



この記事では、SQL サーバー に関する関連知識を提供します。主に、SQL のケース スタディにおける文字列の結合と分割に関する関連情報を紹介します。この記事では、2 つの方法をそれぞれ紹介します。この方法には、 Oracle を学習または使用するすべての人にとって、学習の参考となる価値があり、必要な友人が参照できます。

推奨学習: 「SQL チュートリアル 」
文字列のマージ


SQL の実装:
--方法一 SELECT d.dept_name,wm_concat(e.emp_name) FROM employee e INNER JOIN department d ON d.dept_id=e.dept_id GROUP BY d.dept_name;
実行結果:

SQL分析:
Oracle 独自の wm_concat() 関数を使用して文字列をマージします。ここには欠点があります。マージされた接続記号はデフォルトのカンマのみであり、他の記号は使用できません。 文字列マージ方法 2:SQL の実装:
--方法二 SELECT d.dept_name, LISTAGG (e.emp_name, ',') WITHIN GROUP (ORDER BY e.emp_name) names FROM employee e INNER JOIN department d ON d.dept_id=e.dept_id GROUP BY d.dept_name;
実行結果:

SQL 分析:
Oracle 独自の LISTAGG() 関数を使用して文字列をマージします。その利点は、マージされた接続シンボルを任意の文字として指定できることです。 ORDER BY ソートを簡単に実装できます。 文字列分割

SQL の実装:
--方法一
WITH t (id, name, sub, str) AS (
SELECT id, name, substr(class, 1, instr(class, '、')-1), substr(concat(class,'、'), instr(class, '、')+1)
FROM movies
UNION ALL
SELECT id, name,substr(str, 1, instr(str, '、')-1), substr(str, instr(str, '、')+1)
FROM t WHERE instr(str, '、')>0
)
SELECT id, name, sub
FROM t
ORDER BY id;
Execution結果:

このステートメントは少し複雑なので、以下で順を追って説明します。 :
まず、映画テーブルの元のデータを確認します:
 1. 最初のステップは、クラス フィールドの値を次に従って除算することです。区切り文字 (ここではカンマ) 2 つの部分への予備的な分割を実行します。最初の部分は分割されるクラス フィールドの最初の値であり、2 番目の部分は分割されるクラス フィールドの残りの部分の値です。
1. 最初のステップは、クラス フィールドの値を次に従って除算することです。区切り文字 (ここではカンマ) 2 つの部分への予備的な分割を実行します。最初の部分は分割されるクラス フィールドの最初の値であり、2 番目の部分は分割されるクラス フィールドの残りの部分の値です。
 2. 2 番目のステップでは、WITH 式を使用して再帰クエリを実装し、区切り文字 (ここではカンマ) に従って最初のステップの分割されていない値をループします (パート 2) フィールドの最後の区切り文字まで分割し、再帰の最後のデータを一時テーブル t に配置します。
2. 2 番目のステップでは、WITH 式を使用して再帰クエリを実装し、区切り文字 (ここではカンマ) に従って最初のステップの分割されていない値をループします (パート 2) フィールドの最後の区切り文字まで分割し、再帰の最後のデータを一時テーブル t に配置します。
 3. 3 番目のステップは、2 番目のステップの一時テーブル t のレコードをクエリして並べ替える単純なクエリです。
3. 3 番目のステップは、2 番目のステップの一時テーブル t のレコードをクエリして並べ替える単純なクエリです。
 文字列分割方法 2:
文字列分割方法 2:
--方法二
SELECT m.name,t.column_value FROM movies m,TABLE(SPLIT(m.class,'、')) t;

