
ホームページ >ウェブフロントエンド >jsチュートリアル >画像圧縮にNodeを使用する方法
画像圧縮にNodeを使用する方法

- 青灯夜游転載
- 2023-03-20 18:22:482381ブラウズ
Node を画像圧縮に使用するにはどうすればよいですか?以下の記事ではPNG画像を例に画像の圧縮方法を紹介していますので、ぜひ参考にしてください。

#最近、画像処理サービスを提供したいと考えています。その 1 つは、画像圧縮機能を実装することです。以前はフロントエンドを開発する場合、canvas の既製 API を使って処理できましたが、バックエンドにも既製 API があるかもしれませんが、わかりません。よくよく考えてみると、私は画像圧縮の原理を詳しく理解したことがなかったので、この機会にちょっと調べて勉強してみようと思ったので、記録としてこの記事を書きました。いつものように、何か問題があれば、DDDD(兄弟を連れて行きましょう)。
最初に画像をバックエンドにアップロードし、バックエンドがどのようなパラメーターを受け取るかを確認します。ここではバックエンドとして Node.js (Nest) を使用し、例として PNG 画像を使用します。
インターフェイスとパラメータは次のように出力されます。
@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> <br/> return {<br/> file<br/> }<br/>}<br/>
圧縮するには、画像データを取得する必要があります。ご覧のとおり、画像データを非表示にできるのはこのバッファーだけです。では、このバッファーの文字列は何を表しているのでしょうか? まず、PNG が何なのかを理解する必要があります。 [関連チュートリアルの推奨事項: nodejs ビデオ チュートリアル 、プログラミング教育 ]
PNG
これは です。 PNG WIKI のアドレス。
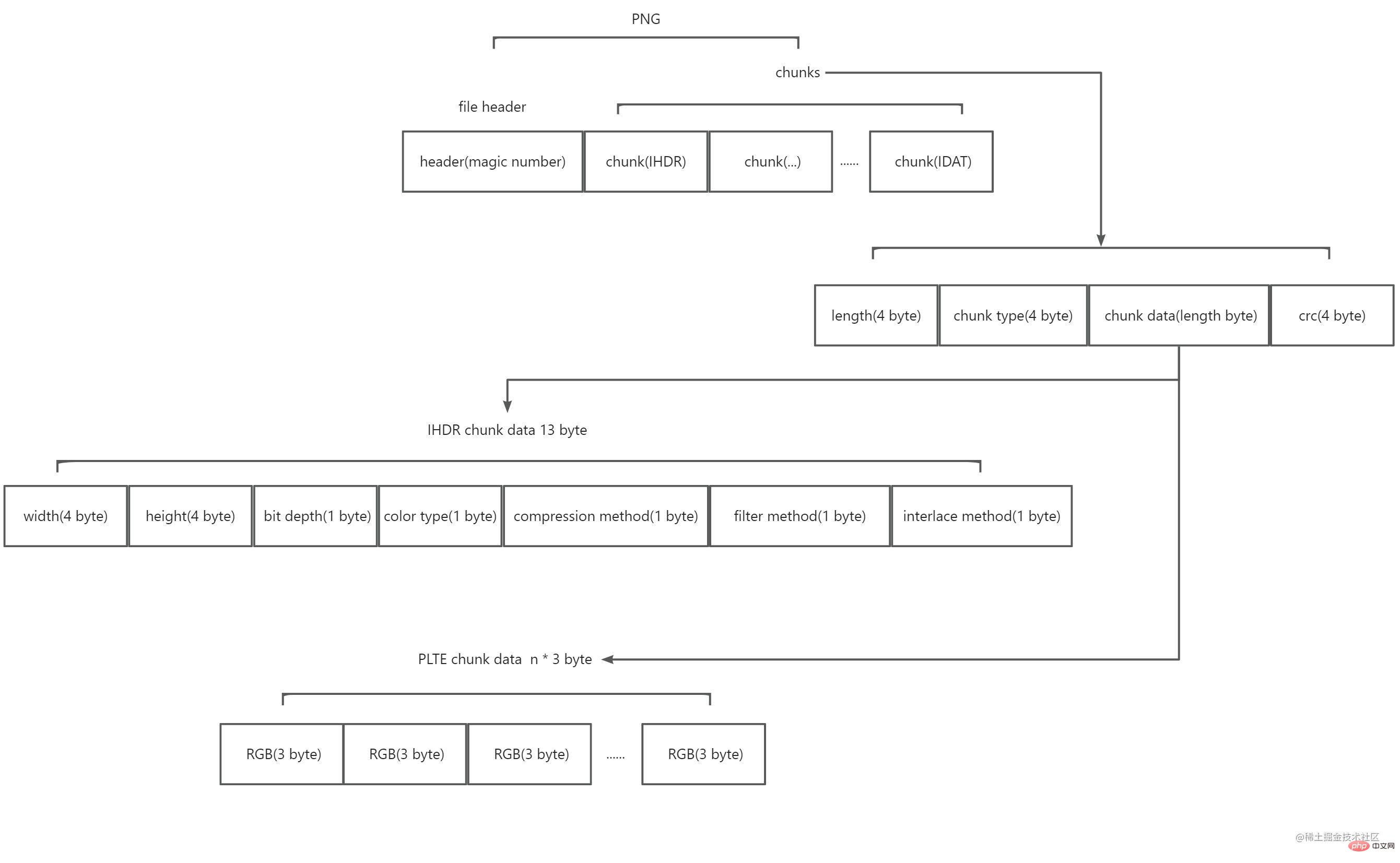
読んだ後、PNG は 8 バイトのファイル ヘッダーと複数のチャンクで構成されていることがわかりました。概略図は次のとおりです。
そのうち:
ファイルヘッダーは、いわゆるマジックナンバーで構成されています。値は 89 50 4e 47 0d 0a 1a 0a (16 進数) です。このデータ文字列を PNG 形式としてマークします。
チャンクは 2 種類に分けられ、1 つは クリティカル チャンク (クリティカル チャンク) と呼ばれ、もう 1 つは 補助チャンク (補助チャンク) と呼ばれます。キーブロックは必須であり、キーブロックがないとデコーダは画像を正しく識別して表示することができません。補助ブロックはオプションであり、一部のソフトウェアは画像処理後に補助ブロックを搭載する場合があります。各ブロックは 4 つの部分で構成されます。4 バイトはこのブロックの内容の長さを表し、4 バイトはこのブロックのタイプを表し、n バイトはブロックの内容を表します (n は前の 4 バイト値のサイズ、つまり、ブロックの最大長は 28*4) で、4 バイトの CRC チェックによってブロックのデータがチェックされ、ブロックの終わりがマークされます。このうち、ブロックタイプの4バイトの値は4つのacsiiコードであり、先頭文字の大文字のはキーブロックであることを意味し、小文字のは補助ブロック#であることを意味します##; 2 番目の文字 大文字はパブリック 、 小文字はプライベート を意味します。