



翻訳者 | Bugatti
レビュアー | Sun Shujuan
現在、機械学習 (ML) アプリケーションを構築および管理するための標準的な実践方法はありません。機械学習プロジェクトは組織化が不十分で再現性に欠け、長期的には完全に失敗する傾向があります。したがって、機械学習のライフサイクル全体を通じて、品質、持続可能性、堅牢性、コスト管理を維持するためのプロセスが必要です。
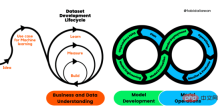
図 1. 機械学習開発ライフサイクル プロセス
品質保証手法 (CRISP-ML(Q ) を使用して機械学習アプリケーションを開発するための業界を超えた標準プロセス) ) は、機械学習製品の品質を保証するための CRISP-DM のアップグレード バージョンです。
CRISP-ML (Q) には 6 つの個別のフェーズがあります:
1. ビジネスとデータの理解
2. データの準備
3. モデル エンジニアリング
4. モデルの評価
5. モデルの展開
6. モニタリングとメンテナンス
これらの段階では、より良いソリューションを構築するために継続的な反復と探索が必要です。フレームワークに順序がある場合でも、後のステージの出力によって、前のステージを再検討する必要があるかどうかが決まる可能性があります。
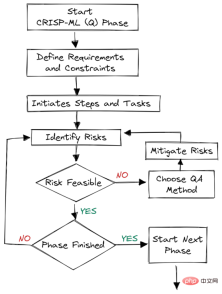
図 2. 各段階での品質保証
品質保証手法がフレームワークの各段階に導入されています。このアプローチには、パフォーマンス指標、データ品質要件、堅牢性などの要件と制約があります。これは、機械学習アプリケーションの成功に影響を与えるリスクを軽減するのに役立ちます。これは、システム全体を継続的に監視し、保守することで実現できます。
例: 電子商取引企業では、データとコンセプトのドリフトがモデルの劣化につながります。これらの変化を監視するシステムを導入しない場合、企業は損失、つまり顧客を失うことになります。
ビジネスとデータの理解
開発プロセスの開始時に、プロジェクトの範囲、成功基準、ML アプリケーションの実現可能性を決定する必要があります。その後、データ収集と品質検証のプロセスを開始しました。このプロセスは長く、困難を伴います。
対象範囲: 機械学習プロセスを使用して達成したいこと。顧客を維持するためでしょうか、それとも自動化によって運用コストを削減するためでしょうか?
成功基準: ビジネス、機械学習 (統計指標)、および経済 (KPI) の成功指標を明確で測定可能に定義する必要があります。
実現可能性: データの可用性、機械学習アプリケーションへの適合性、法的制約、堅牢性、スケーラビリティ、解釈可能性、リソース要件を確保する必要があります。
データ収集: データを収集し、再現性のためにバージョン管理し、実際のデータと生成されたデータの継続的なフローを確保します。
データ品質検証: データの説明、要件、検証を維持することで品質を確保します。
品質と再現性を確保するには、データの統計的特性とデータ生成プロセスを記録する必要があります。
データの準備
第 2 段階は非常に簡単です。モデリングフェーズに向けてデータを準備します。これには、データ選択、データ クリーニング、特徴エンジニアリング、データ拡張および正規化が含まれます。
1. 特徴の選択、データの選択、およびオーバーサンプリングまたはアンダーサンプリングによる不均衡なクラスの処理から始めます。
2. 次に、ノイズの削減と欠損値の処理に重点を置きます。品質保証の目的で、誤った値を減らすためにデータ単体テストを追加します。
3. モデルに応じて、ワンホット エンコーディングやクラスタリングなどの特徴エンジニアリングとデータ拡張を実行します。
4. データを正規化して拡張します。これにより、特徴に偏りが生じるリスクが軽減されます。
再現性を確保するために、データ モデリング、変換、および特徴量エンジニアリングのパイプラインを作成しました。
モデル エンジニアリング
ビジネスおよびデータ理解フェーズの制約と要件によって、モデリング フェーズが決まります。私たちはビジネス上の問題と、それを解決するための機械学習モデルをどのように開発するかを理解する必要があります。私たちはモデルの選択、最適化、トレーニングに重点を置き、モデルのパフォーマンス指標、堅牢性、スケーラビリティ、解釈可能性を確保し、ストレージとコンピューティング リソースを最適化します。
1. モデル アーキテクチャおよび同様のビジネス上の問題に関する調査。
2. モデルのパフォーマンス指標を定義します。
3. モデルの選択。
4. 専門家を統合することでドメインの知識を理解します。
5. モデルのトレーニング。
6. モデルの圧縮と統合。
品質と再現性を確保するために、モデル アーキテクチャ、トレーニングおよび検証データ、ハイパーパラメーター、環境記述などのモデル メタデータを保存し、バージョン管理します。
