
Redis で一般的に使用されるデータ構造 (整理および共有)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-11-07 17:15:502122ブラウズ
この記事では、Redis に関する関連知識を提供します。主に一般的なデータ構造に関する関連コンテンツを紹介します。最もよく使用される 5 つは、文字列、ハッシュ、リスト、セットです。とオーダーセットですので、皆様のお役に立てれば幸いです。

推奨される学習: Redis ビデオ チュートリアル
Redis の一般的なデータ構造
Redis は、When 向けにいくつかのデータ構造を提供します。 Redis 内のデータにアクセスします。最も一般的に使用されるものは、文字列、ハッシュ、リスト、セット、順序セット (ZSET) の 5 つです。
String (String)
文字列型は、Redis の最も基本的なデータ構造です。まず、キーはすべて文字列型であり、他のいくつかのデータ構造は文字列型に基づいて構築されているため、文字列型は他の 4 つのデータ構造を学習するための基礎を築くことができます。文字列型の値は、実際には文字列 (単純な文字列、複雑な文字列 (JSON、XML など))、数値 (整数、浮動小数点数)、またはバイナリ (画像、音声、ビデオ) にすることができますが、その値は最大 512MB を超えることはできません。
(Redis は C で書かれていますが、C には基本的に char 配列を使用して実装される文字列があります。ただし、さまざまな考慮事項により、Redis は引き続き文字列型自体を実装します)
操作コマンド
set set value
set key value
set コマンドにはいくつかのオプションがあります。
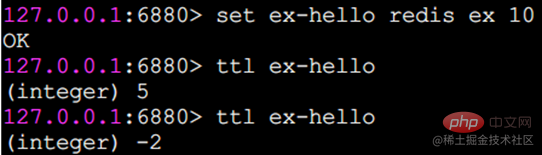
ex 秒: キーの第 2 レベルの有効期限を設定します。
px ミリ秒: キーの有効期限をミリ秒単位で設定します。
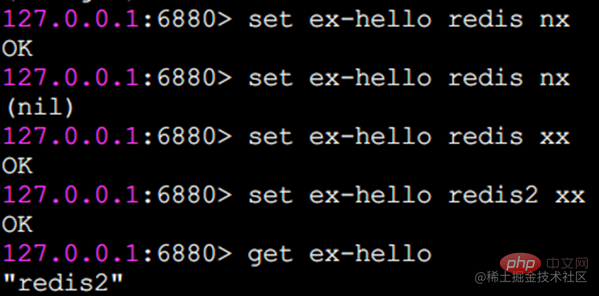
nx: キーは、正常に設定され、追加に使用される前に存在してはなりません (通常、分散ロックに使用されます)。
xx: nx とは異なり、キーを正常に設定して更新に使用するには、キーが存在している必要があります。
 ##setnx の例:
##setnx の例:
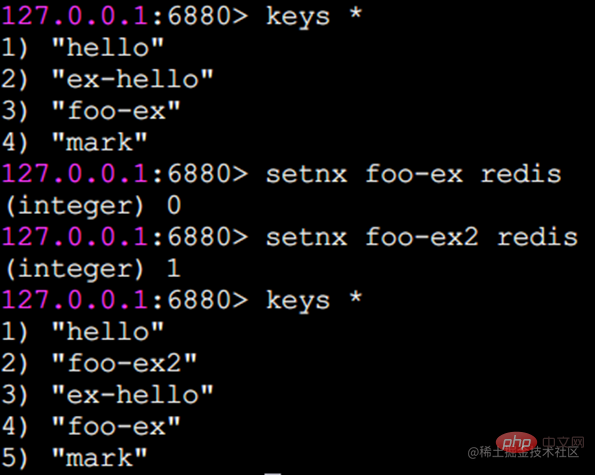 キー foo-ex はすでに存在するため、 setnx は失敗し、戻り結果は 0 になります。キー foo-ex2 が存在しないため、setnx は成功し、戻り結果は 1 になります。
キー foo-ex はすでに存在するため、 setnx は失敗し、戻り結果は 0 になります。キー foo-ex2 が存在しないため、setnx は成功し、戻り結果は 1 になります。
アプリケーション シナリオはありますか? setnx コマンドを例に挙げます。Redis のシングル スレッドのコマンド処理メカニズムにより、複数のクライアントが setnx キー値を同時に実行した場合、1 つのクライアントのみが setnx キー値を設定できます。 setnx の特性に従って、setnx は分散ロックの実装ソリューションとして使用できます。もちろん、分散ロックは 1 つのコマンドだけで実行できるわけではなく、注意すべき点がたくさんありますが、後で別の章を使って Redis をベースにした分散ロックについて説明します。
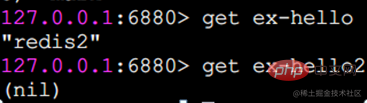
get 値を取得します取得対象のキーが存在しない場合はnil(空)を返します:
