
ホームページ >ウェブフロントエンド >jsチュートリアル >ノード内のストリームの詳細な分析
ノード内のストリームの詳細な分析

- 青灯夜游転載
- 2023-01-29 19:46:303014ブラウズ
ストリームとは何ですか?流れをどう理解するか?次の記事では、Nodejs のストリームについて詳しく説明します。お役に立てば幸いです。

stream は、EventEmitter を継承する抽象データ インターフェイスです。データを送受信できます。その本質は、以下に示すようにデータをフローさせることです。 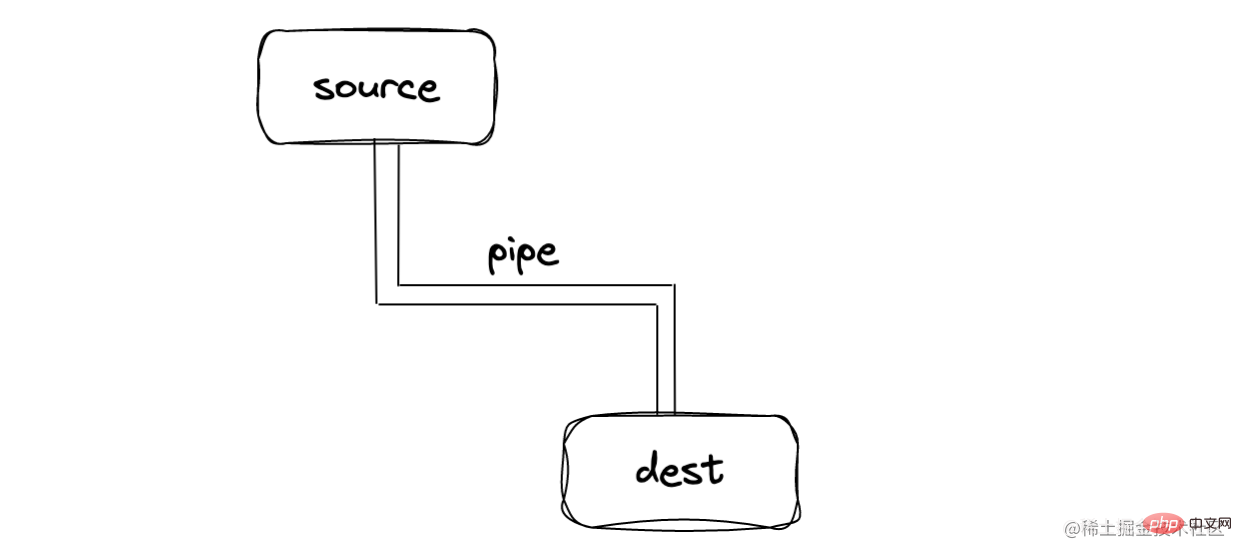 ##Stream は Node 独自の概念ではなく、オペレーティング システムの最も基本的な操作方法です。Linux では | Stream ですが、Node レベルでカプセル化され、対応する API
##Stream は Node 独自の概念ではなく、オペレーティング システムの最も基本的な操作方法です。Linux では | Stream ですが、Node レベルでカプセル化され、対応する API
##なぜ少しずつ行う必要があるのでしょうか?
まず、次のコードを使用して、約 400 MB のファイルを作成します [関連チュートリアルの推奨事項: nodejs ビデオ チュートリアル
] # #readFile を使用して読み取ると、次のコードが表示されます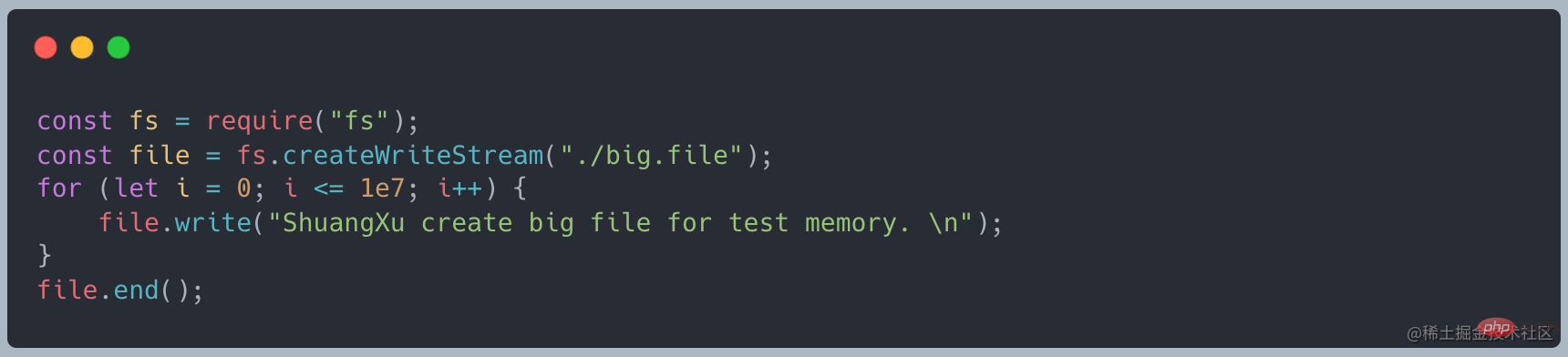
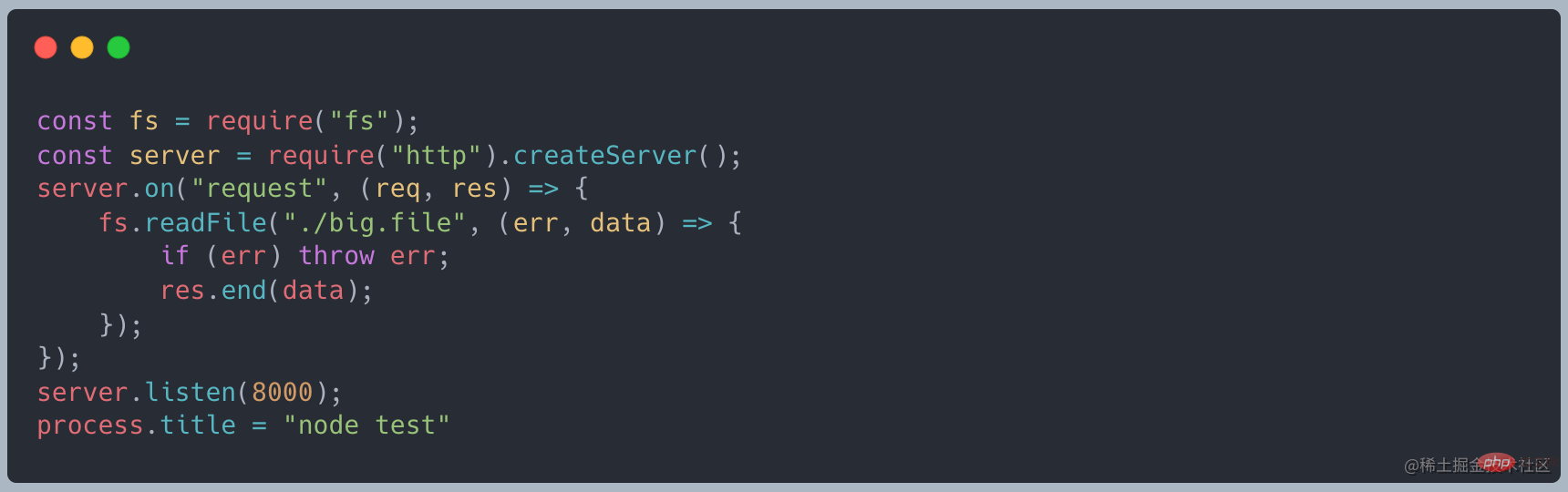
curl http://127.0.0.1:8000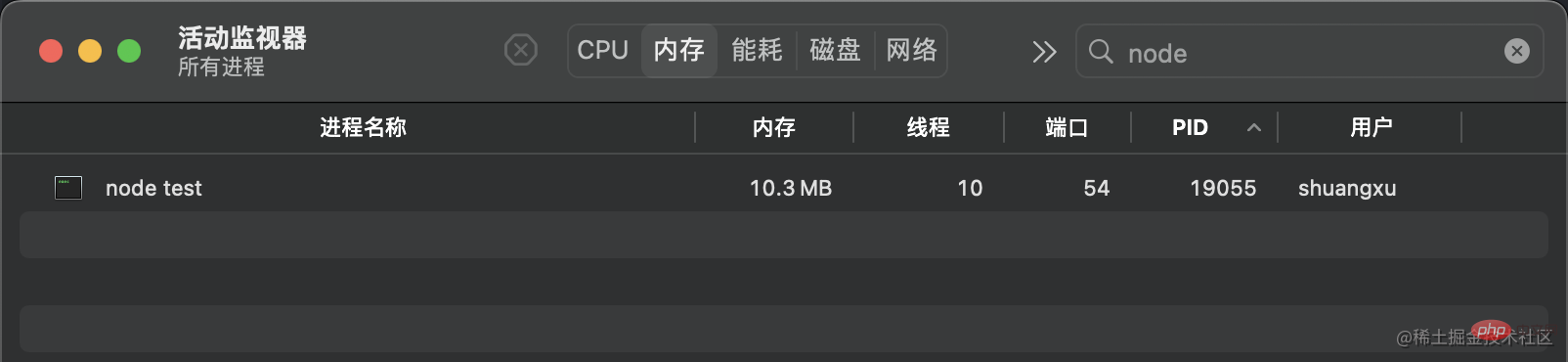 リクエストを行うと、メモリは約 420MB になり、作成したファイルとほぼ同じサイズになります
リクエストを行うと、メモリは約 420MB になり、作成したファイルとほぼ同じサイズになります