最後に、ML 実験を追跡し、ML パイプラインを作成して、反復可能なトレーニング プロセスを作成します。
モデル評価
これは、モデルをテストして展開の準備ができていることを確認する段階です。
- テスト データ セットでモデルのパフォーマンスをテストします。
- ランダムまたは偽のデータを提供してモデルの堅牢性を評価します。
- 規制要件を満たすためにモデルの解釈可能性を強化します。
- 自動的に、またはドメインの専門家が協力して、結果を初期の成功指標と比較します。
評価フェーズのすべてのステップは、品質保証のために文書化されます。
モデルのデプロイメント
モデルのデプロイメントは、機械学習モデルを既存のシステムに統合する段階です。このモデルは、サーバー、ブラウザ、ソフトウェア、エッジ デバイスに展開できます。モデルからの予測は、BI ダッシュボード、API、Web アプリケーション、プラグインで利用できます。
モデル展開プロセス:
- ハードウェア推論を定義します。
- 実稼働環境でのモデルの評価。
- ユーザーの受け入れやすさと使いやすさを確保します。
- 損失を最小限に抑えるためのバックアップ計画を提供します。
- 導入戦略。
監視とメンテナンス
運用環境のモデルには、継続的な監視とメンテナンスが必要です。モデルの適時性、ハードウェアのパフォーマンス、ソフトウェアのパフォーマンスを監視します。
継続的なモニタリングはプロセスの最初の部分です。パフォーマンスがしきい値を下回った場合、新しいデータでモデルを再トレーニングするかどうかが自動的に決定されます。さらに、メンテナンス部分はモデルの再トレーニングに限定されません。それには、ビジネス ユースケースに基づいた意思決定メカニズム、新しいデータの取得、ソフトウェアとハードウェアの更新、ML プロセスの改善が必要です。
つまり、ML モデルの継続的な統合、トレーニング、デプロイです。
結論
モデルのトレーニングと検証は、ML アプリケーションのごく一部です。最初のアイデアを現実にするには、いくつかのプロセスが必要です。この記事では、CRISP-ML(Q) と、CRISP-ML(Q) がリスク評価と品質保証にどのように重点を置いているかを紹介します。
最初にビジネス目標を定義し、データを収集してクリーンアップし、モデルを構築し、テスト データ セットでモデルを検証してから、実稼働環境にデプロイします。
このフレームワークの主要なコンポーネントは、継続的な監視とメンテナンスです。データとソフトウェアおよびハードウェアのメトリクスを監視して、モデルを再トレーニングするかシステムをアップグレードするかを決定します。
機械学習の運用が初めてで、さらに詳しく知りたい場合は、DataTalks.Club によってレビューされた 無料の MLOps コース をお読みください。 6 つのフェーズすべてで実践的な経験を積み、CRISP-ML の実際的な実装を理解します。
元のタイトル: CRISP-ML(Q) の理解: 機械学習ライフサイクル プロセス ,著者: アビッド・アリ・アワン
以上がCRISP-ML(Q) の解釈: 機械学習ライフサイクル プロセスの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIのスキルギャップは、サプライチェーンのダウンを遅くしていますApr 26, 2025 am 11:13 AM
AIのスキルギャップは、サプライチェーンのダウンを遅くしていますApr 26, 2025 am 11:13 AM「AI-Ready労働力」という用語は頻繁に使用されますが、サプライチェーン業界ではどういう意味ですか? サプライチェーン管理協会(ASCM)のCEOであるAbe Eshkenaziによると、批評家ができる専門家を意味します
 1つの会社がAIを永遠に変えるために静かに取り組んでいる方法Apr 26, 2025 am 11:12 AM
1つの会社がAIを永遠に変えるために静かに取り組んでいる方法Apr 26, 2025 am 11:12 AM分散型AI革命は静かに勢いを増しています。 今週の金曜日、テキサス州オースティンでは、ビテンサーのエンドゲームサミットは極めて重要な瞬間を示し、理論から実用的な応用に分散したAI(DEAI)を移行します。 派手なコマーシャルとは異なり
 Nvidiaは、AIエージェント開発を合理化するためにNEMOマイクロサービスをリリースしますApr 26, 2025 am 11:11 AM
