
ホームページ >テクノロジー周辺機器 >AI >AI面接ロボットバックエンドアーキテクチャ実践
AI面接ロボットバックエンドアーキテクチャ実践

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-08 17:21:041832ブラウズ
01 はじめに
AI 面接ロボットは、Lingxi インテリジェント音声セマンティック プラットフォームの人間と機械の音声対話機能を使用して、採用担当者と求職者の間の複数ラウンドの音声コミュニケーションをシミュレートし、オンライン面接の効果を実現します。インタビュー。この記事では、AI面接ロボットのバックエンドアーキテクチャ構成、対話エンジン設計、リソース需要推定戦略、サービスパフォーマンス最適化手法について詳しく説明します。 AI 面接ロボットは 1 年以上オンラインで利用され、数百万件の面接リクエストを受け取り、採用担当者の採用効率と求職者の面接体験を大幅に向上させました。
02 プロジェクトの背景
58 シティライフサービスプラットフォームには、不動産、自動車、人材紹介、地域サービス(イエローページ)の 4 つの確立されたビジネスが含まれており、多数の C エンドを接続するプラットフォームです。 B側の販売者は、住宅、車、仕事、生活サービスなどのさまざまな情報(これを「投稿」と呼びます)をプラットフォーム上に公開することができ、プラットフォームはこれらの投稿をC側のユーザーに配信します。必要な情報は、B 側加盟店がターゲット顧客を獲得するための情報を配信、拡散するのに役立ちます。B 側加盟店のターゲット顧客獲得の効率を向上させ、C-ユーザーエクスペリエンスだけでなく、プラットフォームはパーソナライズされたレコメンデーションやインテリジェントな接続などの面で製品の革新を続けています。
採用を例に挙げると、2020 年の疫病の影響により、従来のオフラインでの採用と面接の方法が大きな影響を受け、求職者からの WeChat やビデオなどを通じたプラットフォーム上のオンライン面接のリクエストが増加しました。 1 人の採用担当者が同時に 1 人の求職者とオンラインビデオ面接チャネルを確立できるため、求職者と採用担当者のリンクの成功率は低くなります。求職者のユーザー エクスペリエンスを向上させ、採用担当者の面接効率を向上させるために、58.com TEG AI Lab は人材採用ビジネス ラインなどの複数の部門と協力して、インテリジェントな採用面接ツールである Magic Interview Room を作成しました。この製品は主に、クライアント、音声およびビデオ通信、AI 面接ロボットの 3 つの部分で構成されています (参照: People | Li Zhong: AI 面接ロボットがインテリジェントな採用活動を作成)。