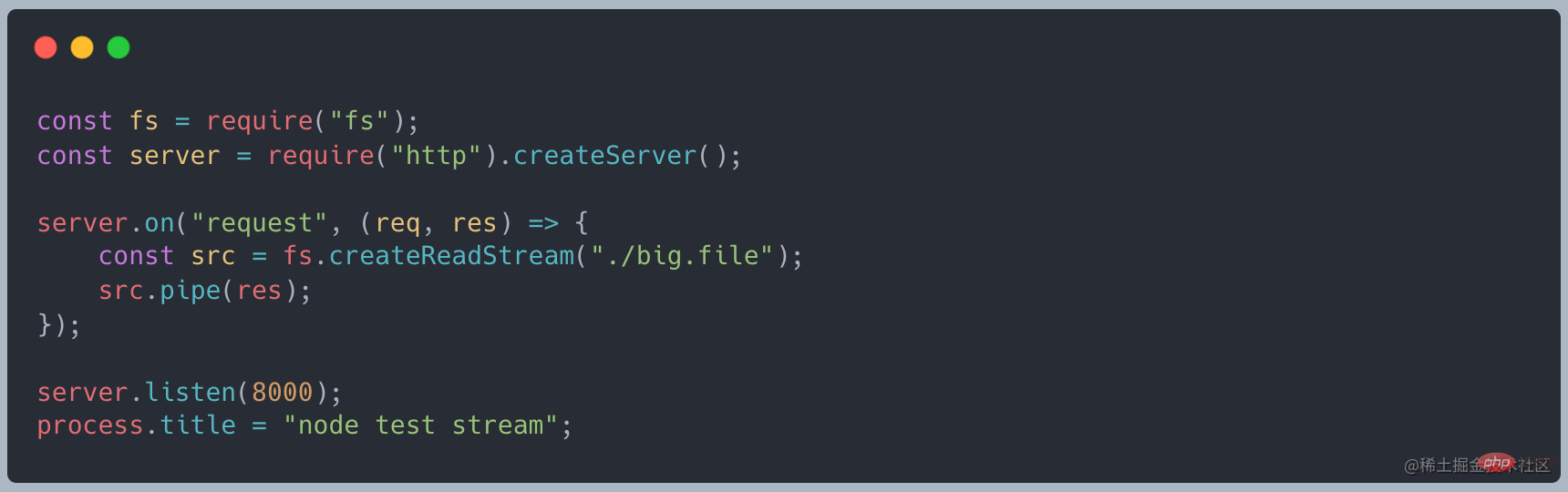

- 要約すると、大きなファイルを一度に読み取るとメモリとインターネットが消費されます。耐えられないほどです。
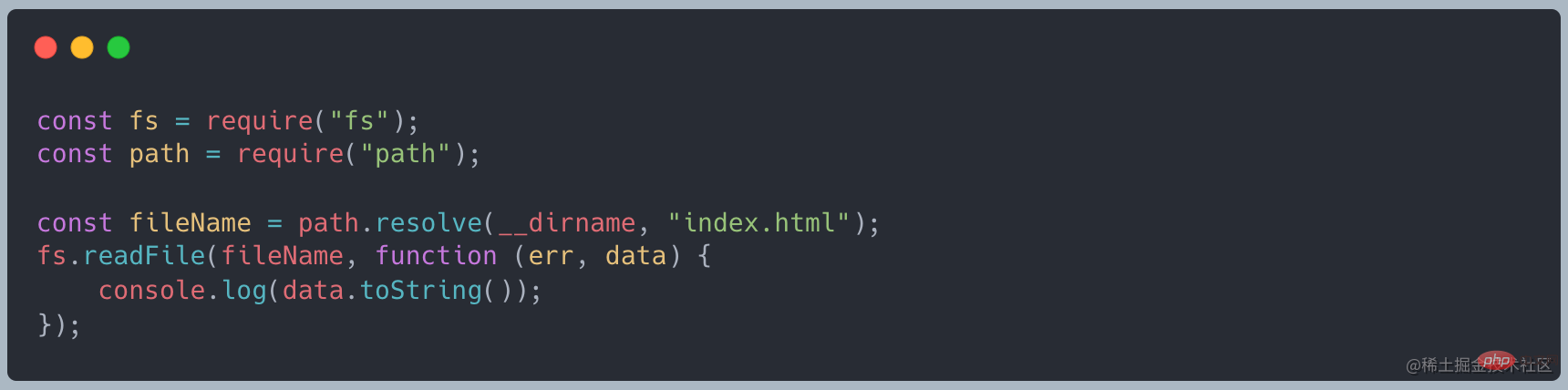
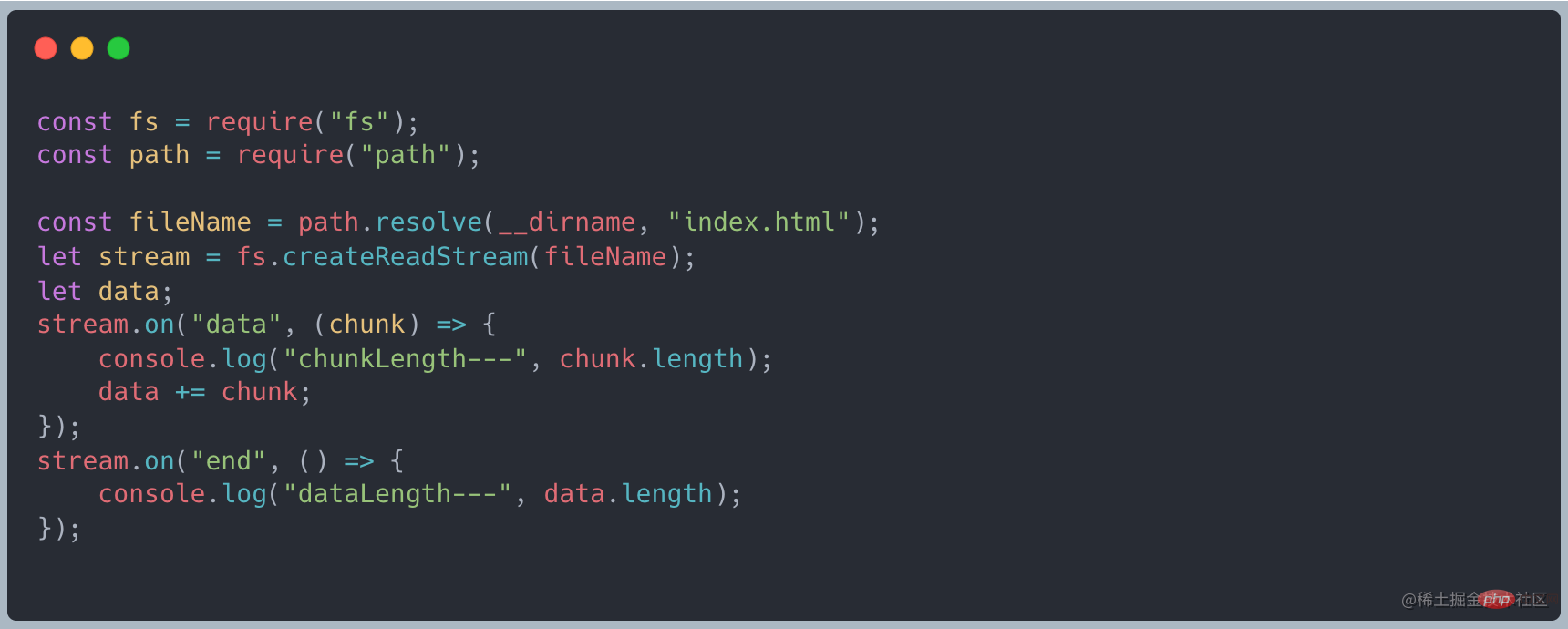
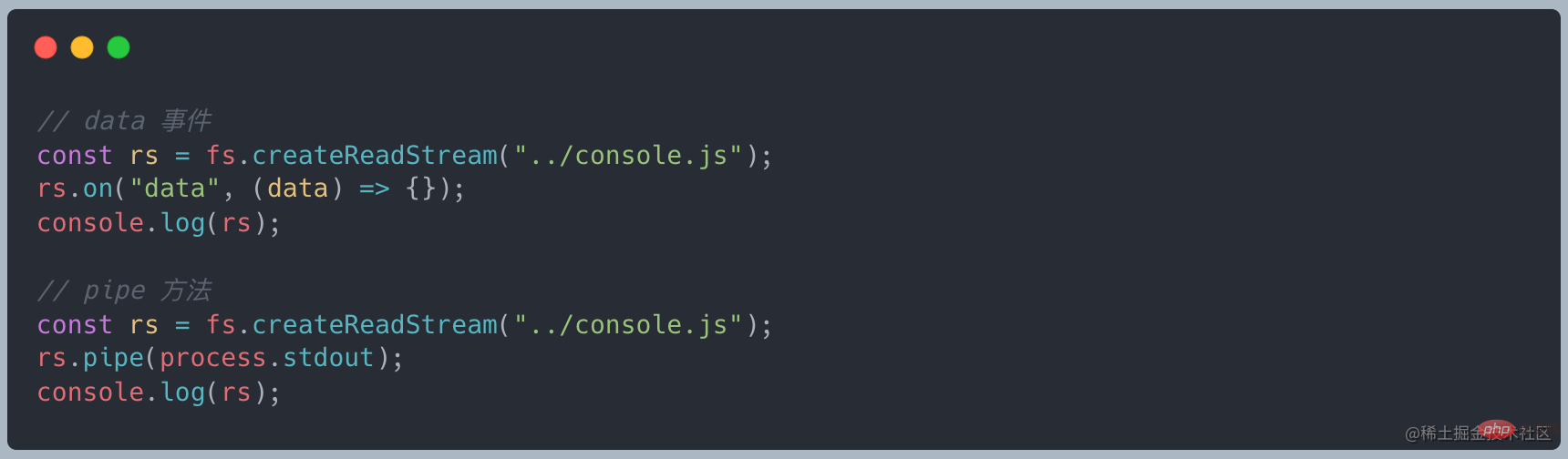
ファイルを読み込むと、読み込み完了後にデータを出力することができます。監視データを実装します。まず、読み込みデータをストリーミング読み込みに変更し、on("data", ()⇒{})でデータを受信し、最後に
on("end", ()⇒{ } )最終結果
データが転送されると、データ イベントがトリガーされ、処理のためにこのデータを受信し、最後にすべてのデータが転送されるまで待機します。 . 終了イベントをトリガーします。 データ フロー プロセス
 データの出所 - ソース
データの出所 - ソース
#http リクエスト、インターフェイスからのデータリクエスト
コンソール コンソール、標準入力 stdin
-
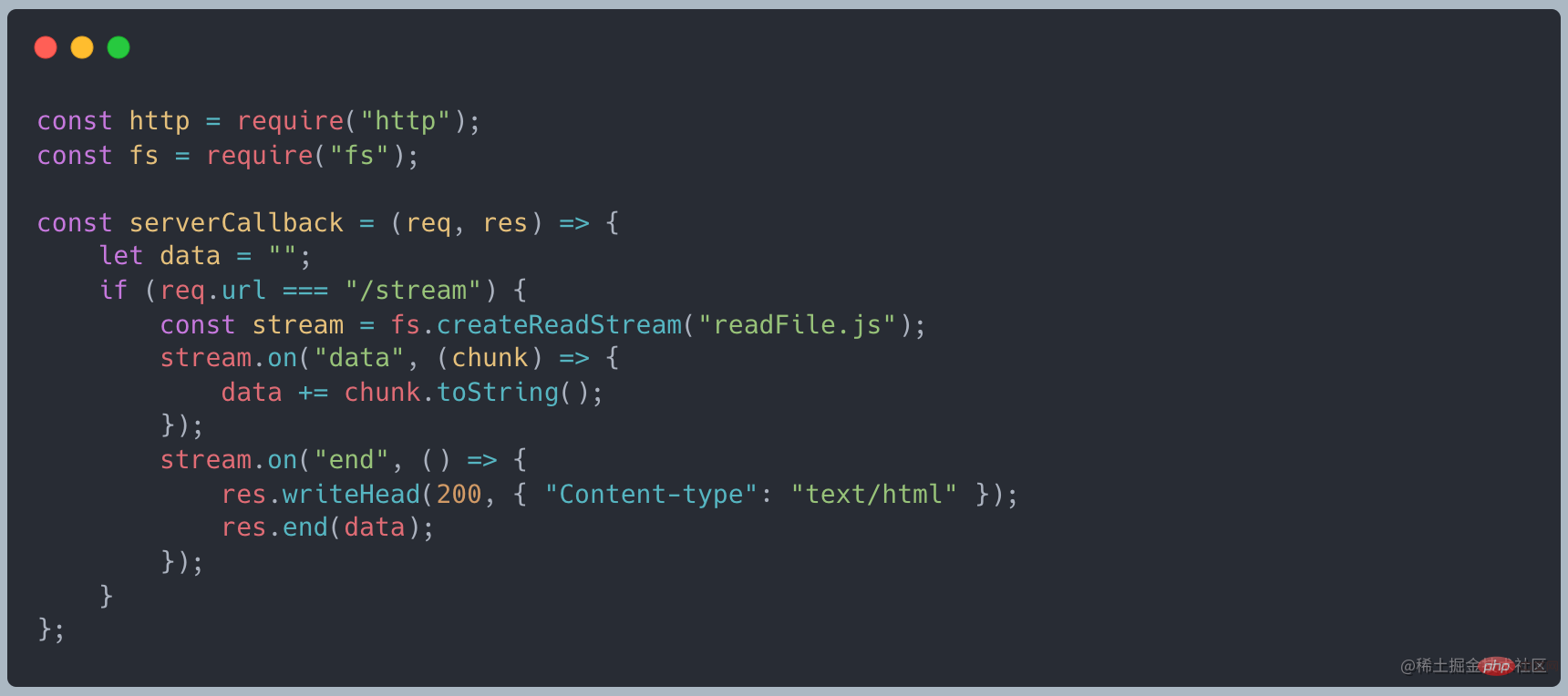 #file ファイルで、上記の例のようなファイルの内容を読み取ります。
#file ファイルで、上記の例のようなファイルの内容を読み取ります。 -
接続されたパイプ - パイプ
source と dest に接続されたパイプ Pipe があります。基本的な構文は source.pipe(dest)
source.pipe(dest) - です。Source と dest はパイプを介して接続されており、データがそこから流れることができます。ソースから宛先へ #上記のコードのようにデータ/終了イベントを手動で監視する必要はありません。
??? フロー データとは正確には何ですか?コード内のチャンクとは何ですか?