Nvidiaは、AIエージェント開発を合理化するためにNEMOマイクロサービスをリリースしますApr 26, 2025 am 11:11 AMエンタープライズAIはデータ統合の課題に直面しています エンタープライズAIの適用は、ビジネスデータを継続的に学習することで正確性と実用性を維持できるシステムを構築する大きな課題に直面しています。 NEMOマイクロサービスは、NVIDIAが「データフライホイール」と呼んでいるものを作成することにより、この問題を解決し、AIシステムがエンタープライズ情報とユーザーインタラクションへの継続的な露出を通じて関連性を維持できるようにします。 この新しく発売されたツールキットには、5つの重要なマイクロサービスが含まれています。 NEMOカスタマイザーは、より高いトレーニングスループットを備えた大規模な言語モデルの微調整を処理します。 NEMO評価者は、カスタムベンチマークのAIモデルの簡素化された評価を提供します。 Nemo Guardrailsは、コンプライアンスと適切性を維持するためにセキュリティ管理を実装しています
 aiは芸術とデザインの未来のために新しい絵を描きますApr 26, 2025 am 11:10 AM
aiは芸術とデザインの未来のために新しい絵を描きますApr 26, 2025 am 11:10 AMAI:芸術とデザインの未来 人工知能(AI)は、前例のない方法で芸術とデザインの分野を変えており、その影響はもはやアマチュアに限定されませんが、より深く影響を与えています。 AIによって生成されたアートワークとデザインスキームは、広告、ソーシャルメディアの画像生成、Webデザインなど、多くのトランザクションデザインアクティビティで従来の素材画像とデザイナーに迅速に置き換えられています。 ただし、プロのアーティストやデザイナーもAIの実用的な価値を見つけています。 AIを補助ツールとして使用して、新しい美的可能性を探求し、さまざまなスタイルをブレンドし、新しい視覚効果を作成します。 AIは、アーティストやデザイナーが繰り返しタスクを自動化し、さまざまなデザイン要素を提案し、創造的な入力を提供するのを支援します。 AIはスタイル転送をサポートします。これは、画像のスタイルを適用することです
 エージェントAIとのズームがどのように革命を起こしているか:会議からマイルストーンまでApr 26, 2025 am 11:09 AM
エージェントAIとのズームがどのように革命を起こしているか:会議からマイルストーンまでApr 26, 2025 am 11:09 AM最初はビデオ会議プラットフォームで知られていたZoomは、エージェントAIの革新的な使用で職場革命をリードしています。 ZoomのCTOであるXD Huangとの最近の会話は、同社の野心的なビジョンを明らかにしました。 エージェントAIの定義 huang d
 大学に対する実存的な脅威Apr 26, 2025 am 11:08 AM
大学に対する実存的な脅威Apr 26, 2025 am 11:08 AMAIは教育に革命をもたらしますか? この質問は、教育者と利害関係者の間で深刻な反省を促しています。 AIの教育への統合は、機会と課題の両方をもたらします。 Tech Edvocate NotesのMatthew Lynch、Universitとして
 プロトタイプ:アメリカの科学者は海外の仕事を探していますApr 26, 2025 am 11:07 AM
プロトタイプ:アメリカの科学者は海外の仕事を探していますApr 26, 2025 am 11:07 AM米国における科学的研究と技術の開発は、おそらく予算削減のために課題に直面する可能性があります。 Natureによると、海外の雇用を申請するアメリカの科学者の数は、2024年の同じ期間と比較して、2025年1月から3月まで32%増加しました。以前の世論調査では、調査した研究者の75%がヨーロッパとカナダでの仕事の検索を検討していることが示されました。 NIHとNSFの助成金は過去数か月で終了し、NIHの新しい助成金は今年約23億ドル減少し、3分の1近く減少しました。リークされた予算の提案は、トランプ政権が科学機関の予算を急激に削減していることを検討しており、最大50%の削減の可能性があることを示しています。 基礎研究の分野での混乱は、米国の主要な利点の1つである海外の才能を引き付けることにも影響を与えています。 35
 オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AM
オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AMOpenaiは、強力なGPT-4.1シリーズを発表しました。実際のアプリケーション向けに設計された3つの高度な言語モデルのファミリー。 この大幅な飛躍は、より速い応答時間、理解の強化、およびTと比較した大幅に削減されたコストを提供します


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。
ホットトピック
 7742
7742 15164314139752129125123329
15164314139752129125123329