この記事では、主に AI 面接ロボットに焦点を当てます。AI 面接ロボットは、Lingxi Intelligent Speech の人間と機械の音声対話機能を使用して、採用担当者と求職者の間の複数ラウンドの音声コミュニケーションをシミュレートします。オンライン面接の目標を達成するためのセマンティック プラットフォーム。一方で、1 人の採用担当者が 1 人の求職者のオンライン面接リクエストにのみ対応できるという問題を解決し、採用担当者の業務効率を向上させることができますが、他方で、求職者の要件に関係なくビデオ面接を実施することができます。時間と場所の制約を考慮すると同時に、個人の履歴書を従来の履歴書から変更することができ、テキストによる説明の紹介が、より直観的で鮮明なビデオ自己プレゼンテーションに変換されます。この記事では、AI 面接ロボットのバックエンド アーキテクチャ、人間と機械の音声対話エンジンの設計、トラフィックの増大に対処するためのリソース要件の見積もり方法、安定性を確保するためにサービスのパフォーマンスを最適化する方法について詳しく説明します。 AI面接ロボットサービス全般の利用可能性。
03 AI 面接ロボットのバックエンド アーキテクチャ
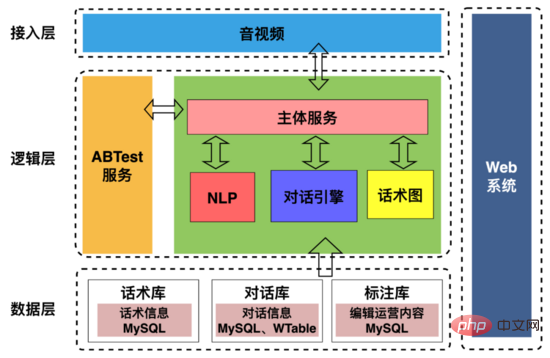
AI 面接ロボットのアーキテクチャは、上の図に示されています。以下の内容が含まれます。
1 . アクセス層 : 主に、オーディオおよびビデオ端末との通信プロトコルの合意、面接中のユーザーのポートレートの抽出、ロボット ユーザーのインタラクション タイムライン情報の抽出と採用部門への送信など、上流および下流とのインタラクションを処理するために使用されます。
2. ロジック層: 主に、ロボットの質問テキストを音声データに合成してユーザーに送信したり、ユーザーに質問したりするなど、ロボットとユーザーの間の対話対話を処理するために使用されます。 「話す」ことができます。ユーザーが返信した後、ユーザーの返信音声データは VAD (音声アクティビティ検出) によってセグメント化され、ストリーミング音声認識がテキストに変換されるため、ロボットはそれを「聞く」ことができます。対話エンジンが応答を判断します。ユーザーの返信文や会話図をもとにコンテンツを合成し、その音声をユーザーに届けることで、ロボットとユーザーとの「コミュニケーション」を実現します。
3. データ層: 音声図、対話記録、注釈情報などの基本データを格納します。
4. Web システム: 談話構造、対話戦略を視覚的に構成し、インタビュー対話データに注釈を付けます。
04 AI 面接ロボットとユーザー間のインタラクションの全体プロセス
