



今年の雇用情勢はとにかく暗いです。来年は今年よりも悪くなるだろうという「ラッキーメンタル」に基づき、迷わず退職を選択しました。1ヶ月半の努力の末、かなりの好成績をいただきました。給与とプラットフォームは大幅に改善されましたが、心理的な期待とはまだ大きなギャップがあります。したがって、最大の結論は、「裸で話してはいけない」ということです。裸で何も言わないでください!裸で何も言わないでください!面接で受けるプレッシャーや現実と理想のギャップによる精神的ダメージは計り知れないので、そのような環境で生き残るのは良い選択です。
関連おすすめ: 2023年フロントエンド面接の質問まとめ(集)
次に、経験する以下のことをまとめます。通常の状況下でのフロントエンド面接。4 つの段階と 3 つの決定要素:
 フロントエンド スタッフとして、テクノロジーの深さと幅広さが第一に挙げられます。3 年が分かれ目です。現時点では、自分自身の正しい方向性と方向性を見つけなければなりません。
フロントエンド スタッフとして、テクノロジーの深さと幅広さが第一に挙げられます。3 年が分かれ目です。現時点では、自分自身の正しい方向性と方向性を見つけなければなりません。
第二に、優れたコミュニケーションと表現スキル、服装とパフォーマンス、その他のオフサイトの要素により、面接官のあなたの認識が高まります。
非常に優秀な人もいますが、面接官は面接中に不快感を抱き、あなたのことを傲慢、だらしがない、独善的、自分の意見をはっきりと表現できないと考え、不採用にしてしまいます。それは最悪の損失です。 。
以下は、私の面接準備全体と私が聞かれた質問の概要です。面接プロセス中、面接官とのコミュニケーションは、多くの場合、単純な承認ではないからです。知識 自分なりの要約や簡潔さを表現し、面接官の質問に基づいてその場で補足・改善します。 [推奨学習: Web フロントエンド 、プログラミング教育 ]
1. 自己紹介
面接官は、自己紹介の範囲を制限するものではありません。面接官はあなたの自己紹介からあなたのことを知りたいと思っているはずです。そのため、自己紹介は簡潔かつスムーズでなければなりません。さまざまな面接官に直面する場合、自己紹介の内容は重要です。したがって、事前に言葉を準備し、つまずかないように、自信を持って注意を払うことが重要です。 スムーズな表現力やコミュニケーション能力も面接官による候補者の評価ポイントの一つです。私も面接官をしたことがありますが、自信があり寛大な候補者は、多くの場合、有利に扱われる可能性が高くなります。
1. 自己紹介 (基本的な状況) と主な履歴書がすべて用意されており、短くなければなりません
2. 技術的および非技術的なことを含む、自分の得意なこと。技術者はあなたの移行を理解でき、技術者以外の人はあなたを人間として理解できます
#3. これまでに行ったプロジェクトの中で最も核となるプロジェクトを選択し、すべてのプロジェクトを推薦のように紹介しないでください 4. あなた自身のアイデア、興味、意見、さらにはあなた自身のキャリアプラン。これが面接官に次のような感情を与えた場合: 「投げる」または「考える」ことに熱心です例: 面接官、こんにちは、私の名前は xxx、xx の xx 大学を卒業しました。卒業以来、フロントエンド開発関連の仕事に従事してきました。 私が得意とするテクノロジー スタックは vue ファミリー バケットであり、vue2 と vue3 の使用法とソース コードについてはある程度研究しており、パッケージ化ツールは webpack と vite に精通しており、私はこれまでに多くのことを経験してきました。中・大規模プロジェクトをゼロからイチまでプロジェクトを遂行する経験と能力。 前の会社では主にxx製品ラインの責任者として、主な業務を行っていました。 。 。 。 。 。 開発関連の仕事に加えて、要件レビュー、UI/UE インタラクション レビューの審査員、開発スケジュールの責任、メンバーのコラボレーション、メンバー コードのレビュー、組織化など、特定の技術管理の経験もあります。定例ミーティングなど普段は自分で構築したブログに学習記事や勉強メモを記録したり、オリジナルの技術記事を書いてナゲッツに公開したりしてxx賞を受賞しました。一般的に、自己紹介は 3 ~ 5 分以内に収めるようにしてください。まず、簡潔かつ要点を絞ったものにし、次に自分の能力や長所を強調することが重要です。 一般的な技術面接官にとって、自己紹介は面接前の習慣的な冒頭の言葉にすぎず、一般的に、履歴書に記載されている基本的な情報で、すでにあなたについての基本的な理解は満たされています。しかし、上司レベルの面接官や人事の場合は、あなたの性格、行動習慣、ストレス耐性などの総合的な能力を評価します。したがって、面接プロセス中はできるだけ前向きであること、継続的な学習が好き、チームワークが好きなど幅広い趣味を持っていること、無条件で残業できることが必要です。もちろんチートをさせるつもりはありませんが、この環境においてはこうした「サイドアビリティ」も競技力をある程度向上させる魔法の武器でもあります。
2. プロジェクト マイニング
現在の市場状況では、面接の通知を受け取った場合、それはあなたのプロジェクト経験とその経験によるものである可能性が高くなります。あなたが募集しているポジション。もっとラインに沿って。 したがって、プロジェクトの準備には次のような特別な注意を払う必要があります。- プロジェクトで使用されている
テクノロジ を深く掘り下げる
プロジェクトの管理全体設計アイデア
プロジェクトの管理運用プロセス
チームコラボレーション能力。
- プロジェクトの
最適化ポイントは何ですか
3. 個人的なこと
まず個人的なことについて話させてください。技術面接に合格し、上司や人事の段階に到達したとき、たとえ現在の能力がどれほど素晴らしくても、あなたの個人的な可能性、学習能力、性格、チーム統合、その他のソフト スキルを調べることに加えて、よく聞かれるいくつかの質問を以下に示します。なぜ転職したのですか。 ?
個人開発から直接始めて、野心を示す:- 私は、技術的な雰囲気が優れているだけでなく、より大きなプラットフォームに行きたいと常々思っていました。 、しかしまた、より多くのことを学びました 知識を広げたいです。以前は、いつも x 側で xx 製品を作っていました。技術スタックは比較的単純だったので、xx を勉強しました。
- 私は前職ではコンフォートゾーンに陥ってしまい、それしかできませんでした。プラットフォームを変更して技術の幅を広げ、新しい技術システムに触れて学びたいと考えています。
あなたと通常のフロントエンドについて教えてください。あなたのハイライトは何ですか?
1. 計画と要約が得意です。担当するプロジェクトを総合的に分析します。1 つはマインドマップを使用して各モジュールの業務を分解する業務分解、もう 1 つはそれを実行することです。コードモジュールを分解し、各コードモジュールを機能に応じて区別することです。再び開発に行きます。これは、やみくもにビジネス開発を行う多くのフロントエンドではできないことだと思います。2. 私はテクノロジーを専門とするのが好きで、普段は vue のソース コードを学習し続けており、自分の開発したコードもアウトプットしています。以前に書いたような独自の技術記事teleport のソース コード を 1 行ずつ集中的に読み、書くのに約 30 時間かかりました。ソース コードの各行の機能と役割が説明されています (しかし、なぜ閲覧数といいね数がこんなに低いのでしょう)。
あなたの欠点は何ですか?
私は比較的真面目な気質で内向的なほうなので、自分ももっと外向的になるように努力します。 1つは様々な検討会を開催することですが、フロントエンドの代表として様々な資料を用意したり、スピーチをしたりする必要があります。 そのため、チーム内で技術的な共有を強化し、毎週定期的にミーティングを主催しています。これにより、表現したり話し合ったりする勇気も得られます。最近何か新しいテクノロジーに注目しましたか?
- #パッケージ依存関係管理ツール pnpm (依存関係の繰り返しインストールなし、非フラットなノードモジュール構造、シンボリック リンクを介した依存パッケージの追加)
- ##パッケージ化ツール vite (非常に高速な開発環境)
- flutter (クロスプラットフォーム、高忠実度、高パフォーマンスに重点を置いた、Google のオープンソース モバイル アプリケーション (アプリ) 開発フレームワーク)
- rust (js の将来のベースになると聞きました)
- webpack の後継であるturbopack は、webpack の 10 倍高速であると言われています。 vite、webpack は 700 倍高速であり、You Yuxi は vite の 10 倍ではないことを個人的に検証しました
- webcomponents
私の個人的な計画は次のとおりです。
3 ~ 5 年で技術的な深みを向上させると同時に、知識の幅、つまり深さと幅を広げていきます。改善するには、主に幅広い点が重要です。主要なフロントエンドを完全に理解した場合にのみ、より良い選択ができるようになります
5 ~ 7 年は、選択する前に蓄積する十分な知識が得られる時期です特定の興味の方向性。さらに勉強して、その分野の専門家になるよう努力してください。
チームの規模、チームの仕様、開発プロセスこれは人によって異なります。規模が異なると、チームの研究開発モデルも大きく異なるため、正直に準備してください。
コードレビューの目標1. 最も重要なことはコードの保守性です (変数の名前付け、コメント、関数の統一原則など)
2. 拡張性: カプセル化機能 (コンポーネントとコード ロジックが再利用可能かどうか、スケーラビリティ)
3. ES の新機能 (es6、ES2020、ES2021 のオプション チェーン、at)
4 . 関数の使用仕様 (たとえば、マップを forEach として使用する場合)
5. パフォーマンスの向上、アルゴリズムを使用してよりエレガントでパフォーマンスの高いコードを記述する方法
How to lead a codeチーム
私は前の会社で技術管理の役割を担っていました。
0,
開発仕様の実装, 名前付け、ベスト プラクティスからさまざまなツール ライブラリの使用方法まで、社内 Wiki に投稿しました。新しい人が入ってきた初期の段階では、彼らのコードの品質を優先的にフォローします。1.
