


7 月 22 日にアップロードされた arXiv 論文「JPerceiver: Joint Perception Network for Depth, Pose and Layout Estimation in Driving Scenes」は、オーストラリアのシドニー大学の Tao Dacheng 教授と北京 JD Research Institute の研究について報告しています。 。

奥行き推定、ビジュアル オドメトリ (VO)、および鳥瞰図 (BEV) シーン レイアウト推定は、自動運転車の動きの鍵である運転シーン認識のための 3 つの重要なタスクです。運転計画とナビゲーションの基礎。補完的ではありますが、通常は個別のタスクに焦点を当て、3 つすべてに同時に取り組むことはほとんどありません。
単純なアプローチは、これを逐次的または並列的に独立して実行することですが、3 つの欠点があります、すなわち、1) 深度および VO の結果は、固有のスケール曖昧さの問題の影響を受ける、2) BEV レイアウトは通常行われます。明示的なオーバーレイとアンダーレイの関係を無視して道路と車両を独立して推定する; 3) 深度マップはシーンのレイアウトを推測するための有用な幾何学的手がかりですが、BEV のレイアウトは実際には、深度関連の情報を使用せずに正面図の画像から直接予測されます。
本論文では、これらの問題を解決し、同時に単眼ビデオシーケンスからスケール知覚深度、VO、BEVレイアウトを推定するための共同知覚フレームワークJPerceiverを提案します。クロスビュー幾何変換 (CGT) を使用して、慎重に設計されたスケール損失に従って、絶対スケールを道路レイアウトから深度および VO に伝播します。同時に、クロスビューおよびクロスモーダル転送 (CCT) モジュールは、奥行きの手がかりを使用して、注意メカニズムを通じて道路と車両のレイアウトを推論するように設計されています。 JPerceiver は、エンドツーエンドのマルチタスク学習方法でトレーニングされています。この方法では、CGT スケール ロス モジュールと CCT モジュールがタスク間の知識伝達を促進し、各タスクの特徴学習を促進します。
コードとモデルはダウンロードできます
https://github.com/sunnyHelen/JPerceiver. 図に示すように、JPerceiver は深度、姿勢、道路レイアウトの 3 つのネットワークで構成されており、すべてエンコーダー/デコーダー アーキテクチャに基づいています。深度ネットワークは、現在のフレーム It の深度マップ Dt を予測することを目的としています。ここで、各深度値は 3D ポイントとカメラの間の距離を表します。ポーズ ネットワークの目的は、現在のフレーム It とその隣接フレーム It m の間のポーズ変換 Tt → t m を予測することです。道路レイアウト ネットワークの目的は、現在のフレームの BEV レイアウト Lt、つまりトップビュー デカルト平面における道路と車両の意味論的な占有を推定することです。 3 つのネットワークはトレーニング中に共同で最適化されます。
 #深度と姿勢を予測する 2 つのネットワークは、自己監視型の方法で測光損失と滑らかさ損失を使用して共同で最適化されます。さらに、CGT スケール損失は、単眼の深さと VO 推定のスケール曖昧さの問題を解決するようにも設計されています。
