



2022年は生成AI元年と言えるでしょう。最近、Yu Shilun のチームは AIGC に関する包括的な調査を発表し、GAN から ChatGPT までの開発の歴史を紹介しました。
過ぎたばかりの 2022 年は、間違いなく生成 AI の爆発的な特異点です。
2021年以降、生成AIはガートナーの「人工知能テクノロジー・ハイプ・サイクル」に2年連続で選出されており、今後の重要なAI技術トレンドと考えられています。
最近、Yu Shilun のチームは AIGC に関する包括的な調査を発表し、GAN から ChatGPT までの開発の歴史を紹介しました。

論文アドレス: https://arxiv.org/pdf/2303.04226.pdf
この記事は、論文の一部を抜粋して紹介します。
特異点が到来?
近年、人工知能生成コンテンツ (AIGC、生成 AI とも呼ばれる) がコンピューター サイエンス コミュニティの外で広く注目を集めています。
ChatGPT や DALL-E-2 など、大手テクノロジー企業が開発したさまざまなコンテンツ生成製品に社会全体が大きな関心を持ち始めています。
AIGC とは、生成人工知能 (GAI) テクノロジーを使用してコンテンツを生成することを指し、短時間で大量のコンテンツを自動的に作成できます。
ChatGPT は、会話を構築するために OpenAI によって開発された AI システムです。このシステムは、人間の言語を効果的に理解し、有意義な方法で応答することができます。
さらに、DALL-E-2 は OpenAI によって開発されたもう 1 つの最先端の GAI モデルであり、テキストの説明から独自の高品質画像を数分で作成できます。

画像生成における AIGC の例
技術的に言えば、AIGC は、GAI を使用して満足のいく画像を生成するためにモデルをガイドしてタスクを完了できる与えられた命令を指します。指導内容です。この生成プロセスは通常、命令からインテント情報を抽出するステップと、抽出されたインテントに基づいてコンテンツを生成するステップの 2 つのステップで構成されます。
しかし、これまでの研究で証明されているように、上記の 2 つのステップを含む GAI モデルのパラダイムは完全に新しいものではありません。
以前の研究と比較して、最近の AIGC の進歩の中心点は、より大きなデータ セットでより複雑な生成モデルをトレーニングし、より大きなベース モデル フレームワークを使用し、幅広いコンピューティング リソースにアクセスできるようになった点です。
たとえば、GPT-3 の主要なフレームワークは GPT-2 と同じですが、事前学習データのサイズが WebText (38GB) から CommonCrawl (フィルタリング後 570GB) に増加し、基本モデルのサイズが増加します。 1.5Bから175Bに増加します。

したがって、GPT-3 は、さまざまなタスクにおいて GPT-2 よりも優れた汎化能力を備えています。
研究者たちは、データ量とコンピューティング能力の増加によるメリットに加えて、新しいテクノロジーと GAI アルゴリズムを組み合わせる方法も模索しています。
たとえば、ChatGPT はヒューマン フィードバックによる強化学習 (RLHF) を利用して、特定の指示に対する最適な応答を決定し、それによってモデルの信頼性と精度が時間の経過とともに向上します。このアプローチにより、ChatGPT は長い会話における人間の好みをよりよく理解できるようになります。
同時に、CVでは、2022年にStability AIによって提案されたStable Diffusionも画像生成において大きな成功を収めました。
これまでの方法とは異なり、生成拡散モデルは探索と活用のバランスを制御することで高解像度の画像を生成することができ、それによって生成される画像の多様性とトレーニング データの組み合わせの類似性との調和を実現します。
これらの進歩を組み合わせることで、このモデルは AIGC の使命を大きく前進させ、芸術、広告、教育などのさまざまな業界で採用されています。
近い将来、AIGC は機械学習研究の重要な分野であり続けるでしょう。
一般的に、GAI モデルはシングルモーダル モデルとマルチモーダル モデルの 2 つのタイプに分類できます。
したがって、過去の研究を包括的にレビューし、現場の問題点を見つけ出します。重要です。これは、AIGC 分野のコア技術とアプリケーションに焦点を当てた初めての調査です。