チーム分業: 各人が製品の開発に責任を負いますその後、通常は公開モジュールを開発するために数人を指名します 2、コード品質保証: コードは毎週レビューされ、クロスレビューされたコードが整理され、修正結果の出力記事が wiki 定期的な組織会議 : 定期的な組織会議を毎週開催し、それぞれの進捗状況とリスクを同期し、それぞれの進捗状況に応じて作業タスクを割り当てます テクノロジー共有: 不定期で技術共有も開催します。当初は、マイクロ フロントエンド システム、ice stark のソース コード パブリック デマンド プール : webpack5/vite のアップグレードなどを共有するのは私だけでした。 vue2.7 セットアップ構文シュガーのアップグレードの導入、pnpm の使用、トポロジ マップのパフォーマンスの最適化 最適化プロジェクト: 製品の最初のバージョンがリリースされた後、私も最初の画面の読み込みパフォーマンスを向上させるために、特別なパフォーマンス最適化プロジェクトを開始しました。パッケージング量の最適化。対応する最適化項目を全員が責任を負います それから記事を書きます。他の人のコンテンツを記録し、自分のオリジナルの記事を書くだけなので、単にメモを取ることを忘れがちです。このプロセスでは、非常に高い割合の知識が自分のものに変換されるため、自分の金鉱の記事に加えて, また、プロジェクトの成果物に関する記事を wiki に出力することもよくあります 私の他の趣味は、友達とバスケットボールをしたり歌うことです 。面接は面接官との対面でのコミュニケーションであるため、要点を話さずに長時間おしゃべりするような候補者は面接官からは好まれません。興味のない部分は無視するので、特定のテクノロジーのコア機能を強調し、そのコアを中心に適切に拡張する必要があります。 大手企業は基本的にアルゴリズムの質問で候補者を選考します。アルゴリズムに近道はありません。段階的に質問に答えて、また質問に答えるしかありません。この点が苦手な方は、事前に計画を立てて勉強してください。 。 技術面接プロセスでは、主にフロントエンド分野に関連するテクノロジーに関する質問が行われます。通常、面接官は貴社の事業所に基づいて質問されますが、多くの場合、面接官は面接での質問に基づいて質問されます。比較的よく知っている技術的な内容を質問するのは、未知のことばかりなので、あらゆる面でかなり厳しいものです。 もしあなたが発展性の高い中~大企業に入りたいのであれば、他人の経験を丸暗記するだけで自分を騙すことはできません。ここでの各要約は非常に短いものですが、これらはすべて私がいくつかを洗練させたものです。各知識を総合的に学習した上で核となる知識を学ぶので、面接官の「思考の発散」を恐れません。 面接プロセスでは、通常、次の 8 つの主要な種類の知識が考慮されます: JS/CSS/TypeScript/フレームワーク (Vue、React)/ブラウザとネットワーク/パフォーマンスの最適化/フロントエンジニアリング/アーキテクチャ/その他 は基本的にOKです 一般的な JS 面接の質問には、一般に次のようなものがあります。 です。 コンストラクターを作成すると、この関数にはデフォルトで 属性が設定され、この属性の値はこの関数のプロトタイプ オブジェクトを指します。 したがって、コンストラクター関数 は、この関数のプロトタイプ オブジェクトから上記の属性を継承します インスタンスの属性を読み取るときに、インスタンスが見つからない場合は、そのオブジェクトに関連付けられたプロトタイプ内の属性を探します。見つからない場合は、プロトタイプのプロトタイプが見つかるまで探します。トップレベル (トップレベルは つまり、プロトタイプを介して層ごとに相互接続されたチェーン構造は、プロトタイプチェーンと呼ばれます。 定義: クロージャは、他の関数のスコープ内の変数を参照する関数 を指し、通常はネストされた関数で実装されます。
vue 内のデータはクロージャである必要がありますパッケージを使用して、各データ内のデータが一意であることを確認し、コンポーネントへの複数の参照によって引き起こされるデータ共有を回避します カリー関数 js コードの実行中に、対応する実行コンテキストが作成され、実行コンテキスト スタックにプッシュされます。 イベント キューは とマイクロ タスク キューに分かれています。現在の実行スタックが空の場合、メインスレッドはまずマイクロ タスク キューにイベントがあるかどうかを確認します。 . イベントがあればマイクロタスクキューを順番に実行し、マイクロタスクキューが空になるまでタスクキュー内のイベントをコールバックし、存在しない場合はマクロタスクキューで処理します。 setTimeout()、 、setImmediate()、I/O 、ユーザー インタラクション、UI レンダリング ,new MutationObserver# が含まれます##、process.nextTick() マイクロ タスクには、実行が必要な明確な非同期タスクはなく、コールバックのみがあり、必要はありません。他の非同期スレッドからのサポート。 v8 ガベージ コレクションについて話す 1. 通常の 2. 3. new download フェーズ は非同期実行になります (HTML 解析と同期); キャプチャ ステージ: イベントより具体性の低いノードが最初にイベントを受信し、最も具体的なノード (トリガー ノード) が最後にイベントを受信します。イベントが最終目的地に到着する前に阻止すること。 ターゲット フェーズ イベントはターゲット ノード でトリガーされ (イベントに対応する関数を実行します)、最も外側のドキュメント ノードに伝播されるまで逆に流れます。 バブリング フェーズ 拡張子 1#e.target と e.currentTarget の違いは何ですか? イベントは ul にバインドされています。li をクリックすると、ターゲットはクリックされた li になり、currentTarget はバインドされたイベントの ul になります イベントのバブリング段階 (上記の例) では、 と を使用して # を実装できます## イベント委任 addEventListener パラメータ インターフェイスまたは capture: ブール値。イベント キャプチャ フェーズが EventTarget に伝播されるときにリスナーがトリガーされるかどうか 著者は主に Vue 関連の開発に従事しており、反応関連のプロジェクトも行っています。プロジェクトを実行することです。履歴書に記載されているようなものです。フレームワークの価値はそれほど多くはありませんが、その本質にあります。Vue のソース コード シリーズを学ぶことで、Vue に非常に自信が持てるようになります。学習プロセスも同様で、あるフレームワークの原則をマスターできれば、他のフレームワークを学習するのは時間の問題です。 1. データの変動性 2. 記述方法 3 、 diff アルゴリズム 拡張: React フックをご存知ですか? コンポーネント クラスの記述は非常に重く、レベルが多すぎるとメンテナンスが困難になります。 。 関数コンポーネントは純粋な関数であり、状態を含めることはできず、ライフサイクル メソッドをサポートしていないため、クラスを置き換えることはできません。 #React Hooks の設計目的は、機能コンポーネントを強化することです。「クラス」をまったく使用せずに完全に機能するコンポーネントを作成できます #vue コンポーネント通信メソッド patchKeyedChildren と呼ばれます。この関数は、コア diff アルゴリズムを実装するためのよく知られた場所です。おおよそのプロセスは、ヘッド ノードを同期し、テール ノードを同期することです。ノードを作成し、新しいノードの追加と削除を処理し、最後に最長増加サブシーケンスを解く方法を使用して未知のサブシーケンスを処理します。これは、既存のノードの再利用を最大限に高め、DOM 操作のパフォーマンスのオーバーヘッドを削減し、インプレース更新によって引き起こされる子ノードのステータス エラーの問題を回避するためです。 まとめると、v-forを使って定数を走査したり、子ノードがプレーンテキストなどの「状態」を持たないノードであれば、キーを追加せずに書く方法が使えます。ただし、実際の開発プロセスでは、より幅広いシナリオを実現し、ステータス更新エラーを回避できるように、キーを均一に追加することをお勧めします。通常、ESlint を使用してキーを v-for の必須要素として設定できます。 想详细了解这个知识点的可以去看看我之前写的文章:v-for 到底为啥要加上 key? vue2使用的是 所以 vue3 采用了 其实从api的原生性能上 而 vue 做的响应式性能优化主要是在将嵌套层级比较深的对象变成响应式的这一过程。 vue2的做法是在组件初始化的时候就递归执行 而vue3是在访问到子对象属性的时候,才会去将它转换为响应式。