
ホームページ >データベース >mysql チュートリアル >知識の拡張: データの偏りを解決するための自己均衡テーブル分割方法
知識の拡張: データの偏りを解決するための自己均衡テーブル分割方法

- 藏色散人転載
- 2023-04-02 06:30:021501ブラウズ
この記事は、データ テーブルに関する関連知識を提供します。主に、データ スキューの問題を解決するための自己均衡テーブルの細分化方法について説明します。興味のある友人は、一緒に見てみると良いでしょう。みんなに役立つ。助けて。
1. 背景
この記事では主に、増加するビジネス データの問題を解決するための B サイド トークン システムのデータ サブテーブルの適用について説明します。ボリュームと既存のデータ スキュー 主なシナリオは 1 対多のデータ スキュー問題です。
1) B トークンのビジネス背景
最初にビジネスについて簡単に説明します。 B トークンの背景。B トークン システムは、多くのユーザーを 1 つのトークンにバインドし、そのトークンをプロモーションにバインドして差別化と正確なマーケティングを実現するためにマーケティング シナリオで使用されます。一般に、トークンのライフ サイクルはこのプロモーションと同等です。
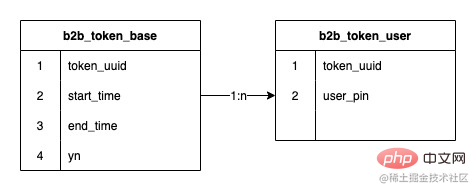
2) B サイド トークンの現在の構造
トークンとトークン ユーザーの関係は 1 対多の関係です。初期のトークン システムでは jed が使用されていました。データベースには 2 つのシャードがあり、途中で拡張が実行されて 8 シャードになり、保存されるデータ行数は 1 億 2,000 万行に達しました
3 ) データとビジネスのステータス
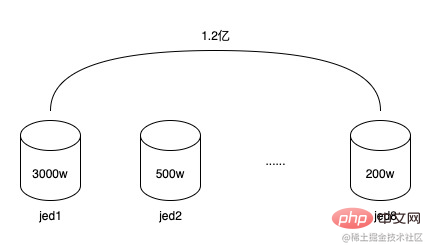
1 億 2,000 万のデータが 8 つのサブデータベースに分散され、各サブデータベースには平均 1,500 万のデータがあります。データベース フィールドはトークン ID (token_uuid) を使用します。トークン ユーザーが少なく、数千人から 10,000 人しかいないフィールドもあれば、100 万から 150 万人という多数のトークン ユーザーがいるフィールドもあります。トークンの総数はそれほど多くなく、わずか約 20,000 です。傾向としては、一部のサブデータベースには 3,000 万を超えるデータがあり、一部のサブデータベースには数百万しかない場合があり、これがデータベースの読み取りおよび書き込みパフォーマンスの低下につながり始めています。また、トークンユーザー関係テーブルのデータ構造は非常に単純であるため、データ行数は多くても、それほどスペースを必要としません。 8 つのサブデータベースの合計占有スペースは 20G 未満です。同時に、トークンのライフサイクルは基本的にプロモーションのライフサイクルと同じであり、トークンは 1 つまたは複数のプロモーションに提供された後、ゆっくりと有効期限が切れて破棄され、将来的には新しいトークンが作成され続けます。したがって、これらの期限切れのトークンはアーカイブできます。