これは、テクノロジーとアプリケーションの観点から GAI をまとめた AIGC の初めての包括的な調査です。
これまでの調査では主に、自然言語生成、画像生成、マルチモーダル機械学習生成など、さまざまな観点から GAI を紹介しました。ただし、これらの以前の作品は、AIGC の特定の部分にのみ焦点を当てていました。
この調査では、まず AIGC で一般的に使用されている基礎技術を確認しました。次に、ユニモーダル生成とマルチモーダル生成を含む、高度な GAI アルゴリズムの包括的な概要がさらに提供されます。さらに、この論文では AIGC のアプリケーションと潜在的な課題についても検討しています。
最後に、この分野の将来の方向性を強調します。要約すると、この論文の主な貢献は次のとおりです。 - 私たちの知る限り、AIGC および AI 拡張生成プロセスの正式な定義と包括的な調査を提供したのは初めてです。
-AIGCの歴史と基礎技術を振り返り、単峰性発電と多峰性発電の観点からGAIタスクとモデルの最新の進歩を包括的に分析しました。
-この記事では、AIGC が直面する主な課題と将来の研究動向について説明します。
生成 AI の歴史
生成モデルには人工知能における長い歴史があり、1950 年代の隠れマルコフ モデル (HMM) とガウス混合モデル (GMM) の開発にまで遡ります。
これらのモデルは、音声や時系列などの連続データを生成します。ただし、生成モデルのパフォーマンスが大幅に向上したのは、ディープ ラーニングの出現によってでした。
初期の深層生成モデルでは、通常、異なるドメインはあまり重複しませんでした。

CV、NLP、VL における生成 AI の開発の歴史
NLP では、文章を生成する伝統的な方法は N グラム言語モデルを使用することです。単語の分布を学習し、最適なシーケンスを検索します。ただし、この方法は長い文章には効果的に適応できません。
この問題を解決するために、リカレント ニューラル ネットワーク (RNN) が後に言語モデリング タスクに導入され、比較的長い依存関係をモデル化できるようになりました。
2 つ目は、長短期記憶 (LSTM) とゲート リカレント ユニット (GRU) の開発です。これらは、トレーニング中の記憶を制御するためにゲート メカニズムを使用します。これらのメソッドは、サンプル内で約 200 個のトークンを処理できます。これは、N グラム言語モデルと比較して大幅な改善を示しています。
同時に、CV では、深層学習ベースの手法が登場する前、従来の画像生成アルゴリズムではテクスチャ合成 (PTS) やテクスチャ マッピングなどの手法が使用されていました。
これらのアルゴリズムは手作業で設計された機能に基づいており、複雑で多様な画像を生成する機能は限られています。
2014 年、敵対的生成ネットワーク (GAN) が最初に提案され、さまざまなアプリケーションで目覚ましい成果を上げたため、人工知能の分野におけるマイルストーンとなりました。
変分オートエンコーダ (VAE) や生成拡散モデルなどの他の手法も開発され、画像生成プロセスをよりきめ細かく制御し、高品質の画像を生成できるようになりました。
さまざまな分野での生成モデルの開発はさまざまな道をたどってきましたが、最終的には Transformer アーキテクチャという交差点が現れました。
2017 年に、Transformer は Vaswani らによって NLP タスクに導入され、その後 CV に適用され、その後、さまざまな分野の多くの生成モデルの主要なアーキテクチャになりました。
NLP の分野では、BERT や GPT などの多くのよく知られた大規模言語モデルが、主要な構成要素として Transformer アーキテクチャを採用しています。以前のビルディング ブロック、つまり LSTM および GRU と比較した利点。
CV では、Vision Transformer (ViT) と Swin Transformer がこのコンセプトをさらに発展させ、Transformer アーキテクチャとビジョン コンポーネントを組み合わせて、画像ベースのダウンリンク システムに適用できるようにしました。
Transformer によって単一モダリティにもたらされる改善に加え、このクロスオーバーにより、さまざまな分野のモデルを融合してマルチモーダル タスクを実行できるようになります。
マルチモーダル モデルの例は CLIP です。 CLIP は共同視覚言語モデルです。 Transformer アーキテクチャとビジュアル コンポーネントを組み合わせて、大量のテキスト データと画像データのトレーニングを可能にします。