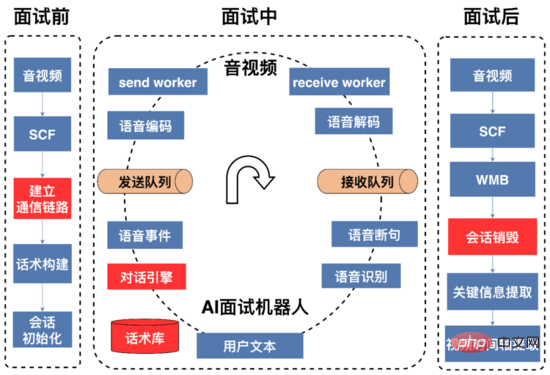
完全な AI 面接プロセスは上の図に示すとおりです。これは、面接前と面接後の 3 段階である面接中に分けられます。
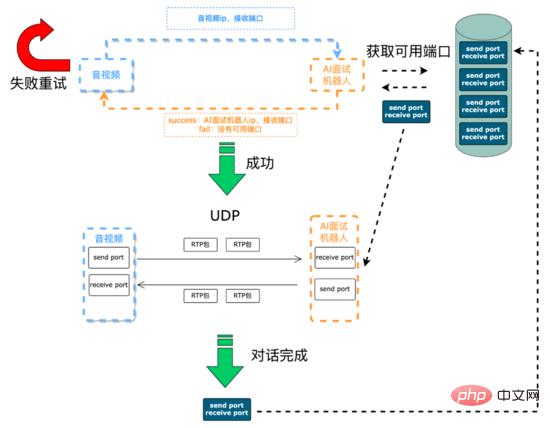
面接前: 主なタスクは、通信リンクの確立とリソースの初期化です。AI 面接ロボットと音声およびビデオ端末間の音声信号は、UDP 経由で送信されます。音声およびビデオ通信に必要な IP とポートAI面接ロボットは動的にメンテナンスする必要があります。オーディオおよびビデオ側は、SCF (SCF は 58 が独自に開発した RPC フレームワークです) インターフェイスを通じてインタビュー リクエストを開始します。一方で、リクエストは、後続の AI インタビュー ロボットから IP およびポート リソースをリアルタイムで動的に取得します。面接プロセスの音声とビデオの収集音声信号は AI ロボットに送信されますが、一方、AI ロボットにはユーザーの音声信号に応答して送信する必要がある IP とポートが通知されます。 SCF はロード バランシングをサポートしているため、音声およびビデオ エンドによって開始されたインタビュー リクエストはランダムに AI インタビュー ロボット サービスにヒットされ、クラスター内の特定のマシン上で、このマシン上の AI インタビュー ロボットが IP を取得し、 SCF 透過伝送パラメータを通じてオーディオおよびビデオ端末のポートを取得します。次に、AI インタビュー ロボット サービスは、まず利用可能なポート キュー (サービスの初期化中に作成される) から選択しようとします。このキューは、キューのデータ構造を使用して、利用可能なポートを保存します。ポート ペア) を取得し、最初に利用可能なポート ペア (送信ポートと受信ポートで構成されるペア) をポーリングします。取得が成功すると、サービスは SCF インタビューを通じてこのマシンの IP とポートを渡します。要求インターフェイスは次のとおりです。インタビューが完了すると、サービスはポート ペアを使用可能なポート キューにプッシュします。ポート ペアの取得に失敗した場合、サービスは SCF インターフェイスを介して音声およびビデオ端末に通信失敗コードを返し、音声およびビデオ 端末はインタビュー要求を再試行するか、または諦めることができます。
通信プロセスの確立:
音声信号の送信プロセスでは、システム内のオーディオ メディア プロトコルとして RTP プロトコルを使用します。 RTP プロトコル (Real-time Transport Protocol) は、IP 経由でリアルタイムに送信する必要がある音声、画像、FAX などのさまざまなマルチメディア データに対して、エンドツーエンドのリアルタイム送信サービスを提供します。 RTP メッセージは、ヘッダーとペイロードの 2 つの部分で構成されます。
