
ホームページ >バックエンド開発 >Python チュートリアル >Python クローラーを 1 つの記事で理解する
Python クローラーを 1 つの記事で理解する

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-01-25 06:30:013587ブラウズ
この記事では、Python に関する関連知識を紹介します。主にクローラーに関する関連知識を紹介します。クローラーとは、簡単に言うと、プログラムを使用してインターネット上のデータを取得するプロセスの名前です。一緒に見てみましょう。できれば幸いです。それはみんなを助けます。

クローラーとは何ですか?
クローラーとは、プログラムを使用してインターネット上のデータを取得するプロセスの単なる名前です。
クローラーの原理
ネットワーク上のデータを取得したい場合は、クローラーに Web サイトのアドレス (通常、プログラム内では URL と呼ばれます) を与える必要があり、クローラーは HTTP リクエストを次のアドレスに送信します。ターゲット Web ページのサーバーにアクセスし、サーバーはクライアント (つまりクローラ) にデータを返します。その後、クローラはデータの解析や保存などの一連の操作を実行します。
プロセス
クローラーを使用すると時間を節約できます。たとえば、トップ 250 の Douban 映画を取得したい場合、クローラーを使用しない場合は、まず Douban 映画の URL を入力する必要があります。クライアント (ブラウザ) は分析によって Douban Movie Web ページのサーバーの IP アドレスを見つけて接続を確立し、ブラウザは HTTP リクエストを作成して Douban Movie サーバーに送信します。サーバーはリクエストを受信すると、データベースから Top250 リストを抽出し、それを HTTP レスポンスにカプセル化し、そのレスポンス結果をブラウザに返します。ブラウザはレスポンスの内容を表示し、データを確認します。私たちのクローラもこのプロセスに基づいていますが、コード形式に変更されています。
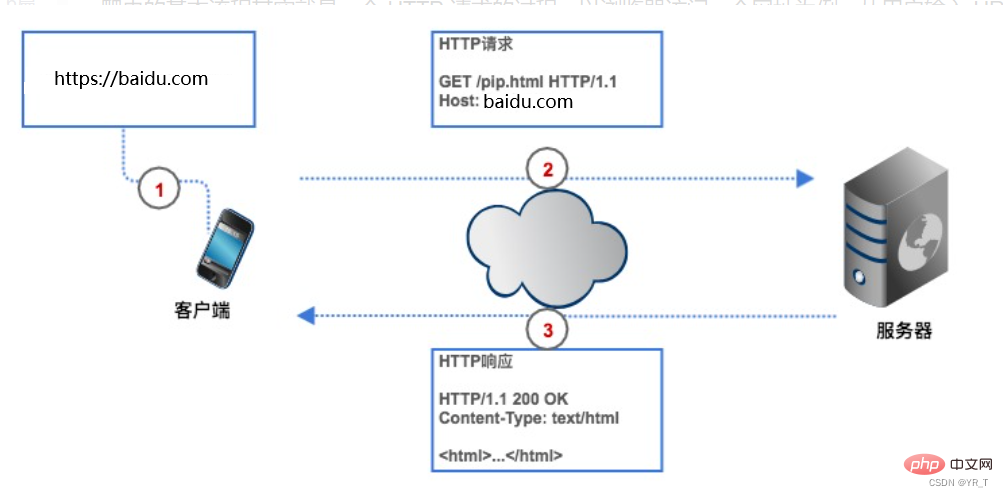
HTTP リクエスト
HTTP リクエストは、リクエスト行、リクエストヘッダー、空行、リクエストボディで構成されます。

リクエスト行は 3 つの部分で構成されます:
1. リクエスト メソッド。一般的なリクエスト メソッドは GET、POST、PUT、DELETE、HEAD
2. クライアントが取得したいリソース パス
3. クライアントが使用する HTTP プロトコルのバージョン番号です
リクエスト ヘッダーは、クライアントからサーバーに送信されるリクエストの補足的な説明です。訪問者の身元。これについては後述します。
リクエスト本文は、ユーザーがログインするときに改善する必要があるアカウントやパスワード情報など、クライアントによってサーバーに送信されるデータです。リクエストヘッダーとリクエストボディは空行で区切られます。リクエストボディはすべてのリクエストに含まれるわけではなく、たとえば一般的な GET にはリクエストボディがありません。
上の図は、ブラウザが Douban にログインするときにサーバーに送信される HTTP POST リクエストです。リクエスト本文にはユーザー名とパスワードが指定されています。
HTTP 応答
HTTP 応答の形式は要求形式と非常によく似ており、応答行、応答ヘッダー、空行、および応答本文で構成されます。