mset コマンドを使用して一度に 4 つのキーと値のペアを設定します

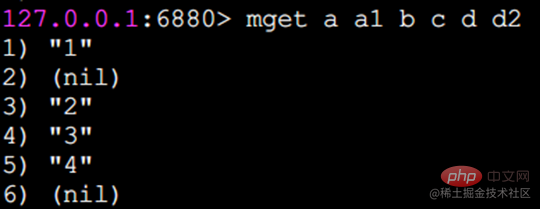 キー a、b、c、d の値を一括取得:
キー a、b、c、d の値を一括取得:
一部のキーが存在しない場合、その値は nil (null) となり、結果は入力キーの順序で返されます。
バッチ操作コマンドを使用すると効率が向上します。mget のようなコマンドがない場合、n 個の get コマンドを実行するのに必要な具体的な時間は次のとおりです:
n 回の get 時間 = n 回のネットワーク時間n 回のコマンド時間
mget コマンドを使用した後、n 回の get コマンド操作の実行に必要な具体的な時間は次のとおりです。
n 回の get 時間 = 1 回のネットワーク時間 n 回のコマンド時間
Redis は 1 秒あたり数万回の読み取りおよび書き込み操作をサポートできますが、これは Redis サーバーの処理能力を指します。クライアントの場合、コマンド時間に加えて、コマンドにはネットワーク時間もかかります。ネットワーク時間は 1 ミリ秒、コマンドの時間は 0.1 ミリ秒 (1 秒あたり 10,000 個のコマンドの処理に基づく)、1,000 個の get コマンドの実行に 1.1 秒かかります (10001 10000.1=1100ms)。 mget コマンドには 0.101 秒かかります (1 1 10000.1=101ms)。
Incr 数値演算
incr コマンドは、値に対して増分演算を実行するために使用されます。返される結果は 3 つの状況に分けられます:
値整数ではない場合、エラーを返します。
値は整数で、自動インクリメント後の結果が返されます。
キーは存在しません。キーは 0 の値に従って増分され、返される結果は 1 になります。
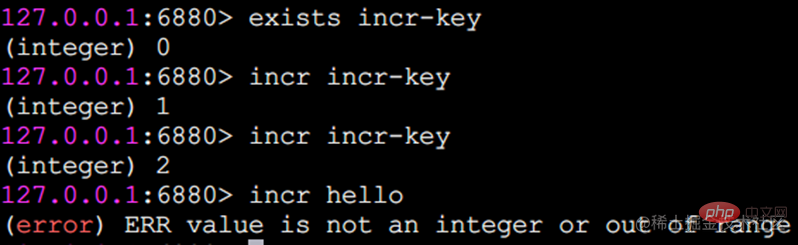
incr コマンドに加えて、Redis は decr (自己減分)、incrby (自己増分指定数)、decrby (自己減分指定数)、incrbyfloat を提供します。 (自己増加する浮動小数点数) )、学生は、具体的な効果を自分で試してみるように求められます。
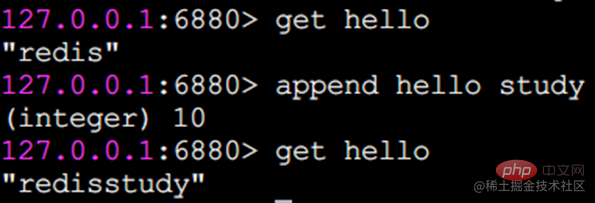
append append コマンド
append は文字列の末尾に値を追加できます
strlen 文字列の長さ
戻り文字列の長さ
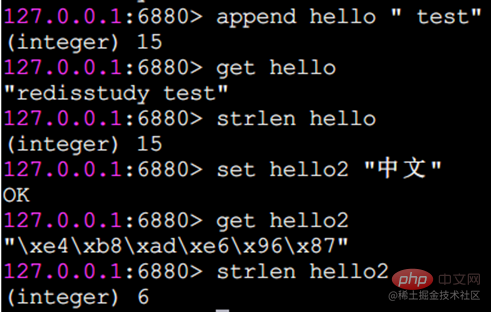
注: 各漢字は 3 バイトを占めます
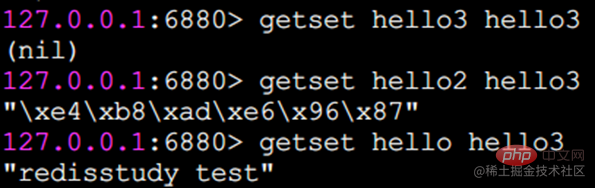
getset 設定および元の値を返す
getset は set と同じように値を設定しますが、キーの元の値も返すという違いがあります
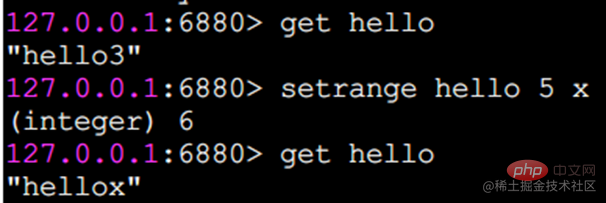
setrange は、指定された位置に文字を設定します。
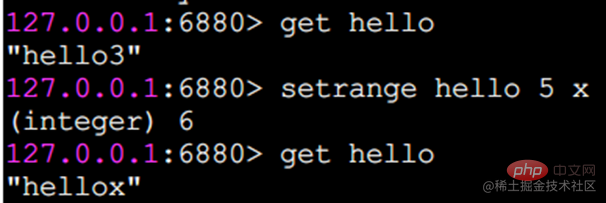
添え字は 0 から始まります。
getrange は文字列をインターセプトします
getrange は文字列の一部をインターセプトして部分文字列を形成します。開始オフセットと終了オフセットを指定する必要があります。インターセプトされた範囲は閉じた範囲です間隔。
コマンドの時間計算量
文字列 これらのコマンドのうち、del、mset、mget を除く複数のキー操作のバッチをサポートします。時間計算量はキーの数に関係しており、O(n) です。Getrange は文字列の長さに関係しており、これも O(n) です。残りのコマンドの時間計算量は基本的に O(1) です。速度の点では、それでも非常に速いです。