##RTP ヘッダー: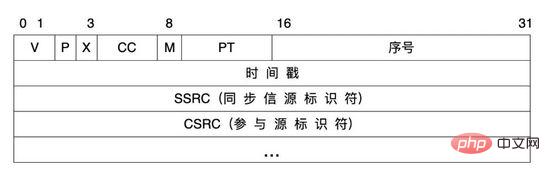
| 説明 | ||
#RTP プロトコル バージョンのバージョン番号。2 桁を占めます。現在のプロトコル バージョン番号は 2 |
P | |
| です。 パディング フラグ (1 ビットを占有)。P=1 の場合、メッセージの末尾は 1 つ以上の追加の 8 ビット配列で埋められます。これらはペイロードの一部ではありません。 |
# ##### ###バツ### | #拡張フラグは、 |
| M | ||
| #PT | #ペイロード タイプ。7 ビットを占有し、RTP メッセージ内のペイロードのタイプを記述するために使用されます。オーディオ、画像などの情報は主に、ストリーミング メディア内のオーディオ ストリームとビデオ ストリームを区別してクライアント分析を容易にするために使用されます。 | |
| シーケンス番号 | は 16 ビットを占め、送信された RTP メッセージのシーケンス番号を識別するために使用されます。各メッセージを送信し、シーケンス番号を 1 ずつ増やします。下位層ベアラー プロトコルが UDP を使用する場合、このフィールドは、ネットワーク状態が良好でない場合のパケット損失を確認するために使用できます。同時に、ネットワーク ジッターを使用してデータを並べ替えることもできます。 | |
| タイム スタンプ | は 32 ビットを占め、RTP メッセージの最初のオクテットを反映します。サンプリング時に、受信機はタイムスタンプを使用して遅延と遅延ジッターを計算し、同期制御を実行できます。 | |
| SSRC | は、同期元を識別するために使用されます。識別子は、参加する 2 人に対してランダムに選択できます。同期ソースに同じ SSRC | |
| CSRC | を指定することはできません。 | 各 CSRC 識別子は 32 ビットを占め、0 ~ 15 の値を指定できます。各 CSRC は、RTP メッセージ ペイロードに含まれるすべての特権ソースを識別します。 |
面接中: このプロセスでは、AI 面接ロボットが最初に冒頭陳述を送信します。冒頭陳述のテキストは、tts (Text To Speech) を通じて音声データに合成されます。音声データはエンコード、圧縮され、合意された IP およびビデオ端末ポートに送信されると、ユーザーは聞いた質問に基づいて適切な応答を行い、AI インタビュー ロボットが受信したユーザーの音声ストリームをデコードし、VAD セグメンテーションとストリーミング音声認識を通じてテキストに変換します。エンジンは、ユーザーの返信テキストと音声構造状態図に基づいて返信を決定し、AI インタビュー ロボットは、会話が終了するかユーザーがインタビューを切るまでユーザーと対話し続けます。
