
ホームページ >ウェブフロントエンド >フロントエンドQ&A >ツール共有:フロントエンド埋め込みポイントの自動管理を実現
ツール共有:フロントエンド埋め込みポイントの自動管理を実現

- 青灯夜游転載
- 2022-12-07 16:14:382326ブラウズ

埋設ポイントは常に H5 プロジェクトの重要な部分であり、埋設ポイント データは後のビジネス改善や技術的最適化のための重要な基盤となります。 [推奨される学習: Web フロントエンド 、プログラミング教育 ]
日々の仕事の中で、製品やビジネスに携わる学生はよく「このプロジェクトには何が含まれていますか?」と尋ねます。 「埋め込まれたポイントはどこで使われますか?」、「この埋め込まれたポイントはどこで使用されますか?」 このような質問は、基本的にコードを 1 回確認して確認することになるため、非常に非効率的です。

これは、埋没点自体の性質と関係がある可能性があります。埋め込みポイントは比較的独立した関数であるため、反復が進むにつれて開発者が埋め込みポイントの目的を思い出すのは困難です。セルフテストと検証の目的で、開発者はプロジェクト内の隠されたデータを整理する必要もあります。したがって、現在のシナリオと組み合わせると、コードをスキャンし、埋め込まれたポイントに関連するコードを分析し、処理し、その後他の管理プラットフォームで使用できるように特定のデータに変換するツールを実装できます。
実装アイデア
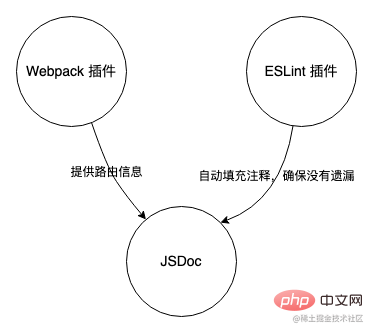
このツールは大きく分けて、JSDoc 埋め込み点の抽出、配線依存関係解析、ESLint の 3 つの部分に分かれます。 プラグイン。
- JSDoc は、JavaScript のアノテーション情報に基づいて API ドキュメントを生成するツールです。 JSDoc のこの機能と組み合わせると、この追跡ツールは JSDoc をコア部分として使用し、コード内で追跡データを出力します。
- Webpack プラグインは、JSDoc にルーティング情報を提供する補助として機能します。
- ESLint プラグインは、ファイルに埋め込まれたコードに対応する JSDoc コメントがあることを確認する最終チェックとして使用されます。
カスタマイズされた JSDoc タグの埋め込みポイント
JSDoc はコード内のコメントに基づいてドキュメントを出力できることがわかっています。まず、JSDoc タグをカスタマイズして非表示のコメントとしてマークし、後続の処理中に他のコメントの干渉を除外できるようにします。特定のプロジェクトで使用されるコードを組み合わせると、次のようなフローチャートを描くことができます。

次に、具体的なコードの実装プロセスを示します。
JSDoc プラグインを作成し、タグをカスタマイズします:
// jsdoc.plugin.js
// 自定义一个 @log,含有 @log 才是埋点的注释
exports.defineTags = function (dictionary) {
dictionary.defineTag('log', {
canHaveName: true,
onTagged: function (doclet, tag) {
doclet.meta.log = tag.text;
},
});
};.ts および .vue ファイルを解析します。
// jsdoc.plugin.js
exports.handlers = {
beforeParse: function (e) {
// 对文件预处理
if (/.vue/.test(e.filename)) {
// 解析 vue 文件
const component = compiler.parseComponent(e.source);
// 获取 vue 文件的 script 代码
const ast = parse.parse(component.script.content, {
// ...
});
}
if (/.ts/.test(e.filename)) {
// ts 转 js
}
},
};カスタマイズされた JSDoc テンプレート。
// publish.js
exports.publish = function (taffyData, opts, tutorials) {
// ...
