
Redis における共通分散ロックの原則と実装 (概要共有)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-08-25 11:53:502640ブラウズ

推奨学習: Redis ビデオ チュートリアル
Java のロックには、主に同期ロックと JUC パッケージのロックが含まれます。これらはすべて単一の JVM インスタンス上のロックに関するものであり、分散環境では無効です。では、分散ロックを実装するにはどうすればよいでしょうか?
一般的な分散ロックの実装は次のとおりです:

データベースに基づく
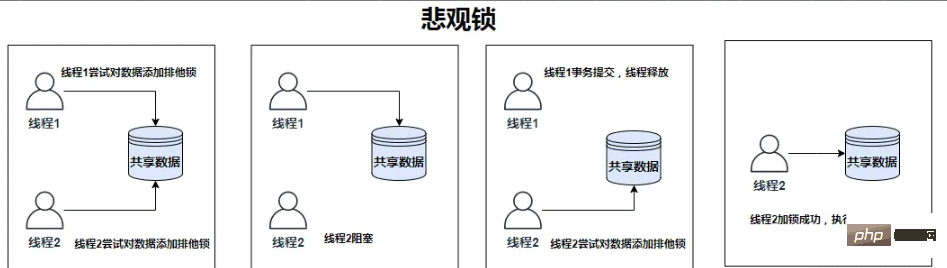
悲観的ロック
悲観的ロック (悲観的ロック) は、その名前が示すように、非常に悲観的なロックであり、データを取得するたびにロックされます。このようにして、悲観的ロックが解放されるまでデータを取得しようとする他のユーザーはブロックされます。悲観的ロック内の共有リソースは一度に 1 つのスレッドによってのみ使用され、他のスレッドはブロックされます。使用後、リソースはただし、効率の点で、ロック機構の処理は追加のオーバーヘッドを生成し、デッドロックが発生しやすくなります。
実装原則
ペシミスティック同時実行制御は、実際には「最初にロックを取得してからアクセスする」という保守的な戦略であり、データ処理のセキュリティを保証します。
具体的な実装
##たとえば、悲観的ロックを通じて在庫控除を実現する擬似コードは次のとおりです。
// 对于库存记录进行行锁
SELECT *FROM sys_goods s WHERE s.Id='1' FOR UPDATE;
//执行库存扣减
update sys_stock s set s.stockQty=s.stockQty-#{number} where s.goodId=1 and s.stockQty>0;
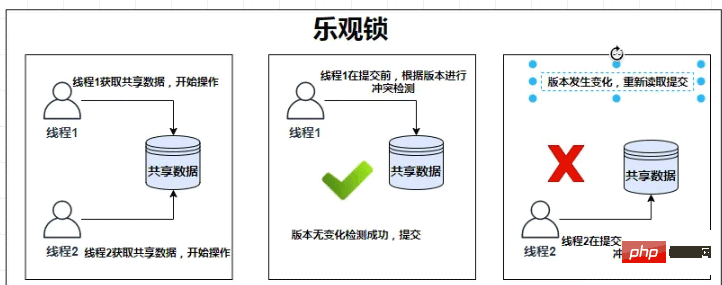
//提交事务,自动释放悲观锁。楽観的ロックはじめにオプティミスティック ロックは、データ バージョン番号 (バージョン) メカニズムに基づいて実装されます。データベース テーブルに「バージョン」フィールドを追加します。データを読み取るときに、このバージョン番号が読み出されます。更新プロセス中にバージョン番号が比較されます。それらが一致していれば、操作は正常に実行され、バージョン番号が表示されます。 1. バージョン番号が一致しない場合、アップデートは失敗します。 実装原理悲観的ロックと比較すると、楽観的ロックの実装はデータベースのロック機構を使用しません。楽観的ロックの原理は CAS 機構を使用して実装されます。CAS (比較-
- 1,
- 比較: 値 A を読み取り、それを B に更新する前に、次のことを確認します。元の値は A のままです (他のスレッドによって変更されていません) 2.