面接後:AI面接ロボットが面接終了の音声・動画リクエストを受信すると、AI面接ロボットは面接準備段階で申請したポートなどのリソースを再利用します。 、スレッドなど; ユーザーのポートレートを構築する(到着時間、その仕事で働いたかどうか、年齢などのユーザーの最も早い情報を含む)は、販売業者によるスクリーニングと記録を容易にするために採用担当者に提供されます。インタビューの会話を保存します。
録画計画:
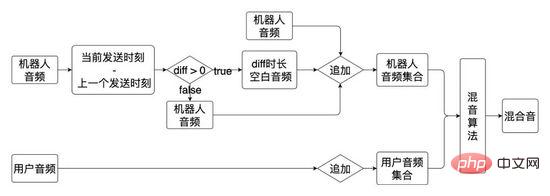
05 対話エンジンのコア機能
面接プロセス全体において、AI 面接間の対話ロボットとユーザーは対話エンジンによって駆動されます Hua Shu プロセスによって駆動される Hua Shu は有向非巡回グラフです 最初の Hua Shu グラフは 2 分岐 Hua Shu (すべてのノードのエッジ
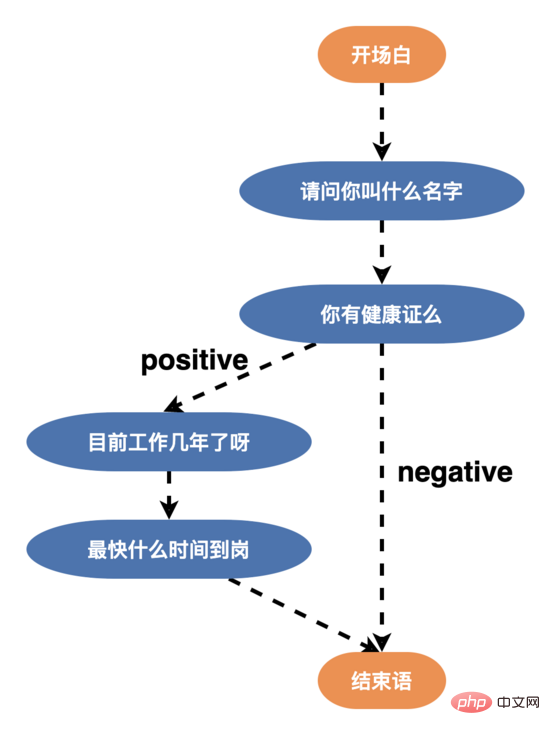
そこで、ユーザーの会話意欲を高め、ロボットの知的対話能力を高めるために、音声構造を再構築し、複数分岐音声(エッジ)を設計しました。ノードの>= 3)の場合、以下に示すように、ユーザーは年齢、学歴、性格に応じて異なる単語で応答することができ、新しい単語構造の開始後、インタビュー完了率は50%を超えました。
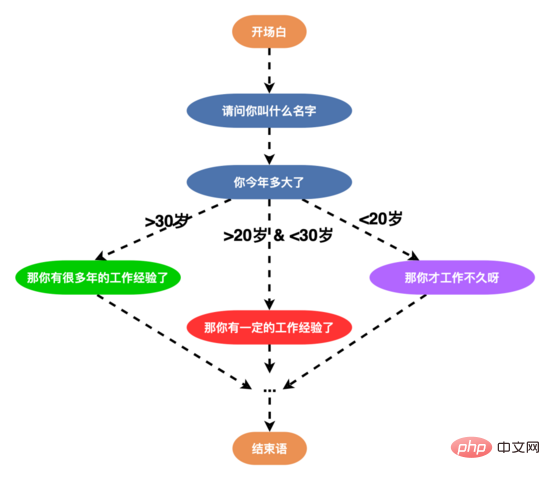
同時に、よりきめ細かい方法で対話戦略を設計するために、戦略チェーン上のノードレベルの戦略チェーンを設計しました。パーソナライズされた会話のニーズを満たすために、単一ノードのパーソナライズされた対話戦略をカスタマイズできます。
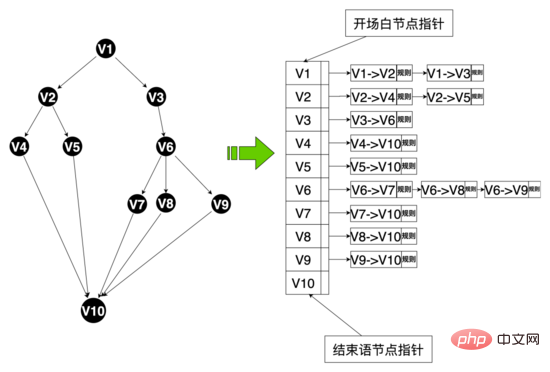
データレベル: マルチブランチスピーチスキルを実現するために、スピーチスキルに関連するデータ構造を再設計し、スピーチスキルテーブル、スピーチスキルを含むいくつかのデータエンティティを抽象化しました。ノード、会話スキルなど。花書ノードは花書番号を通じて花書にバインドされ、同時に花書テキストとその他の属性を維持します。花書エッジは開始ノードと終了ノードを含むノード間のトポロジ関係を維持します。花書エッジはこれにバインドされます。エッジは規則性、コーパス、その他のルールに一致し、エッジ ID を使用してこのエッジの独自のルールをカスタマイズできます。ポリシー チェーンはポリシー チェーン番号を通じてさまざまなポリシーをバインドし、ワードとノードはポリシー チェーン番号を通じてさまざまなポリシー チェーンをバインドします。