どこへ行くか - dest
#
http リクエスト、インターフェース内のレスポンス request
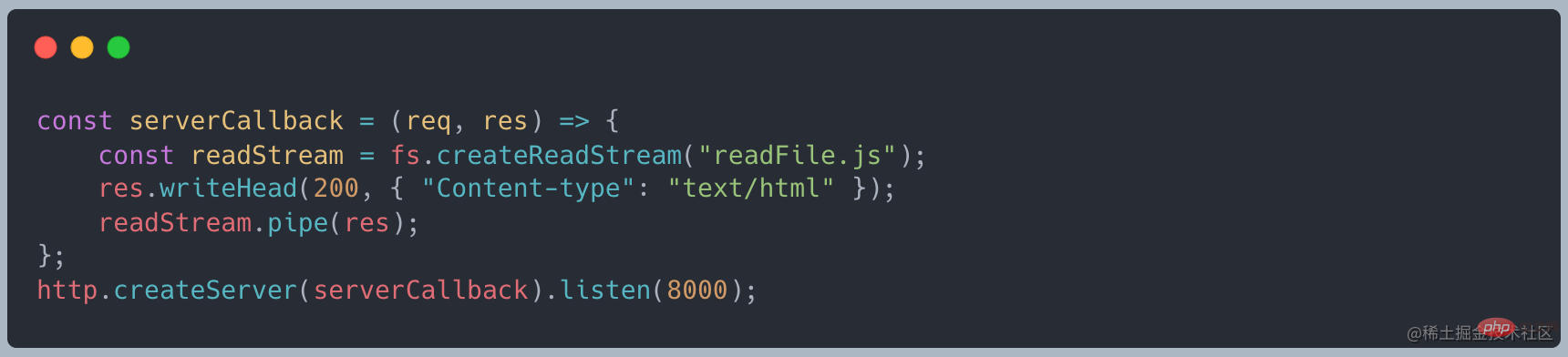
file ファイル、write file
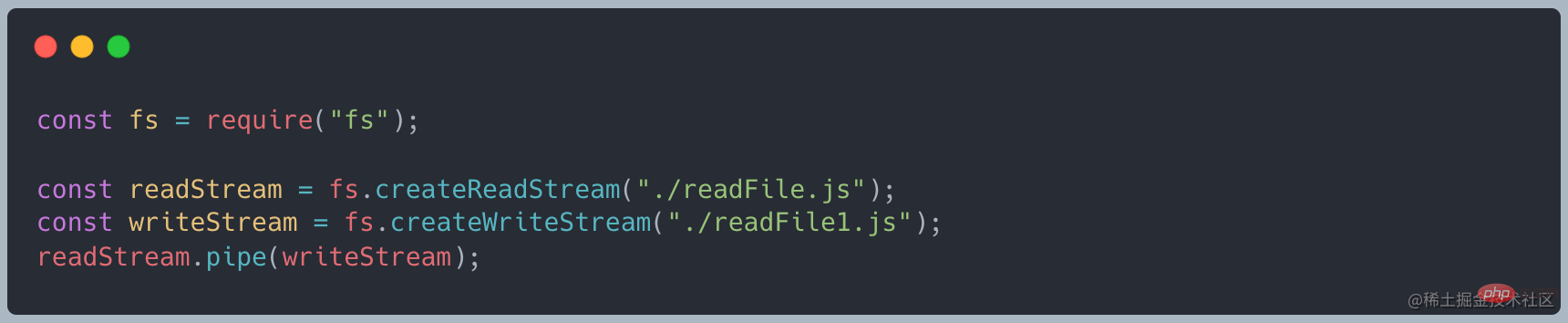
ストリームの種類

##読み取り可能なストリーム読み取り可能なストリーム
読み取り可能なストリームは、データを提供するソースの抽象化です。すべての読み取り可能なストリームは、ストリームによって定義されたインターフェイスを実装します。読み取り可能なクラス  #? ファイルの読み取りストリームの作成
#? ファイルの読み取りストリームの作成
fs.createReadStream Readable オブジェクトの作成
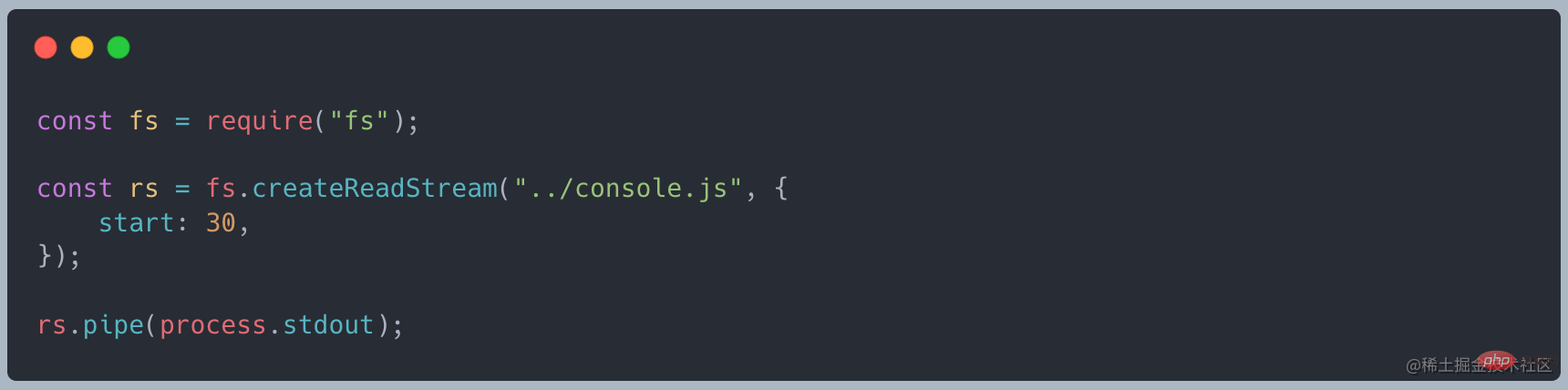
Readable には 2 つのモードがありますストリーム、
flowing modeおよび pause mode は、チャンク データのフロー モードを決定します: 自動フローと手動フロー FlowReadableStream には _readableState 属性があります。フロー モードを決定するフロー属性があり、3 つの状態値があります:
ture: フロー モードとして表現されます- false: 一時停止モードとして表現されます
- null: 初期状態
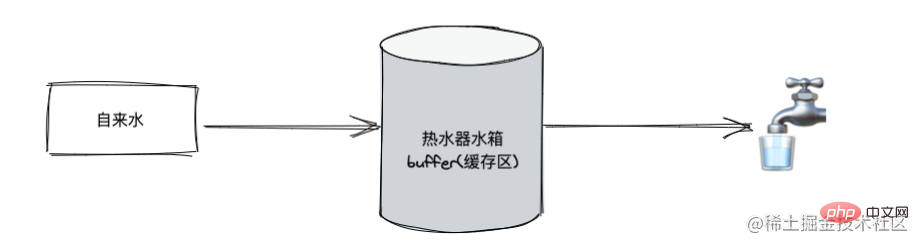 給湯器モデルを使用して、データ フローをシミュレートできます。給湯器のタンク(バッファキャッシュ領域)にはお湯(必要なデータ)が蓄えられており、蛇口を開くと給水タンクからはお湯が流れ続け、給水タンクには水道水が流れ続けます。フローモード。蛇口を閉めると水タンクへの水の流入が止まり、蛇口からの出水も一時停止する「一時停止モード」です。