这种延时定义子对象响应式会对性能有一定的提升 前提:当同类型的 vnode 的子节点都是一组节点(数组类型)的时候, 步骤:会走核心 diff 流程 Vue3是快速选择算法 Vue2是双端比较算法 在新旧字节点的头尾节点,也就是四个节点之间进行对比,找到可复用的节点,不断向中间靠拢的过程 diff目的:diff 算法的目的就是为了尽可能地复用节点,减少 DOM 频繁创建和删除带来的性能开销 基于 MVVM 模型,viewModel(业务逻辑层)提供了数据变化后更新视图和视图变化后更新数据这样一个功能,就是传统意义上的双向绑定。 Vue2.x 实现双向绑定核心是通过三个模块:Observer监听器、Watcher订阅者和Compile编译器。 首先监听器会监听所有的响应式对象属性,编译器会将模板进行编译,找到里面动态绑定的响应式数据并初始化视图;watchr 会去收集这些依赖;当响应式数据发生变更时Observer就会通知 Watcher;watcher接收到监听器的信号就会执行更新函数去更新视图; vue3的变更是数据劫持部分使用了porxy 替代 Object.defineProperty,收集的依赖使用组件的副作用渲染函数替代watcher vue2 v-model 原理剖析 V-model 是用来监听用户事件然后更新数据的语法糖。 其本质还是单向数据流,内部是通过绑定元素的 value 值向下传递数据,然后通过绑定 input 事件,向上接收并处理更新数据。 单向数据流:父组件传递给子组件的值子组件不能修改,只能通过emit事件让父组件自个改。 给组件添加 如果想给绑定的 value 属性和 input 事件换个名称呢?可以这样: 在 Vue 2.2 及以上版本,你可以在定义组件时通过 model 选项的方式来定制 prop/event: vue3 v-model 原理 实现和 vue2 基本一致 等同于 自定义 model 参数 不管vue2 还是 vue3,响应式的核心就是观察者模式 + 劫持数据的变化,在访问的时候做依赖收集和在修改数据的时候执行收集的依赖并更新数据。具体点就是: vue2 的话采用的是 Vue3 使用的是 ES6 的 proxy,proxy 不仅能够追踪属性的获取和修改,还可以追踪对象的增删,这在 vue2中需要 delete 才能实现。然后就是收集的依赖是用组件的副作用渲染函数替代 watcher 实例。 性能方面,从原生 api 角度,proxy 这个方法的性能是不如 Object.property,但是 vue3 强就强在一个是上面提到的可以追踪对象的增删,第二个是对嵌套对象的处理上是访问到具体属性才会把那个对象属性给转换成响应式,而 vue2 是在初始化的时候就递归调用将整个对象和他的属性都变成响应式,这部分就差了。 扩展一 vue2 通过数组下标更改数组视图为什么不会更新? 尤大:性能不好 注意:vue3 是没问题的 why 性能不好? 我们看一下响应式处理: 对于对象是通过 理由是数组的键相较对象多很多,当数组数据大的时候性能会很拉胯。所以不开放 Computed 的大体实现和普通的响应式数据是一致的,不过加了延时计算和缓存的功能: 在访问computed对象的时候,会触发 getter ,初始化的时候将 computed 属性创建的 watcher (vue3是副作用渲染函数)添加到与之相关的响应式数据的依赖收集器中(dep),然后根据里面一个叫 dirty 的属性判断是否要收集依赖,不需要的话直接返回上一次的计算结果,需要的话就执行更新重新渲染视图。 watchEffect? watchEffect会自动收集回调函数中响应式变量的依赖。并在首次自动执行 推荐在大部分时候用 vue有个机制,更新 DOM 是异步执行的,当数据变化会产生一个异步更行队列,要等异步队列结束后才会统一进行更新视图,所以改了数据之后立即去拿 dom 还没有更新就会拿不到最新数据。所以提供了一个 nextTick 函数,它的回调函数会在DOM 更新后立即执行。 nextTick 本质上是个异步任务,由于事件循环机制,异步任务的回调总是在同步任务执行完成后才得到执行。所以源码实现就是根据环境创建异步函数比如 Promise.then(浏览器不支持promise就会用MutationObserver,浏览器不支持MutationObserver就会用setTimeout),然后调用异步函数执行回调队列。 所以项目中不使用$nextTick的话也可以直接使用Promise.then或者SetTimeout实现相同的效果 1、全局错误处理: 如果在组件渲染时出现运行错误,错误将会被传递至全局 比如前端监控领域的 sentry,就是利用这个钩子函数进行的 vue 相关异常捕捉处理 2、全局警告处理: 注意:仅在开发环境生效 像在模板中引用一个没有定义的变量,它就会有warning 3、单个vue 实例错误处理: 和组件相关,只适用于开发环境,这个用处不是很大,不如直接看控制台 4、子孙组件错误处理: 注:只能在组件内部使用,用于捕获子孙组件的错误,一般可以用于组件开发过程中的错误处理 5、终极错误捕捉: 它是一个全局的异常处理函数,可以抓取所有的 JavaScript 异常 Vuex 利用 vue 的mixin 机制,在beforeCreate 钩子前混入了 vuexinit 方法,这个方法实现了将 store 注入 vue 实例当中,并注册了 store 的引用属性 store.xxx`去引入vuex中定义的内容。 然后 state 是利用 vue 的 data,通过 概念 可以通过全局方法 该方法第一个参数必须是 所以** 源码实现 使用方式 要暴露一个 Css直接面试问答的题目相对来说比较少,更多的是需要你能够当场手敲代码实现功能,一般来说备一些常见的布局,熟练掌握flex基本就没有什么问题了。 Block Formatting context,块级格式上下文 BFC 是一个独立的渲染区域,相当于一个容器,在这个容器中的样式布局不会受到外界的影响。 比如浮动元素、绝对定位、overflow 除 visble 以外的值、display 为 inline/tabel-cells/flex 都能构建 BFC。 常常用于解决 处于同一个 BFC 的元素外边距会产生重叠(此时需要将它们放在不同 BFC 中); 清除浮动(float),使用 BFC 包裹浮动的元素即可 阻止元素被浮动元素覆盖,应用于两列式布局,左边宽度固定,右边内容自适应宽度(左边float,右边 overflow) 伪类 伪类即:当元素处于特定状态时才会运用的特殊类 开头为冒号的选择器,用于选择处于特定状态的元素。比如 伪元素 伪元素用于创建一些不在文档树中的元素,并为其添加样式。比如说,我们可以通过 href是Hypertext Reference的简写,表示超文本引用,指向网络资源所在位置。href 用于在当前文档和引用资源之间确立联系 src是source的简写,目的是要把文件下载到html页面中去。src 用于替换当前内容 浏览器解析方式 当浏览器遇到href会并行下载资源并且不会停止对当前文档的处理。(同时也是为什么建议使用 link 方式加载 CSS,而不是使用 @import 方式) 当浏览器解析到src ,会暂停其他资源的下载和处理,直到将该资源加载或执行完毕。(这也是script标签为什么放在底部而不是头部的原因) flex flex + margin Transform + absolute 注:使用该方法只适用于行内元素(a、img、label、br、select等)(宽度随元素的内容变化而变化),用于块级元素(独占一行)会有问题,left/top 的50%是基于图片最左侧的边来移动的,tanslate会将多移动的图片自身的半个长宽移动回去,就实现了水平垂直居中的效果 display: table-cell 浏览器和网络是八股中最典型的案例了,无论你是几年经验,只要是前端,总会有问到你的浏览器和网络协议。 最好的学习文章是李兵老师的《浏览器工作原理与实践》 这里分了同源页面和不同源页面的通信。 不同源页面可以通过 iframe 作为一个桥梁,因为 iframe 可以指定 origin 来忽略同源限制,所以可以在每个页面都嵌入同一个 iframe 然后监听 iframe 中传递的 message 就可以了。 同源页面的通信大致分为了三类:广播模式、共享存储模式和口口相传模式 第一种广播模式,就是可以通过 BroadCast Channel、Service Worker 或者 localStorage 作为广播,然后去监听广播事件中消息的变化,达到页面通信的效果。 第二种是共享存储模式,我们可以通过Shared Worker 或者 IndexedDB,创建全局共享的数据存储。然后再通过轮询去定时获取这些被存储的数据是否有变更,达到一个的通信效果。像常见cookie 也可以作为实现共享存储达到页面通信的一种方式 最后一种是口口相传模式,这个主要是在使用 window.open 的时候,会返回被打开页面的 window 的引用,而在被打开的页面可以通过 window.opener 获取打开它的页面的 window 点引用,这样,多个页面之间的 window 是能够相互获取到的,传递消息的话通过 postMessage 去传递再做一个事件监听就可以了 在浏览器第一次发起请求服务的过程中,会根据响应报文中的缓存标识决定是否缓存结果,是否将缓存标识和请求结果存入到浏览器缓存中。 