一方で、Bサイドビジネスの発展に伴い、ビジネスニーズも増加しており、ビジネスとのコミュニケーションを通じて、将来的には自動選考システムが開始されることを知りました。トークンを自動生成し、昇進に適した人材を選出 将来的には月間データ増加量は約3,000万、1年間運用すると3億6,000万増加、その頃には1テーブルの平均データ量は60に達する現在の設計アーキテクチャでは、ビジネス ニーズを完全に満たすことができません。
同時にページ内でトークン配下のユーザーをトークンIDに基づいて問い合わせる機能もありますが、これは管理側の操作のみに使用され、頻繁に使用されるものではありません。
2. 解決策についての考え方
1) この問題の解決方法
データベースの読み書きパフォーマンスの低下に直面する、ビジネスの成長ニーズに加えて、現在、次の問題に直面しています:
単一テーブル内のデータ行が多すぎる問題を解決する方法
-
現在のサブデータベース スキームには深刻なデータ スキューがあります
将来のデータ増加に対処する場合
2) 調査および技術的ソリューションの比較
a. データベース テーブルのパーティショニング
一般的に、最初の問題に対処するには、通常、データベースをテーブルに分割する必要があります。 、現在 8 つのパーティションがあります。データベース、および 8 つのサブデータベースが占有するスペースは 20G 未満です。単一データベースのリソースは大幅に浪費されるため、サブデータベースを追加することはまったく検討されません。そのため、テーブル シャーディングが最適です。解決。
データをテーブルに分割するには、通常、垂直テーブルと水平テーブルの 2 つの方法があります。
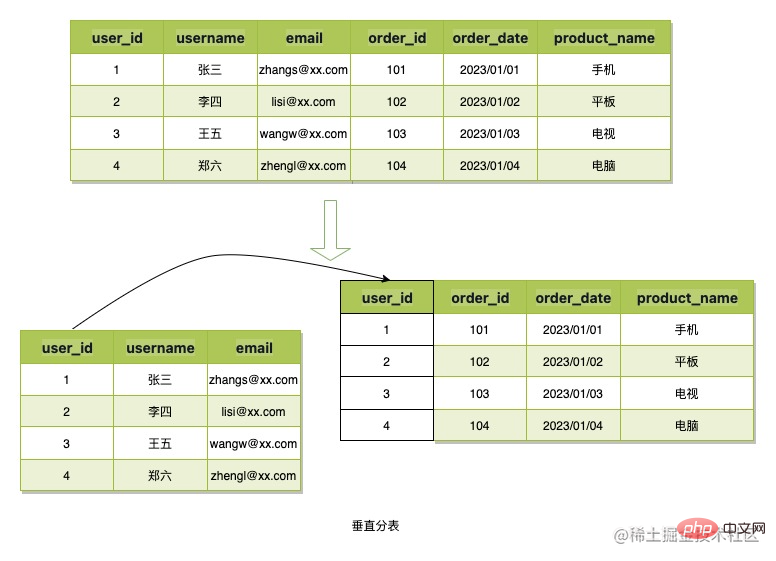
テーブルの垂直分割とは、データの列を分割し、主キーまたはその他のビジネス フィールドを適用してそれらを関連付けることを指します。これにより、単一のテーブル データが占有するスペースを削減したり、冗長性を削減したりできます。残りのストレージの場合、B トークンのシーン データ構造は単純であり、データの占有スペースがほとんどないため、このテーブル分割方法は使用されません。
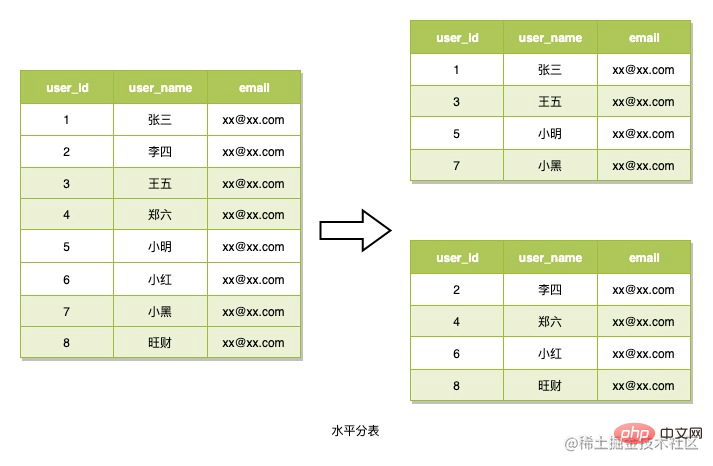
水平テーブル分割とは、ルーティング アルゴリズムを使用してデータ行を複数のテーブルに分割することを指します。データは、読み取り時にもこのルーティング アルゴリズムに基づいて読み取られます。このテーブル パーティション化戦略は一般に、データ構造は複雑ではないが、多数のデータ行があるシナリオに対処するために使用されます。これを使用します。この方法を使用する際に考慮する必要があるのは、ルーティングのアルゴリズムをどのように設計するかですが、ここでもテーブルの分割にこの方法が使用されています。
b. ルーティング アルゴリズム