給湯器モデルを使用して、データ フローをシミュレートできます。給湯器のタンク(バッファキャッシュ領域)にはお湯(必要なデータ)が蓄えられており、蛇口を開くと給水タンクからはお湯が流れ続け、給水タンクには水道水が流れ続けます。フローモード。蛇口を閉めると水タンクへの水の流入が止まり、蛇口からの出水も一時停止する「一時停止モード」です。
データは最下層から自動的に読み取られ、フロー現象を形成し、イベントを通じてアプリケーションに提供されます。
- データ イベントをリッスンすることでこのモードに入ることができます。
- データ イベントが追加されると、書き込み可能なストリームにデータがあると、データがイベントにプッシュされます。データ ブロックを消費するには、処理されないとデータが失われます
- ストリームの呼び出し、メソッドの再開
-
データは内部バッファに蓄積されるため、明示的に呼び出す必要があります。 stream.read() データ ブロックを読み取ります
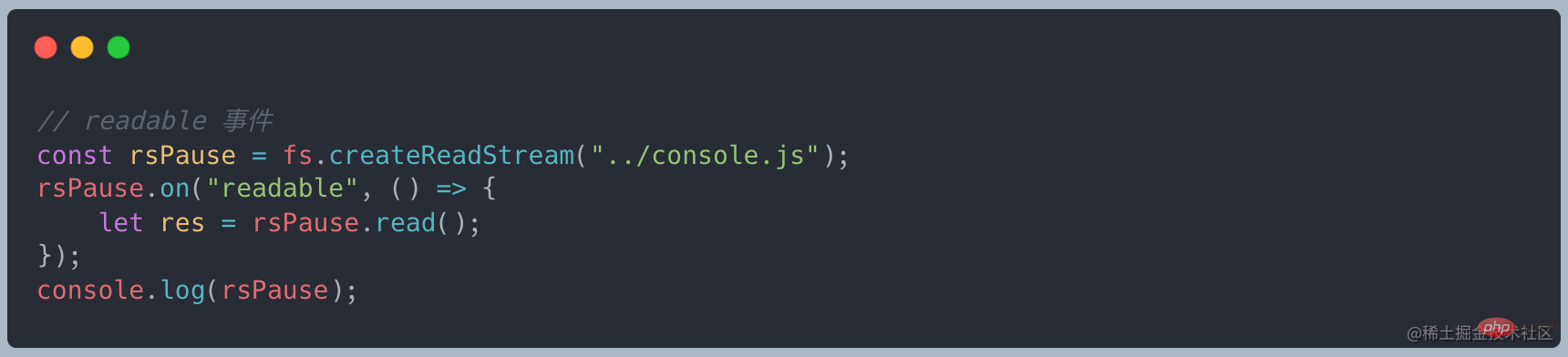
- #読み取り可能なイベントを聞く
書き込み可能なストリームは、データの準備ができた後にこのイベント コールバックをトリガーします。この時点で、データをアクティブに消費するには、コールバック関数で stream.read() を使用する必要があります。読み取り可能なイベントは、ストリームに新しいダイナミクスがあることを示します。新しいデータがあるか、ストリームがすべてのデータを読み取ったかのいずれかです。 2 つのモード 変換
-
読み取り可能なストリームは作成後の初期状態です //TODO: オンライン共有と矛盾しています
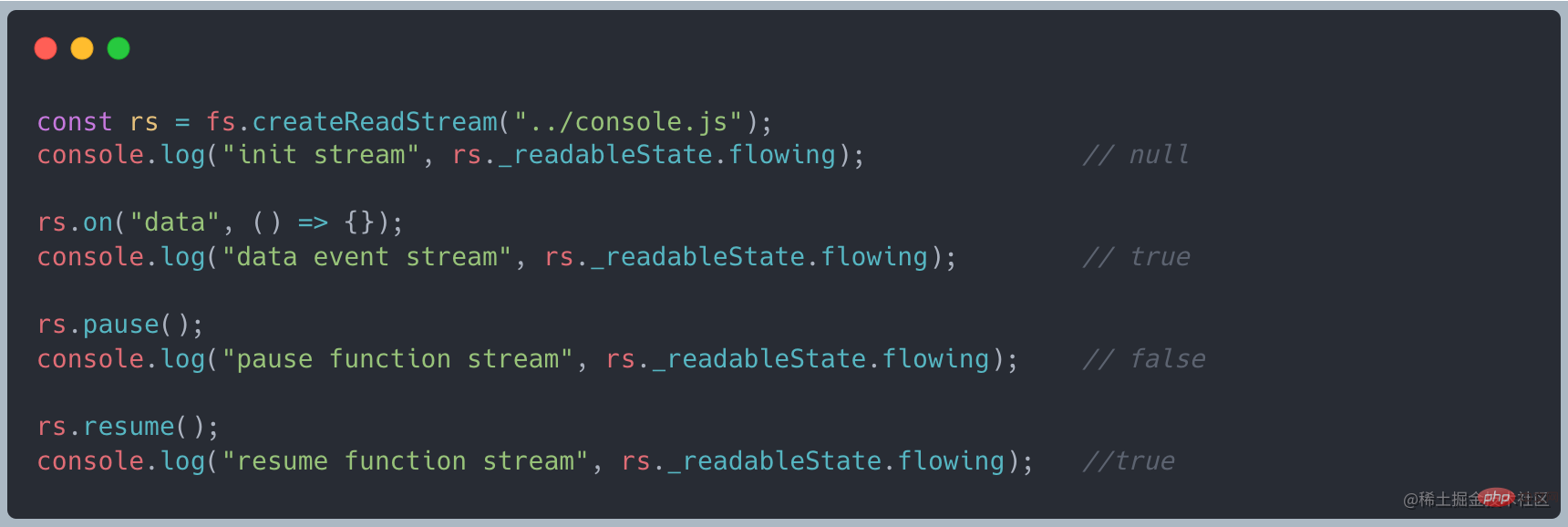
- 监听 data 事件
- 调用 stream.resume 方法
- 调用 stream.pipe 方法将数据发送到 Writable
- フロー モードを一時停止モードに切り替える
- 移除 data 事件 - 调用 stream.pause 方法 - 调用 stream.unpipe 移除管道目标
 実装原則
実装原則- 読み取り可能なストリームを作成するときは、Readable オブジェクトを継承し、_read メソッドを実装する必要があります
