
Golangを使ってBingの壁紙をクロールする方法を詳しく解説

- 青灯夜游転載
- 2023-02-20 19:38:283135ブラウズ

言うまでもなく、Python を使用してクローラーを作成するだけで、1 つの リクエスト で世界をカバーできます。ただし、golang に組み込まれている http パッケージは非常に強力だと聞いたので、何もする必要はありませんが、新しいことを学び、リクエストに関連する知識ポイントを確認したいだけです。 httpプロトコルの応答。言うことはあまりありません。まずは記事全体から始めましょう。
クローラ プロセスの概要graph TD
请求数据 --> 解析数据 --> 数据入库
上記のフローチャートからわかるように、クローラは次のようになります。手順はたったの3ステップだけです。次に、各ステップで何を行う必要があるかについて説明します。
- データのリクエスト: ここでは、golang の組み込みパッケージ http パッケージを使用して、ターゲット アドレスへのリクエストを開始する必要があります。このステップは完了です
- データの解析: ここでは、要求されたデータ全体が必要ではなく、特定のキー データのみが必要であるため、要求されたデータを解析する必要があります。このステップはデータ クリーニングとも呼ばれます #データ ストレージ: これは解析されたデータをデータベースに保存することであることを理解するのは難しくありません
- ##実践的な分析
まず、Bing 壁紙の公式 Web サイトにアクセスして観察してください。クローラーを実行する場合は、特にデータに注意する必要があります。これはホームページ情報です。ページ全体は非常に簡潔です。
次に、ブラウザの開発者ツールを呼び出す必要があります (これについてはよく知っているはずです。詳しくない場合は、従うのは難しいでしょう。)。  F12
F12
を確認してください。 Bing の壁紙では、右クリックしてもコンソールを呼び出すことができず、手動でのみ呼び出すことができます。心配しないで、最初の写真に従ってください。クラスメートの Chrome が中国語の場合も、同じ操作が行われます。さらにツールを選択し、開発者ツールを選択します。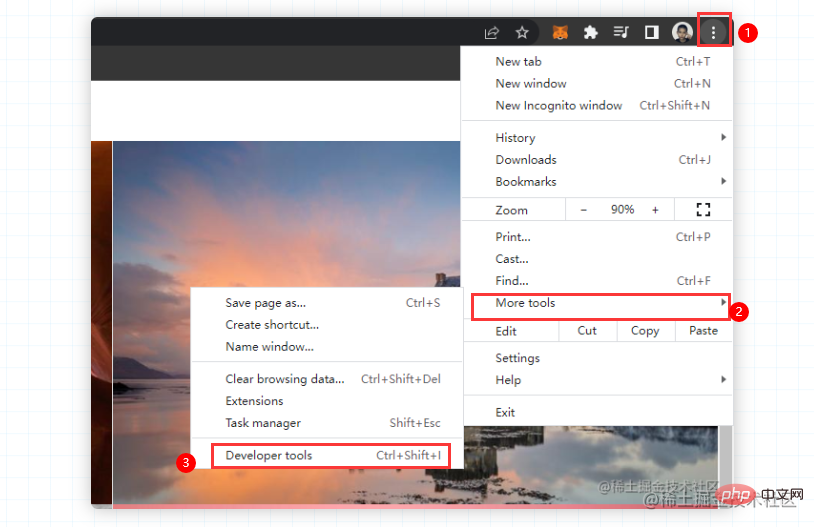 当然のことながら、誰もがこのようなページを目にするはずです
