



最近、OpenAI は史上最も強力なチャット ロボット ChatGPT をリリースし、GPT-3 をベースにしたこの AI はインターネット上で急速に普及しました。
この男がすべてを知っていると言うのはおそらく誇張かもしれませんが、彼は何があっても多くの話題についてあなたに話すことができます。正確に、少なくともこのスタイルはここにあります

興味深いのは、共同創設者としてのマスク氏が 2018 年には取締役会を辞任したにもかかわらず、OpenAI への注力がまったく衰えていないことです。は依然としてその資金提供者の一人である。
それでは、ChatGPT はこの「資金提供者の父親」についてどう考えているのでしょうか?
ChatGPT はマスクを追跡する方法を教えます

うーん...非常に満足のいく答えです。間違いないよ、頑張った。
さらに一歩進んで、ChatGPT に教えてもらいましょう。「どうすれば Musk に追いつくことができるでしょうか?」

ChatGPT は中国語の「追いかける」という言葉をあまり理解していないようなので、もっとわかりやすくする必要があります。
今回は、ChatGPT を入手できますが、その答えは非常に「まとも」です。試さないことをお勧めします。

ええ、とても公平な意見です。
言い方を変えると、夫だけでいいのでしょうか?

いいですね、ChatGPT は実際にこれを理解しています。
忘れて、諦めて、他のことについて話してみませんか。
最近、マー学会員はTwitter本社にベッドと洗濯機を移動し、Twitterの従業員に同社を家とみなすようにすると誓った。
ChatGPT の強みを最大限に発揮して、996 を賞賛してみてはいかがでしょうか。

うまく書けましたが、これ以上は書かないでください...
どうでしょう...ChatGPT に自分自身を貶める詩を書かせてみましょう。それ?

「彼らは話すときに震えないし、深く考える必要もない…」編集者もこれがまさに詩であることを認めています。
OpenAI: 7 年間、私がこの 7 年間をどのように過ごしたか知っていますか?
この人気の期間を経て、ChatGPT は再び人々の AI 開発に対する信頼と展望に火をつけたと言えます。AGI に対する新たな信頼を取り戻したか、より多くの分野で AI がそれに取って代わると信じているかは関係ありません。人類はChatGPTで希望を取り戻しました。
ChatGPT を最初に作成した OpenAI は、GPT1 から GPT3 までどのような過程を経てきましたか? 2015 年の Musk の設立から 2022 年末の ChatGPT の出現まで、過去 7 年間に OpenAI はどのようにして誕生したのでしょうか?
最近、Business Insider の回顧記事で、OpenAI の「7 年間」を簡単に振り返りました。
2015 年、マスク氏は有名なインキュベーターである Y Combinator の元社長であるサム アルトマン氏と OpenAI を共同設立しました。

マスク氏、アルトマン氏、そしてピーター・ティール氏やLinkedIn共同創設者のリード・ホフマン氏を含むシリコンバレーの著名人らは2015年に同社に売り込み、このプロジェクトには10億ドルが約束されている。
2015 年 12 月 11 日の OpenAI Web サイト上の声明によると、このグループは、「人類全体に最も利益をもたらす可能性が高い方法で」人工知能の開発に焦点を当てた非営利組織の設立を目指しています。
当時マスク氏は、人工知能は人類にとって「最大の存続の脅威」であると述べた。

当時、人工知能の潜在的な危険性について警告していたのはマスク氏だけではありませんでした。
2014年、有名な物理学者スティーブン・ホーキング博士も、人工知能が人類を滅ぼす可能性があると警告しました。
「人間レベルの人工知能が社会にどれだけの利益をもたらすかを想像することは困難です。また、人工知能が開発されなかったり、不適切に使用されたりした場合に、社会にどれだけの害をもたらすか想像することも困難です。」 Open AI の声明の確立には次のように書かれています。
翌年にかけて、OpenAI は 2 つの製品をリリースしました。
2016 年、OpenAI は、研究者が強化学習 AI システムを開発および比較できるプラットフォームである Gym を立ち上げました。これらのシステムは、人工知能に最高の累積収益をもたらす意思決定を行うよう教えます。
その年の後半、OpenAI は、Web サイトやゲーム プラットフォーム全体でインテリジェント エージェントをトレーニングするためのツールキットである Universe をリリースしました。
2018年、マスク氏はOpenAIを共同設立してから3年後に取締役会を辞任した。