data().each(function (doclet) {
// 有 log 这个 tag 的才是埋点注释
if (doclet.meta && doclet.meta.log) {
doclet.tags?.forEach((item) => {
// 获取对应的路由地址
});
// 拿到埋点数据
logData.push({});
}
});
// 输出 md 文档
fs.writeFileSync(outpath, mdContent, 'utf8');
};この時点で、コード内のすべての隠れたポイントを完全に出力できます。この時点で、このツールの現在の機能を見てみましょう:
- 埋設ポイント情報を自動的に抽出し、埋設ポイント ドキュメントを生成します: ✅
- 埋設ポイントにカスタム タグを自動的に追加しますコメント (@log ): ❌
- 報告された埋め込みポイント情報を隠しポイント コメントに自動的に追加します: ❌
- ルーティング情報を埋め込みポイント コメントに自動的に追加します: ❌
- 埋め込みポイントを自動的に追加しますポイント コメントから非表示のポイント コメントへ 埋め込まれたポイントの説明情報: ❌
- コメントされていない埋め込まれたポイント コードを自動的にプロンプトする: ❌
上記のコーミングを通じて、次のことがわかります:
- 必須各埋め込みポイントに手動でコメントを追加します
- 各埋め込みポイントに対応するルートを手動で確認する必要があります
- 埋め込みポイントにコメントを追加するのを忘れた場合はどうすればよいですか?
このツールを作成した本来の目的は、反復的で退屈な作業を軽減することですが、コードからドキュメントを自動的に入力するために他のワークロードが追加されるのであれば、その価値は十分にあるでしょう。ゲイン。これらの問題の分析を通じて、次の解決策を導き出すことができます:
- 各隠れポイントに手動でコメントを追加する必要がある - > コードを自動的に入力する - > ESLint 修正機能/VSCode プラグイン - in
- 各隠しポイントに対応するルートを手動で確認する必要があります -> コンポーネントに対応するルートを自動的に見つけます -> Webpack 依存関係分析
- 隠しポイントにコメントするのを忘れた場合はどうすればよいですかポイント? -> コメントを書き忘れた場合はプロンプトが表示されます -> ESLint プラグイン
この時点で、問題の解決策は明らかになりました。次に、webpack プラグインと ESLint プラグインの実装プロセスを見てみましょう。
ルーティング依存関係分析
webpack 自体に 依存関係分析 が付属しており、コンポーネント間の親子関係を簡単に取得できます。
compiler.hooks.normalModuleFactory.tap('routeAnalysePlugin', (nmf) => {
nmf.hooks.afterResolve.tapAsync('routeAnalysePlugin', (result, callback) => {
const { resourceResolveData } = result;
// 子组件
const path = resourceResolveData.path;
// 父组件
const fatherPath = resourceResolveData.context.issuer;
// 只获取 vue 文件的依赖关系
if (/.vue/.test(path) && /.vue/.test(fatherPath)) {
// 将组件间的父子关系存到变量中
}
});
});コンポーネント間の依存関係を必要なデータ形式に変換します
[
{
"path": "src/views/register-v2/index.vue",
"deps": [
{
"path": "src/components/landing-banner/index.vue",
"deps": []
}
]
}
// ...
]组件之间的依赖关系有了,接下来就是找到组件和路由的对应关系,这里我们用 AST 来解析路由文件,获取路由和组件的对应关系。
// 遍历路由文件
for (let i = 0; i < this.routePaths.length; i++) {
// ...
traverse(ast, {
enter(path) {
// 找出组件和路由的对应关系
path.node.properties.forEach((item) => {
// 组件
if (item.key.name === 'component') {
}
// 路由地址
if (item.key.name === 'path') {
}
});
},
});
}同样地,把组件与路由的映射关系拼成合适的数据格式。
{
"src/views/register-v3/index.vue": "/register"
// ...
}再将路由的映射关系和组件间的依赖关系整合到一起,得出每个组件与路由的对应关系。
{
"src/components/landing-banner/index.vue": [
"/register_v2",
"/register"
//...
]
// ...
