現実には、そのようなターゲット アクションは何らかのダイナミクスを伴って実行され、実行遅延 (t δ) が生じるからです。したがって、そのような遅延に対処するために実際の自動運転車でエージェントを訓練するには、シミュレーションにそのような応答時間を導入する必要があります。
この目的を達成するために、より現実的な動作を実現するために、エージェントはまず、エージェントが実行する必要があるターゲット アクションを予測したニューラル ネットワークにローパス フィルターを追加するようにトレーニングされます。図に示すように、青い曲線は、ターゲット アクション (この例ではステアリング角度) を使用したシミュレーションで発生する理想的な瞬間応答時間を表しています。次に、ローパス フィルターを導入した後、緑色の曲線はシミュレートされたエージェントの応答時間を示します。対照的に、オレンジ色の曲線は、同じステアリング操作を実行する自動運転車の動作を示しています。ただし、この図から、シミュレートされた車両と実際の車両の間の応答時間の違いが依然として関係していることがわかります。
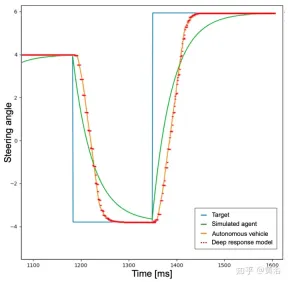
実際には、ニューラル ネットワークによって事前に設定された加速度およびステアリング角度のポイントは実行可能なコマンドではなく、システムの慣性、アクチュエーターの遅延、その他の非理想的な要因などのいくつかの要因が考慮されていません。そこで、実際の車両のダイナミクスをできるだけリアルに再現するために、全結合 3 層(ディープレスポンス)からなる小規模なニューラルネットワークで構成されるモデルを開発しました。深度応答挙動のグラフは、上の図の赤い破線で示されており、実際の自動運転車を表すオレンジ色の曲線に非常に似ていることがわかります。トレーニング シーンに障害物や交通車両がないことを考えると、説明した問題はステアリング角度アクティビティでより顕著になりますが、同じ考え方が加速出力にも適用されます。
自動運転車で収集されたデータセットを使用してディープ レスポンス モデルをトレーニングします。入力は人間のドライバーが車両に与えるコマンド (アクセル圧力とステアリング ホイールの回転) に対応し、出力は以下に対応します。車両のスロットル、ブレーキ、曲がりは、GPS、走行距離計、またはその他のテクノロジーを使用して測定できます。このように、そのようなモデルをシミュレーターに埋め込むと、自動運転車の動作を再現する、よりスケーラブルなシステムが実現します。したがって、深さ応答モジュールはステアリング角の修正に不可欠ですが、あまり目立たない形であっても加速のために必要であり、これは障害物の導入により明確に認識されます。
システムに対するディープ レスポンス モデルの影響を検証するために、2 つの異なる戦略が実際のデータでテストされました。次に、車両が経路を正しくたどっており、HD マップから得られた制限速度を遵守していることを確認します。最後に、模倣学習を通じてニューラル ネットワークを事前トレーニングすると、総トレーニング時間を大幅に短縮できることが証明されました。
戦略は次のとおりです。
- 戦略 1: トレーニングに深い応答モデルを使用せず、ローパス フィルターを使用して実際の車両の応答をシミュレートします。ターゲットのアクション。
- 戦略 2: トレーニングに深い応答モデルを導入することで、より現実的なダイナミクスを確保します。
シミュレーションで実行されたテストでは、両方の戦略で良好な結果が得られました。実際、トレーニングされたシーンでも、トレーニングされていないマップ エリアでも、エージェントは 100% の確率でスムーズかつ安全な動作で目標を達成できます。
実際のシナリオで戦略をテストすると、異なる結果が得られました。戦略 1 は車両のダイナミクスを処理できず、シミュレーション内のエージェントとは異なる方法で予測されたアクションを実行します。このようにして、戦略 1 は予測の予期せぬ状態を観察し、自動運転車での騒々しい動作や不快な動作につながります。
この動作はシステムの信頼性にも影響し、実際、自動運転車が道路から逸脱するのを避けるために人間の支援が必要になる場合があります。
対照的に、戦略 2 では、自動運転車の実世界のすべてのテストにおいて、車両のダイナミクスとシステムが動作を予測するためにどのように進化するかを把握している人間が引き継ぐ必要はありません。人間の介入が必要な唯一の状況は、他の道路利用者を避けることですが、戦略 1 と 2 の両方がバリアフリー シナリオで訓練されているため、これらの状況は失敗とはみなされません。
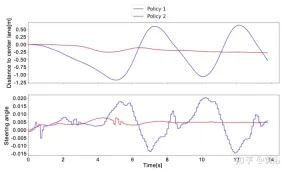
戦略 1 と戦略 2 の違いをよりよく理解するために、実際のテストの短いウィンドウ内でニューラル ネットワークによって予測されたステアリング角度と中央車線までの距離を次に示します。 2 つの戦略は完全に異なる動作をすることがわかります。戦略 1 (青い曲線) は戦略 2 (赤い曲線) に比べてノイズが多く安全ではありません。これは、真の自動運転車への展開にはディープ レスポンス モジュールが重要であることを証明しています。戦略は非常に重要です。 。
