




vue2 diff プロセス
- 比較方法: 同じレベルの比較、クロスレベル比較なし
#次のソース コードはvue/patch.ts からのもので、いくつかの抜粋があり、関連する機能へのリンクが添付されます。 [関連する推奨事項: vuejs ビデオ チュートリアル 、Web フロントエンド開発 ]
パッチ関数
- diff
プロセスでは、patch関数を呼び出し、古いノードと新しいノードを比較し、比較しながら実際の DOM にパッチを適用します。関数:ソース コード アドレス:パッチ関数 - 、isUndef() 関数、isDef() 関数、emptyNodeAt function
return function patch(oldVnode, vnode, hydrating, removeOnly) { if (isUndef(vnode)) { //新的节点不存在 if (isDef(oldVnode)) //旧的节点存在 invokeDestroyHook(oldVnode) //销毁旧节点 return } ......... //isRealElement就是为处理初始化定义的,组件初始化的时候,没有oldVnode,那么Vue会传入一个真实dom if (!isRealElement && sameVnode(oldVnode, vnode)) { -----判断是否值得去比较 patchVnode(oldVnode, vnode, insertedVnodeQueue, null, null, removeOnly) ---打补丁,后面会详细讲 } else { ...... if (isRealElement) ...... oldVnode = emptyNodeAt(oldVnode) //转化为Vnode,并赋值给oldNode } // replacing existing element const oldElm = oldVnode.elm ----找到oldVnode对应的真实节点 const parentElm = nodeOps.parentNode(oldElm) ------找到它的父节点 createElm(.....) --------创建新节点 ....递归地去更新节点 return vnode.elm }

- sameNode
- がその中に表示されますパッチを提供する価値があるかどうかを判断するには、パッチを提供する価値があるかどうかを判断し、価値がない場合は、上記の手順に従って置き換えてください。この関数のソース コード アドレスを見つけてみましょう
:sameNode function -
function sameVnode(a, b) { return ( a.key === b.key && ----------------------key值相等, 这就是为什么我们推荐要加上key,可以让判断更准确 a.asyncFactory === b.asyncFactory && ((a.tag === b.tag && ---------------------标签相等 a.isComment === b.isComment && ---------是否为注释节点 isDef(a.data) === isDef(b.data) && ----比较data是否都不为空 sameInputType(a, b)) || ---------------当标签为input的时候,需要比较type属性 (isTrue(a.isAsyncPlaceholder) && isUndef(b.asyncFactory.error))) ) }
- patchVNode
- 関数を入力してください
ソース コード アドレス:
- patchVNode 関数
- この関数は少し長いため短縮されました
function patchVnode(... ) { if (oldVnode === vnode) { //两个节点一致,啥也不用管,直接返回 return } .... if ( //新旧节点都是静态节点,且key值相等,则明整个组件没有任何变化,还在之前的实例,赋值一下后直接返回 isTrue(vnode.isStatic) && isTrue(oldVnode.isStatic) && vnode.key === oldVnode.key && (isTrue(vnode.isCloned) || isTrue(vnode.isOnce)) ) { vnode.componentInstance = oldVnode.componentInstance return } const oldCh = oldVnode.children //获取旧节点孩子 const ch = vnode.children //获取新节点孩子 if (isUndef(vnode.text)) { //新节点没有文本 if (isDef(oldCh) && isDef(ch)) { //旧节点孩子和新节点孩子都不为空 if (oldCh !== ch) //旧节点孩子不等于新节点孩子 updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly) //重点----比较双方的孩子进行diff算法 } else if (isDef(ch)) { //新节点孩子不为空,旧节点孩子为空 .... addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue) //新增节点 } else if (isDef(oldCh)) { //新节点孩子为空,旧节点孩子不为空 removeVnodes(oldCh, 0, oldCh.length - 1) //移除旧节点孩子节点 } else if (isDef(oldVnode.text)) { //旧节点文本为不为空 nodeOps.setTextContent(elm, '') //将节点文本清空 } } else if (oldVnode.text !== vnode.text) { //新节点有文本,但是和旧节点文本不相等 nodeOps.setTextContent(elm, vnode.text) //设置为新节点的文本 } }