HTTP 缓存分为强制缓存和协商缓存两类。 强制缓存就是请求的时候浏览器向缓存查找这次请求的结果,这里分了三种情况,没查找到直接发起请求(和第一次请求一致);查找到了并且缓存结果还没有失效就直接使用缓存结果;查找到但是缓存结果失效了就会使用协商缓存。 强制缓存有 Expires 和 Cache-control 两个缓存标识,Expires 是http/1.0 的字段,是用来指定过期的具体的一个时间(如 Fri, 02 Sep 2022 08:03:35 GMT),当服务器时间和浏览器时间不一致的话,就会出现问题。所以在 http1.1 添加了 cache-control 这个字段,它的值规定了缓存的范围(public/private/no-cache/no-store),也可以规定缓存在xxx时间内失效(max-age=xxx)是个相对值,就能避免了 expires带来的问题。 ネゴシエーション キャッシュとは、強制キャッシュのキャッシュ結果が無効になる処理であり、ブラウザはキャッシュ識別子を持ってサーバーにリクエストを送信し、サーバーはキャッシュ識別子を介してキャッシュを使用するかどうかを決定します。 。 ネゴシエーション キャッシュを制御するフィールドには、last-modified / if-modified-since および Etag / if-none-match が含まれており、後者の優先順位が高くなります。 一般的なプロセスでは、リクエスト メッセージを通じて last-modified または Etag の値をサーバーに渡し、サーバー内の対応する値と比較します。応答メッセージ内の -none-match 一貫性がある場合、ネゴシエーション キャッシュは有効であり、キャッシュされた結果が使用され、304 が返されます。そうでない場合は、無効で、結果が再度要求され、200 が返されます。を使用すると、ブラウザはまずコンテンツが検索コンテンツであるか URL であるかを判断します。検索コンテンツの場合は、デフォルトの検索エンジンと組み合わせて URL を生成します。たとえば、Google ブラウザは goole.com/search? xxxx. URL の場合は、http/https などのプロトコルを結合します。ページがアップロード前時間を監視しない場合、または実行プロセスの続行に同意する場合、ブラウザのアイコン バーは読み込み状態になります。 その後、TCP スリーウェイ ハンドシェイクによりブラウザとサーバー間の接続が確立され、データ送信が行われます。データ送信が完了したら、手を 4 回振ると切断されます。 が設定されているため、常に接続を維持できます。 ネットワーク プロセスは、TCP を通じて取得したデータ パケットを解析します。まず、応答ヘッダーのコンテンツ タイプに基づいてデータ タイプが決定されます。バイト ストリームまたはファイル タイプの場合は、次のようになります。ダウンロードのためにダウンロード マネージャーに引き渡され、ナビゲーション プロセスは終了します。 text/html タイプの場合は、レンダリングするドキュメントを取得するようにブラウザ プロセスに通知されます。 ブラウザのプロセスは、レンダリング通知を受け取り、現在のページと新しく入力されたページに基づいて同じサイトであるかどうかを判断し、同じサイトである場合は、以前の Web ページで作成されたレンダリング プロセスを再利用します。レンダリングプロセスを新たに作成します。 ブラウザは、レンダリング プロセスから「送信の確認」メッセージを受信すると、ブラウザのページ ステータス (セキュリティ ステータス、アドレス バー URL、前方および後方履歴メッセージなど) を更新し、Web ページを更新します。時間 ページは白紙ページ(白い画面)です。 (キー メモリ) 最後に、レンダリング プロセスは、ページの解析とドキュメントのサブリソースの読み込みを実行します。レンダリング プロセスは、HTML をDOM ツリー構造、および CSS をスタイルシート (CSSOM) に変換します。次に、DOM ツリーをコピーし、表示されていない要素を除外して基本的なレンダリング ツリーを作成し、各 DOM ノードのスタイルを計算し、各ノードの位置レイアウト情報を計算してレイアウト ツリーを構築します。 レイヤは、レイヤ化コンテキストがある場合、またはトリミングが必要な場合に独立して作成されます。これはレイヤ化と呼ばれます。最終的にレイヤ化されたツリーが形成されます。レンダリング プロセスでは、レイヤごとに描画リストが生成され、それが送信されます。合成スレッドは、レイヤーをタイルに分割し (レイヤーのすべてのコンテンツを一度に描画することを回避し、ビューポート部分はタイルの優先順位に従ってレンダリングできます)、タイルをラスター化スレッドでビットマップに変換します。プール。 変換が完了すると、合成スレッドは描画ブロック コマンド DrawQuard をブラウザ プロセスに送信し、ブラウザは DrawQuard メッセージに基づいてページを生成し、ブラウザ上に表示します。 ブラウザのレンダリング プロセスは、HTML を dom ツリーに解析し、css を cssom ツリーに解析します。次に、最初に DOM ツリーをコピーして、次に、表示要素(display: none など)を cssom と組み合わせて各 dom ノードのレイアウト情報を計算し、レイアウト ツリーを構築します。 レイアウト ツリーが生成されると、レイヤーのスタッキング コンテキストまたはトリミングされた部分に従って階層化され、階層ツリーが形成されます。 レンダリング プロセスでは、各レイヤーの描画リストが生成され、それが合成スレッドに送信されます。一度限りのレンダリングを避けるために、合成スレッドはブロック単位でレンダリングします。レイヤーをタイルに分割して渡します。ラスタライズ スレッド プールを介してタイルをビットマップに変換します。 変換が完了すると、合成スレッドはタイルを表示するためにブラウザに描画するコマンドを送信します UDP は User Dataprogram Protocol (ユーザー データプログラム プロトコル) IP は、IP アドレス情報を介して指定されたコンピューターにデータ パケットを送信します。最後に、UDP はポート番号を通じてデータ パケットを正しいプログラムに配布できます。 UDP は、データが正しいかどうかを検証できますが、再送機構がなく、間違ったデータ パケットを破棄するだけであり、送信後に宛先に到達したかどうかを確認することはできません。 UDPはデータの信頼性は保証できませんが、伝送速度が非常に速いため、オンラインビデオやインタラクティブゲームなど、データの完全性が厳密に保証されない分野でよく使用されます。 TCP は、UDP データが失われやすく、データ パケットを正しく組み立てることができないという問題を解決するために導入された伝送制御プロトコル (Transmission Control Protocol) です。ストリーム用のベースのトランスポート層通信プロトコル。 TCP は、パケット損失に対処するための再送信メカニズムを提供し、順序が乱れたデータ パケットを完全なファイルに結合できるパケット ソート メカニズムを導入します。 接続フェーズ ##このフェーズでは、受信側は各パケットを確認する必要があります; 切断フェーズ 4 回手を振って、双方が確立した接続を切断できることを確認します #3に入ります。サーバーはデータ送信完了後、クライアントにFINパケットを送信します。このとき、サーバーはLAST_ACK状態 FIN ACK ACK FIN クロスドメインの共通ソリューション クロスドメインとは何ですか? 解決策 <script></script> 2、 一般使用 cors(跨域资源共享)来解决跨域问题,浏览器在请求头中发送origin字段指明请求发起的地址,服务端返回Access-control-allow-orign,如果一致的话就可以进行跨域访问 3、 Iframe 解决主域名相同,子域名不同的跨域请求 4、 浏览器关闭跨域限制的功能 5、 http-proxy-middleware 代理 预检 补充:http会在跨域的时候发起一次预检请求,“需预检的请求”要求必须首先使用OPTIONS方法发起一个预检请求到服务器,以获知服务器是否允许该实际请求。“预检请求”的使用,可以避免跨域请求对服务器的用户数据产生未预期的影响。 withCredentials为 true不会产生预请求;content-type为application/json会产生预请求;设置了用户自定义请求头会产生预检请求;delete方法会产生预检请求; xss基本概念 Xss (Cross site scripting)跨站脚本攻击,为了和 css 区别开来所以叫 xss Xss 指黑客向 html 或 dom 中注入恶意脚本,从而在用户浏览页面的时候利用注入脚本对用户实施攻击的手段 恶意脚本可以做到:窃取 cookie 信息、监听用户行为(比如表单的输入)、修改DOM(比如伪造登录界面骗用户输入账号密码)、在页面生成浮窗广告等 恶意脚本注入方式: 存储型 xss 黑客利用站点漏洞将恶意 js 代码提交到站点服务器,用户访问页面就会导致恶意脚本获取用户的cookie等信息。 