当然のことながら、誰もがこのようなページを目にするはずです
そんなことはありません問題は、Bing 壁紙 Web サイトのクロール対策エラーにすぎません。 (ずっと前にクロールしたときは、このクロール防止エラーは発生しませんでした) これは操作には影響しません
次に、必要な要素をすばやく見つけるのに役立つこのツールを選択します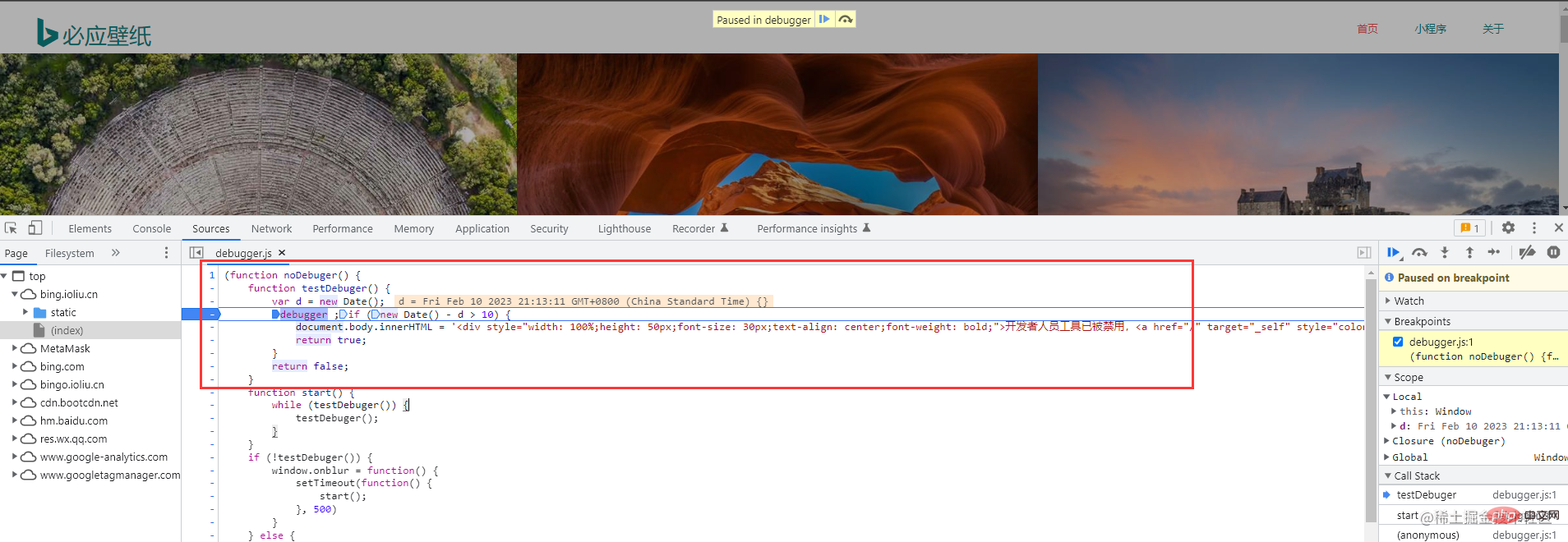 次に、必要な画像情報を見つけることができます
次に、必要な画像情報を見つけることができます
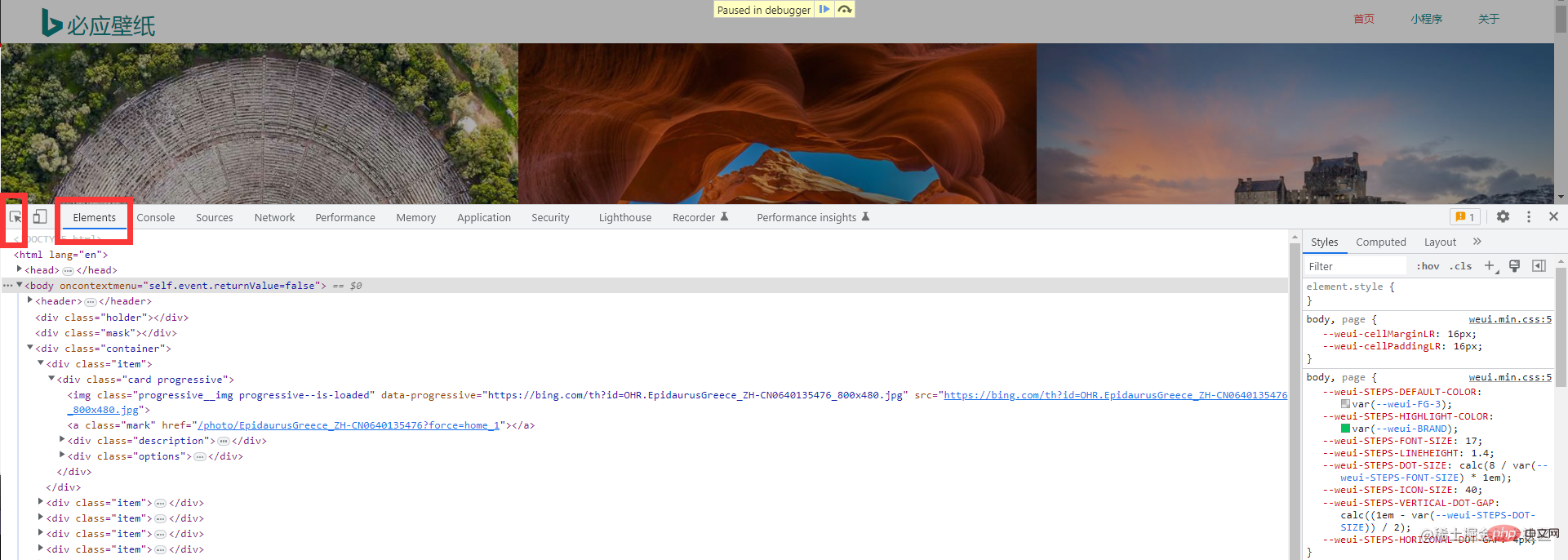
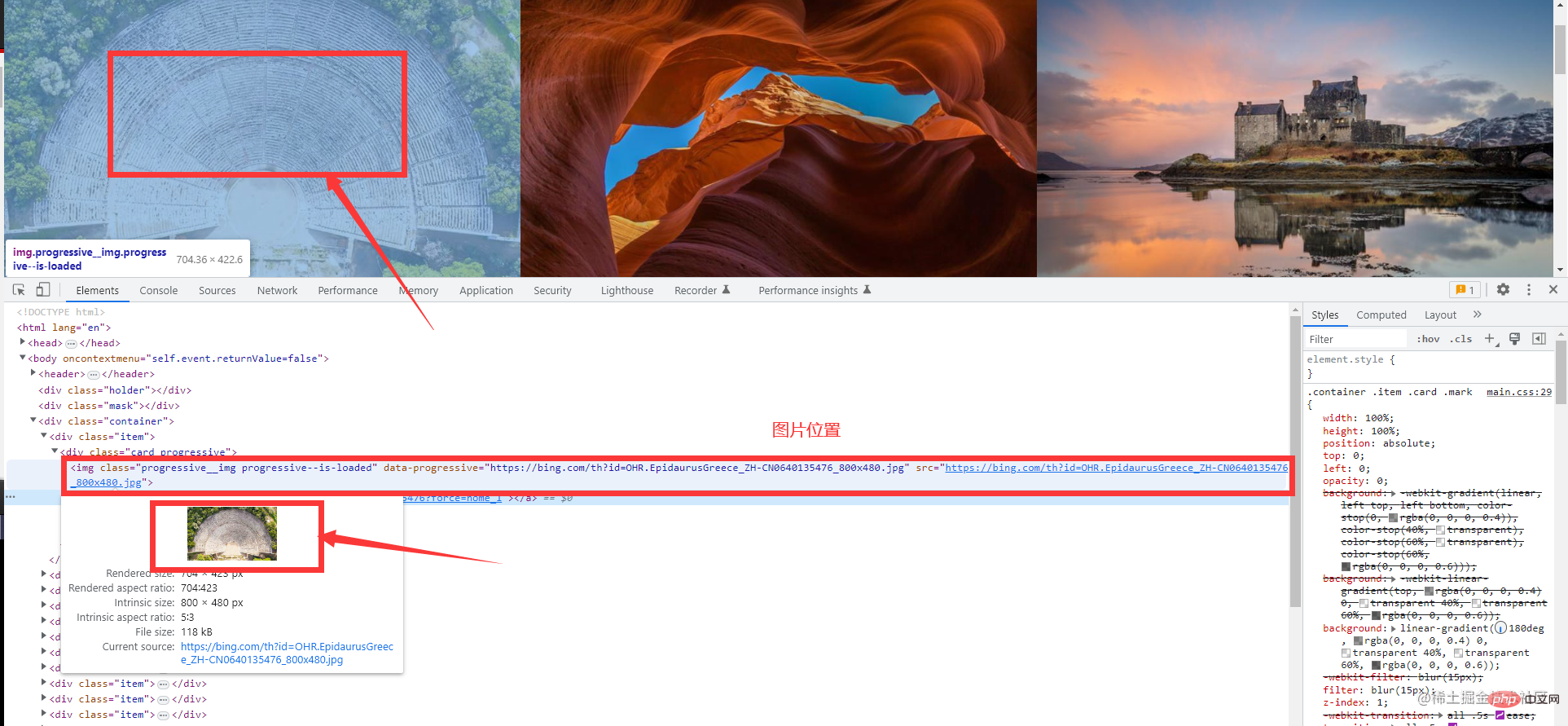 実際の戦闘コード
実際の戦闘コード
1ページをクロールするためのデータは次のとおりです
package main
import (
"fmt"
"github.com/PuerkitoBio/goquery"
"io"
"io/ioutil"
"log"
"net/http"
"os"
"time"
)
func Run(method, url string, body io.Reader, client *http.Client) {
req, err := http.NewRequest(method, url, body)
if err != nil {
log.Println("获取请求对象失败")
return
}
req.Header.Set("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36")
resp, err := client.Do(req)
if err != nil {
log.Println("发起请求失败")
return
}
if resp.StatusCode != http.StatusOK {