#深度と姿勢を予測する 2 つのネットワークは、自己監視型の方法で測光損失と滑らかさ損失を使用して共同で最適化されます。さらに、CGT スケール損失は、単眼の深さと VO 推定のスケール曖昧さの問題を解決するようにも設計されています。
BEV レイアウトのスケール情報を使用して、スケールを意識した環境認識を実現するために、CGT のスケール損失が深度推定と VO に提案されます。 BEV レイアウトは BEV デカルト平面での意味占有を示すため、車両の前方の Z メートルと左右の (Z/2) メートルの範囲をカバーします。これは、図に示すように、自然距離フィールド z、つまり自車両に対する各ピクセルのメトリック距離 zij を提供します。
 BEV 平面が地面であると仮定します。 , その原点は自車座標系の原点の直下にあり、カメラの外部パラメータに基づいて、BEV 平面をホモグラフィー変換によって前方カメラに投影できます。したがって、上の図に示すように、BEV 距離フィールド z を前方カメラに投影し、予測深さ d を調整するために使用することで、CGT スケール損失を導き出すことができます。
BEV 平面が地面であると仮定します。 , その原点は自車座標系の原点の直下にあり、カメラの外部パラメータに基づいて、BEV 平面をホモグラフィー変換によって前方カメラに投影できます。したがって、上の図に示すように、BEV 距離フィールド z を前方カメラに投影し、予測深さ d を調整するために使用することで、CGT スケール損失を導き出すことができます。
CCT-CV と
と
という 2 つの部分に分かれています。
CCT では、Ff と Fd は対応する知覚ブランチのエンコーダーによって抽出されますが、Fb はビュー投影 MLP によって取得されて Ff を BEV に変換し、サイクル損失によって同じ MLP が Ff' に再変換されるように制約されました。 。
CCT-CV では、クロスアテンション メカニズムを使用して、前方視界と BEV 特徴の間の幾何学的対応を発見し、前方視界情報の改良を導き、BEV 推論の準備をします。前方ビュー画像の特徴を最大限に活用するために、Fb と Ff がそれぞれクエリとキーとしてパッチ: Qbi と Kbi に投影されます。
前方ビュー機能の利用に加えて、CCT-CM は Fd からの 3D 幾何学的情報を強制するためにも導入されています。 Fd は前方ビュー画像から抽出されるため、Ff をブリッジとして使用してクロスモーダルギャップを減らし、Fd と Fb の間の対応関係を学習するのが合理的です。 Fd は Value の役割を果たし、BEV 情報に関連する貴重な 3 次元幾何学情報を取得し、道路レイアウト推定の精度をさらに向上させます。
異なるレイアウトを同時に予測するための共同学習フレームワークを探索するプロセスでは、異なるセマンティック カテゴリの特性と分布に大きな違いがあります。フィーチャについては、通常、運転シナリオの道路レイアウトを接続する必要がありますが、さまざまな車両ターゲットをセグメント化する必要があります。
分布に関しては、曲がり角のシーンよりも直線道路のシーンが多く観察されますが、これは実際のデータセットでは合理的です。この場合、単純なクロスエントロピー (CE) 損失または L1 損失では失敗するため、この違いと不均衡により、BEV レイアウトの学習、特に異なるカテゴリを共同で予測することが困難になります。分散ベースの CE 損失、地域ベースの IoU 損失、境界損失などのいくつかのセグメンテーション損失がハイブリッド損失に結合され、各カテゴリのレイアウトが予測されます。
実験結果は次のとおりです。