反射性 xss 用户将一段恶意代码请求提交给 web 服务器,web 服务器接收到请求后将恶意代码反射到浏览器端 基于 DOM 的 xss 攻击 通过网络劫持在页面传输过程中更改 HTML 内容 前两种属于服务端漏洞,最后一种属于前端漏洞 防止xss攻击的策略 1、服务器对输入脚本进行过滤或者转码,比如将 2、充分利用内容安全策略 CSP(content-security-policy),可以通过 http 头信息的 content-security-policy 字段控制可以加载和执行的外部资源;或者通过html的meta 标签 3、cookie设置为 http-only, cookie 就无法通过 csrf基本概念 Csrf(cross site request forgery)跨站请求伪造,指黑客引导用户访问黑客的网站。 CSRF 是指黑客引诱用户打开黑客的网站,在黑客的网站中,利用用户的登录状态发起的跨站请求。简单来讲,CSRF 攻击就是黑客利用了用户的登录状态,并通过第三方的站点来做一些坏事。 Csrf 攻击场景 自动发起 get 请求 比如黑客网站有个图片: 黑客将转账的请求接口隐藏在 img 标签内,欺骗浏览器这是一张图片资源。当该页面被加载时,浏览器会自动发起 img 的资源请求,如果服务器没有对该请求做判断的话,那么服务器就会认为该请求是一个转账请求,于是用户账户上的 100 极客币就被转移到黑客的账户上去了。 自动发起 post 请求 黑客在页面中构建一个隐藏的表单,当用户点开链接后,表单自动提交 引诱用户点击链接 比如页面上放了一张美女图片,下面放了图片下载地址,而这个下载地址实际上是黑客用来转账的接口,一旦用户点击了这个链接,那么他的极客币就被转到黑客账户上了 防止csrf方法 1、设置 cookie 时带上SameSite: strict/Lax选项 2、验证请求的来源站点,通过 origin 和 refere 判断来源站点信息 3、csrf token,浏览器发起请求服务器生成csrf token,发起请求前会验证 csrf token是否合法。第三方网站肯定是拿不到这个token。我们的 csrf token 是前后端约定好后写死的。 websocket是一种支持双向通信的协议,就是服务器可以主动向客户端发消息,客户端也可以主动向服务器发消息。 HTTP プロトコルに基づいて接続を確立し、http プロトコルとの互換性が高いため、HTTP プロキシ サーバーを通過でき、送信元の制限はありません。 WebSocket はイベント駆動型のプロトコルであるため、真のリアルタイム通信に使用できます。 HTTP (常に更新を要求する必要がある) とは異なり、WebSocket を使用すると、更新が利用可能になるとすぐに送信されます WebSocket は、接続が終了したときに自動的に回復しません。これは、によって実装する必要があるメカニズムです。これは、クライアント側のオープン ソース ライブラリが数多く存在する理由の 1 つでもあります。 webpack や vite などの開発サーバーは、WebSocket を使用してホット アップデートを実装します パフォーマンスの最適化は、フロント部門の KPI と密接に関係しているため、中堅企業や大企業が非常に注目しているポイントです。末端の人なら当然面接の質問として使われるでしょう。 #不要なリクエストを減らし、不要なコードを削除します コード圧縮、パッケージ化された静的リソースのサイズの削減 (Terser プラグイン/MiniCssExtratplugin) 画像の遅延読み込み: vue-lazyLoad Web ページのパフォーマンス指標: 首屏渲染时间计算:通过 首先应该避免直接使用 DOM API 操作 DOM,像 vue react 虚拟 DOM 让对 DOM 的多次操作合并成了一次。 样式集中改变,好的方式是使用动态 class 读写操作分离,避免读后写,写后又读 原来的操作会导致四次重排,读写分离之后实际上只触发了一次重排,这都得益于浏览器的渲染队列机制: 当我们修改了元素的几何属性,导致浏览器触发重排或重绘时。它会把该操作放进渲染队列,等到队列中的操作到了一定的数量或者到了一定的时间间隔时,浏览器就会批量执行这些操作。 使用 通过 documentFragment 创建 dom 片段,在它上面批量操作 dom ,操作完后再添加到文档中,这样只有一次重排(示例:一次性插入2000个div) 复制节点在副本上操作然后替换它 使用 BFC 脱离文档流,重排开销小 Css 中的 优化请求数 减小图片大小 缓存 非响应式变量可以定义在 访问局部变量比全局变量块,因为不需要切换作用域 尽可能使用 使用 v8 引擎时,运行期间,V8 会将创建的对象与隐藏类关联起来,以追踪它们的属性特征。能够共享相同隐藏类的对象性能会更好,v8 会针对这种情况去优化。所以为了贴合”共享隐藏类“,我们要避免”先创建再补充“式的动态属性复制以及动态删除属性(使用delete关键字)。即尽量在构造函数/对象中一次性声明所有属性。属性删除时可以设置为 null,这样可以保持隐藏类不变和继续共享。 避免内存泄露的方式 避免强制同步,在修改 DOM 之前查询相关值 避免布局抖动(一次 JS 执行过程中多次执行强制布局和抖动操作),尽量不要在修改 DOM 结构时再去查询一些相关值 合理利用 css 合成动画,如果能用 css 处理就交给 css。因为合成动画会由合成线程执行,不会占用主线程 避免频繁的垃圾回收,优化存储结构,避免小颗粒对象的产生 感兴趣的可以看看我之前的一篇性能优化技巧整理的文章极意 · 代码性能优化之道 前端工程化是前端er成長路上最不可或缺的技能點,一切能夠提升前端開發效率的功能都可以當做前端工程化的一部分。剛入門的可以從零搭建鷹架開始萬字長文詳解從零搭建企業級vue3 vite2 ts4 框架全過程 對於面試而言,考察的最多的還是對打包工具的掌握程度。 webpack 是為現代 JS 應用程式提供靜態資源打包功能的 bundle。 核心流程有三個階段: 初始化階段、建置階段和生成階段 1、初始化階段,會從設定檔、設定物件和Shell參數讀取初始化的參數並與預設配置結合成最終的參數,之以及創建compiler 編譯器物件和初始化它的運行環境 2、建置階段,編譯器會執行它的run()方法開始編譯的過程,其中會先確認entry 入口文件,從入口文件開始搜尋和入口文件有直接或簡介關聯的所有文件創建依賴對象,之後再根據依賴對象創建module 對象,這時候會使用loader 將模組轉換標準的js 內容,再調用js 的解釋器將內容轉換成AST 對象,再從AST 找到該模組所依賴的模組,遞歸本步驟知道所有入口依賴檔案都經過了本步驟的處理。最後完成模組編譯,得到了每個模組被翻譯的內容和他們之間的關係依賴圖(dependency graph),這個依賴圖就是專案所有用到的模組的映射關係。 3、生成階段,將編譯後的module 組合成chunk ,再把每個chunk 轉換成一個單獨的檔案輸出到檔案列表,確定好輸出內容後,根據配置確定輸出路徑和檔案名,就把檔案內容寫入檔案系統 loader webpack只能理解JS和JSON 文件,loader 本質上就是一個轉換器,能將其他類型的文件轉換成webpack 識別的東西 loader 會在webpack 的構建階段將依賴對象創建的module 轉換成標準的js 內容的東西。例如 vue-loader 將vue檔案轉換成 js 模組,圖片字體透過 url-loader 轉換成 data URL,這些 webpack 能夠辨識的東西。 可以在module.rules 中配置不同的loader 解析不同的檔案 #plugin 外掛本質是一個帶有apply 函數的類別 例如stylelint plugin可以指定stylelint 的需要檢查檔案類型和檔案範圍;HtmlWebpackPlugin 用來產生打包後的範本檔案;MiniCssExtactPlugin會將所有的css提取成獨立的chunks,stylelintplugin可以在開發階段提供樣式樣式樣式可以在開發階段提供樣式樣式樣式的檢查功能。 MiniCssExtractPlugin 對於瀏覽器來說,一方面期望每次要求頁面資源時,獲得的都是最新的資源;一方面期望在資源沒有改變時,能夠重複使用快取物件。這個時候,使用檔案名稱 檔案哈希值的方式,就可以實現只要透過檔案名,就可以區分資源是否有更新。而webpack就內建了hash計算方法,對產生檔案的可以在輸出檔中加入hash欄位。 Webpack 內建hash 有三種 hash: 專案每次建置都會產生一個hash,和整個專案有關,專案任意地方有改變就會改變 hash會更根據每次工程的內容進行計算,很容易造成不必要的hash變更,不利於版本管理。一般來說,沒有機會直接使用hash。 content hash: 和單一檔案的內容相關。