ソース コード アドレス: 初期化
採用された 4 つの手順 ポインタはそれぞれ 4 つのノードを指します
- oldStartIdx
- 、
newStartIdxは古いノード ヘッドを指します。新しいノードの先頭、初期値は 0 oldEndIdx - 、
newEndIdxは古いノードの末尾、新しいノードの末尾、初期値を指しますは長さ 1 ##
let oldStartIdx = 0 //旧头指针 let newStartIdx = 0 //新头指针 let oldEndIdx = oldCh.length - 1 //旧尾指针 let newEndIdx = newCh.length - 1 //新尾指针 let oldStartVnode = oldCh[0] //旧头结点 let oldEndVnode = oldCh[oldEndIdx] //旧尾结点 let newStartVnode = newCh[0] //新头结点 let newEndVnode = newCh[newEndIdx] //新尾结点- 、
 4 つの比較 - ループ内
4 つの比較 - ループ内
#Oldヘッドと新しいヘッド
- 古いテールと新しいテール
- 古いヘッドと新しいテール
- 古いテールと新しいヘッド
- 注: ここで 1 つ打てる限り
、どれも打てない場合は次のリンクに移動してください。 、 1 つずつ判断し続けるのではなくfunction updateChildren(){ ·.... //好戏从这里开始看 //只要满足 旧头指针<=旧尾指针 同时 新头指针<= 新尾指针 -- 也可以理解为不能交叉 while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) { //这里进行一个矫正,是应该在循环的过程中,如果进入key表查询的话复用后会将旧节点置空(后面会说),所以这里会对其进行一个处理 if (isUndef(oldStartVnode)) { //旧头结点为空 oldStartVnode = oldCh[++oldStartIdx] // 往右边走 } else if (isUndef(oldEndVnode)) { //旧尾结点为空 oldEndVnode = oldCh[--oldEndIdx] //往左边走 //step1 } else if (sameVnode(oldStartVnode, newStartVnode)) { //比较旧头和新头,判断是否值得打补丁 patchVnode(...) //打补丁 oldStartVnode = oldCh[++oldStartIdx] //齐头并进向右走 newStartVnode = newCh[++newStartIdx] //齐头并进向右走 //step2 } else if (sameVnode(oldEndVnode, newEndVnode)) { //比较旧尾和新尾, 判断是否值得打补丁 patchVnode(...) //打补丁 oldEndVnode = oldCh[--oldEndIdx] //齐头并进向左走 newEndVnode = newCh[--newEndIdx] //齐头并进向左走 //step3 } else if (sameVnode(oldStartVnode, newEndVnode)) { //比较旧头和新尾,判断是否值得打补丁 patchVnode(...) //打补丁 //补完移动节点 canMove && nodeOps.insertBefore(parentElm,oldStartVnode.elm,nodeOps.nextSibling(oldEndVnode.elm)) oldStartVnode = oldCh[++oldStartIdx] //旧头向右走 newEndVnode = newCh[--newEndIdx] //新尾向左走 //step4 } else if (sameVnode(oldEndVnode, newStartVnode)) { //比较旧尾和新头,判断是否值得打补丁 patchVnode(...) //打补丁 //补完移动节点 canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm) oldEndVnode = oldCh[--oldEndIdx] //旧尾向左走 newStartVnode = newCh[++newStartIdx] //新头向右走 }上記のランダムな例を取り上げて練習してください
 上記のランダムな例を取り上げて練習してください
上記のランダムな例を取り上げて練習してください
ステップ 1、ステップ 2

 step3、
step3、
- 在step4进行处理,移动节点到正确位置(插在旧头的前面)
- 旧尾向左走,新头向右走
- 处理完后就重开,从step1开始,到step2再次命中,此时
oldEndInx和newEndInx齐头并进向左走(注意这里是不用去移动节点的哦)(左), 然后重开,在step2再次命中...(右)