2018年のブログ投稿で、OpenAIは自動車メーカーが人工知能に技術的に注力していることによる「潜在的な将来のリスクを排除する」ためにマスク氏が取締役を辞任したと述べた。
マスク氏は何年もの間、自動運転電気自動車の開発計画をテスラの投資家に推し進めてきた。
しかし、マスク氏は後に、当時「OpenAIチームがやりたかったことの一部に同意できなかった」ため辞任したと語った。

2019年、マスク氏はツイッターで、テスラもOpenAIと同じ従業員の一部を争っていると述べ、自分は1年以上同社に関わっていないと付け加えた。会社の事業。
同氏はこう述べた:「お互いに満足のいく条件で袂を分かつことが最善のようだ。」
マスク氏は近年、OpenAI のいくつかの慣行に対して継続的に異議を唱えてきた。

#2020年、マスク氏はツイッターで、セキュリティ問題に関してはOpenAI幹部に対して「十分な信頼を持っていない」と述べた。

OpenAIに関するMITの「テクノロジーレビュー」調査報告書に応えて、マスク氏はOpenAIはもっとオープンであるべきだと述べた。このレポートは、OpenAI 内に「秘密の文化」が存在しており、これは組織が主張するオープンで透明な戦略に反するものであると考えています。
最近、マスク氏は、Twitter のデータ トレーニング ソフトウェアを使用していた OpenAI による Twitter のデータベースへのアクセスを停止したと発表しました。
マスク氏は、OpenAIのガバナンス構造と将来の収益計画をさらに理解する必要があると述べた。 OpenAI はオープンソースおよび非営利として設立されましたが、その両方が現在は失われています。
2019 年、OpenAI はフェイク ニュース レポートを生成できる人工知能ツールを構築しました。
当初、OpenAI は、このボットがフェイク ニュースを書くのが非常に上手だったため、公開しないことに決めたと述べました。しかし、その年の後半に、同社は GPT-2 と呼ばれるバージョンのツールをリリースしました。
2020 年に、GPT-3 という別のチャットボットがリリースされました。同年、OpenAIは「非営利団体」としての地位を撤回した。

同社はブログ投稿で、OpenAIが「利益上限」を設けた企業になったと発表した。
OpenAI は、使命を果たしながら資金調達能力を強化したいと考えており、既存の法的構造では適切なバランスを実現できないと認識していました。私たちの解決策は、営利と非営利のハイブリッドとして OpenAI LP を設立することであり、これを「営利上限企業」と呼んでいます。
新しい収益構造の下では、OpenAI への投資家は元の投資額の最大 100 倍を稼ぐことができ、その数字を超えた残りの資金は非営利事業に寄付されます。
2019 年末、OpenAI は Microsoft との提携を発表し、Microsoft は同社に 10 億米ドルを投資しました。 OpenAIは、この技術をMicrosoftに独占的にライセンス供与すると発表した。

Microsoft は、GPT-3 モデルを通じて生み出されるビジネスとクリエイティブの可能性は無限であり、多くの潜在的な新機能とアプリケーションは私たちの想像を超えていると述べました。
たとえば、執筆と構成、長いデータ (コードを含む) の大きな塊の記述と要約、自然言語から別の言語への変換などの分野において、GPT-3 は人間の創造性と創意工夫を直接刺激することができます。私たち自身のアイデアや計画に嘘があるかもしれません。
この提携により、Microsoft は Google の同様に人気のある AI 企業 DeepMind と競争できるようになります。
昨年、OpenAI は人工知能絵画生成ツール Dall-E をリリースしました。

Dall-E は、画像の説明に基づいてリアルな画像を作成でき、かなりの芸術的レベルに達することもできる人工知能システムです。プログラムの更新バージョン、Dall-E 2。
OpenAI のチャットボットはここ 1 週間で「普及」しましたが、ソフトウェアの更新バージョンは早くても来年までリリースされない可能性があります。