指定檔案的內容發生改變,就會改變hash,內容不變hash 值不變 對於css檔案來說,一般會使用MiniCssExtractPlugin將其抽取為一個單獨的css檔案。 此時可以使用contenthash標記,確保css檔案內容變更時,可以更新hash。 chunk hash:和webpack打包產生的chunk相關。每一個entry,都會有不同的hash。 一般來說,針對於輸出文件,我們使用chunkhash。 因為webpack打包後,最終每個entry檔案及其依賴會產生單獨的一個js檔案。 此時使用chunkhash,能夠確保整個打包內容的更新準確性。 擴充功能:file-loader 的 hash 可能有同學會表示有以下疑問。 明明經常看到在處理一些圖片,字體的file-loader的打包時,使用的是[name]_[hash:8].[ext] 但是如果改了其他工程文件,如index.js,產生的圖片hash並沒有改變。 這裡要注意的是,file-loader的hash字段,這個loader自己定義的佔位符,和webpack的內建hash字段並不一致。 這裡的hash是使用md4等hash演算法,對檔案內容進行hash。 所以只要檔案內容不變,hash還是會保持一致。 Vite 主要由兩個部分組成 開發環境 Vite 利用瀏覽器去解析imports,在伺服器端按需編譯返回,完全跳過了打包這個概念,伺服器隨起隨用(就相當於把我們在開發的檔案轉換成ESM 格式直接傳送給瀏覽器) 當瀏覽器解析import HelloWorld from './components/HelloWorld.vue' 時,會向目前網域發送請求以取得對應的資源(ESM支援解析相對路徑),瀏覽器直接下載對應的檔案然後解析成模組記錄(開啟network 面板可以看到回應資料都是ESM 類型的js)。然後實例化為模組分配內存,並依照導入導出語句建立模組和內存的映射關係。最後運行程式碼。 vite 會啟動一個 koa 伺服器攔截瀏覽器對 ESM 的請求,透過請求路徑找到目錄下對應的檔案並處理成 ESM 格式傳回給客戶端。 vite的熱加載是在客戶端和服務端之間建立了websocket 連接,程式碼修改後服務端發送訊息通知客戶端去請求修改模組的程式碼,完成熱更新,就是改了哪個view文件就重新要求那個文件,這樣保證了熱更新速度不會受到專案大小影響。 開發環境會使用esbuild 對依賴進行個預先建置緩存,第一次啟動會慢一點,後面的啟動會直接讀取快取 生產環境 使用rollup 來建立程式碼,提供指令可以用來最佳化建置過程。缺點是開發環境和生產環境可能不一致; Webpack 的熱更新原理簡單來說就是,一旦發生某個依賴(例如 Vite 利用瀏覽器去解析imports,在伺服器端按需編譯返回,完全跳過了打包這個概念,伺服器隨起隨用,熱更新是在客戶端和服務端之間建立了websocket 連接,代碼修改後服務端發送消息通知客戶端去請求修改模組的代碼,完成熱更新,就是改了哪個文件就重新請求那個文件,這樣保證了熱更新速度不受項目大小影響。 所以vite目前的最大亮點在於開發體驗上,服務啟動快、熱更新快,明顯地優化了開發者體驗,生產環境因為底層是rollup ,rollup更適合小的程式碼庫,從擴展和功能上都是不如webpack 的,可以使用vite當作一個開發伺服器dev server使用,生產打包用webpack這樣的模式。 0、升級webpack 版本,3升4,實測是提升了幾十秒的打包速度 1、splitChunksPlugin 抽離共用模組輸出單獨的chunks ,像一些第三方的依賴函式庫,可以單獨拆分出來,避免單一chunks過大。 2、DllPlugin 作用同上,這個依賴函式庫相當於從業務程式碼中剝離出來,只有依賴函式庫自身版本變化才會重新打包,提升打包速度 3、loaders的運作是同步的,同各模組會執行全部的loaders #4、exclude/include 指定匹配範圍;alias指定路徑別名; 5、 cache-loader持久化儲存; 6、ESM專案開啟useExport標記,使用tree-shaking 7、exclude/include 指定匹配範圍;alias指定路徑別名;cache-loader持久化儲存; 8、terserPlugin 可以提供程式碼壓縮,去除註解、移除空格的功能;MiniCssExtractPlugin 壓縮css 0、在package.json 檔案中可以定義script 設定項,裡面可以定義執行腳本的鍵和值 1、在npm install 的時候,npm 會讀取配置將執行腳本軟連結到 2、還有一種情況,就是單純的執行腳本指令,像是npm run build,實際運行的是node build.js ,即使用node 執行build.js 這個檔案 ES6 CommonJS 代理模式:提供物件一個代用品或占位符,以便控制對它的訪問 例如實現圖片懶加載的功能,先通過一張 裝飾者模式的定義:在不改變物件本身的基礎上,在程式運作期間給物件動態地新增方法 通常運用在原有方法維持不變,在原有方法上再掛載其他方法來滿足現有需求。 像typescript 的裝飾器就是一個典型的裝飾者模式,還有vue 當中的mixin 保證一個類別僅有一個實例,並提供一個存取它的全域存取點。實現的方法為先判斷實例存在與否,如果存在則直接返回,如果不存在就創建了再返回,這就確保了一個類只有一個實例對象 比如ice stark 的子應用,一次只保證渲染一個子應用程式 #1、雖然兩種模式都存在訂閱者和發布者(具體觀察者可認為是訂閱者、具體目標可視為發布者),但是觀察者模式是由具體目標調度的,而發布/訂閱模式是統一由調度中心調的,所以觀察者模式的訂閱者與發布者之間是存在依賴的,而發布/訂閱模式則不會。 2、兩種模式都可以用來鬆散耦合,改善程式碼管理和潛在的複用。 3、在觀察者模式中,觀察者是知道Subject的,Subject一直保持對觀察者進行記錄。然而,在發布訂閱模式中,發布者和訂閱者並不知道對方的存在。它們只有透過訊息代理進行通訊 4、觀察者模式大多時候是同步的,例如當事件觸發,Subject就會去呼叫觀察者的方法。而發布-訂閱模式大多時候是異步的(使用訊息隊列) #正規表示式是什麼資料型別? 是對象, 正規貪婪模式與非貪婪模式? 量詞 貪婪模式 正規中,表示次數的量詞預設是貪婪的,會盡量符合最大長度,例如 非貪婪模式 在量詞後面加上 貪婪& 非貪婪特徵 貪婪模式和非貪婪模式,都需要發生回溯才能完成對應的功能 獨佔模式 獨佔模式和貪婪模式很像,獨佔模式會盡可能多地去匹配,如果匹配失敗就結束,不會進行回溯,這樣的話就比較節省時間。 寫法:量詞後面使用 優缺點:獨佔模式表現好,可以減少匹配的時間和cpu 資源;但是某些情況下匹配不到,例如: 常見正規則符合 概念:前端自动化测试领域的, 用来验证独立的代码片段能否正常工作 1、可以直接用 Node 中自带的 assert 模块做断言:如果当前程序的某种状态符合 assert 的期望此程序才能正常执行,否则直接退出应用。 2、常见单测工具:Jest,使用示例 babel 用途 bebel 如何转换的? 对源码字符串 parse 生成 AST,然后对 AST 进行增删改,然后输出目标代码字符串 转换过程 parse 阶段:首先使用 transform 阶段:接着使用 generate 阶段:使用 好的,以上就是我对三年前端经验通过面试题做的一个总结了,祝大家早日找到心仪的工作~残業についてどう思いますか?
残業には一般的に次の 2 つの状況があると思います。 まず、プロジェクトの進捗が逼迫しているため、もちろんプロジェクトの進捗が第一です。結局のところ、全員がこれに依存しています。 2 番目の問題は、私自身の能力です。ビジネスに慣れていない場合、または新しいテクノロジー スタックを導入していない場合は、追いつくために残業するだけでなく、自分の能力を最大限に活用する必要があると思います。一生懸命勉強して自分の欠点を補うための自由時間#あなたの興味や趣味は何ですか?
私は通常、読書が好きです。つまり、心理学、時間管理、WeChat でのスピーチスキルに関する本を何冊か読みます。
Be技術面接には必ず注意してください:
簡潔かつ要点を絞って、適切に詳しく説明し、理解できない場合は、理解できないと言ってください #したがって、面接前の技術的な準備は決して一朝一夕にできるものではなく、日々の積み重ねが必要です。 1日20分で小さな知識の一つを勉強し、総合的に勉強すれば、長い目で見れば、何年面接しても、雄弁に話せるようになります。
#したがって、面接前の技術的な準備は決して一朝一夕にできるものではなく、日々の積み重ねが必要です。 1日20分で小さな知識の一つを勉強し、総合的に勉強すれば、長い目で見れば、何年面接しても、雄弁に話せるようになります。
JS 学習スタッド赤封筒本と Yu Yu 氏の
In- Depth JS シリーズ ブログ
プロトタイプの本質は
オブジェクトこのプロトタイプ オブジェクトは、コンストラクターを通じて作成されたインスタンス オブジェクトに共有プロパティを提供するために使用されます。つまり、Object.prototype のプロトタイプ、値は null)。 クロージャとは何ですか?