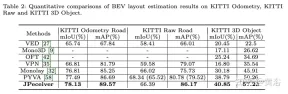
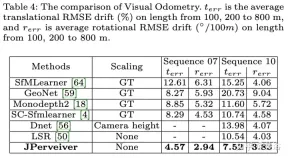

##
以上が共同運転シナリオにおける深度、姿勢、道路推定のための知覚ネットワークの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 在 CARLA自动驾驶模拟器中添加真实智体行为Apr 08, 2023 pm 02:11 PM
在 CARLA自动驾驶模拟器中添加真实智体行为Apr 08, 2023 pm 02:11 PMarXiv论文“Insertion of real agents behaviors in CARLA autonomous driving simulator“,22年6月,西班牙。由于需要快速prototyping和广泛测试,仿真在自动驾驶中的作用变得越来越重要。基于物理的模拟具有多种优势和益处,成本合理,同时消除了prototyping、驾驶员和弱势道路使用者(VRU)的风险。然而,主要有两个局限性。首先,众所周知的现实差距是指现实和模拟之间的差异,阻碍模拟自主驾驶体验去实现有效的现实世界
 特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM
特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM特斯拉是一个典型的AI公司,过去一年训练了75000个神经网络,意味着每8分钟就要出一个新的模型,共有281个模型用到了特斯拉的车上。接下来我们分几个方面来解读特斯拉FSD的算法和模型进展。01 感知 Occupancy Network特斯拉今年在感知方面的一个重点技术是Occupancy Network (占据网络)。研究机器人技术的同学肯定对occupancy grid不会陌生,occupancy表示空间中每个3D体素(voxel)是否被占据,可以是0/1二元表示,也可以是[0, 1]之间的
 一文通览自动驾驶三大主流芯片架构Apr 12, 2023 pm 12:07 PM
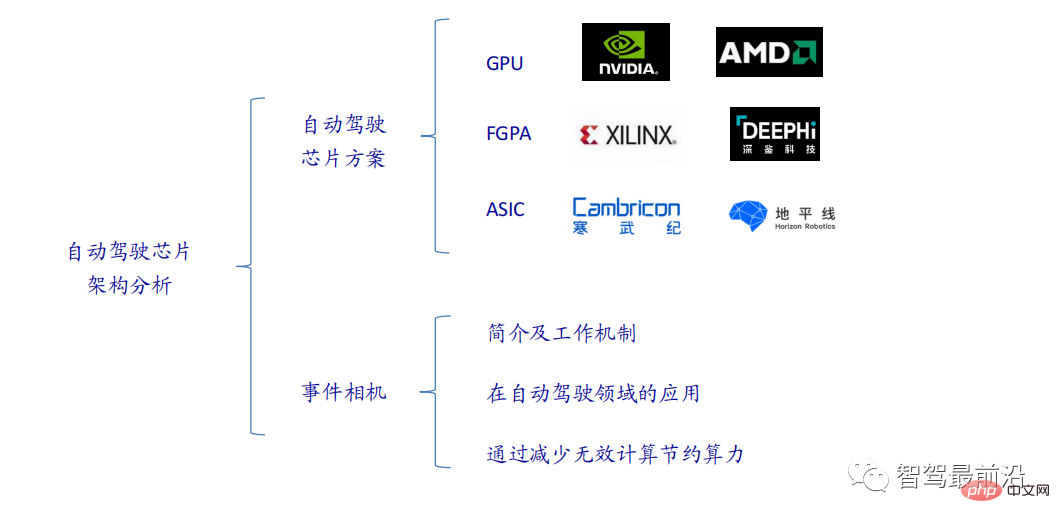
一文通览自动驾驶三大主流芯片架构Apr 12, 2023 pm 12:07 PM当前主流的AI芯片主要分为三类,GPU、FPGA、ASIC。GPU、FPGA均是前期较为成熟的芯片架构,属于通用型芯片。ASIC属于为AI特定场景定制的芯片。行业内已经确认CPU不适用于AI计算,但是在AI应用领域也是必不可少。 GPU方案GPU与CPU的架构对比CPU遵循的是冯·诺依曼架构,其核心是存储程序/数据、串行顺序执行。因此CPU的架构中需要大量的空间去放置存储单元(Cache)和控制单元(Control),相比之下计算单元(ALU)只占据了很小的一部分,所以CPU在进行大规模并行计算
 自动驾驶汽车激光雷达如何做到与GPS时间同步?Mar 31, 2023 pm 10:40 PM
自动驾驶汽车激光雷达如何做到与GPS时间同步?Mar 31, 2023 pm 10:40 PMgPTP定义的五条报文中,Sync和Follow_UP为一组报文,周期发送,主要用来测量时钟偏差。 01 同步方案激光雷达与GPS时间同步主要有三种方案,即PPS+GPRMC、PTP、gPTPPPS+GPRMCGNSS输出两条信息,一条是时间周期为1s的同步脉冲信号PPS,脉冲宽度5ms~100ms;一条是通过标准串口输出GPRMC标准的时间同步报文。同步脉冲前沿时刻与GPRMC报文的发送在同一时刻,误差为ns级别,误差可以忽略。GPRMC是一条包含UTC时间(精确到秒),经纬度定位数据的标准格
 特斯拉自动驾驶硬件 4.0 实物拆解:增加雷达,提供更多摄像头Apr 08, 2023 pm 12:11 PM