3 番目の文字 は大文字の にする必要があり、これはその後の PNG の展開に使用されます。文字はブロックが認識されない場合、安全にコピーできるかどうかを意味し、大文字はキーブロックが変更されていない場合にのみ安全にコピーできることを意味し、小文字は安全にコピーできることを意味します。 PNG は公式に多くの定義されたブロック タイプを提供します。ここで知っておく必要があるのは、IHDR、PLTE、IDAT、および IEND という主要なブロック タイプだけです。
IHDR
PNG では、最初のブロックが IHDR である必要があります。 IHDR のブロック内容は 13 バイトに固定されており、画像の次の情報が含まれます:
幅 (4 バイト) & 高さ (4 バイト)ビット深さ (1 バイト、値)は 1、2、4、8、または 16) & カラータイプ カラータイプ (1 バイト、値は 0、2、3、4、または 6)圧縮方法 圧縮方法 (1 バイト、値は0 ) & filter メソッド filter メソッド (1 バイト、値は 0)Interlace メソッド interlace メソッド (1 バイト、値は 0 または 1)幅と高さは簡単に設定できます。理解する、その他 いくつかの項目は馴染みがないと思われるので、次に説明します。 ビット深度を説明する前に、まず色の種類を見てみましょう。色の種類には 5 つの値があります:- 0 は 1 つのチャネルのみを持つグレースケール (グレースケール) を意味します(チャンネル) を rgb として見ると、その 3 色のチャンネル値が等しいことが理解できるため、それを表すために 2 つ以上のチャンネルは必要ありません。
- 2 は、R (赤)、G (緑)、B (青) の 3 つのチャネルを持つ実際の色 (rgb) を表します。
3 はカラー インデックス (インデックス付き) を表します。また、色のインデックス値を表すチャネルが 1 つだけあります。このタイプには多くの場合、カラー リストのセットが装備されており、インデックス値とカラー リストのクエリに基づいて特定の色が取得されます。
4 はグレースケールとアルファを表します。これには 2 つのチャネルがあります。グレースケール チャネルに加えて、透明度を制御する追加のアルファ チャネルがあります。
6 は、実際の色と 4 つのチャネルを持つアルファを表します。
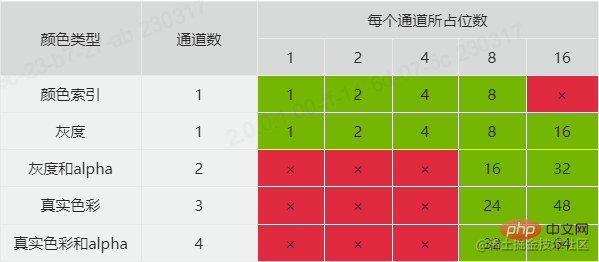
チャネルについて説明する理由は、ここでのビット深度に関連しているためです。ビット深度の値は、各チャネルが占めるビット数を定義します。ビット深度とカラータイプを組み合わせることで、画像のカラーフォーマットタイプと各ピクセルが占有するメモリサイズを知ることができます。 PNG で公式にサポートされている組み合わせは次のとおりです。
フィルタリングと圧縮は、PNG に保存されるのは画像の元のデータではなく、処理されたデータであるためです。 PNG 画像はメモリ使用量が小さいためです。 PNG では、2 つの手順を使用して画像データを圧縮および変換します。