事前トレーニングで視覚的知識と言語的知識を組み合わせることで、CLIP はマルチモーダル キュー生成の画像エンコーダーとしても使用できます。つまり、Transformer ベースのモデルの出現は人工知能の生成に革命をもたらし、大規模なトレーニングの可能性をもたらしました。
近年、研究者はこれらのモデルに基づいた新しい技術を導入し始めています。
たとえば、NLP では、モデルがタスクの要件をよりよく理解できるようにするために、少数ショットのヒントが好まれることがあります。これは、データセットから選択されたいくつかの例をプロンプトに含めることを指します。
視覚言語では、研究者はパターン固有のモデルと自己教師ありの対比学習目標を組み合わせて、より強力な表現を提供します。
今後、AIGCの重要性が高まるにつれ、より多くの技術が導入され、この分野に大きな活力を与えることになるでしょう。
AIGC の基本
このセクションでは、AIGC の一般的に使用される基本モデルを紹介します。
基本モデル
Transformer
Transformer は、GPT-3、DALL などの多くの最先端モデルのバックボーン アーキテクチャです。 -E-2、コーデックスとゴーファー。
可変長シーケンスとコンテキスト認識の処理における RNN などの従来のモデルの制限を解決することが最初に提案されました。
Transformer のアーキテクチャは主に自己注意メカニズムに基づいており、これによりモデルは入力シーケンスのさまざまな部分に注意を払うことができます。
Transformer はエンコーダーとデコーダーで構成されます。エンコーダは入力シーケンスを受信して隠蔽表現を生成し、デコーダは隠蔽表現を受信して出力シーケンスを生成します。
エンコーダとデコーダの各層は、マルチヘッド アテンションとフィードフォワード ニューラル ネットワークで構成されます。マルチヘッド アテンションは Transformer の中核コンポーネントであり、タグの関連性に基づいて異なる重みを割り当てることを学習します。
この情報ルーティングのアプローチにより、モデルは長期的な依存関係をより適切に処理できるようになり、その結果、幅広い NLP タスクのパフォーマンスが向上します。
Transformer のもう 1 つの利点は、そのアーキテクチャにより並列性が高く、データが誘導バイアスを克服できることです。この機能により、Transformer は大規模な事前トレーニングに非常に適しており、Transformer ベースのモデルをさまざまなダウンストリーム タスクに適応させることができます。
事前トレーニング済み言語モデル
Transformer アーキテクチャの導入以来、その並列処理と学習機能により、Transformer アーキテクチャは自然言語処理の主流の選択肢となっています。
一般的に、これらの Transformer ベースの事前トレーニング済み言語モデルは、トレーニング タスクに応じて、自己回帰言語モデルとマスク言語モデルの 2 つのカテゴリに分類できます。
複数のトークンで構成される文が与えられた場合、BERT や RoBERTa などのマスクされた言語モデリングの目標は、文脈情報を考慮してマスクされたトークンの確率を予測することです。
マスクされた言語モデルの最も注目すべき例は BERT です。これには、マスクされた言語モデリングと次の文の予測タスクが含まれます。 RoBERTa は BERT と同じアーキテクチャを使用し、事前トレーニング データの量を増やし、より困難な事前トレーニング目標を組み込むことでパフォーマンスを向上させます。
XL-Net も BERT に基づいており、トレーニング反復ごとに予測の順序を変更する置換操作が組み込まれており、モデルがより多くのラベル間情報を学習できるようになります。
GPT-3 や OPT などの自己回帰言語モデルは、前のトークンが与えられた確率をモデル化するため、左から右への言語モデルです。マスクされた言語モデルとは異なり、自己回帰言語モデルは生成タスクにより適しています。
人間のフィードバックからの強化学習
大規模データでトレーニングされているにもかかわらず、AIGC は常にユーザーの意図と一致するコンテンツを出力するとは限りません。
AIGC 出力を人間の好みにより適合させるために、Sparrow、InstructGPT、ChatGPT などのさまざまなアプリケーションでのモデルの微調整に人間のフィードバックからの強化学習 (RLHF) が適用されています。