業界ではデータ テーブル ルーティング アルゴリズムを使用する方法がたくさんあります。1 つは、一貫性ハッシュを使用する方法で、適切なサブテーブル フィールドについては、フィールド値をハッシュした後の値が固定されており、この値を使用してモジュロ演算またはビット単位の演算を通じて固定シリアル番号を取得し、データがどのテーブルに格納されるかを決定します。
サブライブラリなどの一般的なアプリケーションの多くはコンシステントハッシュを使用しており、サブライブラリフィールドの値を瞬時に計算することでデータがどのサブライブラリに属するかを判断し、どのサブライブラリに保存するかを決定します。データ内のデータ、またはデータからのデータの読み取り。クエリ中にサブデータベース フィールドが指定されていない場合は、クエリ要求をすべてのサブデータベースに同時に送信する必要があり、最後に結果が要約されます。
また、Java コードのような HashMap のデータ構造は、実際には一貫性のあるハッシュ アルゴリズムのテーブル分割戦略であり、キーをハッシュすることによって、データが配列に格納されるシリアル番号が決定されます。 HashMap で使用されるはモジュロではありません。シリアル番号を取得する代わりに、ビット単位の演算が使用されます。このメソッドは、HashMap の拡張が 2 の x 乗のサイズに基づいていることも決定します。この原理は、将来の機会。
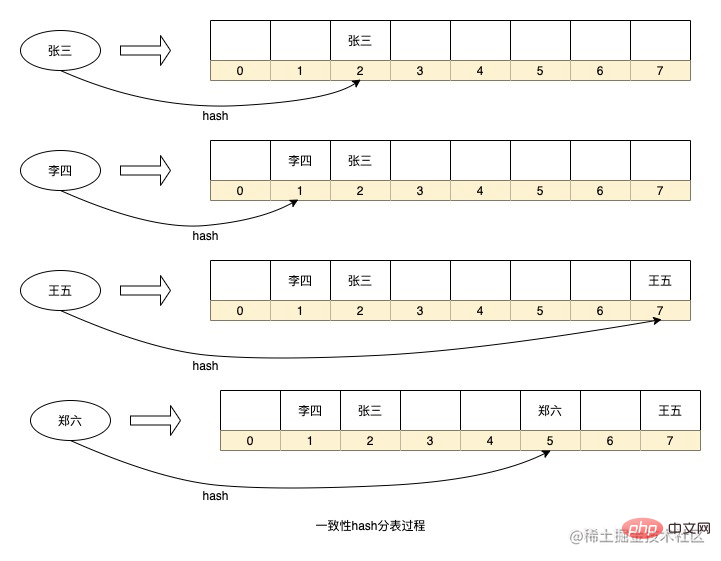
上記は、HashMap でのデータ ハッシュの保存プロセスを簡略化したものです。もちろん、一部の詳細は省略しています。たとえば、HashMap の各ノードはリンクされたリストです (多すぎます)衝突が起こると赤黒の木になります)。このシナリオに適用すると、各シリアル番号をデータ テーブルとみなすことができます。
上記のルーティング アルゴリズムの利点は、ルーティング戦略がシンプルであり、リアルタイム計算のために追加のストレージ領域を追加する必要がないことですが、拡張したい場合には問題もあります。容量を増やすには、データベースのパーティション化など、移行のために履歴データを再ハッシュする必要があります。ライブラリがサブデータベースを追加する場合、すべてのデータをサブデータベースに再計算する必要があります。HashMap の拡張では、シーケンス番号を再計算するための再ハッシュも実行されます。配列内のキーの。データ量が多すぎると、この計算処理に時間がかかります。同時に、データ テーブルが少なすぎる場合、またはシャーディング用に選択されたフィールドの離散性が低い場合は、データ スキューが発生します。
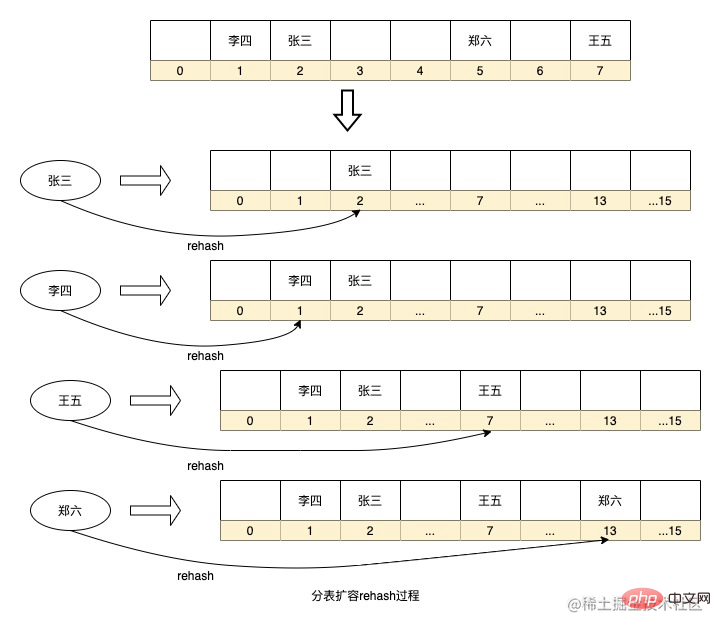