最適なソリューションに到達するために数百万のセグメントが必要となる RL の制限を克服するために、模倣学習 (IL) を通じて事前トレーニングが実行されます。さらに、IL のトレンドは大規模なモデルをトレーニングすることですが、RL フレームワークを使用してシステムのトレーニングを継続し、より堅牢性と汎化機能を確保するという考え方のため、同じ小規模なニューラル ネットワーク (約 100 万のパラメーター) が使用されます。こうすることで、ハードウェア リソースの使用量が増加することがなくなります。これは、将来のマルチエージェント トレーニングの可能性を考慮すると非常に重要です。
IL トレーニング フェーズで使用されるデータ セットは、動作に対するルールベースのアプローチに従うシミュレートされたエージェントによって生成されます。特に、曲げの場合、純粋な追跡追跡アルゴリズムが使用され、エージェントは特定のウェイポイントに沿って移動することを目指します。代わりに、IDM モデルを使用してエージェントの縦方向の加速を制御します。
データセットを作成するために、ルールベースのエージェントが 4 つのトレーニング シーンにわたって移動され、100 ミリ秒ごとにスカラー パラメーターと 4 つの視覚入力が保存されました。代わりに、出力は純粋追跡アルゴリズムと IDM モデルによって提供されます。
出力に対応する 2 つの水平および垂直コントロールは、タプル (μacc、μsa) のみを表します。したがって、IL トレーニング フェーズでは、標準偏差 (σacc、σsa) の値は推定されず、値関数 (vacc、vsa) も推定されません。これらの機能と深度応答モジュールは、IL RL トレーニング フェーズで学習されます。
図に示すように、同じニューラル ネットワークのトレーニングを事前トレーニング段階 (青い曲線、IL RL) から開始し、その結果を RL (赤い曲線、純粋な RL) と比較しています。 4つのケース。 IL RL トレーニングに必要な回数は純粋な RL よりも少なく、傾向はより安定していますが、どちらの方法でも良好な成功率を達成しています (図 a)。

さらに、図 b に示されている報酬曲線は、純粋な RL 手法を使用して取得されたポリシー (赤い曲線) は、トレーニング時間を長くしても許容可能な解決策にさえ到達しないことを証明していますが、IL RLポリシーは、いくつかのセグメント内で最適解に到達します (パネル b の青い曲線)。この場合、最適解はオレンジ色の破線で表されます。このベースラインは、4 つのシナリオにわたって 50,000 セグメントを実行するシミュレートされたエージェントによって得られる平均報酬を表します。シミュレートされたエージェントは、IL 事前トレーニング データ セットの収集に使用されたものと同じ決定論的ルールに従います。つまり、曲げには純粋追跡ルールが使用され、縦方向の加速には IDM ルールが使用されます。 2 つのアプローチ間のギャップはさらに顕著になる可能性があり、知能と身体の相互作用が必要となる場合がある、より複雑な操作を実行するシステムを訓練する必要があります。
以上が深層強化学習が現実世界の自動運転に取り組むの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 在 CARLA自动驾驶模拟器中添加真实智体行为Apr 08, 2023 pm 02:11 PM
在 CARLA自动驾驶模拟器中添加真实智体行为Apr 08, 2023 pm 02:11 PMarXiv论文“Insertion of real agents behaviors in CARLA autonomous driving simulator“,22年6月,西班牙。由于需要快速prototyping和广泛测试,仿真在自动驾驶中的作用变得越来越重要。基于物理的模拟具有多种优势和益处,成本合理,同时消除了prototyping、驾驶员和弱势道路使用者(VRU)的风险。然而,主要有两个局限性。首先,众所周知的现实差距是指现实和模拟之间的差异,阻碍模拟自主驾驶体验去实现有效的现实世界
 强化学习中的奖励函数设计问题Oct 09, 2023 am 11:58 AM
强化学习中的奖励函数设计问题Oct 09, 2023 am 11:58 AM强化学习中的奖励函数设计问题引言强化学习是一种通过智能体与环境的交互来学习最优策略的方法。在强化学习中,奖励函数的设计对于智能体的学习效果至关重要。本文将探讨强化学习中的奖励函数设计问题,并提供具体代码示例。奖励函数的作用及目标奖励函数是强化学习中的重要组成部分,用于评估智能体在某一状态下所获得的奖励值。它的设计有助于引导智能体通过选择最优行动来最大化长期累