通常、RLHF のプロセス全体には、事前トレーニング、報酬学習、強化学習の微調整という 3 つのステップが含まれます。
コンピューティング
ハードウェア
近年、ハードウェア テクノロジが大幅に進歩し、大規模モデルのトレーニングが容易になりました。
以前は、CPU を使用して大規模なニューラル ネットワークをトレーニングするには、数日、場合によっては数週間かかることがありました。ただし、コンピューティング能力の向上に伴い、このプロセスは数桁高速化されました。
たとえば、NVIDIA の NVIDIA A100 GPU は、BERT 大規模推論プロセスにおいて V100 より 7 倍、T4 より 11 倍高速です。
さらに、Google の Tensor Processing Unit (TPU) はディープ ラーニング用に設計されており、A100 GPU と比較して高いコンピューティング パフォーマンスを提供します。
コンピューティング能力の加速的な進歩により、人工知能モデルのトレーニングの効率が大幅に向上し、大規模で複雑なモデルの開発に新たな可能性がもたらされました。
分散トレーニング
もう 1 つの大きな改善点は分散トレーニングです。
従来の機械学習では、トレーニングは通常、単一のプロセッサを使用するマシン上で実行されます。このアプローチは、小規模なデータセットやモデルにはうまく機能しますが、大規模なデータセットや複雑なモデルを扱う場合には非現実的になります。
分散トレーニングでは、トレーニング タスクが複数のプロセッサまたはマシンに分散されるため、モデルのトレーニング速度が大幅に向上します。
一部の企業は、深層学習スタックの分散トレーニング プロセスを簡素化するフレームワークをリリースしています。これらのフレームワークは、開発者が基盤となるインフラストラクチャを管理することなく、トレーニング タスクを複数のプロセッサまたはマシンに簡単に分散できるツールと API を提供します。
クラウド コンピューティング
クラウド コンピューティングは、大規模なモデルのトレーニングにも重要な役割を果たします。以前は、モデルはローカルでトレーニングされることがよくありました。現在、AWS や Azure などのクラウド コンピューティング サービスが強力なコンピューティング リソースへのアクセスを提供しているため、ディープ ラーニングの研究者や実践者は、大規模なモデルのトレーニングに必要な大規模な GPU または TPU クラスターをオンデマンドで作成できます。
これらの進歩を総合すると、より複雑で正確なモデルの開発が可能になり、人工知能の研究と応用のさまざまな分野で新たな可能性が開かれます。
著者の紹介
Philip S. Yu は、コンピューター サイエンス分野の学者、ACM/IEEE フェロー、および米国大学コンピューター サイエンス学部の著名な教授です。イリノイ州シカゴ (UIC)。
彼は、ビッグデータのマイニングと管理の理論と技術において世界的に有名な功績を残しています。規模、速度、多様性の観点からビッグ データの課題に対応するため、特に多様なデータの統合、データ ストリーム、頻出パターン、部分空間のマイニングにおいて、データ マイニングと管理の方法と技術における効果的かつ最先端のソリューションを提案してきました。 . 彼はグラフに関して画期的な貢献をしました。

彼は、並列分散データベース処理テクノロジーの分野でも先駆的な貢献をし、それを IBM S/390 Parallel Sysplex システムに適用し、従来の IBM メインフレーム移行の統合に成功しました。並列マイクロプロセッサアーキテクチャへ。
以上が紙は30ページ! Yu Shilun チームによる新作: AIGC の包括的な調査、GAN から ChatGPT までの開発履歴の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 CrewaiとOllamaでマルチエージェントシステムを構築する方法は?Apr 12, 2025 am 09:44 AM
CrewaiとOllamaでマルチエージェントシステムを構築する方法は?Apr 12, 2025 am 09:44 AM導入 APIにお金を費やしたくないのですか、それともプライバシーを心配していますか?それとも、LLMSをローカルに実行したいだけですか?心配しないで;このガイドは、ローカルLLMSを使用してエージェントとマルチエージェントフレームワークを構築するのに役立ちます