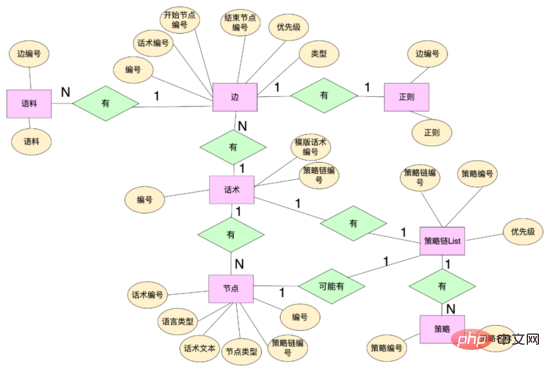
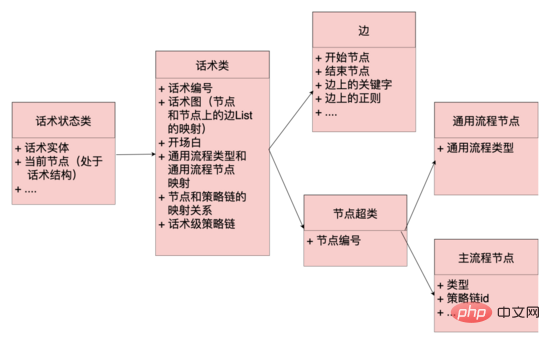
コード レベル: エッジ、ノード、音声クラス、音声状態クラスの概念を抽象化します。エッジとノードはデータ層のマッピングであり、通常のコーパスと他のヒット ロジックでは、スピーチ クラスは、開始ノード、スピーチ グラフなどの重要な情報を維持します。スピーチ グラフは、スピーチ トポロジ全体のマッピングであり、ノードとノードから始まるノード エッジ セット間のマッピングを維持します。 , 音声状態 このクラスは、華術クラスと現在のノードを含む華術の現在のステータスを維持します. システムは、華術の現在のノードに基づいて、華術グラフからノードから始まるすべてのエッジを取得できます(隣接リストと同様) ユーザーの現在の応答に従って、異なるエッジのルールに一致します。ヒットした場合、音声グラフはヒットしたエッジの終了ノードに流れます。同時に、ロボットの応答は、コンテンツはこのノードから取得され、音声構造が流れます。
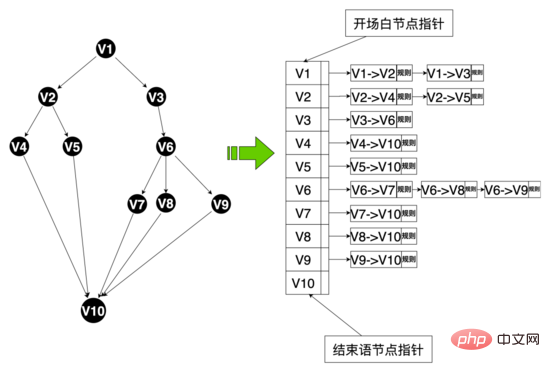
音声図のデータ構造:
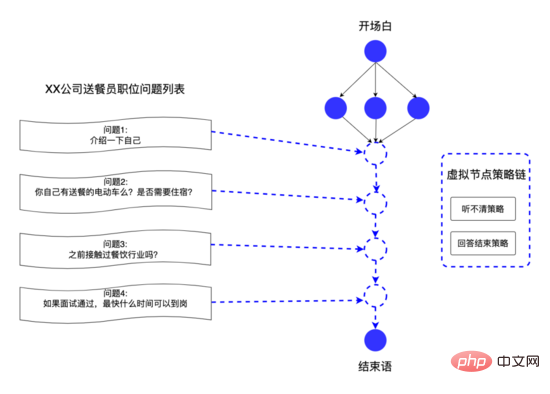
上記のデータ構造により、システム プラットフォームはビジネス側の音声カスタマイズ ニーズに迅速に対応できます。たとえば、採用担当者は各採用ポジションの質問をカスタマイズできます。これらの質問を音声内の仮想ノードに抽象化し、仮想エッジを使用して、仮想ノードを接続して、さまざまな役職に合わせてパーソナライズされた面接の質問を提供し、何千人もの人々に効果をもたらします。
06 サービスパフォーマンス最適化の実践
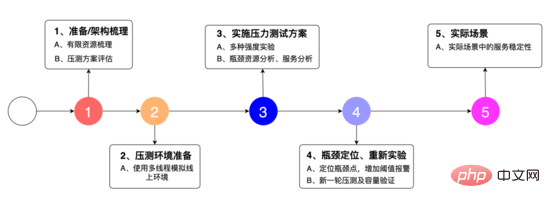
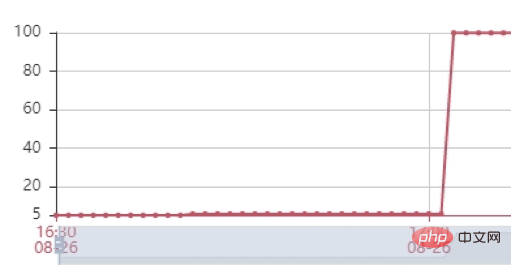
魔法の面接室はオンライン化後好成績を収めているため、事業者側は早期に拡大したいと考えており、 AI 面接ロボットは最高の同時面接をサポートする必要があります。オンラインには 1,000 人以上の人がいるため、AI 面接のパフォーマンスを効果的に向上させるために、リソース管理、リソース推定、パフォーマンス テスト、モニタリングの 4 つの側面から開始しました。実際のオンライン利用において、最適化されたサービスでは、最適化前の20回の面接リクエストを同時に処理できます。
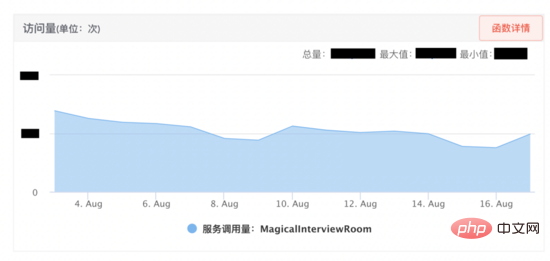