- Settings: 変更が送信されない場合は、A を B に更新して終了します。変化が起こっても何もしません。
たとえば、在庫控除を実装するためのオプティミスティック ロックの疑似コードは次のとおりです。
// 查询库存记录,获取版本号
SELECT stockQty,version FROM sys_goods s WHERE s.Id='1'
//执行库存扣减,防止出现超卖
update sys_stock s set
s.stockQty=s.stockQty-#{number},
s.version=version+1
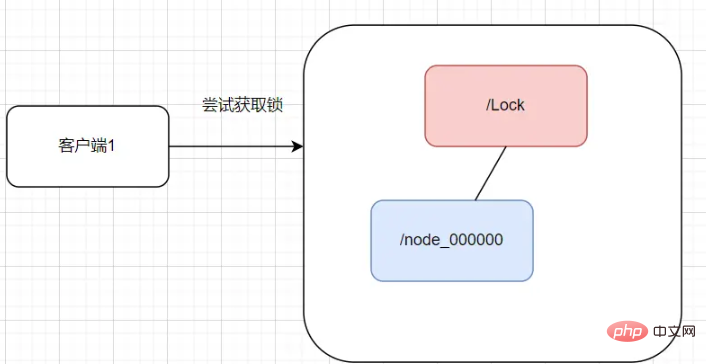
where s.goodId=1 and s.stockQty>0 and version=#{version};Redis は分散型を実装します。 lockRedis 分散ロックの実装については以前の記事で説明しています。次の記事を参照してください。Spring Boot は Redis 分散ロックの原理を実装しますSpring Boot統合 分散ロックを実装する Redisson の詳細なケースZooker の分散ロックの実装Zookper は、主に Zookeeper ノードの一時的かつ秩序立った性質を適用することによって、分散ロックを実装します。 ロック プロセスクライアント 1 が要求すると、Zookeeper クライアントは永続ノードの Locks ノードを作成します。クライアント 1 がロックを取得したい場合は、locks ノード/の下に一時的なノードを作成します。 node_000000 で、ロックの下に一時的に順序付けされた子ノードがすべて見つかった場合、最小のノードである場合、ロックの取得に成功します。
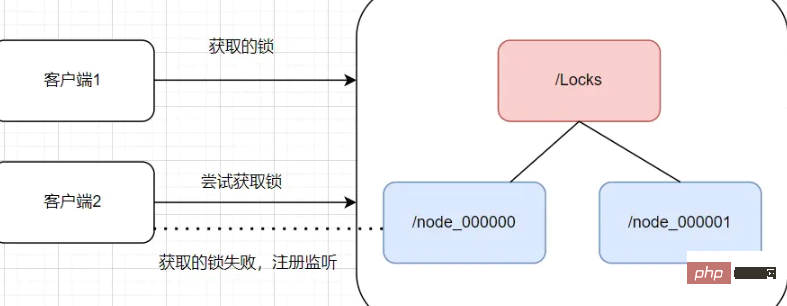
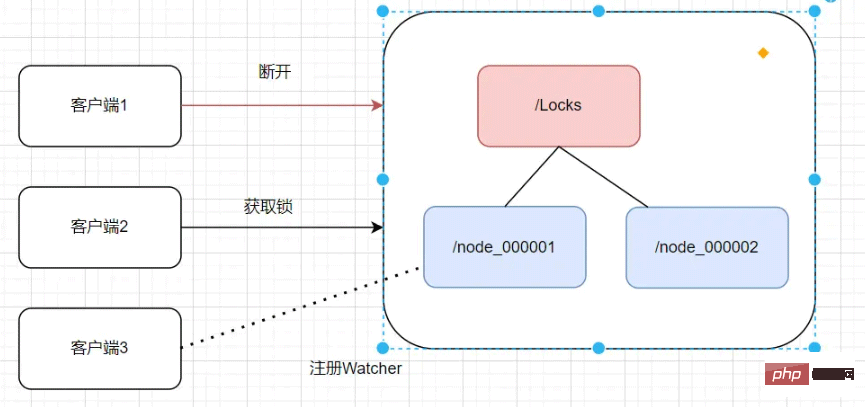
异常场景分析
客户端1创建临时节点后,会与Zookeeper服务器维护一个Session,这个Session会依赖客户端 定时心跳来维持连接。由于网路异常原因,Zookeeper长时间收不到客户端1的心跳,就认为这个Session过期了,也会把这个临时节点删除,此时客户端2创建临时节点能够获取锁成功。当客户端网络恢复正常后,它仍然认为持有锁,此时就会造成锁冲突。
具体实现
Zookeeper实现分布式锁,可以采用Curator实现分布式锁,关于SpringBoot如何集成Curator,大家可以参考如下文章:
Java Spring Boot 集成Zookeeper
Zookpeer实现分布式锁实现库存扣减
@RequestMapping("/lockStock")
public void lockStock()
{
zooKeeperUtil.lock("/Locks", 1000, TimeUnit.SECONDS, ()->{
//业务逻辑
});
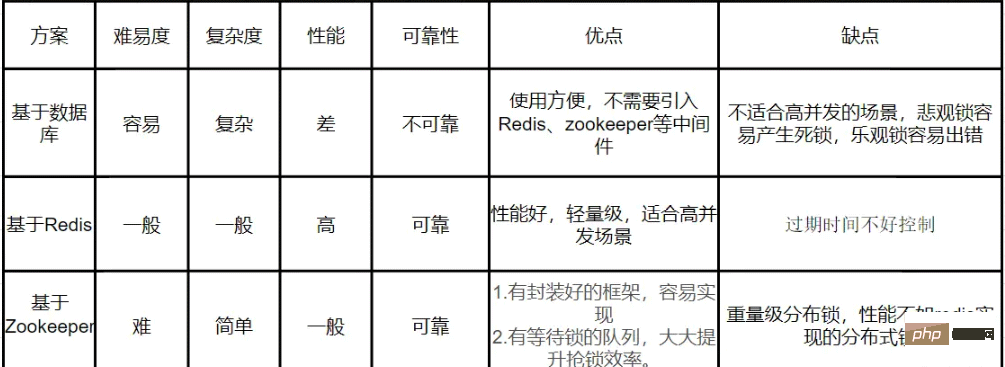
}小结:
关于分布式锁的实现的对比,详情请查看下图:
推荐学习:Redis视频教程
以上がRedis における共通分散ロックの原則と実装 (概要共有)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。