使用シナリオ
文字列型には幅広い使用シナリオがあります:
キャッシュ関数
Redis MySQL はキャッシュ層としてストレージ層として機能し、要求されたデータのほとんどは Redis から取得されます。 Redis には高い同時実行性をサポートする特性があるため、通常、キャッシュは読み取りと書き込みを高速化し、バックエンドの負荷を軽減する役割を果たします。
カウント
カウントの基本ツールとして Redis を使用すると、高速カウントとクエリ キャッシュの機能を実現でき、データを他のデータに非同期にランディングできます。ソース。
共有セッション
分散 Web サービスでは、ユーザーのセッション情報 (ユーザー ログイン情報など) がそれぞれのサーバーに保存されます。これにより問題が発生します。負荷分散用分散サービスでは、さまざまなサーバーへのユーザー アクセスが分散されるため、アクセスを更新すると再度ログインが必要になる可能性があり、この問題はユーザーにとって耐えられません。
この問題を解決するには、Redis を使用してユーザーのセッションを集中管理します。このモードでは、Redis の可用性とスケーラビリティが高い限り、ユーザーがログイン情報を更新またはクエリするたびに、 Redis の集中取得から直接アクセスできます。
速度制限
たとえば、セキュリティ上の理由から、多くのアプリケーションは、ユーザーがログインするたびに携帯電話の確認コードを入力して、ユーザーが本人であるかどうかを確認するように求めます。ユーザー、私自身。ただし、SMS インターフェイスへの頻繁なアクセスを防ぐため、ユーザーが 1 分間に認証コードを取得する頻度は、たとえば 1 分間に 5 回以下に制限されます。一部の Web サイトでは、IP アドレスが 1 秒間に n 回以上要求されることを制限しており、同様の考え方を使用できます。
Hash
Java は HashMap を提供し、Redis にも同様のデータ構造 (ハッシュ タイプ) があります。ただし、ハッシュ型のマッピング関係はフィールドと値と呼ばれ、ここでの値はキーに対応する値ではなく、フィールドに対応する値を指すことに注意してください。
操作コマンド
基本的に、ハッシュ操作コマンドは文字列操作コマンドと非常に似ており、多くのコマンドは文字列型コマンドの前に文字 h を追加します。これは、それが操作であることを意味します。ギリシャ型で、操作対象のフィールドの値も指定します。
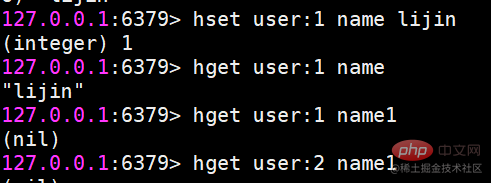
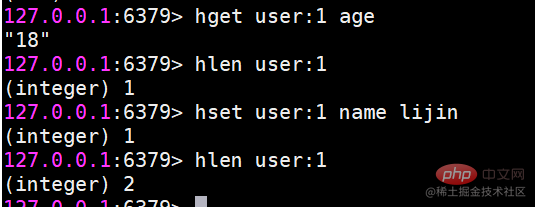
hset 設定値
hset user:1 name lijin

設定が成功した場合は 1 が返され、それ以外の場合は 0 が返されます。さらに、Redis には hsetnx コマンドが用意されており、その関係は set および setnx コマンドと同じですが、スコープがキーからフィールドに変わる点が異なります。
hget value
hget user:1 name
キーまたはフィールドが存在しない場合は、nil が返されます。
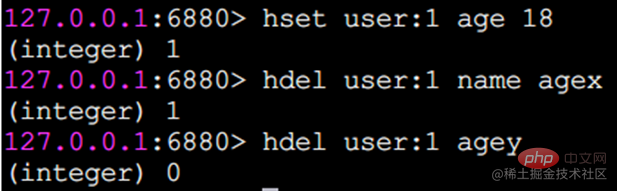
hdel delete field
hdel は 1 つ以上のフィールドを削除します。返される結果は、正常に削除されたフィールドの数です。

 ##hexists はフィールドが存在するかどうかを決定します
##hexists はフィールドが存在するかどうかを決定します