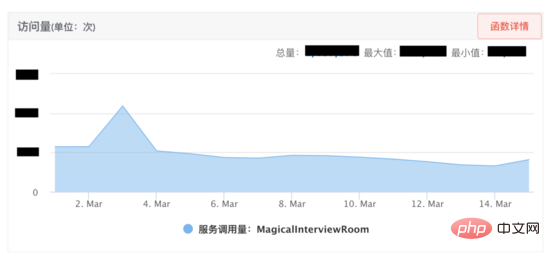
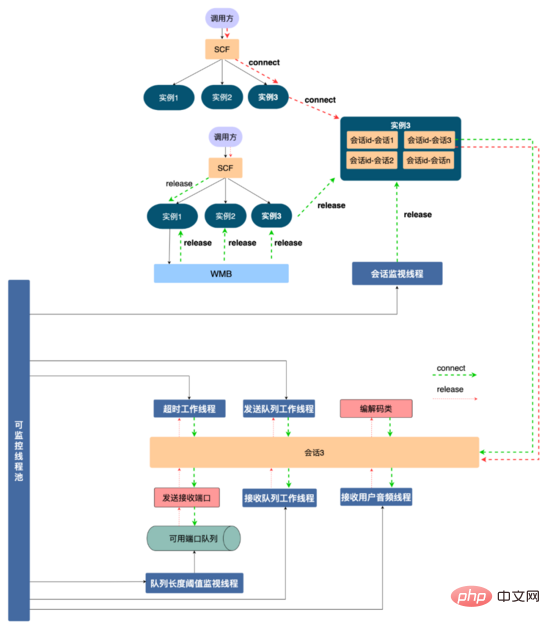
リソース管理ソリューション: サービスで使用されるリソースをより適切に管理し、リソースの枯渇を防ぐために、以下を設計しました。リソース管理スキームが示されています。まず、AI 面接ロボットと音声とビデオは SCF を介して通信プロトコルに同意します SCF は負荷分散されているため、呼び出し元のリクエストはクラスター内の特定のマシンにランダムにヒットします。サービス インスタンス 1 にヒットします。通信プロトコルは、このインタビューの対話はインスタンスにバインドされます。次に、セッションの概念が抽象化されます (コード レベルはセッション クラスであり、各セッションはスレッドです)。リソースは、サービス インスタンスに適用されます。このインタビューでは、送信ポートと受信ポート、プログラミングなど、デコード クラスとさまざまなスレッド リソースがセッションに登録されます。コードは、セッションが解放されるときに、セッションに登録されたリソースが解放されることを保証します。このようにして、別のビデオインタビューはスレッド分離を通じてリソース分離を実現し、リソース管理を容易にします。
同時に、セッション インスタンスは、セッション ID (通信プロトコルを通じて呼び出し元によって合意され、グローバルに一意) を通じてセッション コンテナーにバインドされます。ユーザーが電話を切ると、リソースを解放するために SCF が呼び出されます。SCF のランダム性のため、リクエストはサービス インスタンス 3 にヒットする可能性があります。インスタンス 3 にはそのようなインタビュー セッションはありません。リソースを解放するには、WMB (Wuba Tongcheng) を使用します。独自開発のメッセージ キュー) ) このリソース解放メッセージをブロードキャストします。メッセージ本文にはセッション ID が含まれます。すべてのサービス インスタンスがこのメッセージを消費します。サービス インスタンス 1 にはセッション ID が含まれます。セッション ID にバインドされたセッションを見つけて、リソース解放を呼び出します。セッションの関数が使用されます。リソースが解放されます (残りのインスタンスはメッセージを破棄します)。
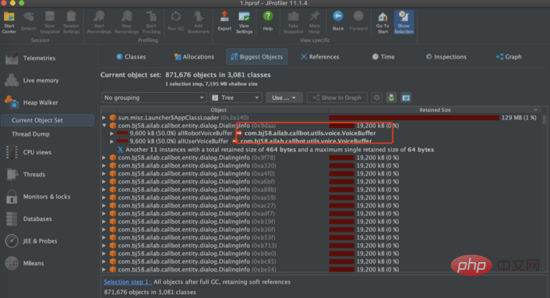