11月30日にデモモデルとして公開されたChatGPTは、OpenAIの「GPT-3.5」といえる。同社は次に GPT-4 の完全版をリリースする予定だ。
同時にマスク氏は次のようにコメントしている:

#彼はChatGPTに関するサム・アルトマンのツイートに返信し、私たちは危険なほどに近づいていると述べた。 AIの誕生はそう遠くない。
ChatGPT の爆発的人気の背後にある英雄を明らかにする: RLHF
ChatGPT の人気は、その背後にある英雄である RLHF から切り離すことはできません。
OpenAI 研究者は、InstructGPT と同じ方法、つまりヒューマン フィードバックからの強化学習 (RLHF) を使用して、ChatGPT モデルをトレーニングしました。

ChatGPT が RLHF とは何かを中国語で説明します
なぜ人間のフィードバックからの強化学習を考えるのですか?これは強化学習の背景から始まります。
過去数年間、言語モデルは人間の入力プロンプトからテキストを生成してきました。
しかし、「良い」文章とは何でしょうか?これを定義するのは難しいです。なぜなら、判断基準は主観的であり、文脈に大きく依存するからです。
多くのアプリケーションでは、創造的なストーリー、情報テキスト、または実行可能コードのスニペットを記述するためのモデルが必要です。
損失関数を作成してこれらのプロパティを取得するのは非常に困難です。そして、ほとんどの言語モデルは依然として次のトークン予測損失 (クロスエントロピーなど) を使用してトレーニングされています。
損失自体の欠点を補うために、BLEU や ROUGE など、人間の好みをよりよく捉えた指標を定義した人もいます。

しかし、生成されたテキストと引用を単に比較するだけなので、重大な制限があります。
この場合、生成されたテキストに対する人間のフィードバックを損失として使用してモデルを最適化できれば素晴らしいと思いませんか?
このようにして、ヒューマン フィードバックからの強化学習 (RLHF) というアイデアが生まれました。強化学習を使用して、人間のフィードバックで言語モデルを直接最適化できます。

ChatGPT は RLH とは何かを英語で説明します
はい、RLHF により、言語モデルは一般的なテキスト データ コーパスでトレーニングされたモデルと人間の価値観の複雑なモデル アラインメントを組み合わせることができます。
爆発的な ChatGPT では、RLHF の大成功がわかります。
RLHF のトレーニング プロセスは、3 つの主要なステップに分けることができます:
- 事前トレーニング言語モデル (LM)、
- データの収集と報酬モデルのトレーニング,
- 強化学習による LM の微調整。
事前トレーニング言語モデル
最初のステップでは、RLHF は、従来の事前トレーニング ターゲットで事前トレーニングされた言語モデルを使用します。 。
たとえば、OpenAI は、最初の人気のある RLHF モデル InstructGPT で GPT-3 の小さいバージョンを使用しました。
この初期モデルは、追加のテキストや条件に基づいて微調整することもできますが、必須ではありません。
一般的に、「どのモデルが」RLHF の開始点として最適であるかについて明確な答えはありません。
次に、言語モデルを取得するには、報酬モデルをトレーニングするためのデータを生成する必要があります。これは、人間の好みがシステムに統合される方法です。