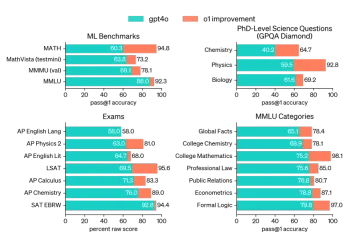 AVバイト:Openai' S O1モデル、Apple'の視覚的なAIなど - 分析VidhyaApr 12, 2025 am 09:38 AM
AVバイト:Openai' S O1モデル、Apple'の視覚的なAIなど - 分析VidhyaApr 12, 2025 am 09:38 AM導入 今週は、人工知能の世界(AI)の主要な更新が詰め込まれています。 OpenaiのO1モデルから、高度な推論の紹介からAppleの画期的な視覚知能技術、Techまで
 生産グレードのエージェントRAGパイプラインを監視する方法は?Apr 12, 2025 am 09:34 AM
生産グレードのエージェントRAGパイプラインを監視する方法は?Apr 12, 2025 am 09:34 AM導入 2022年、CHATGPTの立ち上げにより、ハイテク産業と非テクノロジーの両方の業界の両方に革命をもたらし、個人や組織にAIを生成しました。 2023年を通じて、大規模な言語モードの活用に集中しました
 Star Schemaを使用してデータウェアハウスを最適化する方法は?Apr 12, 2025 am 09:33 AM
Star Schemaを使用してデータウェアハウスを最適化する方法は?Apr 12, 2025 am 09:33 AMStar Schemaは、データウェアハウジングとビジネスインテリジェンスで使用される効率的なデータベース設計です。データを整理し、周囲の寸法テーブルにリンクされた中央のファクトテーブルになります。この星のような構造は、複雑なqを簡素化します
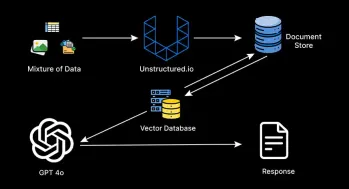 マルチモーダルRAGシステムの構築に関する包括的なガイドApr 12, 2025 am 09:29 AM
マルチモーダルRAGシステムの構築に関する包括的なガイドApr 12, 2025 am 09:29 AMRAGシステムとしてよく知られている検索拡張生成システムは、高価な微調整の手間なしでカスタムエンタープライズデータに関する質問に答えるインテリジェントAIアシスタントを構築するための事実上の標準となっています
 エージェントラグシステムはどのようにテクノロジーを変換しますか?Apr 12, 2025 am 09:21 AM
エージェントラグシステムはどのようにテクノロジーを変換しますか?Apr 12, 2025 am 09:21 AM導入 人工知能は新しい時代に入りました。モデルが事前定義されたルールに基づいて単に情報を出力する時代は終わりました。今日のAIの最先端のアプローチは、Ragを中心に展開しています(検索装備
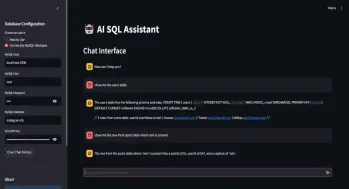 自動生成クエリのSQLアシスタントApr 12, 2025 am 09:13 AM
自動生成クエリのSQLアシスタントApr 12, 2025 am 09:13 AM複雑なSQLクエリを書いたり、スプレッドシートを並べ替えたりせずに、データベースと話をしたり、単純な言語で質問したり、即座に答えを得たりすることを望んだことがありますか? LangchainのSQL Toolkit、Groq a
 AIインデックス2025を読む:AIはあなたの友人、敵、または副操縦士ですか?Apr 11, 2025 pm 12:13 PM
AIインデックス2025を読む:AIはあなたの友人、敵、または副操縦士ですか?Apr 11, 2025 pm 12:13 PMスタンフォード大学ヒト指向の人工知能研究所によってリリースされた2025年の人工知能インデックスレポートは、進行中の人工知能革命の良い概要を提供します。 4つの単純な概念で解釈しましょう:認知(何が起こっているのかを理解する)、感謝(利益を見る)、受け入れ(顔の課題)、責任(責任を見つける)。 認知:人工知能はどこにでもあり、急速に発展しています 私たちは、人工知能がどれほど速く発展し、広がっているかを強く認識する必要があります。人工知能システムは絶えず改善されており、数学と複雑な思考テストで優れた結果を達成しており、わずか1年前にこれらのテストで惨めに失敗しました。 2023年以来、複雑なコーディングの問題や大学院レベルの科学的問題を解決することを想像してみてください


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