この再ハッシュ プロセスを最適化するテーブル分割アルゴリズムもあります。これは一貫性のあるハッシュ リングです。このメソッドは、エンティティ ノード間の多くの仮想ノードを抽象化します。その後、一貫したハッシュ アルゴリズムを使用してこれらの仮想ノード上のデータをヒットし、各エンティティ ノードは実際には、エンティティ ノードの反時計回り方向で他のエンティティ ノードに隣接する仮想ノードのデータを担当します。この方法の利点は、容量を拡張してノードを追加する必要がある場合、追加されたノードはリング上の任意の場所に配置され、ノードの時計回り方向に隣接するノードのデータにのみ影響を与えることです。ノード内のデータは、この新しいノードにインストールするだけで移行する必要があるため、再ハッシュ プロセスが大幅に削減されます。同時に、仮想ノードの数が多いため、データをリング上でより均等に分散することもでき、物理ノードが適切な場所に配置されている限り、データのスキューの問題は最大限に解決できます。
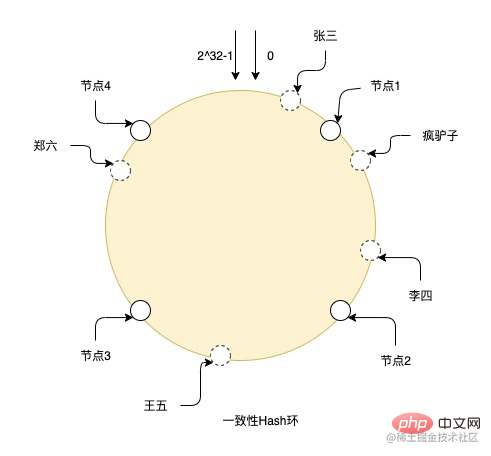
たとえば、図は一貫性のあるハッシュ リングのハッシュ プロセスを示しています。リング全体には 0 から 2^32-1 までのノードがあり、実線はが本物のノードで、他はすべて仮想ノードです。Zhang San はハッシュによってリング上の仮想ノードに落ち、仮想ノードの位置から時計回りに実ノードを探します。最終的なデータは、実ノードなので、Crazy Donkey と Li Si ストアがノード 2 にあり、Wang Wu はノード 3 に、Zheng Liu はノード 4 にあります。
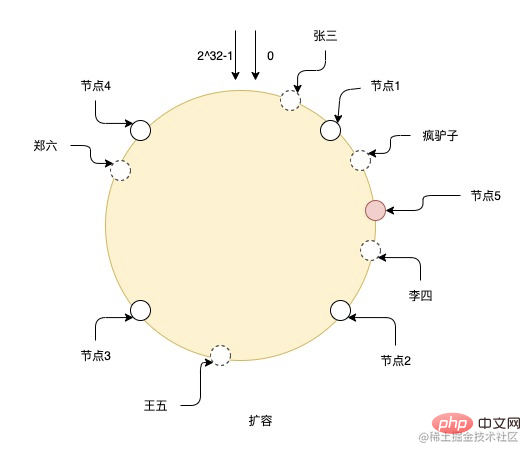
ノード 5 の容量を拡張した後、ノード 1 とノード 5 の間のデータをノード 5 に移行する必要があります。他のノードのデータは移行する必要はありません。かわった。ただし、図からわかるように、この 1 つのノードだけを追加すると、各ノードが担当するデータが不均等になる可能性が高くなります。たとえば、ノード 2 とノード 5 は他のノードよりもはるかに少ないデータを担当するため、データが均一な状態を維持できるように、容量を指数関数的に拡張することが最善です。
#3) 計画について考える
B トークンのビジネス シナリオに戻ると、次の要求を達成できる必要があります- まず、単一テーブル内の過剰なデータ量の問題を解決するには、水平テーブル シャーディングを使用する必要があります。
- に基づいてユーザーのページング クエリをサポートする必要があります。トークン
- 現在のビジネス データの増分は 3,000 万ですが、将来的にビジネスが継続的に成長する可能性が排除されないため、サブテーブルの数はサポートできる必要があります。将来の拡張
- データ行の数が多すぎるため、将来拡張される予定です。データ移行の必要がないこと、またはデータ移行のコストが低いことを確認する必要があります。 #単一テーブル内の過剰なデータ量によって全体のパフォーマンスが低下しないように、データ スキューの問題を解決する必要があります