- 重开, 这次在step3命中,然后将旧头结点结点的真实节点插在旧尾结点的后面,到这里其实真实节点就已经是我们所期望的了
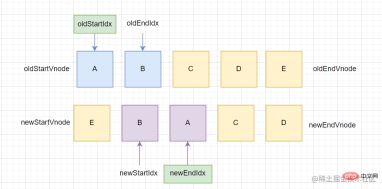

- 上述处理完后,旧头向右走,新尾向左走,命中step1,新头和旧头都向左走,出现交叉情况,至此退出循环


- 通过上面这个例子,我们把四种情况都命中了一下(一开始随便画的图没想到都命中了哈哈哈),也成功通过复用节点将真实结点变为预期结果,这里便是双端diff一个核心体现了
- 但是如果四种情况都没有命中的呢(如图下)
- 则会走向我们最后一个分支,也就是后面介绍的列表寻找

列表寻找-循环中
- 先来看懂里面涉及到的
createKeyToOldIdx函数 - 源码地址: createKeyToOldIdx函数
function createKeyToOldIdx(children, beginIdx, endIdx) {
let i, key
const map = {} //初始化一个对象
for (i = beginIdx; i <= endIdx; ++i) { //从头到尾
key = children[i].key //提取每一项的key
if (isDef(key)) map[key] = i //key不为空的时候,存入对象,键为key,值为下标
}
return map //返回对象
}
//所以该函数的作用其实就是生成了一个节点的键为key,值为下标的一个表- 再来看一下里面涉及到的
findIdxInOld函数 - 源码地址:findIdxInOld函数
function findIdxInOld(node, oldCh, start, end) {
//其实就是进行了一个遍历的过程
for (let i = start; i < end; i++) {
const c = oldCh[i]
if (isDef(c) && sameVnode(node, c)) return i //判断是否有值得打补丁的节点,有则返回
}
}- 进入正文
let oldKeyToIdx, idxInOld, vnodeToMove, refElm;
....
else {
if (isUndef(oldKeyToIdx))
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx) //传入的是旧节点孩子,所以生成了一个旧节点孩子的key表
//使用三目运算符--- 这里也是要使用key的原因,key有效的话可以通过表获取,无效的话则得进行比遍历比较
idxInOld = isDef(newStartVnode.key) //判断新头结点的key是否不为空--是否有效
? oldKeyToIdx[newStartVnode.key] //不为空的的话就到key表寻找该key值对象的旧节点的下标
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx) //遍历寻找旧节点数组中是否有和新头结点值得打补丁的节点,有的话则赋值其下标给idxInOld(不通过key)
if (isUndef(idxInOld)) { //发现找不到了就直接创建新真实节点
createElm(...)
} else { //找到了
vnodeToMove = oldCh[idxInOld] //找到该下标对应的节点
if (sameVnode(vnodeToMove, newStartVnode)) { //进行一个比较判断是否值得打补丁
patchVnode(...) //打补丁
oldCh[idxInOld] = undefined //置空,下次生成表就不会把它加进去
canMove &&nodeOps.insertBefore( parentElm, vnodeToMove.elm,oldStartVnode.elm ) //移动节点
} else {
//不值得打补丁,创建节点
createElm(...)
}
}
newStartVnode = newCh[++newStartIdx] //新头指针向前一步走
}
} //--- while循环到这里- 看完源码其实可以总结一下,就是前面四个都没有命中后,就会生成旧节点孩子的
key表 - 新头节点的
key有效的话,就拿新头节点的key去旧节点的key表找,找不到就创建新的真实节点, 找得到的话就判断是否值得打补丁,值得的话就打补丁后复用节点,然后将该旧节点孩子值置空,不值得就创建新节点 - 新头节点的
key无效的话,则去遍历旧节点数组挨个进行判断是否值得打补丁,后续跟上述一样 - 新头指针向前一步走
也使用一下上面的例子运用一下这个步骤,以下都为key有效的情况
(重新放一下图,方便看)
- 生成了一个旧节点的key表(key为键,值为下标), 然后
newStartVnode的key值为B,找到旧节点孩子该节点下标为1,则去判断是否直接打补丁,值得的话将该旧节点孩子置空再在A前面插入B


