
ホームページ >データベース >mysql チュートリアル >MySQL インデックスの左端一致原則の詳細な例
MySQL インデックスの左端一致原則の詳細な例

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-09-06 17:32:462994ブラウズ

推奨される学習: mysql ビデオ チュートリアル
準備
以降の手順については、まず次のテーブル (MySQL5.7) には合計 5 つのフィールド (a、b、c、d、e) があります。ここで a が主キー、b、c、d で構成されるジョイント インデックスがあり、ストレージ エンジンは InnoDB、3 つのテスト データが挿入されます。 この記事のすべてのステートメントを MySQL で試してみることを強くお勧めします。
CREATE TABLE `test` ( `a` int NOT NULL AUTO_INCREMENT, `b` int DEFAULT NULL, `c` int DEFAULT NULL, `d` int DEFAULT NULL, `e` int DEFAULT NULL, PRIMARY KEY(`a`), KEY `idx_abc` (`b`,`c`,`d`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci; INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (1, 2, 3, 4, 5); INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (2, 2, 3, 4, 5); INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (3, 2, 3, 4, 5);
このとき、以下のSQL文を実行するとインデックスが使用されると思いますか?
SELECT b, c, d FROM test WHERE d = 2;
左端の一致原則 (ジョイント インデックスで簡単に説明されているように、左端のフィールドから一致を開始し、条件内のフィールドがジョイント インデックスの左から右の順序と一致する場合) に従う場合は、それ以外の場合は、(a, b, c) の結合インデックスは、(a, b) インデックスと (a, b, c) インデックスを作成することと同じであると単純に理解できます。はい、インデックスを通過できませんが、EXPLAIN ステートメントを使用して分析すると、非常に興味深い現象が見つかります。インデックスを使用した出力は次のとおりです。

これは非常に奇妙です。左端の一致原則が失敗したのでしょうか?実際、いいえ、段階的に分析してみましょう。
詳細な理論的説明
現在は基本的に InnoDB エンジンがメインエンジンとなっているため、主な説明では InnoDB を例として使用します。
クラスター化インデックスと非クラスター化インデックス
MySQL の最下層は B ツリーを使用してインデックスを保存し、データはリーフ ノードに保存されます。 InnoDB の場合、主キー インデックスと行レコードが一緒に保存されるため、クラスター化インデックスと呼ばれます。クラスター化インデックスを除き、通常のインデックス、一意のインデックスなど、その他すべては非クラスター化インデックス (セカンダリ インデックス) と呼ばれます。
InnoDB には、クラスター化インデックスが 1 つだけあります:
- テーブルに主キーがある場合、主キー インデックスはクラスター化インデックスです。テーブルに主キーがない場合、最初の空でない一意のインデックスがクラスター化インデックスとして使用されます;
- それ以外の場合、ROWID は暗黙的にクラスター化インデックスとして定義されます。
- 次の図を例に挙げます。id、name、age の 3 つのフィールドを持つテーブルがあるとします。ID が主キーであるため、id はクラスター化インデックス、name は非クラスター化インデックスとしてインデックス付けされます。 idとnameのインデックスに関しては以下のBツリーがあり、クラスター化インデックスのリーフノードには主キーと行レコードが格納され、非クラスター化インデックスのリーフノードには主キーが格納されていることがわかります。
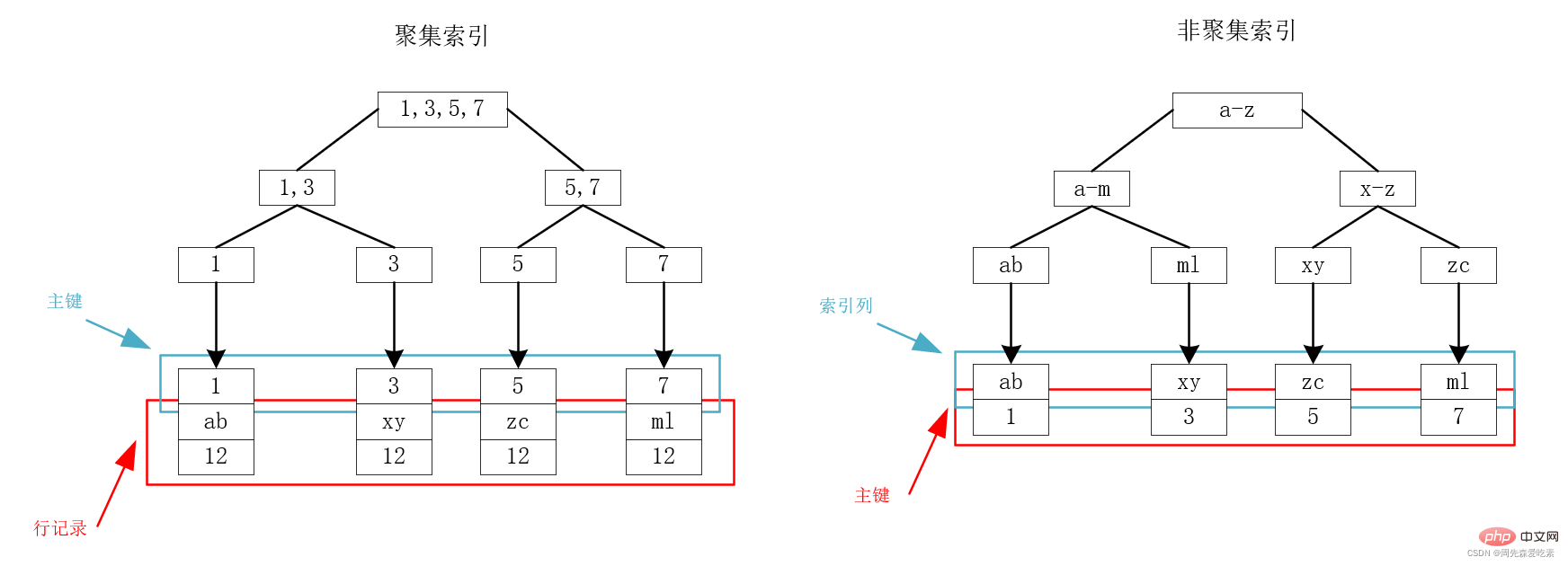 テーブル クエリに戻る
テーブル クエリに戻る
上記のインデックス ストレージ構造から、主キー インデックス ツリー上で 1 回限りのクエリを実行できることがわかります。主キーを使用して、必要なデータをすばやく見つけます。主キーが行レコードと一緒に保存されるため、これは非常に直感的であり、主キーが見つかると、探しているすべてのフィールドを含むレコードが見つかります。
ただし、非クラスター化インデックスの場合は、上の右の図に示すように、最初に name が配置されているインデックス ツリーに従って対応する主キーを見つけてから、目的のレコードをクエリする必要があることがわかります。主キー インデックス ツリーを経由するこのプロセスは、リターン テーブル クエリと呼ばれます。
インデックス カバレッジ
上記のテーブルを返すクエリは間違いなくクエリの効率を低下させます。そのため、テーブルを返さないようにする方法はありますか?これがインデックスカバレッジです。いわゆるインデックス カバレッジとは、このインデックスを使用してクエリを実行するときに、そのインデックス ツリーのリーフ ノード上のデータがクエリを実行するすべてのフィールドをカバーできるため、テーブルが返されることを回避できることを意味します。最初の例に戻りましょう。
(b,c,d) という結合インデックスを確立したため、クエリするフィールドが b、c、d にある場合、テーブルは返されません。インデックス ツリーは 1 回だけ表示する必要があります。これがインデックス カバレッジです。 左端一致原則
は、結合インデックスの左端の列のインデックスを指します。複数のフィールドの結合インデックスにも同じことが当てはまります。たとえば、index(a,b,c) ジョイント インデックスは、単一列インデックス、(a,b) ジョイント インデックス、および (a,b,c) ジョイント インデックスを作成することと同じです。
次のステートメントを実行して、この原則を確認できます。
EXPLAIN SELECT * FROM test WHERE b = 1;
EXPLAIN SELECT * FROM test WHERE b = 1 and c = 2;