read メソッドを呼び出すと、全体的なプロセスは次のようになります。
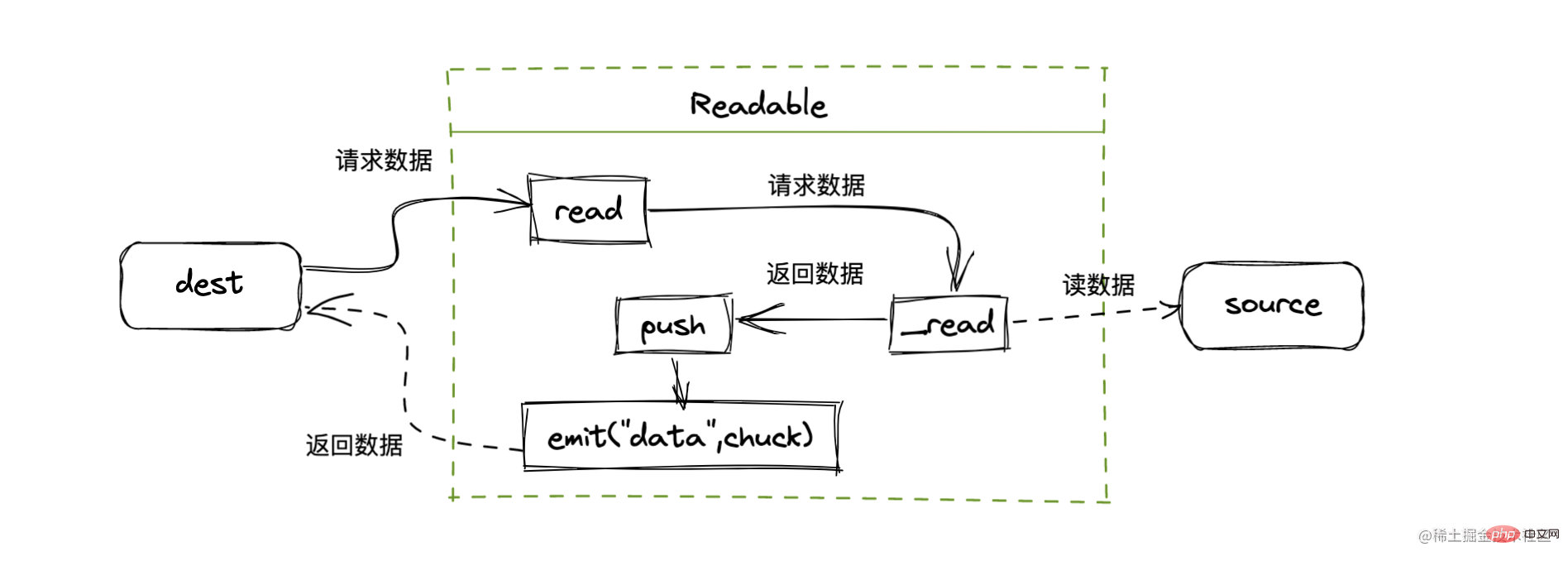
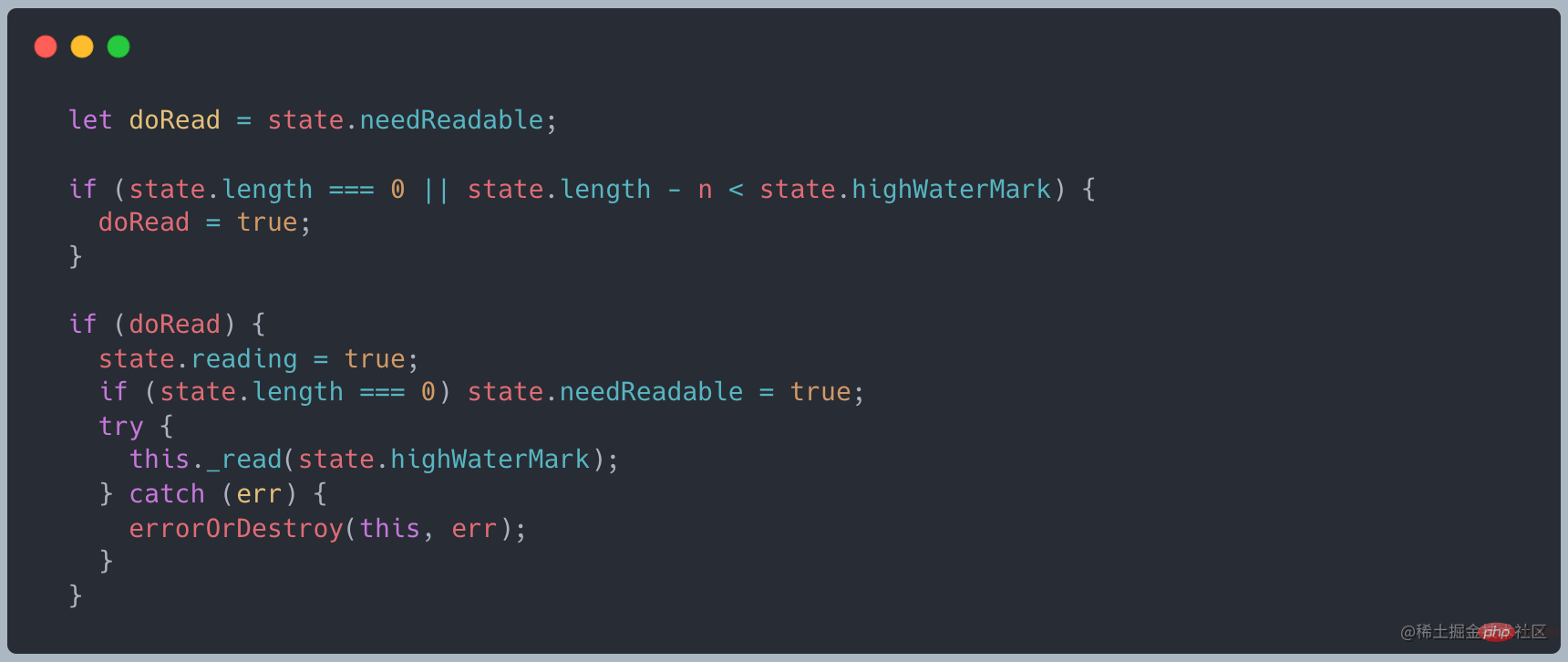
#doRead
キャッシュが維持されます。 stream 内で、最下層からのデータをリクエストする必要があるかどうかを判断するために read メソッドを呼び出すとき 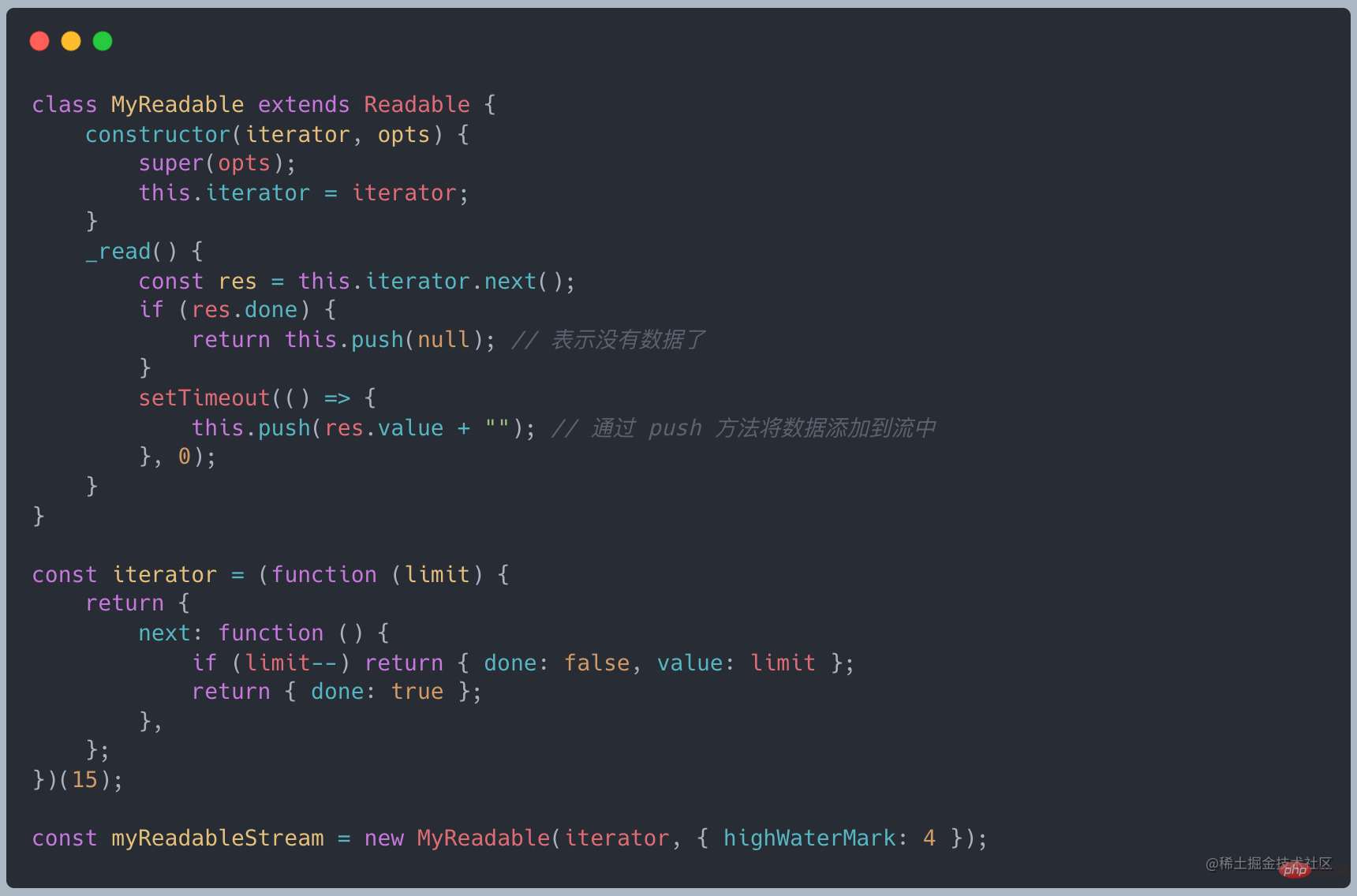
バッファ長が 0 以下の場合、最下層からデータを取得するために _read が呼び出されますソース コードのリンク
Writable StreamWritable Stream
Writable Stream はデータの書き込み先を抽象化したもので、上流から流れるデータを消費するために使用されます。書き込み可能なストリーム、データはデバイスに書き込まれます。一般的な書き込みストリームはローカル ディスクに書き込みます

#書き込み可能なストリームの特性
- #write を介してデータを書き込みます
-
#end を介してデータを書き込み、ストリームを閉じます。end = write close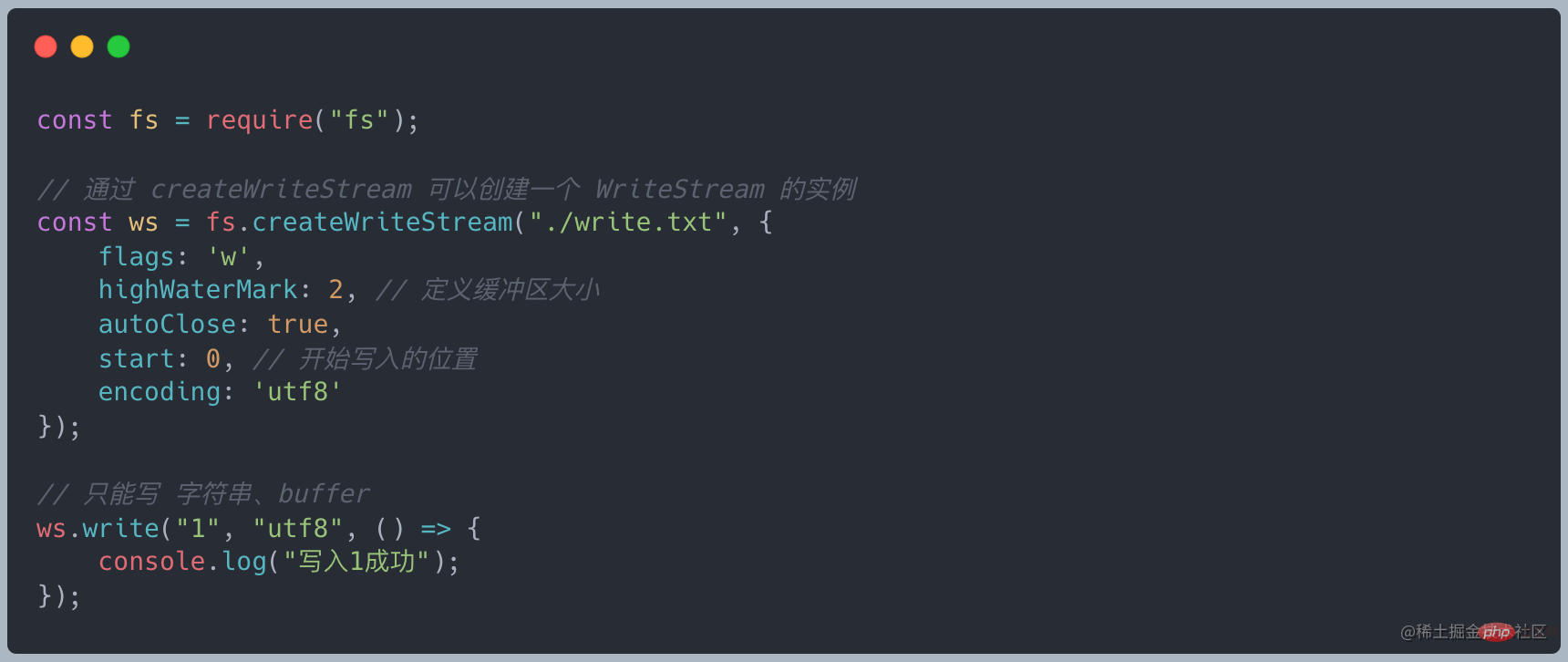
-
書き込まれたデータが highWaterMark のサイズに達すると、ドレイン イベントがトリガーされます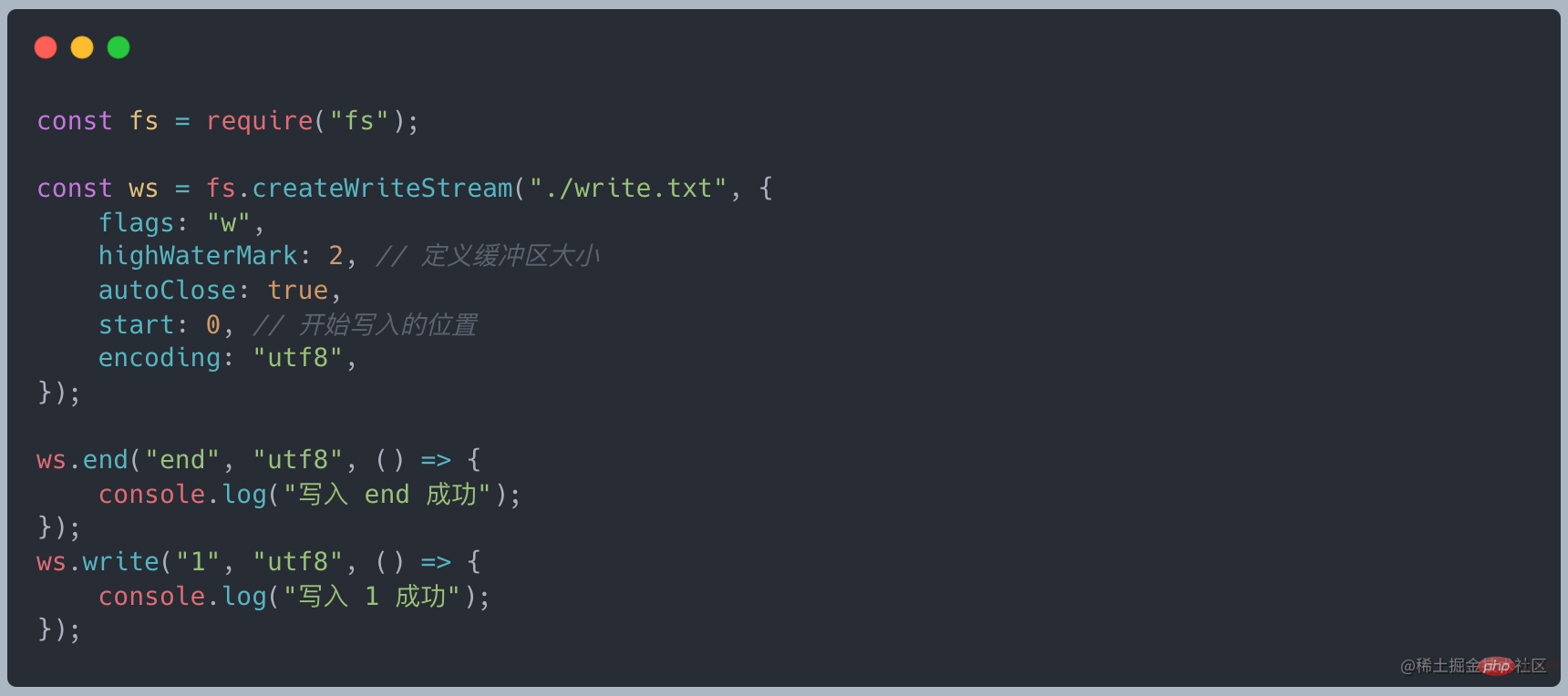
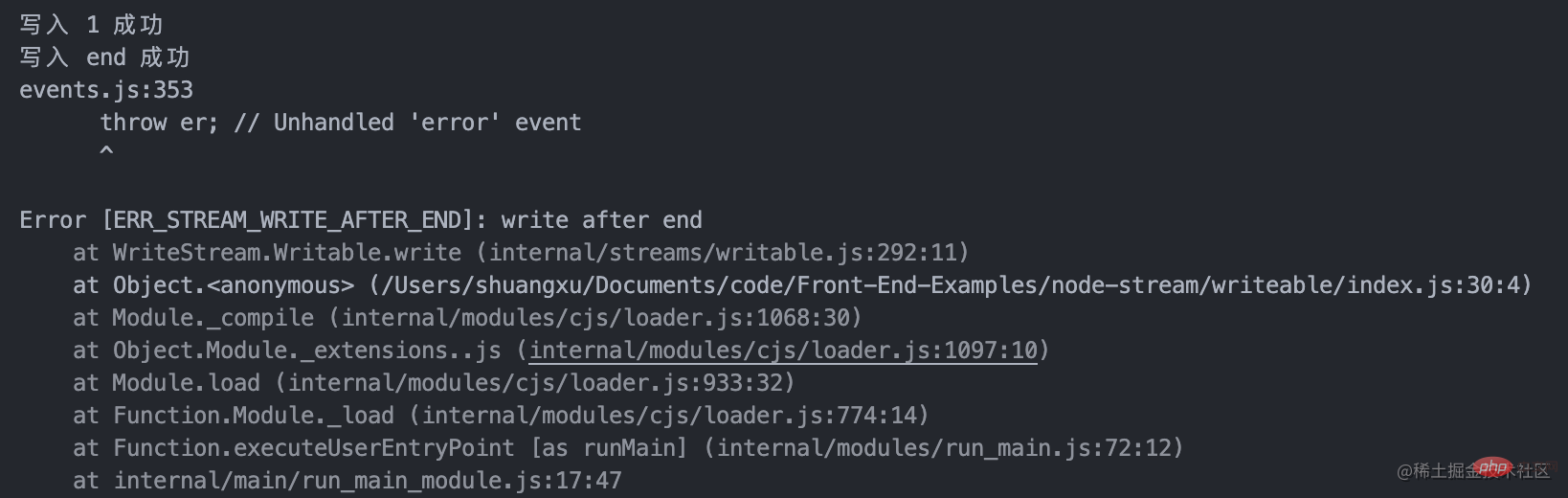
-
ws.write( chunk) を呼び出すと false が返され、現在のバッファ データが highWaterMark の値以上であることを示し、ドレイン イベントがトリガーされます。実際、これは警告として機能します。データを書き込むことはできますが、未処理のデータは、バックログが Node.js バッファーでいっぱいになるまで、書き込み可能なストリームの