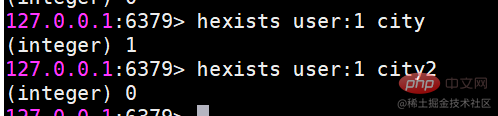 フィールドが存在する場合は、存在しない場合は 1 を返し、0 を返します
フィールドが存在する場合は、存在しない場合は 1 を返し、0 を返します
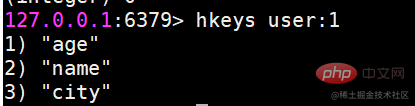
hkeys はすべてのフィールドを取得します
指定されたハッシュ キーを持つすべてのフィールドを返します
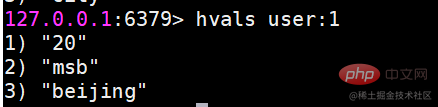
 hvals はすべての値を取得します
hvals はすべての値を取得します
 hgetall はすべてのフィールドと値を取得します
hgetall はすべてのフィールドと値を取得します
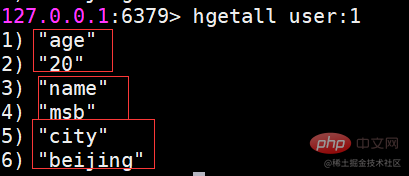 hgetall を使用する場合、数値がハッシュ要素が大きいと、Redis がブロックされる可能性があります。フィールドの一部のみを取得する必要がある場合は、hmget を使用できます。すべてのフィールド値を取得する必要がある場合は、hscan コマンドを使用できます。このコマンドは、ハッシュ タイプを徐々に走査します。hscan については後の章で紹介します。
hgetall を使用する場合、数値がハッシュ要素が大きいと、Redis がブロックされる可能性があります。フィールドの一部のみを取得する必要がある場合は、hmget を使用できます。すべてのフィールド値を取得する必要がある場合は、hscan コマンドを使用できます。このコマンドは、ハッシュ タイプを徐々に走査します。hscan については後の章で紹介します。
hincrby は、
hincrby と hincrbyfloat を追加します。これは incrby および incrbyfloat コマンドと同様ですが、そのスコープはファイルされます。
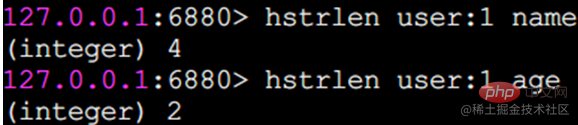
hstrlen value の文字列長を計算します
 コマンドの計算量
コマンドの計算量
ハッシュ型操作コマンド hdel、hmget では、 hmset の時間計算量は、コマンドによって伝送されるフィールドの数 O(k)、hkeys、hgetall、hvals に関連し、格納されるフィールドの総数 O(N) に関連します。残りのコマンドの時間計算量は O(1) です。
使用シナリオ
これまでの操作からわかるように、文字列とハッシュの操作は非常に似ていますが、ストレージ用にハッシュを作成する必要があるのはなぜでしょうか。
ハッシュ タイプは、オブジェクト タイプ データの保存に適しています。比較できます。データベース テーブルに記録されているユーザーが次の場合:
| 名前 | #年齢||
|---|---|---|
| ##2 | msb | |
|
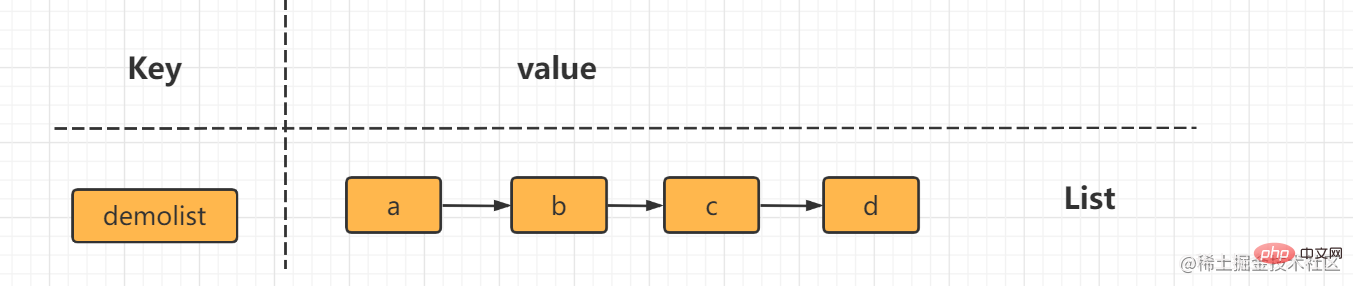
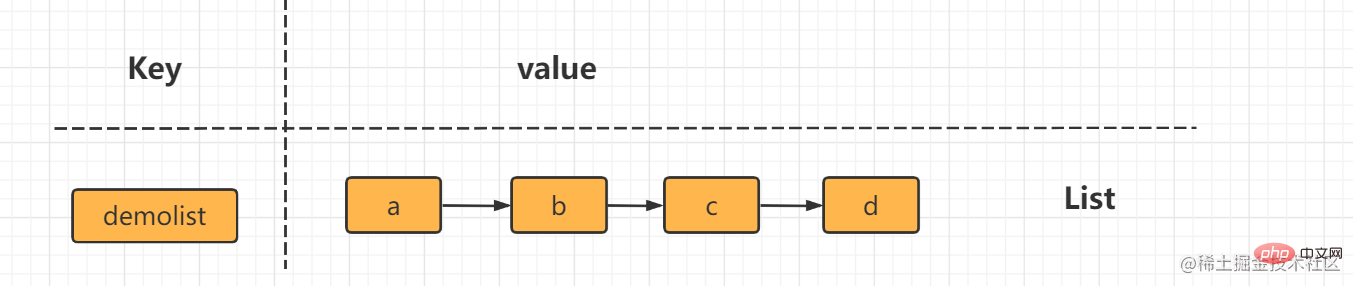
1. String 型 を使用するには、1 つずつ挿入および取得する必要があります。 ユーザーを設定:1:名前 lijin; ユーザーを設定:1:年齢 18; ユーザーを設定:2:名前 msb; ユーザーを設定:2:20 歳; 利点: シンプルで直感的、各キーが値に対応しています 欠点: キーが多すぎるため、多くのスペースを必要とします。メモリ、ユーザー 情報が分散しすぎているため、本番環境では使用できません 2. オブジェクトをシリアル化し、redis set user: に保存します。 