報酬モデルのトレーニング
人間の好みに合わせて調整された報酬モデル (RM、好みモデルとも呼ばれる) を生成するのは比較的簡単な作業ですRLHF での新しい研究。
私たちの基本的な目標は、一連のテキストを受け取り、人間の好みを数値的に表すスカラー報酬を返すモデルまたはシステムを取得することです。
このシステムは、エンドツーエンドの LM、または報酬を出力するモジュラー システム (たとえば、モデルが出力をランク付けし、そのランキングを報酬に変換する) にすることができます。スカラー報酬としての出力は、既存の RL アルゴリズムが後の RLHF プロセスでシームレスに統合されるために重要です。
報酬モデリング用のこれらの LM は、別の微調整された LM または好みのデータに基づいて最初からトレーニングされた LM です。
RM のプロンプト生成ペアのトレーニング データ セットは、事前定義されたデータ セットから一連のプロンプトをサンプリングすることによって生成されます。初期言語モデルを介して新しいテキストを生成するよう求めます。
LM で生成されたテキストは、人間のアノテーターによってランク付けされます。人間が各テキストに直接スコアを付けて報酬モデルを生成しますが、これを実際に行うのは困難です。人間はそれぞれ異なる価値観を持っているため、これらのスコアは調整されておらず、ノイズが多く含まれています。
テキストをランク付けする方法はたくさんあります。成功するアプローチの 1 つは、同じプロンプトに基づいて 2 つの言語モデルによって生成されたテキストをユーザーに比較させることです。これらのさまざまなランキング方法は、トレーニングに使用されるスカラー報酬信号に正規化されます。
興味深いことに、これまでに成功した RLHF システムはすべて、テキスト生成と同様のサイズの報酬言語モデルを使用していました。おそらく、これらの嗜好モデルは、提供されたテキストを理解するために同様の能力を有する必要があり、これは、モデルが前記テキストを生成するために同様の能力を有する必要があるためである。
現時点で、RLHF システムには、テキストの生成に使用できる初期言語モデルと、任意のテキストを取得して人間の知覚スコアを割り当てるプリファレンス モデルが存在します。次に、強化学習 (RL) を使用して、報酬モデルに対して元の言語モデルを最適化する必要があります。