EXPLAIN SELECT * FROM test WHERE b = 1 and c = 2 and d = 3;

接着,我们尝试一条不符合最左原则的查询,它也如图预期一样,走了全表扫描。
EXPLAIN SELECT * FROM test WHERE d = 3;

详细规则
我们先来看下面两个语句,他们的输出如下。
EXPLAIN SELECT b, c from test WHERE b = 1 and c = 1; EXPLAIN SELECT b, d from test WHERE d = 1;
id|select_type|table|partitions|type|possible_keys|key |key_len|ref |rows|filtered|Extra | --+-----------+-----+----------+----+-------------+-------+-------+-----------+----+--------+-----------+ 1|SIMPLE |test | |ref |idx_bcd |idx_bcd|10 |const,const| 1| 100.0|Using index| i d|select_type|table|partitions|type |possible_keys|key |key_len|ref|rows|filtered|Extra | --+-----------+-----+----------+-----+-------------+-------+-------+---+----+--------+------------------------+ 1|SIMPLE |test | |index|idx_bcd |idx_bcd|15 | | 3| 33.33|Using where; Using index|
显然第一条语句是符合最左匹配的,因此type为ref,但是第二条并不符合最左匹配,但是也不是全表扫描,这是因为此时这表示扫描整个索引树。
具体来看,index 代表的是会对整个索引树进行扫描,如例子中的,列 d,就会导致扫描整个索引树。ref 代表 mysql 会根据特定的算法查找索引,这样的效率比 index 全扫描要高一些。但是,它对索引结构有一定的要求,索引字段必须是有序的。而联合索引就符合这样的要求,联合索引内部就是有序的,你可以理解为order by b,c,d这种排序规则,先根据字段b排序,再根据字段c排序,以此类推。这也解释了,为什么需要遵守最左匹配原则,当最左列有序才能保证右边的索引列有序。
因此,我们总结最后的原则为,若符合最左覆盖原则,则走ref这种索引;若不符合最左匹配原则,但是符合覆盖索引(index),就可以扫描整个索引树,从而找到覆盖索引对应的列,避免回表;若不符合最左匹配原则,也不符合覆盖索引(如本例的select *),则需要扫描整个索引树,并且回表查询行记录,此时,查询优化器认为这样两次查找索引树,还不如全表扫描来得快(因为联合索引此时不符合最左匹配原则,要不普通索引查询慢得多),因此,此时会走全表扫描。
补充:为什么要使用联合索引
减少开销。建一个联合索引(col1,col2,col3),实际相当于建了(col1),(col1,col2),(col1,col2,col3)三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
覆盖索引。对联合索引(col1,col2,col3),如果有如下的sql: select col1,col2,col3 from test where col1=1 and col2=2。那么MySQL可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机io操作。减少io操作,特别的随机io其实是dba主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
效率高。索引列越多,通过索引筛选出的数据越少。有1000W条数据的表,有如下sql:select from table where col1=1 and col2=2 and col3=3,假设假设每个条件可以筛选出10%的数据,如果只有单值索引,那么通过该索引能筛选出1000W10%=100w条数据,然后再回表从100w条数据中找到符合col2=2 and col3= 3的数据,然后再排序,再分页;如果是联合索引,通过索引筛选出1000w10% 10% *10%=1w,效率提升可想而知!
推荐学习:mysql视频教程
以上がMySQL インデックスの左端一致原則の詳細な例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。