に常にバックログされます。強制的に中断される可能性があります。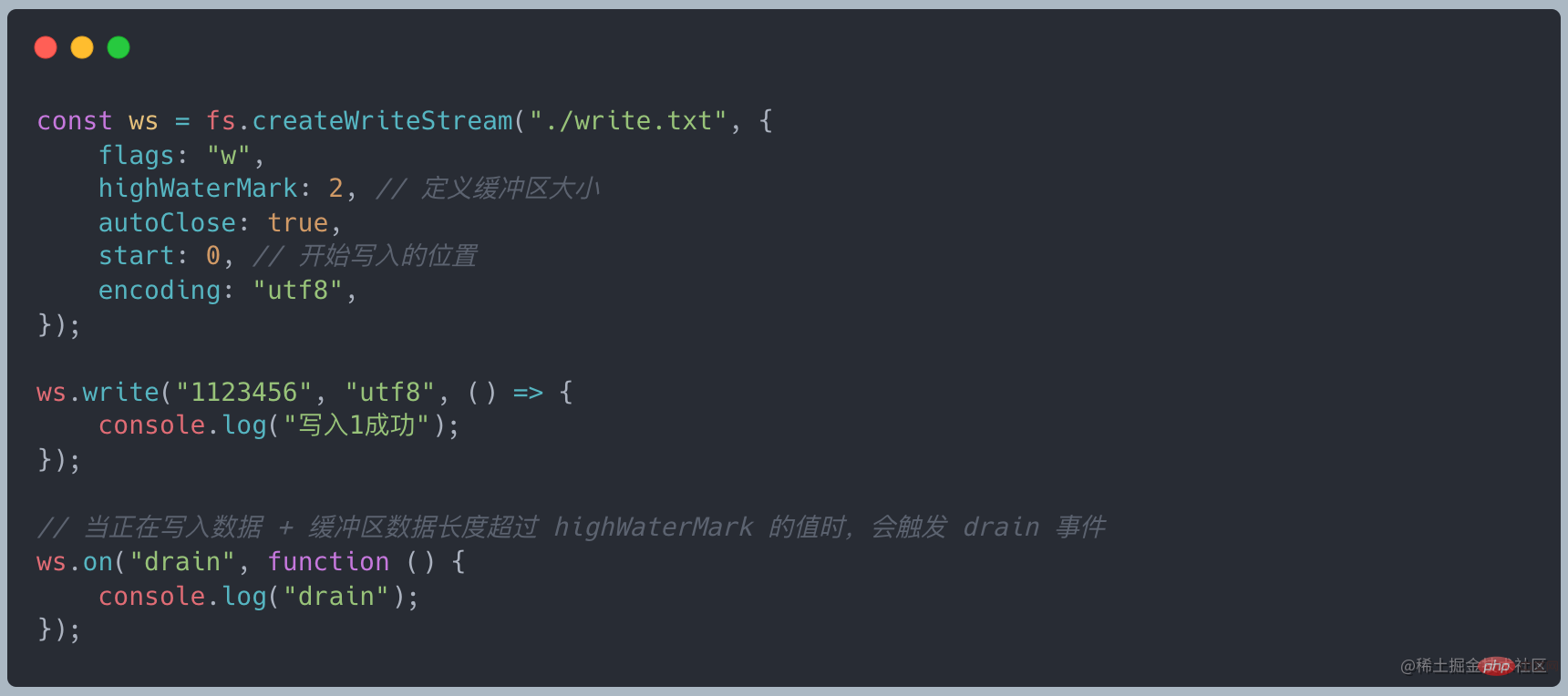 内部バッファー カスタマイズされた書き込み可能ストリーム
内部バッファー カスタマイズされた書き込み可能ストリーム
すべての Writeable は、ストリームによって定義されたインターフェイスを実装します。Writeable クラス
You _write メソッドを実装するだけで、基礎となるレイヤーにデータを書き込むことができます。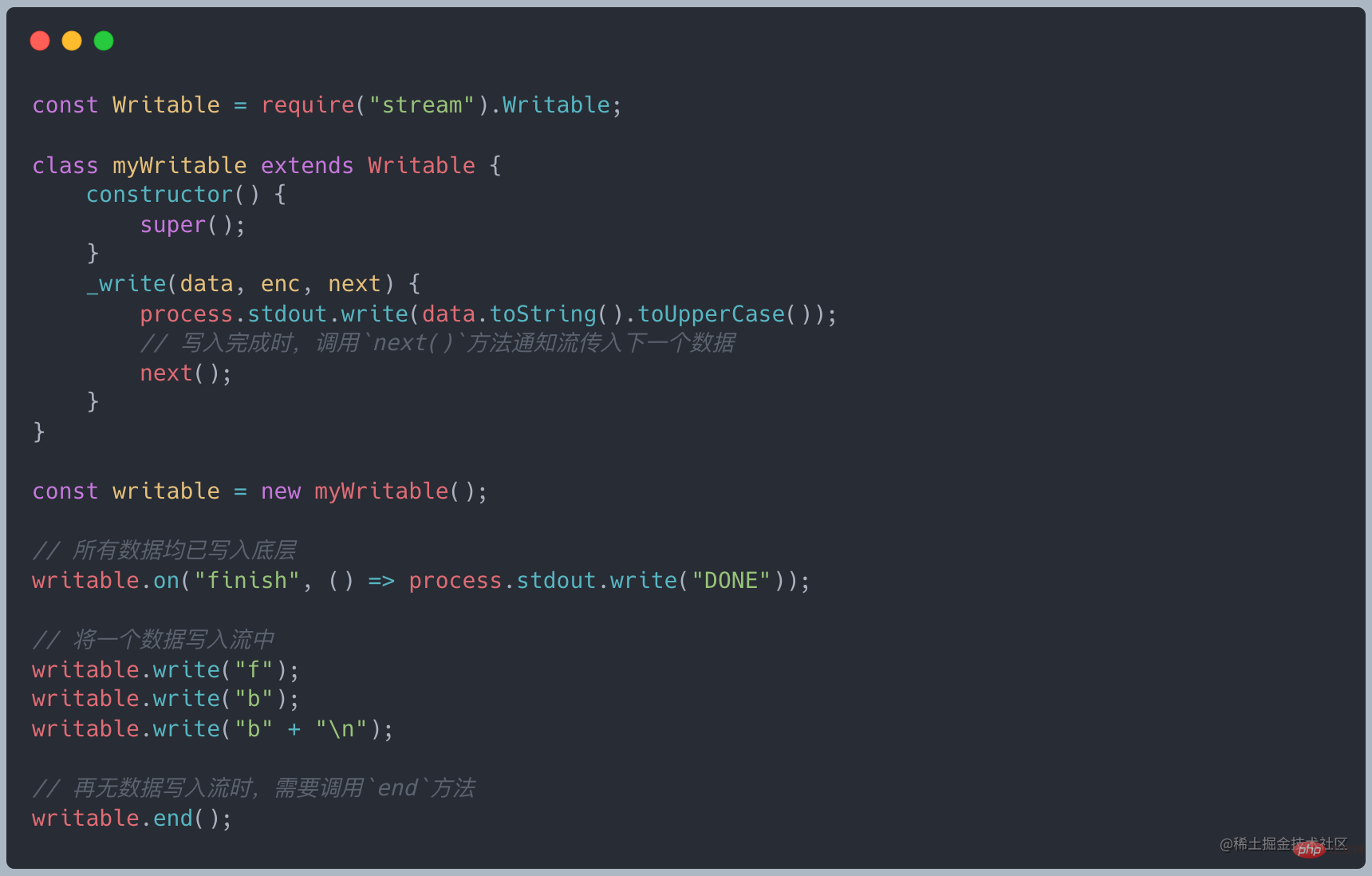 #writable.write メソッドを呼び出してストリームにデータを書き込むと、_write メソッドが呼び出されます。データを最下層に転送します。
#writable.write メソッドを呼び出してストリームにデータを書き込むと、_write メソッドが呼び出されます。データを最下層に転送します。
- _write data が成功したら、次のデータを処理するために次のメソッドを呼び出す必要があります。
- must call writable.end(data) To書き込み可能なストリームを終了します。データはオプションです。その後、新しいデータを追加するために write を呼び出すことはできません。そうでない場合は、エラーが報告されます。
- #end メソッドが呼び出された後、基礎となるすべての書き込み操作が完了すると、終了イベントがトリガーされます
- Duplex StreamDuplex Stream
Duplex ストリームは読み取りと書き込みの両方が可能です。実際、これは Readable と Writable を継承するストリームなので、読み取り可能なストリームと書き込み可能なストリームの両方として使用できます。カスタム二重ストリームは、Readable の _read メソッドと _write メソッドを実装する必要があります。 Writable