最初のステップはフィルタリングです。フィルタリングの目的は、元の画像データがルールを通過した後に、より高い圧縮率を達成できるようにすることです。たとえば、左から右に色が [#000000, #000001, #000002, ..., #ffffff] であるグラデーション画像がある場合、右側のピクセルは常に同じです。前の左のピクセルと比較すると、処理されたデータは [1, 1, 1, ..., 1] になります。これにより、圧縮率が向上しますか?現在、PNG にはフィルタリング方法が 1 つしかありません。これは、隣接するピクセルを予測値としてベースにし、現在のピクセルから予測値を減算するものです。フィルタリングには 5 つのタイプがあります (現時点では、このタイプの値がどこに格納されているかはわかりません。IDAT にある可能性があります。見つかった場合は、この括弧内の を削除してください。このタイプは、このタイプであると判断されています)の値は IDAT データに保存されます) 次の表に示すように:
| Type byte | Filter name | 予測値 |
|---|---|---|
| 0 | なし | 処理なし |
| 1 | Sub | 左の隣接ピクセル |
| 2 | Up | 上の隣接ピクセル |
| 3 | Average | Math.floor((左隣のピクセルの上の隣接ピクセル) / 2) |
| #4 | Paeth | (左隣のピクセルの上の隣ピクセル - 左上のピクセル)に最も近い値を取得します |
第二步,压缩。PNG也只有一种压缩算法,使用的是DEFLATE算法。这里不细说,具体看下面的章节。
交错方式,有两种值。0表示不处理,1表示使用Adam7 算法进行处理。我没有去详细了解该算法,简单来说,当值为0时,图片需要所有数据都加载完毕时,图片才会显示。而值为1时,Adam7会把图片划分多个区域,每个区域逐级加载,显示效果会有所优化,但通常会降低压缩效率。加载过程可以看下面这张gif图。

PLTE
PLTE的块内容为一组颜色列表,当颜色类型为颜色索引时需要配置。值得注意的是,颜色列表中的颜色一定是每个通道8bit,每个像素24bit的真实色彩列表。列表的长度,可以比位深约定的少,但不能多。比如位深是2,那么22,最多4种颜色,列表长度可以为3,但不能为5。
IDAT
IDAT的块内容是图片原始数据经过PNG压缩转换后的数据,它可能有多个重复的块,但必须是连续的,并且只有当上一个块填充满时,才会有下一个块。
IEND
IEND的块内容为0 byte,它表示图片的结束。
阅读到这里,我们把上面的接口改造一下,解析这串buffer。
@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> const buffer = file.buffer;<br/><br/> const result = {<br/> header: buffer.subarray(0, 8).toString('hex'),<br/> chunks: [],<br/> size: file.size,<br/> };<br/><br/> let pointer = 8;<br/> while (pointer < buffer.length) {<br/> let chunk = {};<br/> const length = parseInt(buffer.subarray(pointer, pointer + 4).toString('hex'), 16);<br/> const chunkType = buffer.subarray(pointer + 4, pointer + 8).toString('ascii');<br/> const crc = buffer.subarray(pointer + length, pointer + length + 4).toString('hex');<br/> chunk = {<br/> ...chunk,<br/> length,<br/> chunkType,<br/> crc,<br/> };<br/><br/> switch (chunkType) {<br/> case 'IHDR':<br/> const width = parseInt(buffer.subarray(pointer + 8, pointer + 12).toString('hex'), 16);<br/> const height = parseInt(buffer.subarray(pointer + 12, pointer + 16).toString('hex'), 16);<br/> const bitDepth = parseInt(<br/> buffer.subarray(pointer + 16, pointer + 17).toString('hex'),<br/> 16,<br/> );<br/> const colorType = parseInt(<br/> buffer.subarray(pointer + 17, pointer + 18).toString('hex'),<br/> 16,<br/> );<br/> const compressionMethod = parseInt(<br/> buffer.subarray(pointer + 18, pointer + 19).toString('hex'),<br/> 16,<br/> );<br/> const filterMethod = parseInt(<br/> buffer.subarray(pointer + 19, pointer + 20).toString('hex'),<br/> 16,<br/> );<br/> const interlaceMethod = parseInt(<br/> buffer.subarray(pointer + 20, pointer + 21).toString('hex'),<br/> 16,<br/> );<br/><br/> chunk = {<br/> ...chunk,<br/> width,<br/> height,<br/> bitDepth,<br/> colorType,<br/> compressionMethod,<br/> filterMethod,<br/> interlaceMethod,<br/> };<br/> break;<br/> case 'PLTE':<br/> const colorList = [];<br/> const colorListStr = buffer.subarray(pointer + 8, pointer + 8 + length).toString('hex');<br/> for (let i = 0; i < colorListStr.length; i += 6) {<br/> colorList.push(colorListStr.slice(i, i + 6));<br/> }<br/> chunk = {<br/> ...chunk,<br/> colorList,<br/> };<br/> break;<br/> default:<br/> break;<br/> }<br/> result.chunks.push(chunk);<br/> pointer = pointer + 4 + 4 + length + 4;<br/> }<br/><br/> return result;<br/>}<br/>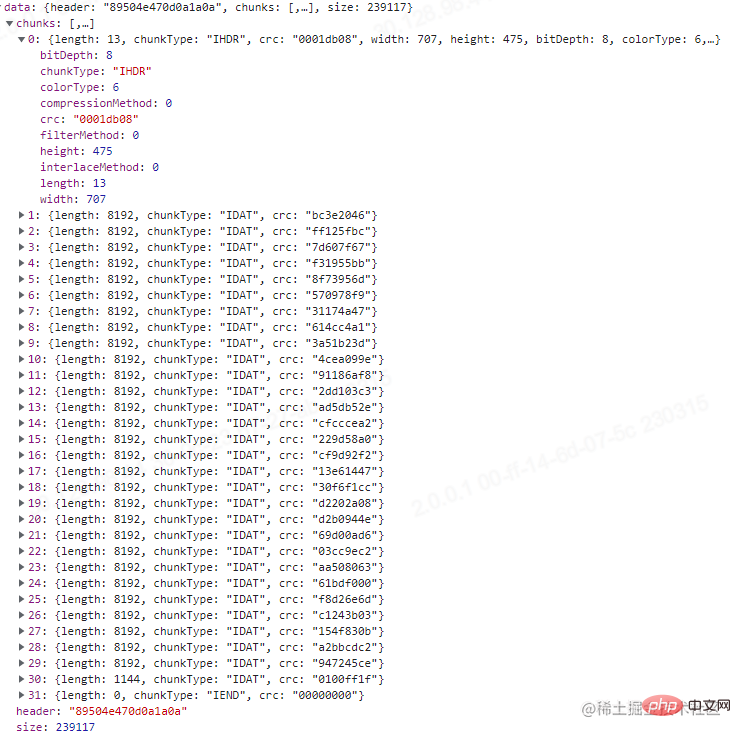