右图的表中B没有变为undefined是因为表示一开始就生成的,在下次进入循环的时候生成的表才会没有B
- 然后将新头向右走一步,然后重开,发现前四步依旧没有命中,此时新头结点为B,但是生成的旧节点表没有B,故创建新的节点,然后插入


- 新头继续向右走,重开,命中step1(如图左), 之后新头和旧头齐头并进向右走, 此时,旧头指向的
undefined(图右),直接向右走,重开


- 发现此时又都没有命中, 此时也是生成一个
key表,发现找不到,于是创建新节点M插入


- 然后新头继续向前走,依旧都没有命中,通过
key表去寻找,找到了D,于是移动插入,旧节点孩子的D置空,同时新头向前一步走


- 走完这一步其实就出现交叉情况了,退出循环,此时如下图,你会发现,诶,前面确实得到预期了,可是后面还有一串呢

- 别急,这就来处理
处理
if (oldStartIdx > oldEndIdx) { //旧的交叉了,说明新增的节点可能还没加上呢
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm
addVnodes(....) //新增
} else if (newStartIdx > newEndIdx) { //新的交叉了,说明旧节点多余的可能还没删掉呢
removeVnodes(oldCh, oldStartIdx, oldEndIdx) //把后面那一段删掉
}- 对于上面这个例子,就是把后面那一段,通过遍历的方式,挨个删除