1 Serialize(userInfo); 利点: プログラミングが簡単、シリアル化を使用する場合は適度なメモリ使用量 欠点: シリアル化と逆シリアル化には一定のオーバーヘッドがあり、userInfo属性を更新するときに更新する必要があるすべてを取り出して逆シリアル化し、更新してから redis 3 にシリアル化します。ハッシュ タイプ hmset を使用します。ユーザー:1 名前 lijin 年齢 18 ##hmset ユーザー:2 名前 msb 年齢 20#利点: シンプルで直感的で、合理的に使用するとメモリ領域の消費を削減できます欠点: 内部エンコード形式を制御する必要があり、不適切な形式はより多くのメモリを消費します。 #List (リスト) リスト (リスト) タイプは複数のデータを格納するために使用されます。順序付けられた文字列 a 4 つの要素 b、c、c、b は、左から右に順序付けられたリストを形成します。リスト内の各文字列は要素と呼ばれます。リストには最大 (2^32-1) 個の要素(4294967295)。
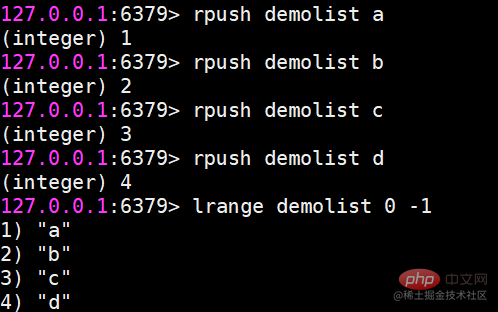
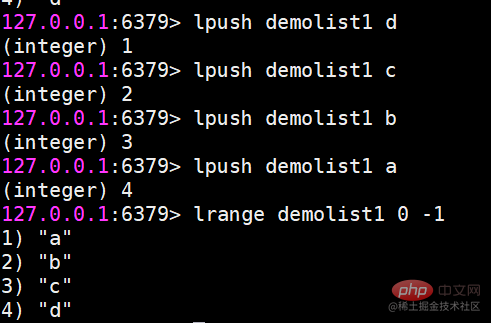
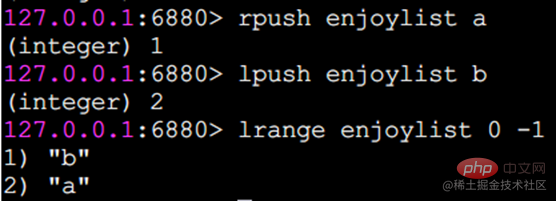
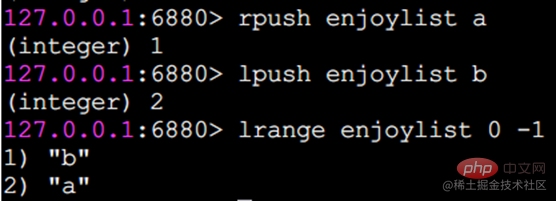
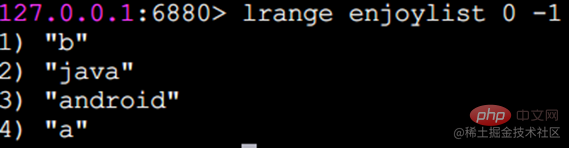
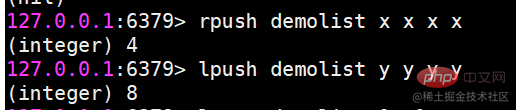
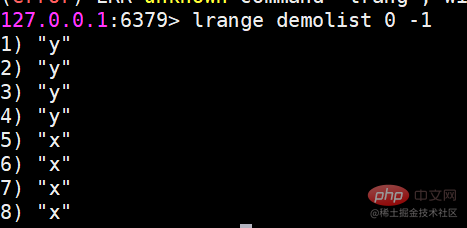
Redis では、リストの両端を挿入 (プッシュ) したり、ポップ (ポップ) したり、指定した範囲の要素のリストを取得したり、要素を取得したりすることもできます。指定されたインデックス添字などを使用します。 List は、スタックおよびキューとして機能する比較的柔軟なデータ構造であり、実際の開発では多くのアプリケーション シナリオがあります。 リスト タイプには 2 つの特徴があります。 まず、リスト内の要素が順序付けされます。これは、要素がインデックス添字またはリストを通じて取得できることを意味します。範囲内の要素の数。 2 番目に、リスト内の要素を繰り返すことができます。 操作コマンドlrange 指定範囲内の要素のリストを取得します(要素は削除されません)key start endインデックス添え字の機能:左から右へは 0 から N-1lrange 0 -1 コマンドはリストのすべての要素を左から右に取得できますrpush insert to right
lpush 左に挿入
linsert 前に挿入または要素の後 新しい要素
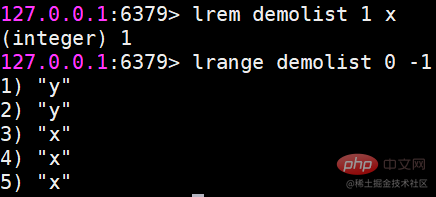
3 つの返される結果は現在のリストの長さですコマンドの完了後、リストに含まれる要素の数も表示されますが、rpush と lpush は両方とも複数の要素の同時挿入をサポートしています。 r ポップアップした後、要素は消えますので注意してください。 lrem 指定された要素を削除します。 lrem コマンドは、リストから value に等しい要素を見つけて削除します。カウントに応じて 3 つの状況があります:
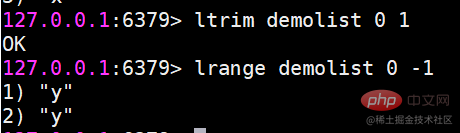
戻り値は、実際に削除された要素の数です。 ltirm インデックス範囲に従ってリストをトリミングしますたとえば、リストの 0 番目から 1 番目の要素を保持したい場合は、
lset 仕様を変更します インデックスの添字の要素
lindex リストの指定されたインデックスの添字にある要素を取得します