特斯拉自动驾驶硬件 4.0 实物拆解:增加雷达,提供更多摄像头Apr 08, 2023 pm 12:11 PM2 月 16 日消息,特斯拉的新自动驾驶计算机,即硬件 4.0(HW4)已经泄露,该公司似乎已经在制造一些带有新系统的汽车。我们已经知道,特斯拉准备升级其自动驾驶硬件已有一段时间了。特斯拉此前向联邦通信委员会申请在其车辆上增加一个新的雷达,并称计划在 1 月份开始销售,新的雷达将意味着特斯拉计划更新其 Autopilot 和 FSD 的传感器套件。硬件变化对特斯拉车主来说是一种压力,因为该汽车制造商一直承诺,其自 2016 年以来制造的所有车辆都具备通过软件更新实现自动驾驶所需的所有硬件。事实证
 端到端自动驾驶中轨迹引导的控制预测:一个简单有力的基线方法TCPApr 10, 2023 am 09:01 AM
端到端自动驾驶中轨迹引导的控制预测:一个简单有力的基线方法TCPApr 10, 2023 am 09:01 AMarXiv论文“Trajectory-guided Control Prediction for End-to-end Autonomous Driving: A Simple yet Strong Baseline“, 2022年6月,上海AI实验室和上海交大。当前的端到端自主驾驶方法要么基于规划轨迹运行控制器,要么直接执行控制预测,这跨越了两个研究领域。鉴于二者之间潜在的互利,本文主动探索两个的结合,称为TCP (Trajectory-guided Control Prediction)。具
 一文聊聊自动驾驶中交通标志识别系统Apr 12, 2023 pm 12:34 PM
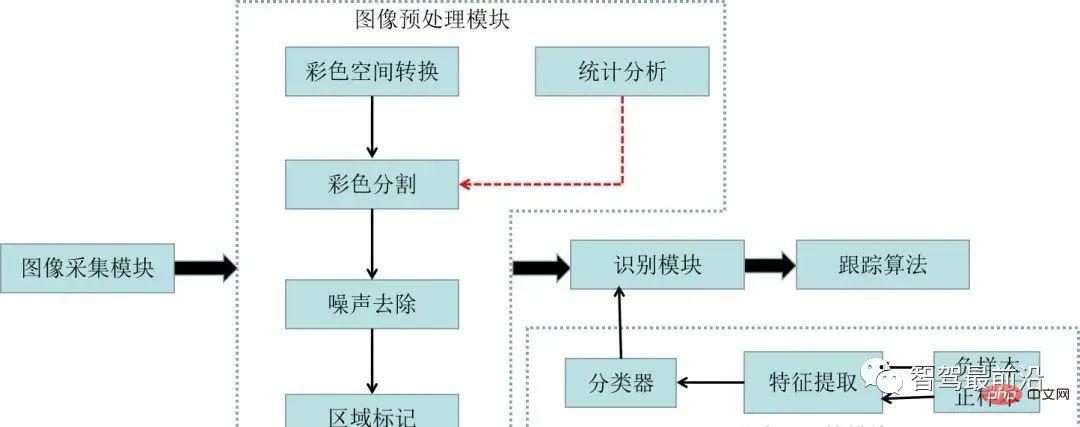
一文聊聊自动驾驶中交通标志识别系统Apr 12, 2023 pm 12:34 PM什么是交通标志识别系统?汽车安全系统的交通标志识别系统,英文翻译为:Traffic Sign Recognition,简称TSR,是利用前置摄像头结合模式,可以识别常见的交通标志 《 限速、停车、掉头等)。这一功能会提醒驾驶员注意前面的交通标志,以便驾驶员遵守这些标志。TSR 功能降低了驾驶员不遵守停车标志等交通法规的可能,避免了违法左转或者无意的其他交通违法行为,从而提高了安全性。这些系统需要灵活的软件平台来增强探测算法,根据不同地区的交通标志来进行调整。交通标志识别原理交通标志识别又称为TS
 一文聊聊SLAM技术在自动驾驶的应用Apr 09, 2023 pm 01:11 PM
一文聊聊SLAM技术在自动驾驶的应用Apr 09, 2023 pm 01:11 PM定位在自动驾驶中占据着不可替代的地位,而且未来有着可期的发展。目前自动驾驶中的定位都是依赖RTK配合高精地图,这给自动驾驶的落地增加了不少成本与难度。试想一下人类开车,并非需要知道自己的全局高精定位及周围的详细环境,有一条全局导航路径并配合车辆在该路径上的位置,也就足够了,而这里牵涉到的,便是SLAM领域的关键技术。什么是SLAMSLAM (Simultaneous Localization and Mapping),也称为CML (Concurrent Mapping and Localiza


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

ドリームウィーバー CS6
ビジュアル Web 開発ツール

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

メモ帳++7.3.1
使いやすく無料のコードエディター

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、
ホットトピック
 7444
7444 15137152
15137152