



この記事は、Python に関する関連知識を提供するもので、主に pytorch モデルの保存と読み込みに関するいくつかの問題の実践的な記録を紹介します。一緒に見てみましょう。皆様のお役に立てれば幸いです。ヘルプ。

Python3 ビデオ チュートリアル ]
1. torch でモデルを保存およびロードする方法1. モデル パラメーターとモデル構造の保存と読み込みtorch.save(model,path)
torch.load(path)
2. モデル パラメーターの保存と読み込みのみ - この方法は安全ですが、少し面倒ですtorch.save(model.state_dict(),path)
model_state_dic = torch.load(path)
model.load_state_dic(model_state_dic)
2. モデル保存の問題#1. シングル カード モデルでモデル構造とパラメータを保存した後の読み込みの問題
モデルを保存すると、モデル構造定義ファイルへのパスが記録されます。 . をロードすると、パスに従って解析されてパラメータがロードされますが、モデル定義ファイルのパスが変更されると、torch.load(path) を使用するとエラーが報告されます。
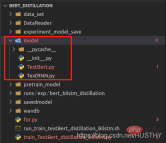
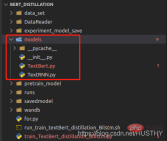
#モデルフォルダーをmodelsに変更した後、再度ロードするとエラーが報告されます。 
import torch from model.TextRNN import TextRNN load_model = torch.load('experiment_model_save/textRNN.bin') print('load_model',load_model)
完全なモデル構造とパラメーターを保存するこの方法では、モデル定義ファイルのパス
を変更しないように注意してください。2. シングルカード トレーニング モデルをマルチカード マシンに保存した後、シングルカード マシンにロードするとエラーが報告されます。マルチカード マシンでは 0 から開始し、モデルは n>= 1 でのグラフィックス カード トレーニングが保存された後、コピーがシングルカード マシンにロードされます
import torch from model.TextRNN import TextRNN load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin') print('load_model',load_model)
cuda デバイスの不一致の問題が発生します - 保存したモデル コード セグメント ウィジェット タイプ cuda1 を使用する場合、torch.load() を使用してそれを開くと、デフォルトで cuda1 が検索され、ロードされます。モデルをデバイスに接続します。現時点では、map_location を直接使用して問題を解決し、モデルを CPU にロードできます。
load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin',map_location=torch.device('cpu'))
3. マルチ GPU トレーニング モデルのモデル構造とパラメーターを保存してロードした後に発生する問題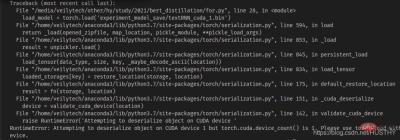
#a. モデル構造とパラメータを一緒に保存し、ロード時に使用します
#
torch.distributed.init_process_group(backend='nccl')
上記のマルチプロセスメソッドなので、ロード時に宣言しないとエラーが報告されます。
#b. モデルパラメータを個別に保存するmodel = Transformer(num_encoder_layers=6,num_decoder_layers=6) state_dict = torch.load('train_model/clip/experiment.pt') model.load_state_dict(state_dict)同じ問題が発生しますが、ここでの問題は、パラメータ辞書のキーがモデルで定義されているキーと異なることです

model = torch.load('train_model/clip/Vtransformers_bert_6_layers_encoder_clip.bin') print(model) model.cuda(args.local_rank) 。。。。。。 model = nn.parallel.DistributedDataParallel(model,device_ids=[args.local_rank],find_unused_parameters=True) print('model',model)パッケージ化前のモデル構造:

外層にはさらに DistributedDataParallel とモジュールがあるため、ロード時に重みが表示されますシングルカード環境でのモデルの重み キーが一致していません。 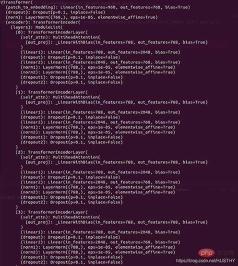
if gpu_count > 1:
torch.save(model.module.state_dict(),save_path)
else:
torch.save(model.state_dict(),save_path)
model = Transformer(num_encoder_layers=6,num_decoder_layers=6)
state_dict = torch.load(save_path)
model.load_state_dict(state_dict)これはより良いパラダイムであり、ロード時にエラーは発生しません。 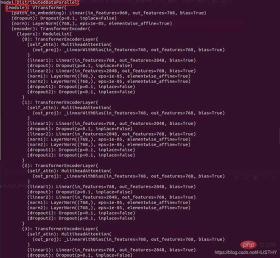 【関連する推奨事項:
【関連する推奨事項:
]
以上がpytorch モデルの保存と読み込みにおけるいくつかの問題の実践的な記録の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Python:コンパイラまたはインタープリター?May 13, 2025 am 12:10 AM
Python:コンパイラまたはインタープリター?May 13, 2025 am 12:10 AMPythonは解釈された言語ですが、コンパイルプロセスも含まれています。 1)Pythonコードは最初にBytecodeにコンパイルされます。 2)ByteCodeは、Python Virtual Machineによって解釈および実行されます。 3)このハイブリッドメカニズムにより、Pythonは柔軟で効率的になりますが、完全にコンパイルされた言語ほど高速ではありません。
 ループvs whileループ用のpython:いつ使用するか?May 13, 2025 am 12:07 AM
ループvs whileループ用のpython:いつ使用するか?May 13, 2025 am 12:07 AMuseaforloopwhenteratingoverasequenceor foraspificnumberoftimes; useawhileloopwhentinuninguntinuntilaConditionismet.forloopsareidealforknownownownownownownoptinuptinuptinuptinuptinutionsituations whileoopsuitsituations withinterminedationations。
 Pythonループ:最も一般的なエラーMay 13, 2025 am 12:07 AM
Pythonループ:最も一般的なエラーMay 13, 2025 am 12:07 AMpythonloopscanleadtoErrorslikeinfiniteloops、ModifiningListsDuringiteration、Off-Oneerrors、Zero-dexingissues、およびNestededLoopinefficiencies.toavoidhese:1)use'i
 ループの場合、およびPythonのループ:それぞれの利点は何ですか?May 13, 2025 am 12:01 AM
ループの場合、およびPythonのループ:それぞれの利点は何ですか?May 13, 2025 am 12:01 AMforloopsareadvastountousforknowterations and sequences、offeringsimplicityandeadability;
 Python:編集と解釈に深く掘り下げますMay 12, 2025 am 12:14 AM
Python:編集と解釈に深く掘り下げますMay 12, 2025 am 12:14 AMpythonusesahybridmodelofcompilation andtertation:1)thepythoninterpretercompilessourcodeodeplatform-indopent bytecode.2)thepythonvirtualmachine(pvm)thenexecuteTesthisbytecode、balancingeaseoputhswithporformance。
 Pythonは解釈されたものですか、それとも編集された言語であり、なぜそれが重要なのですか?May 12, 2025 am 12:09 AM
Pythonは解釈されたものですか、それとも編集された言語であり、なぜそれが重要なのですか?May 12, 2025 am 12:09 AMpythonisbothintersedand compiled.1)it'scompiledtobytecode forportabalityacrossplatforms.2)bytecodeisthenは解釈され、開発を許可します。
 ループ対pythonのループの場合:説明されたキーの違いMay 12, 2025 am 12:08 AM
ループ対pythonのループの場合:説明されたキーの違いMay 12, 2025 am 12:08 AMloopsareideal whenyouwhenyouknumberofiterationsinadvance、foreleloopsarebetterforsituationsは、loopsaremoreedilaConditionismetを使用します
 ループのために:実用的なガイドMay 12, 2025 am 12:07 AM
ループのために:実用的なガイドMay 12, 2025 am 12:07 AMhenthenumber ofiterationsisknown advanceの場合、dopendonacondition.1)forloopsareideal foriterating over for -for -for -saredaverseversives likelistorarrays.2)whileopsaresupasiable forsaresutable forscenarioswheretheloopcontinupcontinuspificcond


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

WebStorm Mac版
便利なJavaScript開発ツール

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