使用シナリオ: プライベート変数の作成
ほとんどの場合、関数の呼び出し方法によって # の値が決まります。 ##this (実行時バインディング)
1. 非厳密モードのグローバル this は window オブジェクトを指し、厳密モードは undefined2 を指します。オブジェクトのプロパティ メソッドはオブジェクト自体を指します非同期タスクが発生した場合、タスクは一時停止され、他のスレッドに引き渡されて非同期タスクを処理します。非同期タスクが処理されると、コールバック結果がイベント キューに追加されます。 実行スタック内のすべてのタスクが実行されると、つまりメインスレッドがアイドル状態になると、最初のイベント コールバック結果がイベント キューから取得され、このコールバックが実行スタックに追加されます。コードが実行されるなど、このプロセスはイベント ループと呼ばれます。
一般的なマイクロタスクには、promise.then(),マクロ タスクとマイクロ タスクの本質的な違い
2. 参照データ型のサイズは不確実なので、ヒープ メモリに配置し、メモリ適用時にサイズを自分で決定させます3. この方法でストレージを分離すると、メモリの占有量を最小限に抑えることができます。スタックの効率はヒープの効率よりも高くなります
4. スタック メモリ内の変数は実行環境終了直後にガベージ コレクションされますが、ヒープ メモリ内の変数への参照はすべて完了する必要があります。リサイクルされる前に 3. 古い世代では、マークのクリアとマークの並べ替えが使用されます。マークのクリア: すべてを走査します。オブジェクトを使用して、アクセスできる (生きている) オブジェクトをマークし、非アクティブなオブジェクトをガベージとしてリサイクルします。リサイクル後、メモリの不連続を避けるために、マーキングとソートを通じてライブオブジェクトをメモリの一端に移動し、移動が完了した後に境界メモリをクリーンアップする必要があります
関数呼び出しメソッド
function は () を使用して直接呼び出され、次のようなパラメータを渡します: function test(x, y) { return x y},test(3, 4) のように、オブジェクトの属性メソッドとして呼び出されます。 const obj = { test: function (val) { return val } }, obj.test(2)call または ## を使用します。 #apply呼び出し、関数のこの点を変更します。つまり、関数の実行コンテキストを変更します。コンストラクターを間接的に呼び出してオブジェクトを生成できます。 instancedefer と async
の違い 通常の状況では、script タグが実行されると、ダウンロードと 2 段階の操作が実行されます。 HTML の解析をブロックします; async と defer can スクリプトの ブラウザ イベント メカニズム
DOM イベント フローの 3 つの段階:
=> => ; 、つまり、ドキュメントによってキャプチャされ、DOM ツリーに沿って下方向に伝播され、 になるまで各ノードでキャプチャ イベント がトリガーされます。実際のターゲット要素に到達します。 e.target
<ul>
<li><span>hello 1</span></li>
</ul>
let ul = document.querySelectorAll('ul')[0]
let aLi = document.querySelectorAll('li')
ul.addEventListener('click',function(e){
let oLi1 = e.target
let oLi2 = e.currentTarget
console.log(oLi1) // 被点击的li
console.log(oLi2) // ul
console.og(oLi1===oLi2) // false
})e.target は等しくありませんが、イベントのターゲット段階では、 e.currenttarget と e.target は等しい 関数: 、原則は、イベント バブリング (またはイベント キャプチャ) を通じて親要素をリッスンするイベントを追加することであり、e.target はトリガー イベントをトリガーする要素を指します 拡張子 2addEventListener(type, listener);
addEventListener(type, listener, options || useCapture);
type: リスニング イベントのタイプ (例: 'click'/'scroll) '/'focus'
function を実装するオブジェクトである必要があります。監視対象のイベント タイプがトリガーされると、それが実行されます。 once: リスナーが追加後に最大 1 回呼び出せることを示すブール値。true の場合、リスナーは実行後に削除されます。
signal: オプション、AbortSignal
Vue の章

vue と React の違い
setState または onchange
react主に diff キューを使用して DOM が必要とするものを保存します更新する場合はパッチツリーを取得し、DOMを一括更新する統合操作を行います。の場合、ShouldComponentUpdate() を使用して反応レンダリングを手動で最適化する必要があります。
#props / $emit
ref / $refs
キーのない子ノード配列の更新は、インプレース更新戦略を使用します。古い子ノード配列と新しい子ノード配列の長さを比較し、まず短い方の長さを基準として使用し、新しい子ノードの部分に直接パッチします。次に、新しい子ノード配列の長さが長い場合は、新しい子ノード配列の残りの部分を直接マウントし、新しい子ノード配列が短い場合は、古い子ノード配列の余分な部分をアンインストールするかどうかを判断します。
したがって、子ノードがコンポーネントまたはステートフル DOM 要素である場合、元の状態が保持され、不正なレンダリングが発生します。 キーを使用した子ノードの更新は、vue3 相对 vue2的响应式优化
Object.defineProperty去监听对象属性值的变化,但是它不能监听对象属性的新增和删除,所以需要使用$set、$delete这种语法糖去实现,这其实是一种设计上的不足。proxy去实现响应式监听对象属性的增删查改。proxy是比Object.defineProperty要差的。Object.defineProperty把子对象变成响应式的;Vue 核心diff流程
vue双向绑定原理
v-model 原理
// 比如
<input v-model="sth" />
// 等价于
<input :value="sth" @input="sth = $event.target.value" />
v-model 属性时,默认会把value 作为组件的属性,把 input作为给组件绑定事件时的事件名:// 父组件
<my-button v-model="number"></my-button>
// 子组件
<script>
export default {
props: {
value: Number, // 属性名必须是 value
},
methods: {
add() {
this.$emit('input', this.value + 1) // 事件名必须是 input
},
}
}
</script><script>
export default {
model: {
prop: 'num', // 自定义属性名
event: 'addNum' // 自定义事件名
}
}<Son v-model="modalValue"/>
<Son v-model="modalValue"/>
<Son v-model:visible="visible"/>
setup(props, ctx){
ctx.emit("update:visible", false)
}vue 响应式原理
Object.definePorperty劫持对象的 get 和 set 方法,每个组件实例都会在渲染时初始化一个 watcher 实例,它会将组件渲染过程中所接触的响应式变量记为依赖,并且保存了组件的更新方法 update。当依赖的 setter 触发时,会通知 watcher 触发组件的 update 方法,从而更新视图。export class Observer {
this.value = value
this.dep = new Dep()
this.vmCount = 0
def(value, '__ob__', this)
if (Array.isArray(value)) {
// 这里对数组进行单独处理
if (hasProto) {
protoAugment(value, arrayMethods)
} else {
copyAugment(value, arrayMethods, arrayKeys)
}
this.observeArray(value)
} else {
// 对对象遍历所有键值
this.walk(value)
}
}
walk (obj: Object) {
const keys = Object.keys(obj)
for (let i = 0; i < keys.length; i++) {
defineReactive(obj, keys[i])
}
}
observeArray (items: Array<any>) {
for (let i = 0, l = items.length; i < l; i++) {
observe(items[i])
}
}
}Object.keys()遍历全部的键值,对数组只是observe监听已有的元素,所以通过下标更改不会触发响应式更新。computed 和 watch
watch 显式的指定依赖以避免不必要的重复触发,也避免在后续代码修改或重构时不小心引入新的依赖。watchEffect 适用于一些逻辑相对简单,依赖源和逻辑强相关的场景(或者懒惰的场景 )$nextTick 原理?
Vue 异常处理
Vue.config.errorHandlerVue.config.errorHandler = function(err, vm, info) {};Vue.config.errorHandler 配置函数 (如果已设置)。Vue.config.warnHandlerVue.config.warnHandler = function(msg, vm, trace) {};renderErrorconst app = new Vue({
el: "#app",
renderError(h, err) {
return h("pre", { style: { color: "red" } }, err.stack);
}
});errorCapturedVue.component("cat", {
template: `<div><slot></slot></div>`,
props: { name: { type: string } },
errorCaptured(err, vm, info) {
console.log(`cat EC: ${err.toString()}\ninfo: ${info}`);
return false;
}
});window.onerrorwindow.onerror = function(message, source, line, column, error) {};Vuex 流程 & 原理
new Vue({data: {$$state: state}} 将 state 转换成响应式对象,然后使用 computed 函数实时计算 getterVue.use函数里面具体做了哪些事
Vue.use()注册插件,并能阻止多次注册相同插件,它需要在new Vue之前使用。Object或Function类型的参数。如果是Object那么该Object需要定义一个install方法;如果是Function那么这个函数就被当做install方法。Vue.use()执行就是执行install方法,其他传参会作为install方法的参数执行。Vue.use()本质就是执行需要注入插件的install方法**。export function initUse (Vue: GlobalAPI) {
Vue.use = function (plugin: Function | Object) {
const installedPlugins = (this._installedPlugins || (this._installedPlugins = []))
// 避免重复注册
if (installedPlugins.indexOf(plugin) > -1) {
return this
}
// 获取传入的第一个参数
const args = toArray(arguments, 1)
args.unshift(this)
if (typeof plugin.install === 'function') {
// 如果传入对象中的install属性是个函数则直接执行
plugin.install.apply(plugin, args)
} else if (typeof plugin === 'function') {
// 如果传入的是函数,则直接(作为install方法)执行
plugin.apply(null, args)
}
// 将已经注册的插件推入全局installedPlugins中
installedPlugins.push(plugin)
return this
}
}installedPlugins import Vue from 'vue'
import Element from 'element-ui'
Vue.use(Element)
怎么编写一个vue插件
install方法,第一个参数是Vue构造器,第二个参数是一个可选的配置项对象Myplugin.install = function(Vue, options = {}) {
// 1、添加全局方法或属性
Vue.myGlobalMethod = function() {}
// 2、添加全局服务
Vue.directive('my-directive', {
bind(el, binding, vnode, pldVnode) {}
})
// 3、注入组件选项
Vue.mixin({
created: function() {}
})
// 4、添加实例方法
Vue.prototype.$myMethod = function(methodOptions) {}
}CSS篇
什么是 BFC
伪类和伪元素及使用场景
:first-child选择第一个子元素;:hover悬浮在元素上会显示;:focus用键盘选定元素时激活;:link + :visted点击过的链接的样式;:not用于匹配不符合参数选择器的元素;:fist-child匹配元素的第一个子元素;:disabled 匹配禁用的表单元素::before 来在一个元素前增加一些文本,并为这些文本添加样式。虽然用户可以看到这些文本,但是这些文本实际上不在文档树中。示例:::before 在被选元素前插入内容。需要使用 content 属性来指定要插入的内容。被插入的内容实际上不在文档树中h1:before {
content: "Hello ";
}::first-line 匹配元素中第一行的文本src 和 href 区别
不定宽高元素的水平垂直居中
<div class="wrapper flex-center">
<p>horizontal and vertical</p>
</div>
.wrapper {
width: 900px;
height: 300px;
border: 1px solid #ccc;
}
.flex-center { // 注意是父元素
display: flex;
justify-content: center; // 主轴(竖线)上的对齐方式
align-items: center; // 交叉轴(横轴)上的对齐方式
}<div class="wrapper">
<p>horizontal and vertical</p>
</div>
.wrapper {
width: 900px;
height: 300px;
border: 1px solid #ccc;
display: flex;
}
.wrapper > p {
margin: auto;
}<div class="wrapper">
<img src="/static/imghwm/default1.png" data-src="test.png" class="lazy" alt="3 年間の面接経験の共有: フロントエンド面接の 4 つの段階と 3 つの決定要因" >
</div>
.wrapper {
width: 300px;
height: 300px;
border: 1px solid #ccc;
position: relative;
}
.wrapper > img {
position: absolute;
left: 50%;
top: 50%;
tansform: translate(-50%, -50%)
}<div class="wrapper">
<p>absghjdgalsjdbhaksldjba</p>
</div>
.wrapper {
width: 900px;
height: 300px;
border: 1px solid #ccc;
display: table-cell;
vertical-align: middle;
text-align: center;
}浏览器和网络篇

跨页面通信的方法?