log.Printf("请求失败,状态码:%d", resp.StatusCode)
return
}
defer resp.Body.Close() // 关闭响应对象中的body
query, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Println("生成goQuery对象失败")
return
}
query.Find(".container .item").Each(func(i int, s *goquery.Selection) {
imgUrl, _ := s.Find("a.ctrl.download").Attr("href")
imgName := s.Find(".description>h3").Text()
fmt.Println(imgUrl)
fmt.Println(imgName)
DownloadImage(imgUrl, i, client)
time.Sleep(time.Second)
fmt.Println("-------------------------")
})
}
func DownloadImage(url string, index int, client *http.Client) {
req, err := http.NewRequest("POST", url, nil)
if err != nil {
log.Println("获取请求对象失败")
return
}
req.Header.Set("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36")
resp, err := client.Do(req)
if err != nil {
log.Println("发起请求失败")
return
}
data, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Println("读取请求体失败")
return
}
baseDir := "./image/image-%d.jpg"
f, err := os.OpenFile(fmt.Sprintf(baseDir, index), os.O_CREATE|os.O_TRUNC|os.O_WRONLY, 0666)
if err != nil {
log.Println("打开文件失败", err.Error())
return
}
defer f.Close()
_, err = f.Write(data)
if err != nil {
log.Println("写入数据失败")
return
}
fmt.Println("下载图片成功")
}
func main() {
client := &http.Client{}
url := "https://bing.ioliu.cn/?p=%d"
method := "GET"
Run(method, url, nil, client)
}以下は複数ページのデータをクロールするためのコードです。複数ページをクロールするためのコードはあまり変更されていません。最初に Web サイトの特性を観察する必要があります。発見何が起こったのか?最初のページ p=1、2 番目のページ p=2、10 番目のページ p=10
したがって、for ループを開始し、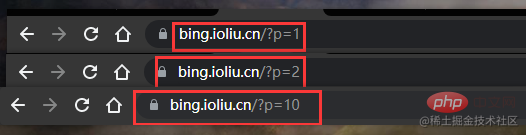
// 爬取多页的main函数如下
func main() {
client := &http.Client{}
url := "https://bing.ioliu.cn/?p=%d"
method := "GET"
for i := 1; i < 5; i++ { // 实现分页操作
Run(method, fmt.Sprintf(url, i), nil, client)
}
}# の前に単一のページをクロールしたコードを再利用します。 ##概要
この例では、正規表現を使用するのは非常に面倒なので、サードパーティのツール パッケージを使用して Web ページ データを解析します #CSS セレクターを使用します:
goQuery以上がGolangを使ってBingの壁紙をクロールする方法を詳しく解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。