llen リストの長さを取得します
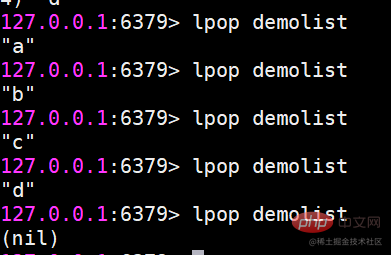
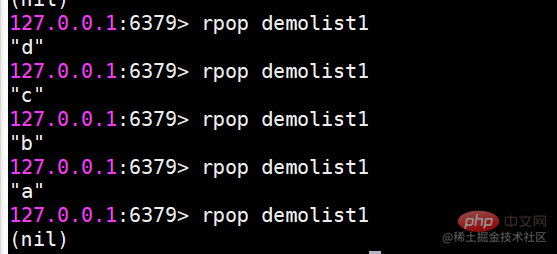
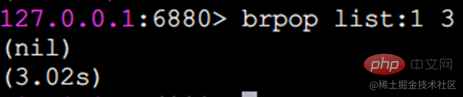
blpop および brpop はポップアップ要素をブロックしますblpop および brpop は lpop のバージョンをブロックしますおよび rpop. さらに、複数のリスト タイプと設定もサポートしています。ブロック時間を秒単位で設定します。ブロック時間が 0 の場合は、ブロックし続けることを意味します。 brpopを例に挙げてみましょう。
クライアントがブロックされました (要素がないとブロックされるため)
クライアントがブロックされました。このとき、別のクライアント B から
を実行すると、クライアント A は
を出力します。 brpop 複数のキーがある場合、brpop はキーを左から右に移動します。キーが要素をポップアップできると、クライアントはすぐに戻ります。 使用シナリオリスト タイプは、たとえば次のように使用できます: メッセージ キュー、Redis の lpush brpop コマンドの組み合わせによりブロッキング キューを実現でき、プロデューサー クライアントはリストから lrpush を使用します。要素を左側に挿入し、複数のコンシューマー クライアントが brpop コマンドを使用して、ブロック方式でリストの最後にある要素を「取得」します。複数のクライアントにより、負荷分散と消費の高可用性が保証されます。 記事リスト 各ユーザーは独自の記事リストを持っており、記事リストをページに表示する必要があります。現時点では、リストの使用を検討できます。リストは順序付けされているだけでなく、インデックス範囲に応じた要素の取得もサポートしているためです。 他のデータ構造の実装 lpush lpop =Stack(スタック) lpush rpop =Queue(キュー) lpsh ltrim =Capped Collection(制限付きコレクション) ) lpush brpop=Message Queue(Message Queue) SET
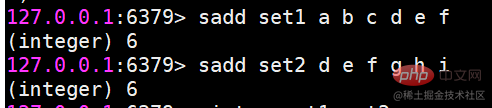
set タイプは、複数の文字列要素を保存するためにも使用されます。ただし、リスト タイプとは異なり、セット内で要素の重複は許可されず、セット内の要素には順序がなく、インデックス添字を使用して要素を取得することはできません。 コレクションには、最大 2 の 32 乗 - 1 つの要素を保存できます。コレクション内の追加、削除、変更、およびクエリのサポートに加えて、Redis は複数のコレクションの交差セット、和集合、および差分セットもサポートします。コレクション型を適切に使用すると、実際の開発における多くの実際的な問題を解決できます。 #セット内操作コマンドsadd 要素の追加複数の要素を追加でき、追加に成功した要素の数が返されます
指定された要素要素がセット内にある場合は 1 を返し、それ以外の場合は 1 を返します。 returns 0 指定された数が書き込まれていない場合、デフォルトは 1#spop はコレクションから要素をランダムにポップします数値を指定することもできます。書かれていない場合、デフォルトは 1 です。ポップしているため、spop コマンドの実行後、要素は次のようになります。コレクションから削除されますが、srandmember は削除しません。
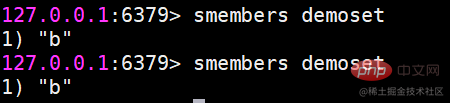