応答行には、サーバーの HTTP バージョン番号、応答ステータス コード、ステータスの説明という 3 つの部分も含まれています。
ここには、各ステータス コードの意味に対応するステータス コードの表があります



cmd 実行: pip install リクエストを実行してリクエストをインストールします。
import リクエストを入力して実行します。エラーが報告されなければ、インストールは成功です。 ほとんどのライブラリをインストールする方法は次のとおりです: pip install xxx (ライブラリの名前)次に、IDLE またはコンパイラ (個人的には VS Code または Pycharm をお勧めします) に
リクエストのメソッド
| リクエストを作成し、各メソッドの基本メソッドをサポートします | |
| HTML Web ページを取得する主なメソッド。HTTP の GET | |
| #HTTP HEAD に対応する HTML Web ページのヘッダー情報を取得するメソッド | requests.post() |
| requests.put() に対応する、HTML Web ページに POST リクエストを送信するメソッド | |
| requests.patch( ) | |
| ## に対応する、HTML Web ページへの部分的な変更リクエストを送信します。 | #requests.delete() |
| 最も一般的なのは、使用された get メソッド |
2 つの重要なオブジェクトが含まれています:
サーバーからリソースを要求する Request オブジェクトを構築し、次の内容を含む Response オブジェクトを返します。サーバー リソース
#r.status_code
| #r.text | HTTP 応答コンテンツの文字列形式、つまり URL |
| r.encoding | に対応するページ コンテンツHTTP ヘッダーから推測される応答コンテンツのエンコード方式 (ヘッダーの文字セットが存在しない場合、エンコードは ISO-8859-1 とみなされます) |
| r.apparent_encoding | コンテンツから分析された応答コンテンツのエンコード方式 (代替エンコード方式) |
| r.content | HTTP 応答コンテンツのバイナリ形式 |
| requests.HTTPError | HTTP エラー例外 |
| URL が欠落している例外 | |
| リダイレクトの最大数を超え、リダイレクト例外が生成されます | |
| タイムアウト例外リモート サーバーに接続するとき | #requests.Timeout |
| requests は最も基本的なクローラ ライブラリですが、簡単な翻訳を行うことができます | 最初に、私が作成した小さなクローラ プロジェクトのプロジェクト構造を置きます。ソースコードは私とのプライベートチャットでダウンロードできます。 |
以下は、翻訳部分のソース コードです。
import requests
def English_Chinese():
url = "https://fanyi.baidu.com/sug"
s = input("请输入要翻译的词(中/英):")
dat = {
"kw":s
}
resp = requests.post(url,data = dat)# 发送post请求
ch = resp.json() # 将服务器返回的内容直接处理成json => dict
resp.close()
dic_lenth = len(ch['data'])
for i in range(dic_lenth):
print("词:"+ch['data'][i]['k']+" "+"单词意思:"+ch['data'][i]['v'])
コードの詳細な説明:
リクエスト モジュールをインポートし、URL を設定しますBaidu 翻訳 Web ページの URL にアクセスします。
次に、post メソッドを通じてリクエストを送信し、返された結果を dic (辞書) に入力します。今回はそれを出力してみたところ、次のようになっています。これ。
辞書内のリスト内の辞書は次のようになります。おそらく次のようになります。 { xx:xx , xx:
{ xx:xx , xx:
 ]
]
青色でマークされたリストに n 個の辞書があると仮定すると、len() 関数を通じて n の値を取得でき、そして for ループを使用してトラバースして結果を取得できます。
dic_lenth = len(ch['data']
for i in range(dic_lenth):
print("词:"+ch['data'][i]['k']+" "+"单词意思:"+ch['data'][i]['v'])
最後にわかりました、今日の共有はこれで終わりです、さようなら~ねえ?一つ忘れていました。天気をクロールするコードをもう 1 つ教えてください。
# -*- coding:utf-8 -*-
import requests
import bs4
def get_web(url):
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59"}
res = requests.get(url, headers=header, timeout=5)
# print(res.encoding)
content = res.text.encode('ISO-8859-1')
return content
def parse_content(content):
soup = bs4.BeautifulSoup(content, 'lxml')
'''
存放天气情况
'''
list_weather = []
weather_list = soup.find_all('p', class_='wea')
for i in weather_list:
list_weather.append(i.text)
'''
存放日期
'''
list_day = []
i = 0
day_list = soup.find_all('h1')
for each in day_list:
if i <= 6:
list_day.append(each.text.strip())
i += 1
# print(list_day)
'''
存放温度:最高温度和最低温度
'''
tem_list = soup.find_all('p', class_='tem')
i = 0
list_tem = []
for each in tem_list:
if i == 0:
list_tem.append(each.i.text)
i += 1
elif i > 0:
list_tem.append([each.span.text, each.i.text])
i += 1
# print(list_tem)
'''
存放风力
'''
list_wind = []
wind_list = soup.find_all('p', class_='win')
for each in wind_list:
list_wind.append(each.i.text.strip())
# print(list_wind)
return list_day, list_weather, list_tem, list_wind
def get_content(url):
content = get_web(url)
day, weather, tem, wind = parse_content(content)
item = 0
for i in range(0, 7):
if item == 0:
print(day[i]+':\t')
print(weather[i]+'\t')
print("今日气温:"+tem[i]+'\t')
print("风力:"+wind[i]+'\t')
print('\n')
item += 1
elif item > 0:
print(day[i]+':\t')
print(weather[i] + '\t')
print("最高气温:"+tem[i][0]+'\t')
print("最低气温:"+tem[i][1] + '\t')
print("风力:"+wind[i]+'\t')
print('\n')
【関連する推奨事項:
Python3 ビデオ チュートリアル]
以上がPython クローラーを 1 つの記事で理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。