到这里updateChildren函数就结束喽,自己推导一下节点的变化就会很清晰啦
(学习视频分享:编程基础视频)
以上がvue2 diff アルゴリズムを 1 つの記事で理解します (画像付き)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Vue.js:Web開発におけるその役割を定義しますApr 18, 2025 am 12:07 AM
Vue.js:Web開発におけるその役割を定義しますApr 18, 2025 am 12:07 AMWeb開発におけるVue.jsの役割は、開発プロセスを簡素化し、効率を向上させるプログレッシブJavaScriptフレームワークとして機能することです。 1)開発者は、レスポンシブデータのバインディングとコンポーネント開発を通じてビジネスロジックに集中できるようになります。 2)VUE.JSの作業原則は、パフォーマンスを最適化するためにレスポンシブシステムと仮想DOMに依存しています。 3)実際のプロジェクトでは、VUEXを使用してグローバルな状態を管理し、データの応答性を最適化することが一般的な慣行です。
 Vue.jsの理解:主にフロントエンドフレームワークApr 17, 2025 am 12:20 AM
Vue.jsの理解:主にフロントエンドフレームワークApr 17, 2025 am 12:20 AMVue.jsは、2014年にYou YuxiがリリースしたプログレッシブJavaScriptフレームワークで、ユーザーインターフェイスを構築します。その中心的な利点には、次のものが含まれます。1。レスポンシブデータバインディング、データ変更の自動更新ビュー。 2。コンポーネントの開発では、UIは独立した再利用可能なコンポーネントに分割できます。
 Netflixのフロントエンド:React(またはVue)の例とアプリケーションApr 16, 2025 am 12:08 AM
Netflixのフロントエンド:React(またはVue)の例とアプリケーションApr 16, 2025 am 12:08 AMNetflixは、Reactをフロントエンドフレームワークとして使用します。 1)Reactのコンポーネント開発モデルと強力なエコシステムが、Netflixがそれを選択した主な理由です。 2)コンポーネント化により、Netflixは複雑なインターフェイスをビデオプレーヤー、推奨リスト、ユーザーコメントなどの管理可能なチャンクに分割します。 3)Reactの仮想DOMおよびコンポーネントライフサイクルは、レンダリング効率とユーザーインタラクション管理を最適化します。
 フロントエンドの風景:Netflixが選択にアプローチした方法Apr 15, 2025 am 12:13 AM
フロントエンドの風景:Netflixが選択にアプローチした方法Apr 15, 2025 am 12:13 AMNetflixのフロントエンドテクノロジーでの選択は、主にパフォーマンスの最適化、スケーラビリティ、ユーザーエクスペリエンスの3つの側面に焦点を当てています。 1。パフォーマンスの最適化:Netflixは、Reactをメインフレームワークとして選択し、SpeedCurveやBoomerangなどのツールを開発して、ユーザーエクスペリエンスを監視および最適化しました。 2。スケーラビリティ:マイクロフロントエンドアーキテクチャを採用し、アプリケーションを独立したモジュールに分割し、開発効率とシステムのスケーラビリティを改善します。 3.ユーザーエクスペリエンス:Netflixは、Material-UIコンポーネントライブラリを使用して、A/Bテストとユーザーフィードバックを介してインターフェイスを継続的に最適化して、一貫性と美学を確保します。
 React vs. Vue:Netflixはどのフレームワークを使用していますか?Apr 14, 2025 am 12:19 AM
React vs. Vue:Netflixはどのフレームワークを使用していますか?Apr 14, 2025 am 12:19 AMnetflixusesaCustomframeworkは、「ギボン」ビルトンリアクト、notreactorvuedirectly.1)チームエクスペリエンス:seice basedonfamperivity.2)projectomplerprojects:vueforsplerprojects、racefforcomplexones.3)customeforsneeds:reactofforsmorefloficailie.
 フレームワークの選択:Netflixの決定を推進するものは何ですか?Apr 13, 2025 am 12:05 AM
フレームワークの選択:Netflixの決定を推進するものは何ですか?Apr 13, 2025 am 12:05 AMNetflixは、主に、パフォーマンス、スケーラビリティ、開発効率、エコシステム、技術的な負債、およびフレームワーク選択におけるメンテナンスコストを考慮しています。 1。パフォーマンスとスケーラビリティ:JavaとSpringbootが選択され、大規模なデータと高い同時リクエストを効率的に処理します。 2。開発効率とエコシステム:Reactを使用して、フロントエンド開発効率を向上させ、その豊富なエコシステムを利用します。 3.技術的な負債とメンテナンスコスト:node.jsを選択してマイクロサービスを構築して、メンテナンスコストと技術的債務を削減します。
 Netflixのフロントエンドの反応、Vue、および未来Apr 12, 2025 am 12:12 AM
Netflixのフロントエンドの反応、Vue、および未来Apr 12, 2025 am 12:12 AMNetflixは、主にReactをフロントエンドフレームワークとして使用し、特定の機能のためにVUEによって補足されます。 1)Reactのコンポーネント化と仮想DOMは、Netflixアプリケーションのパフォーマンスと開発効率を向上させます。 2)VueはNetflixの内部ツールと小規模プロジェクトで使用されており、その柔軟性と使いやすさが重要です。
 フロントエンドのvue.js:実際のアプリケーションと例Apr 11, 2025 am 12:12 AM
フロントエンドのvue.js:実際のアプリケーションと例Apr 11, 2025 am 12:12 AMVue.jsは、複雑なユーザーインターフェイスを構築するのに適した進歩的なJavaScriptフレームワークです。 1)そのコア概念には、レスポンシブデータ、コンポーネント、仮想DOMが含まれます。 2)実際のアプリケーションでは、TODOアプリケーションを構築し、Vuerouterを統合することで実証できます。 3)デバッグするときは、vuedevtools and Console.logを使用することをお勧めします。 4)パフォーマンスの最適化は、V-IF/V-Show、リストレンダリング最適化、コンポーネントの非同期負荷などを通じて達成できます。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

ドリームウィーバー CS6
ビジュアル Web 開発ツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