详细说说 HTTP 缓存
次に、ブラウザ プロセスは、IPC プロセス間通信を介してネットワーク プロセスに URL リクエストを送信します。ネットワーク プロセスは、まずキャッシュ内のリソースを検索します。リソースがあれば、リクエストをインターセプトします。そのまま200を返します、そうでない場合はネットワークリクエスト処理に入ります。 ネットワーク リクエスト プロセスは、ネットワーク プロセスが DNS サーバーに対して、ドメイン名に対応する IP とポート番号を返すように要求します (これらが以前にキャッシュされている場合は、キャッシュされた結果が直接返されます)。はポート番号ではありません。 http のデフォルトは 80 で、https のデフォルトは 443 です。 https の場合は、暗号化されたデータ チャネルを作成するために TLS 安全な接続を確立する必要もあります。
ブラウザ プロセスは、レンダリング プロセスに「ドキュメントの送信」メッセージを送信します。レンダリング プロセスはメッセージを受信すると、ネットワーク プロセスとのデータ送信チャネルを確立します。データ送信が完了すると、戻ります。 「送信の確認」メッセージをブラウザのサーバー プロセスに送信します。 TCP と UDP の違い
TCP と UDP の違い
TCP 接続のライフサイクルは、リンク段階、データ送信、切断段階の 3 つの段階を経ます。
パケットなので、4 つの波は 4 つのパケット インタラクションである必要があります。Content-length わかりますか? Content-length は、http メッセージの長さ、つまり 10 進数で表されるバイト数です。 content -length
content-length の値が不明な場合は、Transfer-Encoding: chunked を使用する必要があります。これにより、長さ 0 の終了ブロックが返されるまで、返されるデータを複数のデータ チャンクに分割できます。
プロトコルのドメイン名とポート番号が同じであれば同一ドメイン、どちらかが異なっていればクロスドメインです
XSS 和 CSRF
code:<script>alert('你被xss攻击了')</script>转换成code:<script>alert('你被xss攻击了')</script><meta http-equiv="Content-Security-Policy" content="script-src 'self'; object-src 'none'; style-src cdn.example.org third-party.org; child-src https:">document.cookie 来读取
<img src="/static/imghwm/default1.png" data-src="https://time.geekbang.org/sendcoin?user=hacker&number=100" class="lazy" alt="3 年間の面接経験の共有: フロントエンド面接の 4 つの段階と 3 つの決定要因" >
websocket
Post と Get の違い
パフォーマンスの最適化の章

#パフォーマンスを最適化する手段とは何ですか
localstorage/sessionStorage/indexdDB を通じて変更のないビッグ データを読み取ります
メイン スレッドをブロックする長時間の JS 処理を回避します (時間がかかり、無関係な DOM がスレッドにスローされる可能性があります)。 Web ワーカー 小さなタスクに処理または分割するため)
最初の画面の速度の向上ルートの遅延読み込み、最初の画面は最初のルートの関連リソースのみを要求します
#vue 一般的なパフォーマンス最適化方法仮想スクロール
##さまざまな性能指標データが取得可能
window.performance
完全なフロントエンド監視プラットフォームには、データの収集とレポート、データの並べ替えと保存、データの表示が含まれます
PerformanceObserverMutationObserver监听document对象的属性变化如何减少回流、重绘,充分利用 GPU 加速渲染?
// bad 强制刷新 触发四次重排+重绘
div.style.left = div.offsetLeft + 1 + 'px';
div.style.top = div.offsetTop + 1 + 'px';
div.style.right = div.offsetRight + 1 + 'px';
div.style.bottom = div.offsetBottom + 1 + 'px';
// good 缓存布局信息 相当于读写分离 触发一次重排+重绘
var curLeft = div.offsetLeft;
var curTop = div.offsetTop;
var curRight = div.offsetRight;
var curBottom = div.offsetBottom;
div.style.left = curLeft + 1 + 'px';
div.style.top = curTop + 1 + 'px';
div.style.right = curRight + 1 + 'px';
div.style.bottom = curBottom + 1 + 'px';
display: none后元素不会存在渲染树中,这时对它进行各种操作,然后更改 display 显示即可(示例:向2000个div中插入一个div)transform、opacity、filter、will-change能触发硬件加速大图片优化的方案
background-url和backgroun-position来显示图标background-url来懒加载
代码优化
created钩子中使用 this.xxx 赋值const声明变量,注意数组和对象
前端工程化篇

webpack的執行流程與生命週期
webpack的plugin 和loader
class myPlugin { apply(compiler) {} },這個apply 函數有個參數compiler 是webpack 初始化階段產生的編譯器對象,可以呼叫編譯器物件中的hooks 註冊各種鉤子的回呼這些hooks 是貫穿整個編譯的生命週期。所以開發者可以透過鉤子回呼在裡面插入特定的程式碼,實現特定的功能。 webpack的hash策略
vite原理
webpack 和vite 對比
a.js )改變,就將這個依賴所處的module 的更新,並將新的module 傳送給瀏覽器重新執行。每次熱更新都會重新產生 bundle。試想如果依賴越來越多,就算只修改一個文件,理論上熱更新的速度也會越來越慢做過哪些wewbpack 的優化
npm run 執行過程
node_modules/.bin目錄下,同時將./bin加入當環境變數$PATH中,所以如果在全域直接執行該指令會去全域目錄找,可能會找不到該指令就會報錯。例如npm run start,他是執行的webpack-dev-server帶上參數ESM和CJS 的差異
設計模式篇
代理模式
loading圖佔位,然後通過異步的方式加載圖片,等圖片加載好了再把完成的圖片載入到img標籤裡面裝飾模式
單例模式
觀察者模式和發布訂閱模式
其他
正規表示式
let re = /ab c/等價於let re = new RegExp('ab c')*:0或多次; ?:0或1次; :1到多次; {m}:出現m次;{m,}:出現至少m次;{m, n}:出現m到n次 a*會從第一個配對到a的時候向後配對盡可能多的a,直到沒有a為止。 ?就能變成非貪婪模式,非貪婪即找出長度最小且滿足條件的
#a{1,3} ab 去符合aaab 字串, a{1,3} 會把前面三個a 都用掉,且不會回溯
正規
文字
結果
貪婪模式
a{1,3}ab
aaab
符合
##非貪婪模式
a{1,3}?ab aaab 匹配
獨佔模式
a{1,3} ab aaab 不符合
###? ######前一個字元0 次或1 次擴充#########abc?### 表示ab、abc################# #############運算子
說明 實例
.
表示任何單一字元
#[ ]
字元集,對單一字元給出範圍
[abc]
表示a、b、c,[a-z]表示a-z 的單一字元
[^ ]
非字元集,對單一字元給予排除範圍
[^abc]
表示非a或b或c的單一字元
_
前一個字元零次或無限次擴充
abc_
表示ab、abc、abcc、abccc 等
#` `
` abcdef`表示abc、def
$
#符合字串結尾 ##abc$ 表示abc 且在一個字串結尾
#( ) ##\D 分組標記內部只能使用
(abc)
表示abc,`(abc#def)`表示abc、def
#\d非數字
\S數字,等價於0-9
#\s可見字元
\W空白字元(空格、換行、製表符等等)
\w非單字字元
單字字符,等價於[a-z0-9A-Z_]
符合字串開頭
^abc 表示abc並且在一個字串的開頭
##一個字元m 到n 次
表示abc、abbcab{1,2}c
{m} 擴充前一個字元m 次 表示abbc
{m,}
#前一個字元匹配至少m 次
单元测试
function multiple(a, b) {
let result = 0;
for (let i = 0; i < b; ++i)
result += a;
return result;
}
const assert = require('assert');
assert.equal(multiple(1, 2), 3));const sum = require('./sum');
describe('sum function test', () => {
it('sum(1, 2) === 3', () => {
expect(sum(1, 2)).toBe(3);
});
// 这里 test 和 it 没有明显区别,it 是指: it should xxx, test 是指 test xxx
test('sum(1, 2) === 3', () => {
expect(sum(1, 2)).toBe(3);
});
})babel原理和用途
@babel/parser将源码转换成 AST@babel/traverse遍历 AST,并调用 visitor 函数修改 AST,修改过程中通过@babel/types来创建、判断 AST 节点;使用@babel/template来批量创建 AST@babel/generate将 AST 打印为目标代码字符串,期间遇到代码错误位置时会用到@babel/code-frame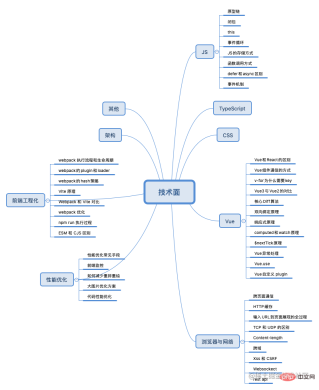

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

メモ帳++7.3.1
使いやすく無料のコードエディター