このメソッドは実際に関数をカスタマイズすることで文字列を処理します。関数分割のロジックは実際には似ています。どちらも再帰を使用して文字列内の値を区切り文字に従って 1 つずつ分割し、最終的に分割された文字列を返します。個人的には、この方法の方が優れていると感じています。分割ロジックがカプセル化されており、使いやすく、ロジックが明確になっているためです。
以下は分割関数の作成スクリプトです:
create or replace function split (p_list clob, p_sep varchar2 := ',')
return tabletype
pipelined
is
l_idx pls_integer;
v_list varchar2 (32676) := to_char(p_list);
begin
loop
l_idx := instr (v_list, p_sep);
if l_idx > 0
then
pipe row (substr (v_list, 1, l_idx - 1));
v_list := substr (v_list, l_idx + length (p_sep));
else
pipe row (v_list);
exit;
end if;
end loop;
end;関数の戻り値の型、tabletype もカスタム型です。
このタイプの作成スクリプトは次のとおりです:
create or replace type tabletype as table of varchar2(32676);
推奨学習: "
SQL チュートリアル以上がSQL のケーススタディ: 文字列のマージと分割の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询Aug 26, 2022 pm 02:07 PM
SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询Aug 26, 2022 pm 02:07 PM本篇文章给大家带来了关于SQL的相关知识,其中主要介绍了SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询的方法,文中通过示例代码介绍的非常详细,下面一起来看一下,希望对大家有帮助。
 SQL Server解析/操作Json格式字段数据的方法实例Aug 29, 2022 pm 12:00 PM
SQL Server解析/操作Json格式字段数据的方法实例Aug 29, 2022 pm 12:00 PM本篇文章给大家带来了关于SQL server的相关知识,其中主要介绍了SQL SERVER没有自带的解析json函数,需要自建一个函数(表值函数),下面介绍关于SQL Server解析/操作Json格式字段数据的相关资料,希望对大家有帮助。
 聊聊优化sql中order By语句的方法Sep 27, 2022 pm 01:45 PM
聊聊优化sql中order By语句的方法Sep 27, 2022 pm 01:45 PM如何优化sql中的orderBy语句?下面本篇文章给大家介绍一下优化sql中orderBy语句的方法,具有很好的参考价值,希望对大家有所帮助。
 Monaco Editor如何实现SQL和Java代码提示?May 07, 2023 pm 10:13 PM
Monaco Editor如何实现SQL和Java代码提示?May 07, 2023 pm 10:13 PMmonacoeditor创建//创建和设置值if(!this.monacoEditor){this.monacoEditor=monaco.editor.create(this._node,{value:value||code,language:language,...options});this.monacoEditor.onDidChangeModelContent(e=>{constvalue=this.monacoEditor.getValue();//使value和其值保持一致i
 一文搞懂SQL中的开窗函数Sep 02, 2022 pm 04:55 PM
一文搞懂SQL中的开窗函数Sep 02, 2022 pm 04:55 PM本篇文章给大家带来了关于SQL server的相关知识,开窗函数也叫分析函数有两类,一类是聚合开窗函数,一类是排序开窗函数,下面这篇文章主要给大家介绍了关于SQL中开窗函数的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下。
 Monaco Editor怎么实现SQL和Java代码提示May 11, 2023 pm 05:31 PM
Monaco Editor怎么实现SQL和Java代码提示May 11, 2023 pm 05:31 PMmonacoeditor创建//创建和设置值if(!this.monacoEditor){this.monacoEditor=monaco.editor.create(this._node,{value:value||code,language:language,...options});this.monacoEditor.onDidChangeModelContent(e=>{constvalue=this.monacoEditor.getValue();//使value和其值保持一致i
 如何使用exp进行SQL报错注入May 12, 2023 am 10:16 AM
如何使用exp进行SQL报错注入May 12, 2023 am 10:16 AM0x01前言概述小编又在MySQL中发现了一个Double型数据溢出。当我们拿到MySQL里的函数时,小编比较感兴趣的是其中的数学函数,它们也应该包含一些数据类型来保存数值。所以小编就跑去测试看哪些函数会出现溢出错误。然后小编发现,当传递一个大于709的值时,函数exp()就会引起一个溢出错误。mysql>selectexp(709);+-----------------------+|exp(709)|+-----------------------+|8.218407461554972
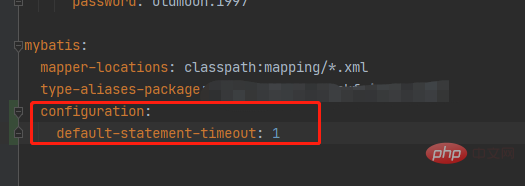 springboot配置mybatis的sql执行超时时间怎么解决May 15, 2023 pm 06:10 PM
springboot配置mybatis的sql执行超时时间怎么解决May 15, 2023 pm 06:10 PM当某些sql因为不知名原因堵塞时,为了不影响后台服务运行,想要给sql增加执行时间限制,超时后就抛异常,保证后台线程不会因为sql堵塞而堵塞。一、yml全局配置单数据源可以,多数据源时会失效二、java配置类配置成功抛出超时异常。importcom.alibaba.druid.pool.DruidDataSource;importcom.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;importorg.apache.


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