- 上記のリクエストに基づいて、最初に質問 b を見てください。トークンに基づいてユーザーのページング クエリをサポートしたい場合は、単にページング クエリをサポートするために、トークンの下にあるすべてのユーザーが同じテーブル上にあることを確認する必要があります。それ以外の場合は、一部を使用する 要約とマージのアルゴリズムが複雑すぎるため、テーブルが多すぎるとクエリのパフォーマンスが低下します。データ異種を利用してクエリ機能を提供することもできますが、データ異種化を行うのは少数の管理側クエリリクエストに対してのみであり、コストが高く、メリットが分かりにくく、無駄でもあります。リソース。したがって、サブテーブルフィールドはトークン ID を使用してのみ決定できます。
前述のように、トークン ID の数は多くなく、トークンに含まれるユーザー数は 10,000 ~ 100 万の範囲です。単純に整合性ハッシュを使用し、サブテーブル戦略としてトークン ID を使用すると、データ スキューが発生します。は深刻であり、将来の拡張時にデータ移行コストも高額になります。
ただし、一貫したハッシュ リングを使用すると、将来 2 の倍数で最適な拡張が可能になります。そうでない場合、一部のノードはより多くの仮想ノードを担当し、一部のノードはより少ない仮想ノードを担当することになります。 、結果としてデータは不均等になります。ただし、データベースの同僚と通信する場合、1 つのデータベース内のデータ テーブルの数が多すぎないように注意してください。そうしないと、データベースに大きな負荷がかかります。コンシステント ハッシュ リング方式では、容量が 2 ~ 3 倍に拡張される可能性があり、 1 に達するまでのサブテーブルの数。非常に高い値。
上記の問題を踏まえ、トークン ID をサブテーブルとして使用することを決定する前提で、動的拡張をサポートし、データ スキューの問題を解決する方法に焦点を当てる必要があります 。
3. 計画の実施
1) 計画の概要
a. 支援方法動的拡張
サブテーブルのフィールドはトークン ID を使用するように決定されています。前述したように、データ構造はトークンとユーザー間の 1 対多の関係です。 -テーブルはトークンの作成時にハッシュ化されます。シリアル番号が保存され、その後のルーティングはサブテーブルの保存されたシリアル番号に基づいて実行されます。これにより、将来の拡張が既存のデータのルーティングに影響を与えず、データを必要としないことが保証されます。移住。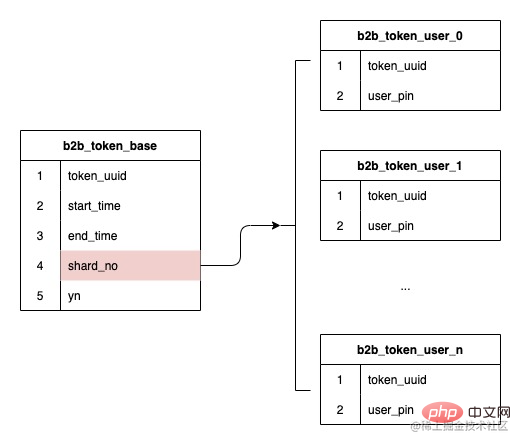
b. データの偏りを解決する方法
サブテーブルのフィールドとしてトークン ID が選択されているため、トークン ID の量は各トークンのデータ サイズが異なると、データの偏りが大きな問題になります。そこでここでは、サブメーター水位の概念を導入してみます。
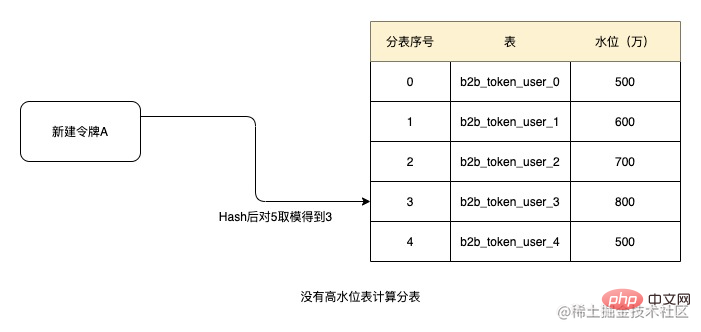
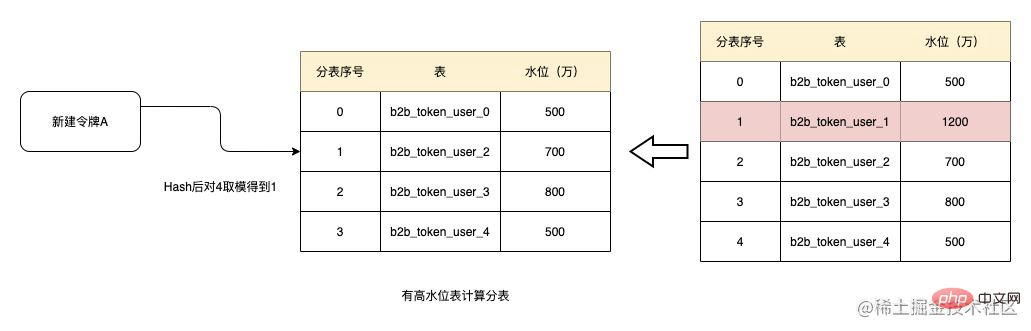
c. サブテーブルの水位を下げるための定期的なデータ アーカイブ
