
ホームページ >テクノロジー周辺機器 >AI >Googleもやったのか? Bard は ChatGPT データをトレーニングに使用していることが暴露され、大きなモデルは実際に一歩一歩遅れをとっています。
Googleもやったのか? Bard は ChatGPT データをトレーニングに使用していることが暴露され、大きなモデルは実際に一歩一歩遅れをとっています。

- PHPz転載
- 2023-04-04 12:30:021720ブラウズ
The Information によると、元 Google 人工知能研究者のジェイコブ デブリン氏は、最近 OpenAI に入社するために会社を辞めましたが、その前に、Google の親会社である Alphabet の CEO、Sundar Pichai 氏に、Google The chatbot Bard が入手していると警告していたことを明らかにしました。 ChatGPT から間接的な方法でデータを取得します。

Baidu Wenxin が「抜け殻」であるとして尋問された事件をまだ覚えていますか?最近、海外メディアは、Googleも同じことをしたようだというニュースを報じた。
The Information によると、元 Google の人工知能研究者であるジェイコブ デブリン氏は、最近 OpenAI に入社するために会社を辞めましたが、その前に、Google の親会社である Alphabet の CEO、Sundar Pichai 氏に、Google のチャットボットについて警告を発していたことを明らかにしました。 Bard は ChatGPT から間接的な方法でデータを取得しています。
Devlin の説明によると、Bard の開発チームは ShareGPT と呼ばれる Web サイトにアクセスしました。この Web サイトでは、ChatGPT を通じてユーザーが取得した多数のチャット コンテンツが共有および公開されていました。これは、Bard が ChatGPT の既製データを使用して自身を「武装」したことを意味します。これは、ChatGPT の初期結果を盗むことと同じです。