net モジュールを使用してソケットを作成できます。ソケットは NodeJS の典型的な Duplex です。TCP クライアントの例を参照してください。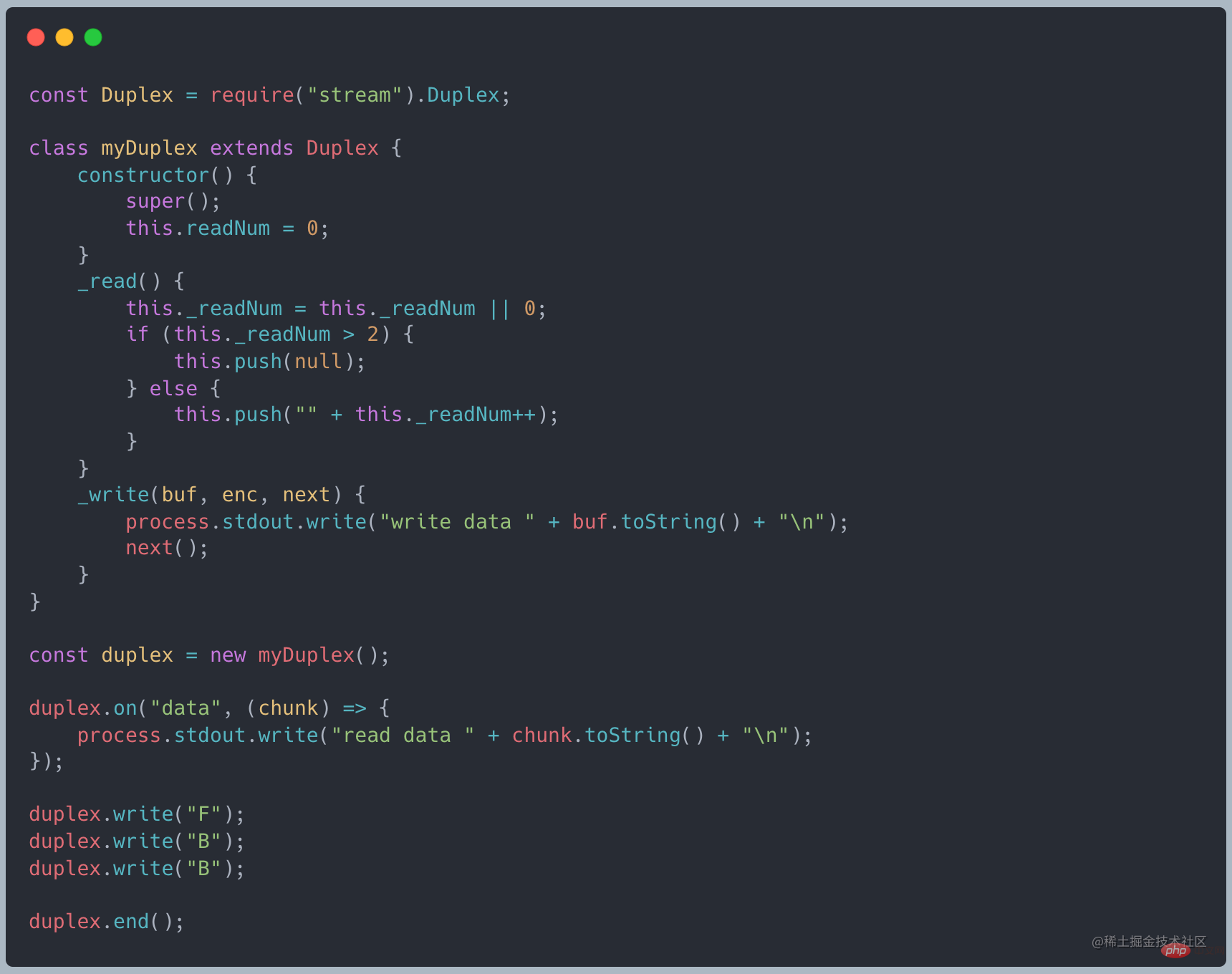
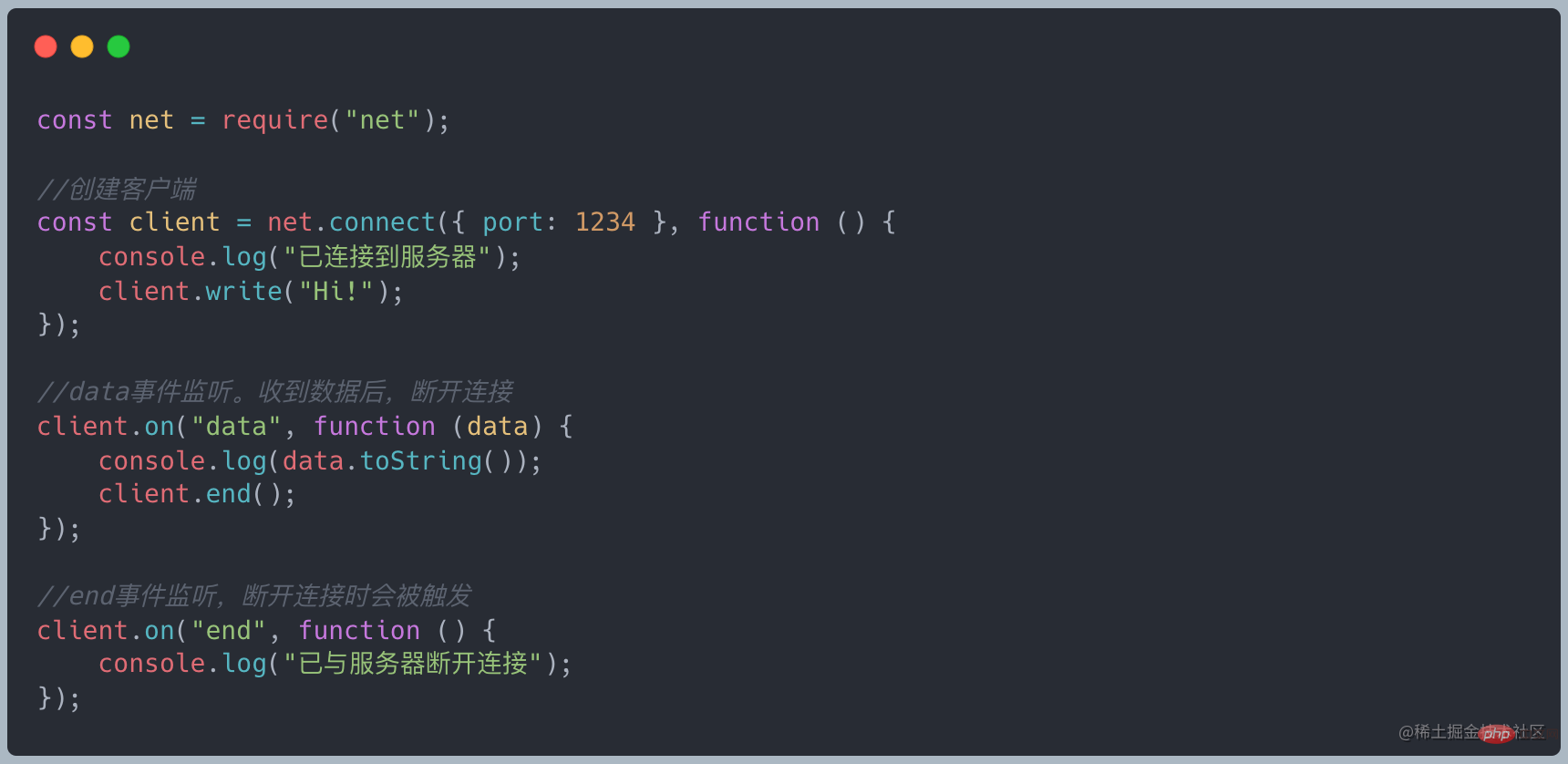
上記の例では、読み取り可能なストリームのデータ (0/1) と書き込み可能なストリームのデータ ('F'、'B') ,'B') は孤立しており、両者に関連性はありませんが、Transform の場合、書き込み可能側に書き込まれたデータは、変換後に読み取り可能側に自動的に追加されます。 Transform は Duplex から継承しており、_write メソッドと _read メソッドがすでに実装されています。実装する必要があるのは _tranform メソッドのみです。
gulp ストリームベースのオートメーションツールを構築するには、公式 Web サイトのサンプルコードを参照してください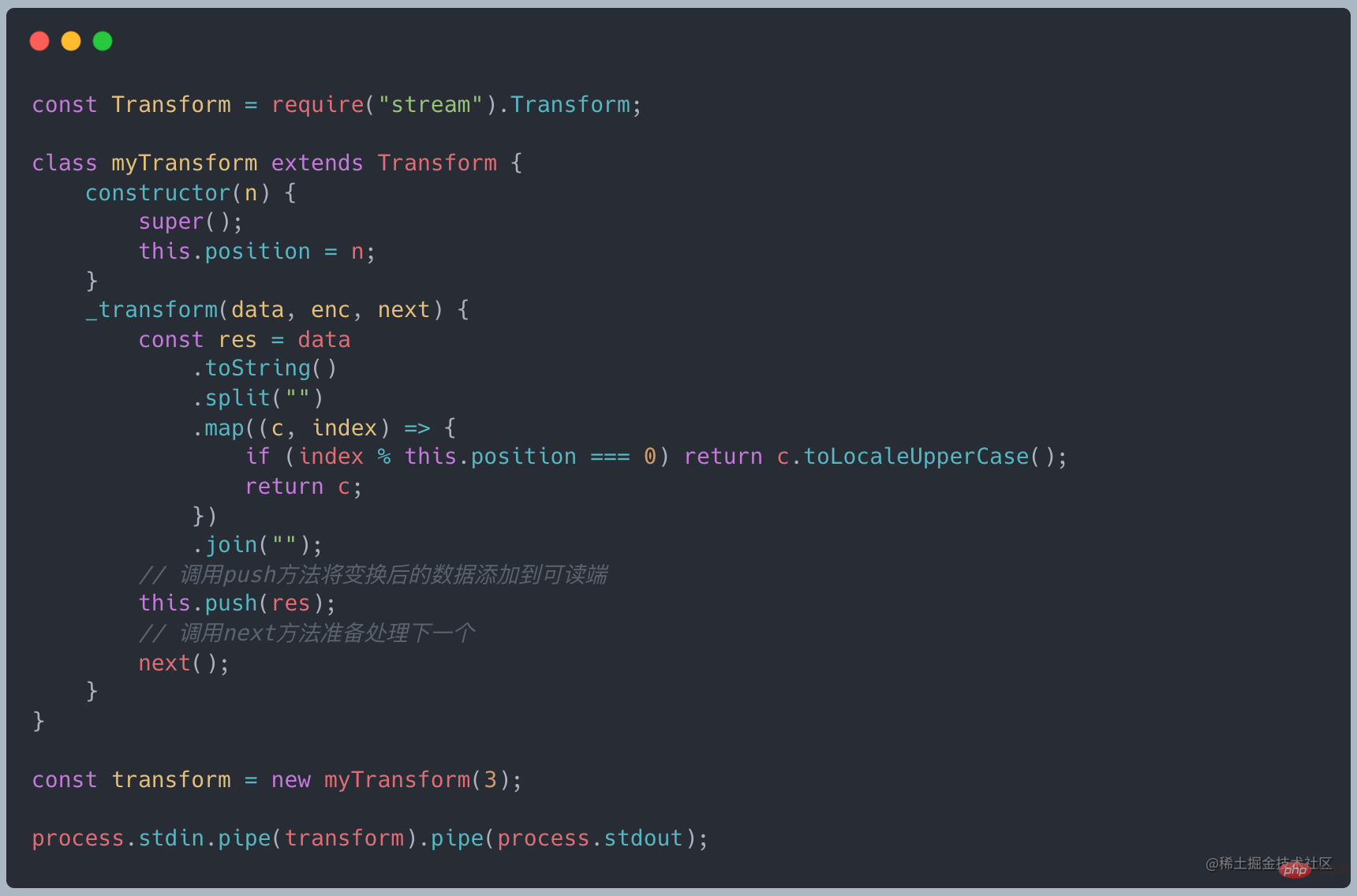
##less→less を css に変換→css 圧縮を実行→compressed css
実際には、 less() と minifyCss() は入力データに対して何らかの処理を実行し、それを出力データに渡します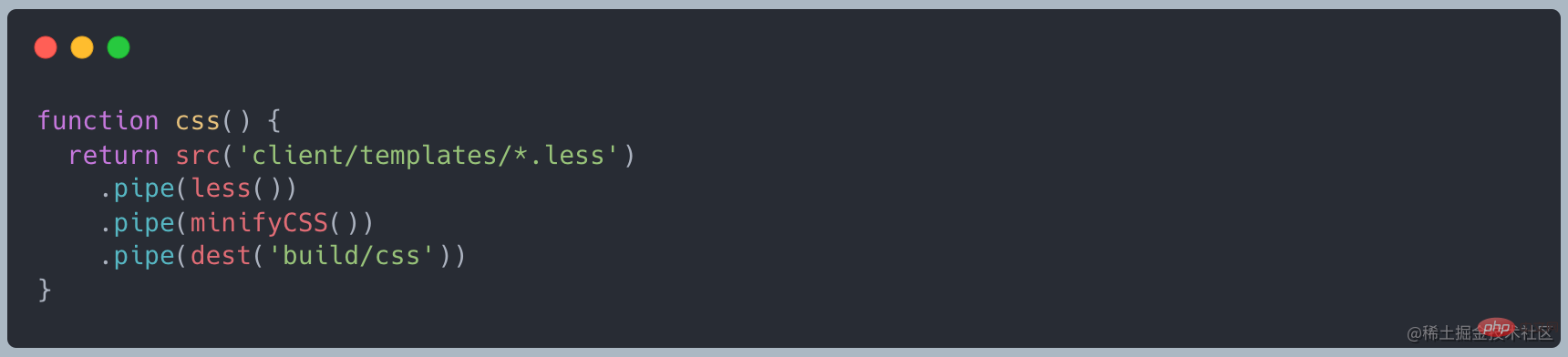
Duplex と Transform の選択
上記の例と比較すると、ストリームがプロデューサーとコンシューマーの両方にサービスを提供する場合は Duplex を選択し、データに対して何らかの変換作業を行うだけの場合は Transform
バックプレッシャ問題
バックプレッシャとは
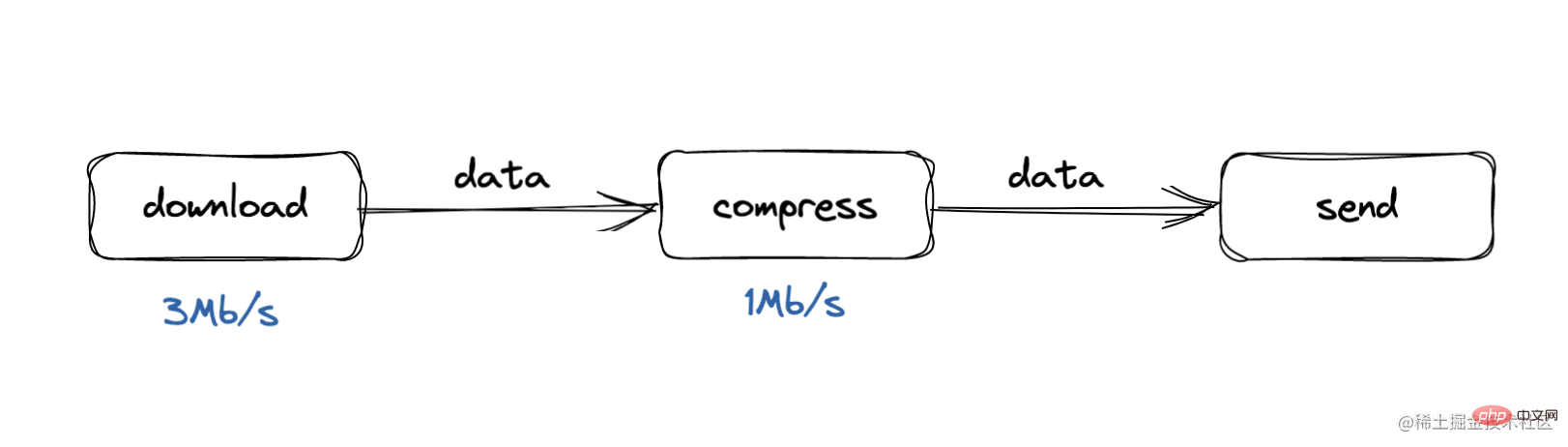
バックプレッシャ問題は、コンシューマが速度を処理する生産者/消費者モデルに起因します。遅すぎる
たとえば、ダウンロード処理中の処理速度は3Mb/sですが、圧縮処理中の処理速度は1Mb/sです。この場合、すぐにバッファキューが蓄積されます
プロセス全体のメモリ消費量が増加するか、バッファ全体が遅くなり一部のデータが失われます