テーブル内のデータ量が減少せずに増加し続ける場合は、遅かれ早かれ、すべてのテーブルが高い水位に達し、動的な効果を実現できなくなります。上記の背景で述べたように、トークンは特定のプロモーションを提供するために作成されます。プロモーションが終了すると、トークンはその効力を失います。同時に、トークンには有効期限があり、期限を超えたトークンは無効になります。有効期限が切れると、その効力も失われます。したがって、データを定期的にアーカイブすると、水位が高いテーブルの水位をゆっくりと下げて、サブテーブルに再び参加できるようになります。 そして、現在のトークンはすでに b2b_token_user テーブルに存在しており、その中に 1 億 2,000 万のデータがあります。このテーブルを図のテーブル 0 として使用できるため、初めてオンラインに接続するときに必要なのは、履歴コマンドを変更する Paidu のサブテーブルのシリアル番号は 0 として記録でき、既存のデータを移行する必要はありませんが、このテーブルのデータ量が多い場合はサブテーブルに参加しません。定期的なデータのアーカイブと組み合わせることで、テーブルの水位は徐々に下がっていきます。d. 監視メカニズム
定期的なデータ アーカイブによりテーブルの水位を下げることができますが、ビジネスの発展に伴い、ほとんどのテーブルが存在する可能性があります。レベル、およびすべてが有効なデータの場合です。このとき、HashMapと同様にシステムが容量が75%に達したと判断すると自動で拡張しますテーブルを自動作成することはできませんが、テーブルの75%が高水位に入るとアラームが発せられます開発者は監視します警報を鳴らして手動で介入する 観測には調整が必要である 水位が高い場合はテーブルを拡張した方がよい3) 不十分さ
•水位閾値と容量拡張の監視
現在、水位のしきい値は依然として手動設定に依存しています。どのくらいの大きさに設定すべきかは非常に感情的です。設定できるのは 1 つだけで、アラーム後に適切に調整できます。しかし、実際には、システムはインターフェイスの読み取りおよび書き込みパフォーマンスの変動を自動的に監視することができ、ほとんどの式が高いレベルに達しても、インターフェイスの読み取りおよび書き込みパフォーマンスは大きく変化しないことがわかります。自動的にしきい値を増やしてスマートなしきい値を形成します。
インターフェイスの読み取りおよび書き込みパフォーマンスが大幅に変化し、ほとんどのテーブルがしきい値に達していることが判明した場合、容量拡張を検討する必要があることを示すアラームが発行されます。
4. まとめ
問題を解決する特効薬はありません。手元にある技術的手段とツールを使用して、それらを組み合わせ、適応させて問題を解決する必要があります。ビジネスやシナリオには、良い悪いはなく、向いているか向いていないだけです。
以上が知識の拡張: データの偏りを解決するための自己均衡テーブル分割方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。