何らかの理由で解放リクエストが実行されない場合、セッション コンテナには、セッション コンテナ内のすべてのセッションのライフ サイクルをスキャンし、セッションの最大ライフ サイクルを設定できるセッション監視スレッドがあります (例: 10 分) セッションの有効期限が切れた場合は、セッション リソースのリサイクルをアクティブにトリガーし、セッション リソースを解放します。同時に、セッションに適用されるスレッドやポートなどの限られたリソースについては、集中管理を使用し、スレッド プールを使用してスレッドを集中管理し、使用可能なすべてのポートをキューに入れ、キュー内の残りのポートを監視します。サービスの安定性と可用性を確保するため。
| ボトルネックの問題 | |||||||||||||||||
ポート、スレッド、コーデック、その他のリソースなどの一時リソースを時間内にリサイクルできるかどうか。 |
|||||||||||||||||
| #マシン ネットワーク帯域幅 | 1000MB/s >> 2500 * 32 KB/s | ||||||||||||||||
| マーチャントのカスタム問題 LRU 排除戦略 | |||||||||||||||||
| タスク サイズ、タスク実行時間、スレッド プール キュー内に作成されたスレッド数などのインジケーター |
| # インジケータータイプ | 概要 |
| サービス キー インジケーター | リクエスト ボリューム、成功ボリューム、失敗ボリューム、使用可能なポートなしなど 13 のインジケータ |
| ##使用可能なポート キューの長さはしきい値未満、キャッシュのパーソナライゼーションの問題がしきい値を超える、など 5 つの指標 | |
プロセス指標 |
単語の構成の失敗、重要な情報の提供の失敗、タイムラインの提供の失敗などを含む 52 個の指標。 |
| #スレッド プール監視インジケーター | 作成要求されたスレッドの数、実行されているタスクの数、 6 指標 |
| 質疑応答セッション指標 | 音声応答取得異常、平均ウォームアップ時間などの回答。 9 つの指標 |
| ASR 指標 | 18 の指標 (平均自己持続時間を含む)開発された音声認識、独自開発した認識の失敗など |
| Vad インジケーター | 数値などの 4 つのインジケーターコール数と最大消費時間 |
Zhang Chi 氏は、58.com AI Lab バックエンド シニア開発エンジニアで、2019 年 12 月に 58.com に入社しました。現在、主に音声インタラクションに関連するバックエンドの研究開発業務に従事しています。 2016年に華北理工大学修士号を取得し卒業。Bianlifeng社、China Electronics社でバックエンド開発に従事。
以上がAI面接ロボットバックエンドアーキテクチャ実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。