 自动驾驶汽车激光雷达如何做到与GPS时间同步?Mar 31, 2023 pm 10:40 PM
自动驾驶汽车激光雷达如何做到与GPS时间同步?Mar 31, 2023 pm 10:40 PMgPTP定义的五条报文中,Sync和Follow_UP为一组报文,周期发送,主要用来测量时钟偏差。 01 同步方案激光雷达与GPS时间同步主要有三种方案,即PPS+GPRMC、PTP、gPTPPPS+GPRMCGNSS输出两条信息,一条是时间周期为1s的同步脉冲信号PPS,脉冲宽度5ms~100ms;一条是通过标准串口输出GPRMC标准的时间同步报文。同步脉冲前沿时刻与GPRMC报文的发送在同一时刻,误差为ns级别,误差可以忽略。GPRMC是一条包含UTC时间(精确到秒),经纬度定位数据的标准格
 使用Panda-Gym的机器臂模拟实现Deep Q-learning强化学习Oct 31, 2023 pm 05:57 PM
使用Panda-Gym的机器臂模拟实现Deep Q-learning强化学习Oct 31, 2023 pm 05:57 PM强化学习(RL)是一种机器学习方法,它允许代理通过试错来学习如何在环境中表现。行为主体会因为采取行动导致预期结果而获得奖励或受到惩罚。随着时间的推移,代理会学会采取行动,以使得其预期回报最大化RL代理通常使用马尔可夫决策过程(MDP)进行训练,MDP是为顺序决策问题建模的数学框架。MDP由四个部分组成:状态:环境的可能状态的集合。动作:代理可以采取的一组动作。转换函数:在给定当前状态和动作的情况下,预测转换到新状态的概率的函数。奖励函数:为每次转换分配奖励给代理的函数。代理的目标是学习策略函数,
 C++中的深度强化学习技术Aug 21, 2023 pm 11:33 PM
C++中的深度强化学习技术Aug 21, 2023 pm 11:33 PM深度强化学习技术是人工智能领域备受关注的一个分支,目前在赢得多个国际竞赛的同时也被广泛应用于个人助手、自动驾驶、游戏智能等领域。而在实现深度强化学习的过程中,C++作为一种高效、优秀的编程语言,在硬件资源有限的情况下尤其重要。深度强化学习,顾名思义,结合了深度学习和强化学习两个领域的技术。简单理解,深度学习是指通过构建多层神经网络,从数据中学习特征并进行决策
 特斯拉自动驾驶硬件 4.0 实物拆解:增加雷达,提供更多摄像头Apr 08, 2023 pm 12:11 PM
特斯拉自动驾驶硬件 4.0 实物拆解:增加雷达,提供更多摄像头Apr 08, 2023 pm 12:11 PM2 月 16 日消息,特斯拉的新自动驾驶计算机,即硬件 4.0(HW4)已经泄露,该公司似乎已经在制造一些带有新系统的汽车。我们已经知道,特斯拉准备升级其自动驾驶硬件已有一段时间了。特斯拉此前向联邦通信委员会申请在其车辆上增加一个新的雷达,并称计划在 1 月份开始销售,新的雷达将意味着特斯拉计划更新其 Autopilot 和 FSD 的传感器套件。硬件变化对特斯拉车主来说是一种压力,因为该汽车制造商一直承诺,其自 2016 年以来制造的所有车辆都具备通过软件更新实现自动驾驶所需的所有硬件。事实证
 再掀强化学习变革!DeepMind提出「算法蒸馏」:可探索的预训练强化学习TransformerApr 12, 2023 pm 06:58 PM
再掀强化学习变革!DeepMind提出「算法蒸馏」:可探索的预训练强化学习TransformerApr 12, 2023 pm 06:58 PM在当下的序列建模任务上,Transformer可谓是最强大的神经网络架构,并且经过预训练的Transformer模型可以将prompt作为条件或上下文学习(in-context learning)适应不同的下游任务。大型预训练Transformer模型的泛化能力已经在多个领域得到验证,如文本补全、语言理解、图像生成等等。从去年开始,已经有相关工作证明,通过将离线强化学习(offline RL)视为一个序列预测问题,那么模型就可以从离线数据中学习策略。但目前的方法要么是从不包含学习的数据中学习策略
 如何使用 Go 语言进行深度强化学习研究?Jun 10, 2023 pm 02:15 PM
如何使用 Go 语言进行深度强化学习研究?Jun 10, 2023 pm 02:15 PM深度强化学习(DeepReinforcementLearning)是一种结合了深度学习和强化学习的先进技术,被广泛应用于语音识别、图像识别、自然语言处理等领域。Go语言作为一门快速、高效、可靠的编程语言,可以为深度强化学习研究提供帮助。本文将介绍如何使用Go语言进行深度强化学习研究。一、安装Go语言和相关库在开始使用Go语言进行深度强化学习


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

WebStorm Mac版
便利なJavaScript開発ツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター
ホットトピック
 7444
7444 15137152
15137152