这里我测试用的图没有PLTE,刚好我去TinyPNG压缩我那张测试图之后进行上传,发现有PLTE块,可以看一下,结果如下图。
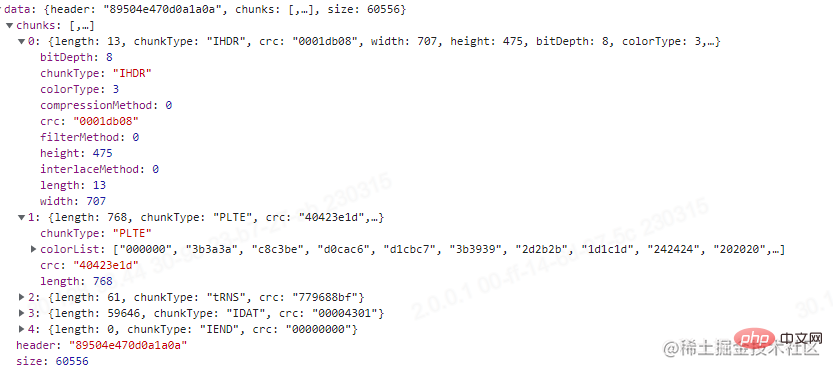
通过比对这两张图,压缩图片的方式我们也能窥探一二。
PNG的压缩
前面说过,PNG使用的是一种叫DEFLATE的无损压缩算法,它是Huffman Coding跟LZ77的结合。除了PNG,我们经常使用的压缩文件,.zip,.gzip也是使用的这种算法(7zip算法有更高的压缩比,也可以了解下)。要了解DEFLATE,我们首先要了解Huffman Coding和LZ77。
Huffman Coding
哈夫曼编码忘记在大学的哪门课接触过了,它是一种根据字符出现频率,用最少的字符替换出现频率最高的字符,最终降低平均字符长度的算法。
举个例子,有字符串"ABCBCABABADA",如果按照正常空间存储,所占内存大小为12 * 8bit = 96bit,现对它进行哈夫曼编码。
1.统计每个字符出现的频率,得到A 5次 B 4次 C 2次 D 1次
2.对字符按照频率从小到大排序,将得到一个队列D1,C2,B4,A5
3.按顺序构造哈夫曼树,先构造一个空节点,最小频率的字符分给该节点的左侧,倒数第二频率的字符分给右侧,然后将频率相加的值赋值给该节点。接着用赋值后节点的值和倒数第三频率的字符进行比较,较小的值总是分配在左侧,较大的值总是分配在右侧,依次类推,直到队列结束,最后把最大频率和前面的所有值相加赋值给根节点,得到一棵完整的哈夫曼树。
4.对每条路径进行赋值,左侧路径赋值为0,右侧路径赋值为1。从根节点到叶子节点,进行遍历,遍历的结果就是该字符编码后的二进制表示,得到:A(0)B(11)C(101)D(100)。
完整的哈夫曼树如下(忽略箭头,没找到连线- -!):
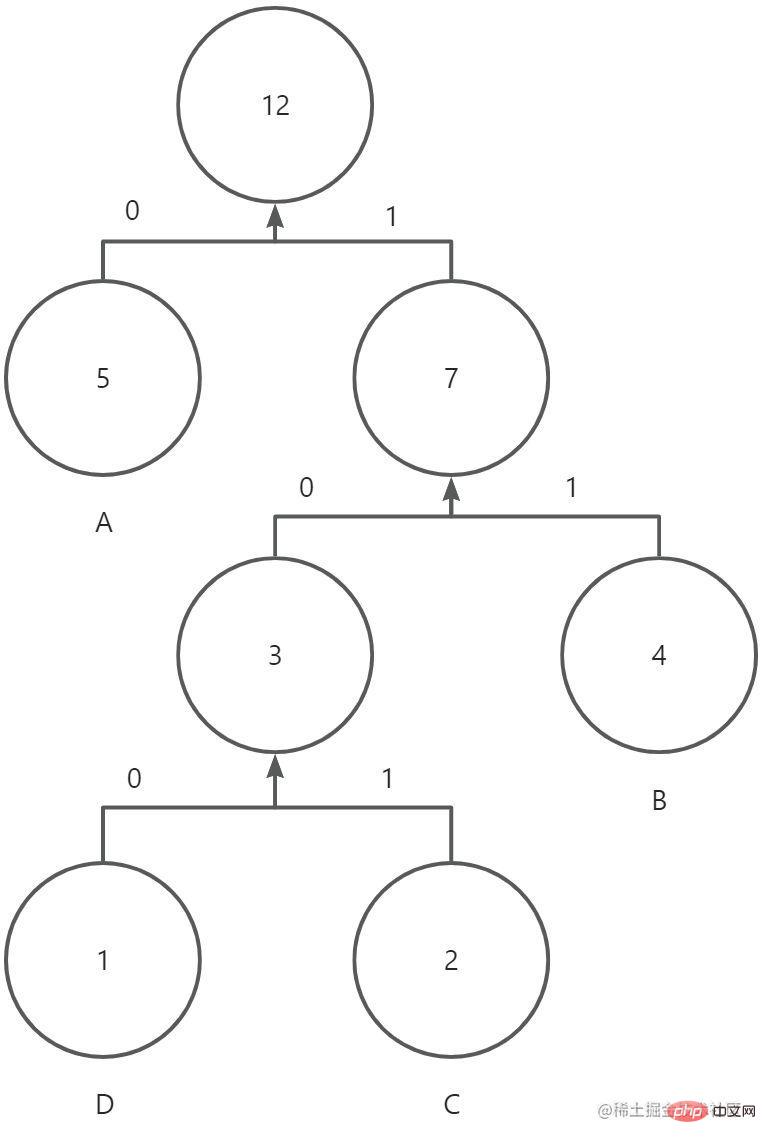
压缩后的字符串,所占内存大小为5 * 1bit + 4 * 2bit + 2 * 3bit + 1 * 3bit = 22bit。当然在实际传输过程中,还需要把编码表的信息(原始字符和出现频率)带上。因此最终占比大小为 4 * 8bit + 4 * 3bit(频率最大值为5,3bit可以表示)+ 22bit = 66bit(理想状态),小于原有的96bit。
LZ77
LZ77算法还是第一次知道,查了一下是一种基于字典和滑动窗的无所压缩算法。(题外话:因为Lempel和Ziv在1977年提出的算法,所以叫LZ77,哈哈哈?)
我们还是以上面这个字符串"ABCBCABABADA"为例,现假设有一个4 byte的动态窗口和一个2byte的预读缓冲区,然后对它进行LZ77算法压缩,过程顺序从上往下,示意图如下:

总结下来,就是预读缓冲区在动态窗口中找到最长相同项,然后用长度较短的标记来替代这个相同项,从而实现压缩。从上图也可以看出,压缩比跟动态窗口的大小,预读缓冲区的大小和被压缩数据的重复度有关。
DEFLATE
DEFLATE【RFC 1951】是先使用LZ77编码,对编码后的结果在进行哈夫曼编码。我们这里不去讨论具体的实现方法,直接使用其推荐库Zlib,刚好Node.js内置了对Zlib的支持。接下来我们继续改造上面那个接口,如下:
import * as zlib from 'zlib';<br/><br/>@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> const buffer = file.buffer;<br/><br/> const result = {<br/> header: buffer.subarray(0, 8).toString('hex'),<br/> chunks: [],<br/> size: file.size,<br/> };<br/><br/> // 因为可能有多个IDAT的块 需要个数组缓存最后拼接起来<br/> const fileChunkDatas = [];<br/> let pointer = 8;<br/> while (pointer < buffer.length) {<br/> let chunk = {};<br/> const length = parseInt(buffer.subarray(pointer, pointer + 4).toString('hex'), 16);<br/> const chunkType = buffer.subarray(pointer + 4, pointer + 8).toString('ascii');<br/> const crc = buffer.subarray(pointer + length, pointer + length + 4).toString('hex');<br/> chunk = {<br/> ...chunk,<br/> length,<br/> chunkType,<br/> crc,<br/> };<br/><br/> switch (chunkType) {<br/> case 'IHDR':<br/> const width = parseInt(buffer.subarray(pointer + 8, pointer + 12).toString('hex'), 16);<br/> const height = parseInt(buffer.subarray(pointer + 12, pointer + 16).toString('hex'), 16);<br/> const bitDepth = parseInt(<br/> buffer.subarray(pointer + 16, pointer + 17).toString('hex'),<br/> 16,<br/> );<br/> const colorType = parseInt(<br/> buffer.subarray(pointer + 17, pointer + 18).toString('hex'),<br/> 16,<br/> );<br/> const compressionMethod = parseInt(<br/> buffer.subarray(pointer + 18, pointer + 19).toString('hex'),<br/> 16,<br/> );<br/> const filterMethod = parseInt(<br/> buffer.subarray(pointer + 19, pointer + 20).toString('hex'),<br/> 16,<br/> );<br/> const interlaceMethod = parseInt(<br/> buffer.subarray(pointer + 20, pointer + 21).toString('hex'),<br/> 16,<br/> );<br/><br/> chunk = {<br/> ...chunk,<br/> width,<br/> height,<br/> bitDepth,<br/> colorType,<br/> compressionMethod,<br/> filterMethod,<br/> interlaceMethod,<br/> };<br/> break;<br/> case 'PLTE':<br/> const colorList = [];<br/> const colorListStr = buffer.subarray(pointer + 8, pointer + 8 + length).toString('hex');<br/> for (let i = 0; i < colorListStr.length; i += 6) {<br/> colorList.push(colorListStr.slice(i, i + 6));<br/> }<br/> chunk = {<br/> ...chunk,<br/> colorList,<br/> };<br/> break;<br/> case 'IDAT':<br/> fileChunkDatas.push(buffer.subarray(pointer + 8, pointer + 8 + length));<br/> break;<br/> default:<br/> break;<br/> }<br/> result.chunks.push(chunk);<br/> pointer = pointer + 4 + 4 + length + 4;<br/> }<br/><br/> const originFileData = zlib.unzipSync(Buffer.concat(fileChunkDatas));<br/><br/> // 这里原图片数据太长了 我就只打印了长度<br/> return {<br/> ...result,<br/> originFileData: originFileData.length,<br/> };<br/>}<br/>
最终打印的结果,我们需要注意红框的那几个部分。可以看到上图,位深和颜色类型决定了每个像素由4 byte组成,然后由于过滤方式的存在,会在每行的第一个字节进行标记。因此该图的原始数据所占大小为:707 * 475 * 4 byte + 475 * 1 byte = 1343775 byte。正好是我们打印的结果。
我们也可以试试之前TinyPNG压缩后的图,如下:
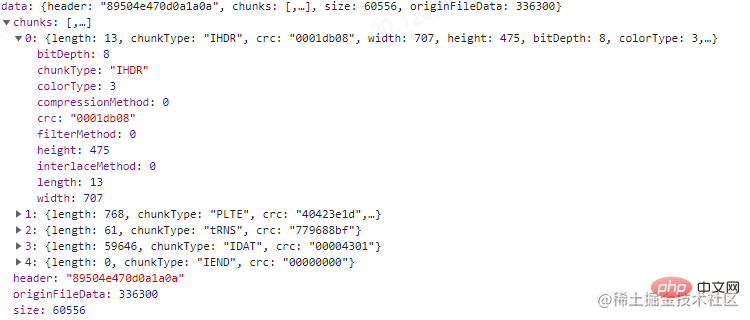
可以看到位深为8,索引颜色类型的图每像素占1 byte。计算得到:707 * 475 * 1 byte + 475 * 1 byte = 336300 byte。结果也正确。
总结
现在再看如何进行图片压缩,你可能很容易得到下面几个结论:
1.减少不必要的辅助块信息,因为辅助块对PNG图片而言并不是必须的。
2.减少IDAT的块数,因为每多一个IDAT的块,就多余了12 byte。
3.降低每个像素所占的内存大小,比如当前是4通道8位深的图片,可以统计整个图片色域,得到色阶表,设置索引颜色类型,降低通道从而降低每个像素的内存大小。
4.等等....
至于JPEG,WEBP等等格式图片,有机会再看。溜了溜了~(还是使用现成的库处理压缩吧)。
好久没写文章,写完才发现语雀不能免费共享,发在这里吧。
更多node相关知识,请访问:nodejs 教程!
以上が画像圧縮にNodeを使用する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。