これに対し、Google の広報担当者 Chris Pappas はすぐにメディアに声明を発表し、「Bard はトレーニングに ShareGPT や ChatGPT データを一切使用していません。」とはっきりと明言しました。 Bard は ShareGPT や ChatGPT からのいかなるデータについても訓練されていません。")"
Google Bard が以前に ChatGPT データを使用したことがあるかどうかメディアから尋ねられたとき、パパスは答えることを拒否し、彼が言えるのは内容だけだと主張しました。上記のステートメントの。
この事件は、百度文信尼燕が最近直面した同様の疑念を人々に思い出させずにはいられません。
3 月下旬、一部のネチズンは、Baidu Wenxin Yiyan Painting が本質的にどのように「海外でオープンソース化されたばかりの人工知能 Stable Diffusion を使用して画像を生成し、中国語の文章を英語の単語に翻訳し、
当時のネチズンが挙げた例としては、温信宜燕に指示を入力し、「ネズミとバス」を描くよう指示し、その絵を描いたというものがある。 Wenxinyiyan が作成したのは「マウス」と「バス」で、「マウス」と「バス」を英語で表すと「mouse」と「bus」になります。
百度も緊急に対応しました。 3月23日、Baiduは声明を発表し、Wenxin Yiyanは完全にBaiduが開発した大規模言語モデルであり、Wenxinのグラフ機能はWenxinクロスモーダル大規模モデルERNIE-ViLGから来ていると述べた。大規模モデルのトレーニングでは、Baidu は業界の慣例に沿った世界規模のインターネット公開データを使用します。同時に、Wen Xinyiyan は使用プロセス中に常に学習し成長しており、誰もが自社開発のテクノロジーと製品にある程度の自信を持ってほしいと述べました。
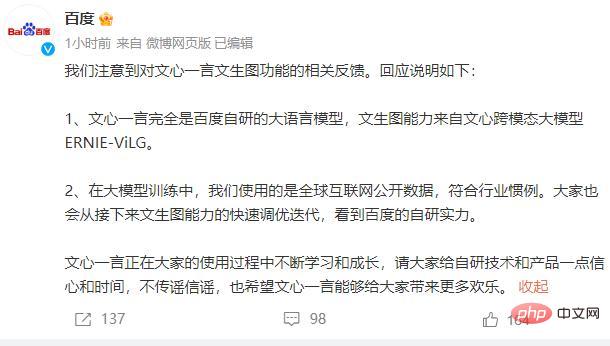
その後、Baidu は同様の問題を修正し、ユーザーはすぐに関連する問題が存在しないことに気づきました。これは、ユーザーのフィードバックに従って同様の状況が修正されたことを示しています。
Baidu Wen Xinyiyan 氏の質問に関して、業界専門家は、ネットワーク公共データの使用は業界の基本的な業務であるとも述べています。この業界には、AI アプリケーション用のトレーニング データを専門とする中間サービス プロバイダーが多数あり、公開データのアノテーションに基づいてトレーニングされた AI データ セットは、実際に複数の AI アプリケーションで同時に使用されます。
しかし、業界の基本的な操作は、消費者レベルでは同じ理解と認識を得られていない可能性があります。今回、Google Bard が ChatGPT データをトレーニングに使用していたことが暴露され、海外でも大騒ぎになりました。多くのネチズンOpenAIの結果を盗んだとしてGoogleを非難した。
Web サイト情報を含むインターネット上の公開データは技術的手段で簡単に取得できるため、検索エンジンである Google にとっては簡単なことです。しかも、この種の暴露は最近退職した Google 社員によるものなので、当然信憑性は大きく高まります。
しかし、一部のネチズンは、デブリン氏が Google AI チームを離れた後、競合他社である OpenAI に加わったと指摘しており、彼の暴露には必然的に商業的利益が絡んでおり、真実性をさらに確認する必要があると指摘しています。
しかし、Geek.com の見解では、このような事件がどれほど真実であっても、これは「鉄則」を完全に示しています。つまり、AI 大型モデルの分野は実際に一歩ずつ遅れをとっており、後発者です。先行者に追いつきたい、それはレベルですが、簡単ではありません。
この背後には、アルゴリズム、計算能力、トレーニング データの品質など、多くの影響要因があります。さらに重要なことは、最初の大規模な AI モデルが成功への道を見つけた後も、トレーニングと進化を続け、立ち止まって追跡者を待つことはないということです。
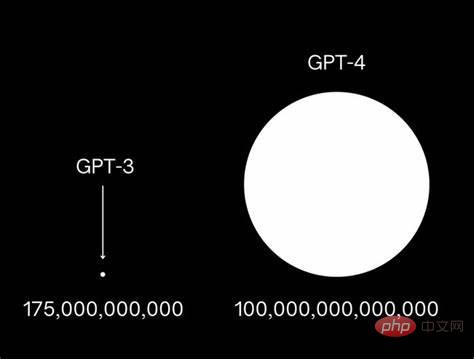
このため、OpenAI の GPT は GPT-3 から GPT-4 時代に急速にアップグレードされました。これはまた、マスクを含む多くの有名人が共同で大企業に次のことを求める公開書簡を発行するきっかけにもなりました。大規模な作戦を一時停止し、人間への脅威を避けるためのモデル開発速度を向上させます。
ロビン・リー氏はメディアとの以前のインタビューでも、一部の分野ではパフォーマンスが向上したが、全体的にはBaidu WenxinyiyanとOpenAI ChatGPTはまだ改善されていないと述べた。レベル間のギャップは 1 ~ 2 か月です。彼はまた、ChatGPT が初期段階で立ち上げられたとき、外部からのフィードバックは Wen Xinyiyan よりもさらに悪かったとも指摘しました。
對於GoogleBard來說,還有一個不利消息是據傳谷歌的Brain 人工智慧團隊正在與另一家隸屬於Alphabet 的人工智慧公司DeepMind 合作,共同進行一個代號為Gemini 的新項目,目標是開發出一個能與OpenAI的GPT競爭的產品。這似乎在暗示,Google對Bard並不自信,希望開發更領先的AI大模型,打造更先進的AI聊天機器人。
以上がGoogleもやったのか? Bard は ChatGPT データをトレーニングに使用していることが暴露され、大きなモデルは実際に一歩一歩遅れをとっています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。