smembers すべての要素を取得します (ポップアップする要素はありません)戻り結果は順序付けされていません
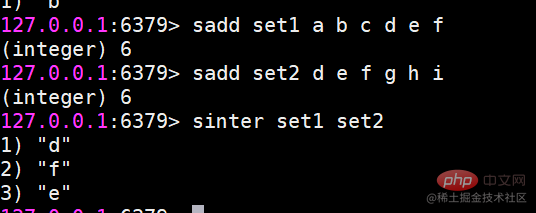
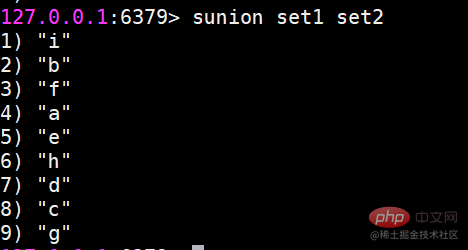
##これで set1 と set2 の 2 つのセットができましたsinter 複数のセットの共通部分を見つけます ##すいのん 複数の集合の和集合を求める
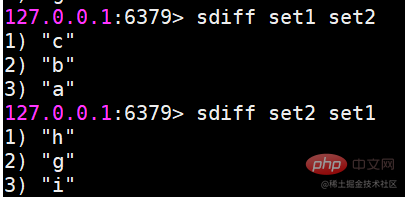
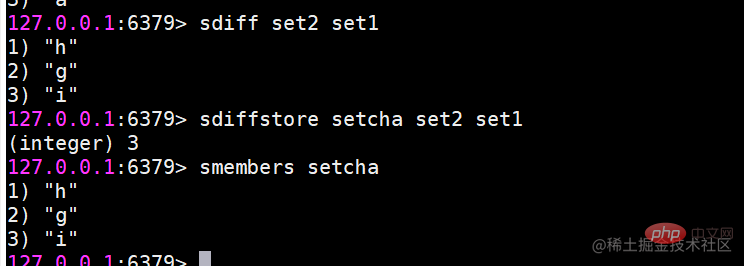
sdiff 複数の集合の差分を求める
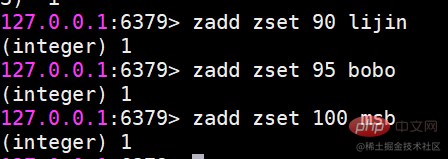
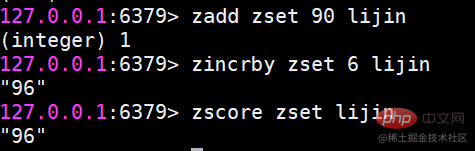
交差セット、和集合、および差分セットの結果を保存するsinterstore destination key [key ...] suionstore destination key [key ...] sdiffstore destination key [key ...]复制代码 要素が多いとセット間の操作に時間がかかるため、Redis では上記 3 つのコマンドを提供しています (オリジナルのコマンド ストア)セット間の交差、和集合、および差分の結果を宛先キーに保存します。例: 使用シナリオ セット タイプの比較 一般的な使用法シナリオはタグです。たとえば、あるユーザーはエンターテイメントやスポーツに興味があり、別のユーザーは歴史やニュースに興味がある場合、これらの興味のある点がタグになります。このデータにより、同じタグを好む人や、ユーザーが共通して好むタグを把握することができ、ユーザーエクスペリエンスやユーザーの粘着性を高めるために重要なデータとなります。 順序付きセットは、ハッシュ、リスト、セットと比べると少し馴染みがありませんが、順序付きセットの場合と呼ばれるため、は順序付きセットである場合、そのセットに関連している必要があります。セットに重複するメンバーを含めることができないという特性は維持されますが、順序付きセット内の要素は並べ替えることができるという違いがあります。ただし、並べ替えの基準としてインデックス添字を使用するリストとは異なり、並べ替えの基準として各要素のスコアを設定します。同じクラスの生徒の生徒番号を繰り返すことができないのと同様に、順序付きセット内の要素を繰り返すことはできませんが、スコアは繰り返すことができますが、テストの得点は同じになる可能性があります。 #コレクション内の操作コマンド #zadd はメンバーを追加します #返される結果は、正常に追加されたメンバーの数を表します注意:
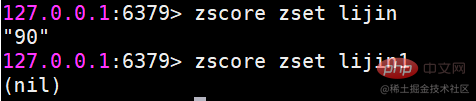
incr: スコアを増やします。これは、後で紹介する Zincrby と同等です。 zcardメンバー数の計算 zscore メンバーのスコアの計算#メンバーが存在しない場合は、return nil
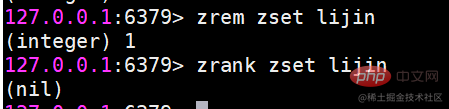
zrank是从分数从低到高返回排名 zrevrank反之 很明显,排名从0开始计算。 zrem 删除成员
允许一次删除多个成员。 返回结果为成功删除的个数。 zincrby 增加成员的分数
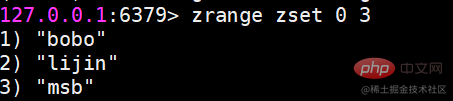
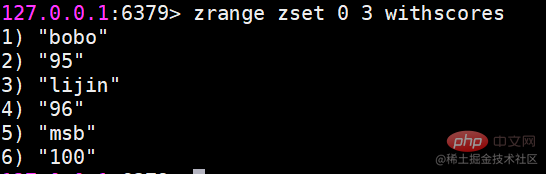
zrange和zrevrange返回指定排名范围的成员有序集合是按照分值排名的,zrange是从低到高返回,zrevrange反之。如果加上 withscores选项,同时会返回成员的分数