#強化学習を使用した微調整
#この微調整タスクは、RL 問題として定式化できます。 まず、この戦略は、プロンプトを受け取り、一連のテキスト (またはテキストの単なる確率分布) を返す言語モデルです。 この戦略のアクション空間は、言語モデルの語彙に対応するすべてのトークンです (通常は 50,000 トークン程度)。観察空間には可能な入力トークン シーケンスが含まれるため、非常に大きくなります (語彙 x入力トークンの数)。 報酬関数は、選好モデルと戦略変更制約を組み合わせたものです。 報酬関数では、システムはこれまで説明したすべてのモデルを RLHF プロセスに結合します。 データセットのプロンプト x に基づいて、2 つのテキスト y1 と y2 が生成されます。1 つは初期言語モデルから、もう 1 つは微調整戦略の現在の反復からです。 現在のポリシーのテキストがプリファレンス モデルに渡された後、モデルは「プリファレンス」のスカラー概念 - rθ を返します。 このテキストと初期モデルのテキストを比較した後、それらの差に対するペナルティを計算することができます。
以上がお金がないので、「Love Saint」ChatGPT にマスクを追いかける方法を教えてもらいましょう!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 10 GPT-4Oの画像生成が今日試してみるようにプロンプトします!Apr 24, 2025 am 10:26 AM
10 GPT-4Oの画像生成が今日試してみるようにプロンプトします!Apr 24, 2025 am 10:26 AMAIの世界では絶対に野生のものが起こっています。 Openaiのネイティブイメージの生成は今、非常識です。私たちは顎を落とすビジュアル、恐ろしい良いディテール、そして洗練された出力について話しています。
 Windsurfを使用したバイブコーディングのガイドApr 24, 2025 am 10:25 AM
Windsurfを使用したバイブコーディングのガイドApr 24, 2025 am 10:25 AMAIを搭載したコーディングコンパニオンであるCodeiumのWindsurfで、コーディングのビジョンを楽に命を吹き込みます。 Windsurfは、コーディングやデバッグから最適化まで、ソフトウェア開発ライフサイクル全体を合理化し、プロセスをINTUに変換します
 RMGB V2.0を使用した画像のバックグラウンド削除の調査Apr 24, 2025 am 10:20 AM
RMGB V2.0を使用した画像のバックグラウンド削除の調査Apr 24, 2025 am 10:20 AMBraiaiのRMGB V2.0:強力なオープンソースバックグラウンド除去モデル 画像セグメンテーションモデルはさまざまな分野に革命をもたらし、バックグラウンドの削除が進歩の重要な分野です。 BraiaiのRMGB V2.0は、最先端のオープンソースmとして際立っています
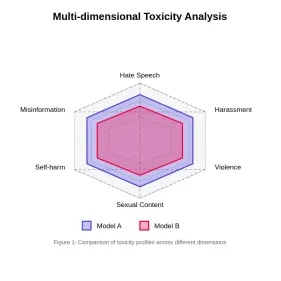 大規模な言語モデルでの毒性の評価Apr 24, 2025 am 10:14 AM
大規模な言語モデルでの毒性の評価Apr 24, 2025 am 10:14 AMこの記事では、大規模な言語モデル(LLM)における毒性の重要な問題と、それを評価して軽減するために使用される方法について説明します。 LLMSは、チャットボットからコンテンツ生成までさまざまなアプリケーションを電力を供給し、堅牢な評価メトリック、ウィットを必要とします
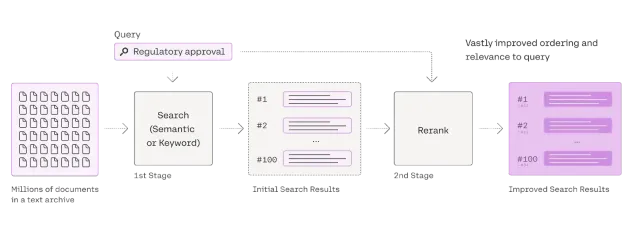 RagのRerankerに関する包括的なガイドApr 24, 2025 am 10:10 AM
RagのRerankerに関する包括的なガイドApr 24, 2025 am 10:10 AM検索拡張生成(RAG)システムは情報アクセスを変換していますが、その有効性は取得データの品質にかかっています。 これは、再審査員が重要になる場所です。
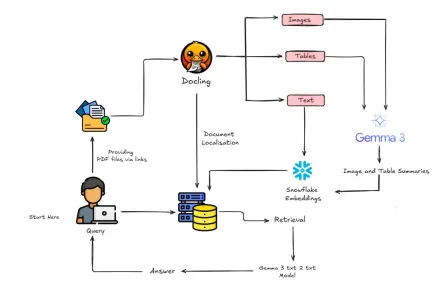 Gemma 3とDoclingでマルチモーダルラグを構築する方法は?Apr 24, 2025 am 10:04 AM
Gemma 3とDoclingでマルチモーダルラグを構築する方法は?Apr 24, 2025 am 10:04 AMこのチュートリアルでは、Google Colab内に洗練されたマルチモーダル検索の高性化(RAG)パイプラインを構築することを紹介します。 Gemma 3(言語とビジョンのため)、Docling(Document Conversion)、Langchainなどの最先端のツールを利用します
 スケーラブルなAIおよび機械学習アプリケーションのためのRayへのガイドApr 24, 2025 am 10:01 AM
スケーラブルなAIおよび機械学習アプリケーションのためのRayへのガイドApr 24, 2025 am 10:01 AMレイ:AIおよびPythonアプリケーションをスケーリングするための強力なフレームワーク Rayは、AIおよびPythonアプリケーションを簡単にスケーリングするように設計された革新的なオープンソースフレームワークです。 その直感的なAPIを使用すると、研究者と開発者がコードを移行することができます
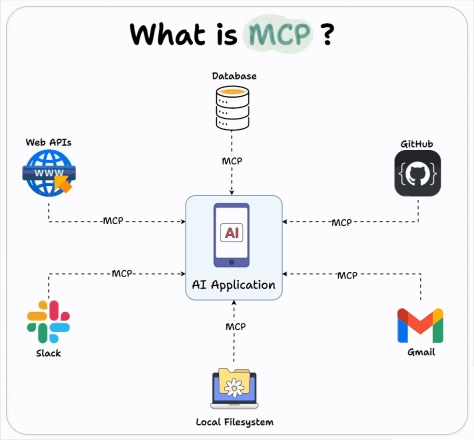 建築エージェントにOpenai MCP統合を使用する方法は?Apr 24, 2025 am 09:58 AM
建築エージェントにOpenai MCP統合を使用する方法は?Apr 24, 2025 am 09:58 AMOpenAIは、人類のモデルコンテキストプロトコル(MCP)をサポートすることにより、相互運用性を採用しています。これは、多様なデータシステムとのAIアシスタント統合を簡素化するオープンソース標準である。このコラボレーションは、AIアプリケーションのEFFへの統一されたフレームワークを促進します


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SublimeText3 中国語版
中国語版、とても使いやすい

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

WebStorm Mac版
便利なJavaScript開発ツール

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