}因为使用 AST 遍历的方式来解析路由文件,目前支持的解析的路由文件写法有以下四种,基本上满足了当前的场景:
const page1 = (resolve) => {
require.ensure(
[],
() => {
resolve(require('page1.vue'));
},
'page1',
);
};
const page2 = () =>
import(
/* webpackChunkName: "page2" */
'page2.vue'
);
export default [
{ path: '/page1', component: page1 },
{ path: '/page2', component: page2 },
{
path: '/page3',
component: (resolve) => {
require.ensure(
[],
() => {
resolve(require('page3.vue'));
},
'page3',
);
},
},
{
path: '/page4',
component: () =>
import(
/* webpackChunkName: "page4" */
'page4.vue'
),
},
];
再得到了上面的对应关系之后,可以把埋点数据放到传到埋点管理平台上,从而实现一键查询:
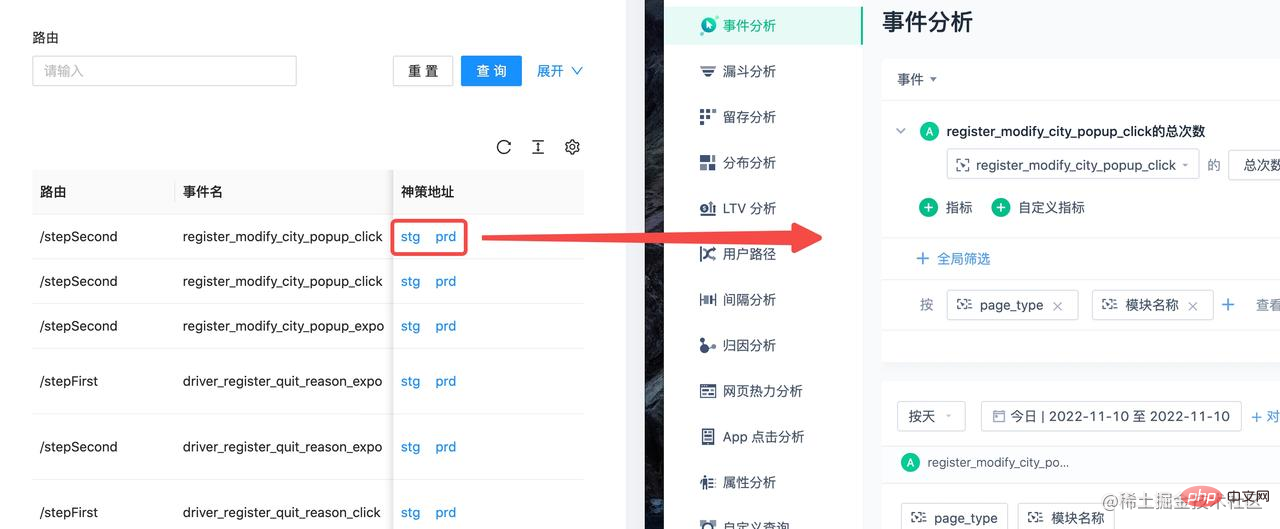
编写 ESLint 插件
先来看看代码中埋点上报的三种方式:
// 神策 sdk
sensors.track('xxx', {});
// 挂载到 Vue 实例中
this.$sa.track('xxx', {});
// 装饰器
@SensorTrack('xxx', {})观察上面三种方式,可以知道埋点上报是通过 track 函数和 SensorTrack 函数,所以我们的 ESLint 插件对这两个函数进行校验。
function create(context) {
// 调用 track 函数的对象
const checkList = ['sensor', 'sensors', '$sa', 'sa'];
return {
Literal: function (node) {
// ...
// 调用埋点函数而缺少注释时
if (
isNoComment &&
((isTrack && isSensor) || (is$Track && isThisExpression))
) {
context.report({
node,
messageId: 'missingComment',