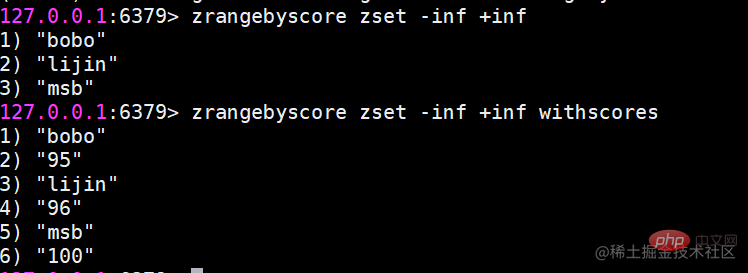
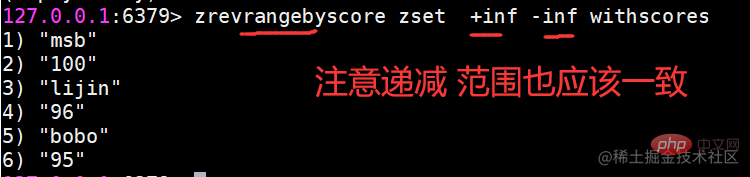
zrangebyscore返回指定分数范围的成员zrangebyscore key min max [withscores] [limit offset count] zrevrangebyscore key max min [withscores][limit offset count]复制代码 其中zrangebyscore按照分数从低到高返回,zrevrangebyscore反之。例如下面操作从低到高返回200到221分的成员,withscores选项会同时返回每个成员的分数。 同时min和max还支持开区间(小括号)和闭区间(中括号),-inf和+inf分别代表无限小和无限大:
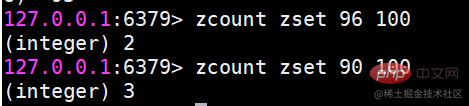
zcount 返回指定分数范围成员个数zcount key min max
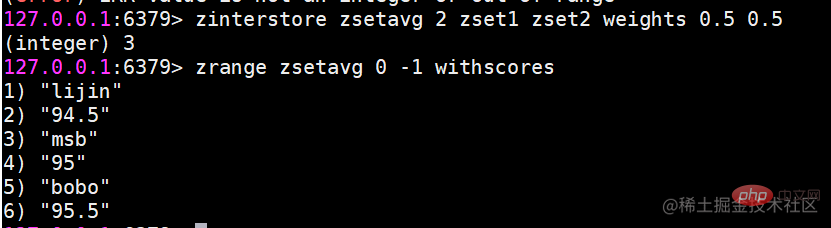
zremrangebyrank 按升序删除指定排名内的元素zremrangebyrank key start end zremrangebyscore 删除指定分数范围的成员zremrangebyscore key min max 集合间操作命令zinterstore 交集zinterstore 这个命令参数较多,下面分别进行说明 destination:交集计算结果保存到这个键。 numkeys:需要做交集计算键的个数。 key [key ...]:需要做交集计算的键。 weights weight [weight ...]:每个键的权重,在做交集计算时,每个键中的每个member 会将自己分数乘以这个权重,每个键的权重默认是1。 aggregate sum/ min |max:计算成员交集后,分值可以按照sum(和)、min(最小值)、max(最大值)做汇总,默认值是sum。 不太好理解,我们用一个例子来说明。(算平均分)
zunionstore 并集该命令的所有参数和zinterstore是一致的,只不过是做并集计算,大家可以自行实验。 使用场景有序集合比较典型的使用场景就是排行榜系统。例如视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多个方面的:按照时间、按照播放数量、按照获得的赞数。 持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第26天,点击查看活动详情 推荐学习:Redis视频教程 |


 #
#
 ls
ls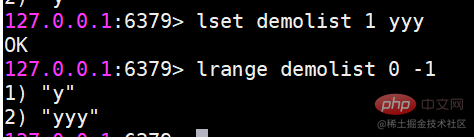
 l
l 






 ##sismember 要素がセット内にあるかどうかを決定します
##sismember 要素がセット内にあるかどうかを決定します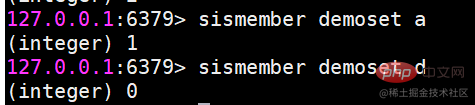 srandmember コレクションから指定された数の要素をランダムに返します
srandmember コレクションから指定された数の要素をランダムに返します 

 ch: この操作後に変更された順序付きセット要素の数とスコアを返します。
ch: この操作後に変更された順序付きセット要素の数とスコアを返します。 



以上がRedis で一般的に使用されるデータ構造 (整理および共有)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。