バックプレッシャー処理とは
バックプレッシャー処理は、上向きに「宣言」するプロセスとして理解できます。##圧縮処理でバッファデータの圧迫が閾値を超えた場合、ダウンロード処理に「宣言」します。忙しすぎます。再度送信しないでください。
メッセージを受信した後、ダウンロード処理で下方向へのデータの送信が一時停止されます。
あるプロセスから別のプロセスにデータを転送するためのさまざまな関数があります。 Node.js には、.pipe() と呼ばれる組み込み関数があり、最終的に、このプロセスの基本レベルには、データのソースとコンシューマーという 2 つの無関係なコンポーネントがあります。
When .pipe() はソースによって呼び出され、送信するデータがあることをコンシューマーに通知します。パイプライン関数は、イベント トリガーに適したバックログ パッケージを確立します。
データ キャッシュが highWaterMark を超えるか書き込みキューがビジーな場合、.write() は false を返します
false が返される場合、バックログ システム踏み込んだ。データを送信しているデータ ストリームからの受信 Readable を一時停止します。データ ストリームが空になると、ドレイン イベントがトリガーされ、受信データ ストリームが消費されます。
キューが完全に処理されると、バックログ メカニズムによりデータの再送信が可能になります。使用中のメモリ空間は自動的に解放され、データの次のバッチを受信する準備が整います
#パイプのバック プレッシャー処理が確認できます:
データをチャンクごとに分割して書き込みます
##チャンクが大きすぎる場合やキューがビジーな場合は読み取りを一時停止します- ##キューが空の場合はデータの読み取りを継続します
- ノード関連の知識の詳細については、 nodejs チュートリアル
- を参照してください。
以上がノード内のストリームの詳細な分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。