fix: function (fixer) {
// 自动修复
},
});
}
// 使用修饰器但没有注释时
if (
callee.name === 'SensorTrack' &&
sourceCode.getCommentsBefore(node).length === 0
) {
context.report({
node,
messageId: 'missingComment',
fix: function (fixer) {
// 自动修复
},
});
}
},
};
}看下完成后的效果:
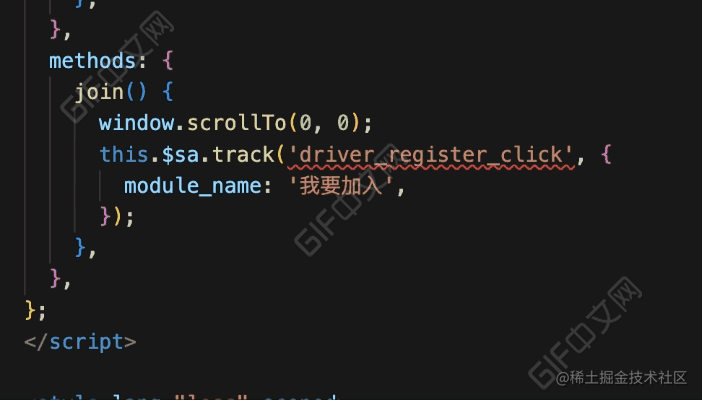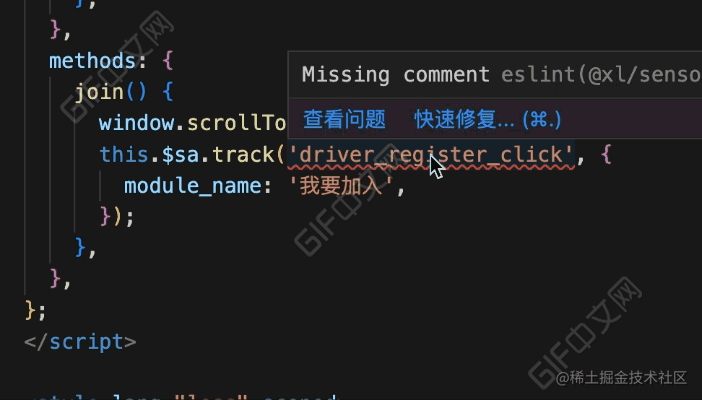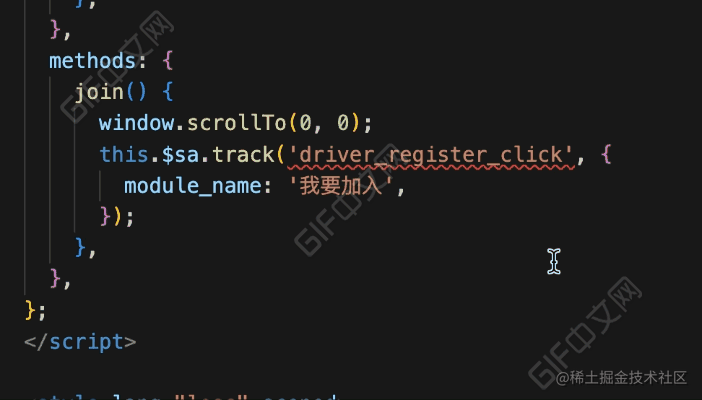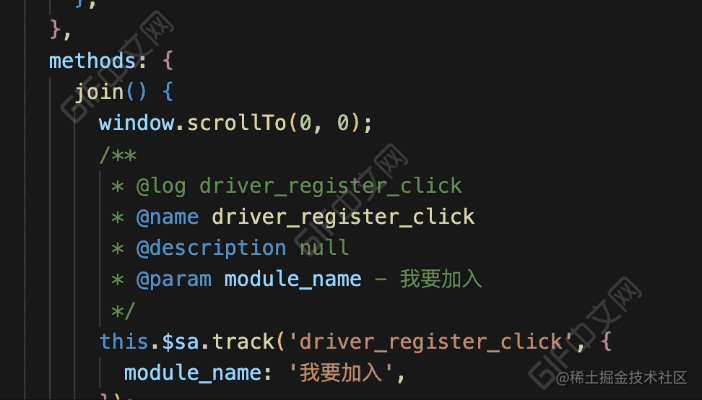
效果对比
我们再来对比下优化前后的区别:
| 优化前 | 优化后 | |
|---|---|---|
| 自动提取埋点信息,生成埋点文档 | ✅ | ✅ |
| 自动给埋点注释添加自定义 tag(@log) | ❌ | ✅ |
| 自动给埋点注释添加上报的埋点信息 | ❌ | ✅ |
| 自动给埋点注释添加路由信息 | ❌ | ✅ |
| 自动给埋点注释添加埋点描述信息 | ❌ | ❌ |
| 自动提示没有注释的埋点代码 | ❌ | ✅ |
优化之后除了整个流程基本都由工具自动完成,剩下一个埋点描述信息。因为埋点的描述信息只是为了让我们更好地理解这个埋点,本身并不在上报的代码中,所以工具没有办法自动生成,但是我们可以直接在产品提供的埋点文档中拷贝过来完成这一步。
总结
在项目中接入这个工具之后,可以快速地知道项目的埋点有哪些以及各个埋点所在的页面,也方便我们对埋点的梳理,同时利用导出的埋点数据开发后台应用,有效地提升了开发者效率。
这个工具的实现是在 JSDoc、webpack 和 ESLint 插件的加持下水到渠成的,说是水到渠成是因为一开始的想法只是做到第一步,先有个一键查询功能和能够输出一份文档用着先。但是第一版出来后发现要手动去处理这些埋点注释还是比较繁琐,恰巧平常开发中常见的 webpack 插件和 ESLint 插件可以很好地解决这些问题,于是便有路由依赖分析和 ESLint 插件。像是《牧羊少年奇幻之旅》中所说的,“如果你下定决心要做一件事情,整个宇宙都会合力帮助你。”
以上がツール共有:フロントエンド埋め込みポイントの自動管理を実現の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。