SHOW PROCESSLIST は、現在のデータベース接続の使用状況やさまざまなステータス情報を表示するのに非常に便利です。 SHOW PROCESSLIST; 最初の 100 項目のみがリストされます。すべてをリストしたい場合は、SHOW FULL PROCESSLIST を使用してください。
| テーブルの確認 |
データシートを確認してください (これは自動です)。 |
| テーブルを閉じています |
テーブル内の変更されたデータはディスクにフラッシュされ、使い果たされたテーブルは閉じられています。これは簡単な操作ですが、そうでない場合は、ディスク領域がいっぱいであるか、ディスクに高い負荷がかかっているかを確認する必要があります。 |
#接続出力 | レプリケーション スレーブ サーバーがマスター サーバーに接続しています。 |
ディスク上の tmp テーブルにコピーしています | 一時結果セットが tmp_table_size (デフォルト 16M) より大きいため、一時テーブルはメモリ ストレージからディスク ストレージに変換されていますメモリを節約するためです。 |
一時テーブルの作成 | クエリ結果を保存するために一時テーブルを作成しています。 |
メインテーブルから削除 | サーバーは複数テーブル削除の最初の部分を実行中で、最初のテーブルを削除したところです。 |
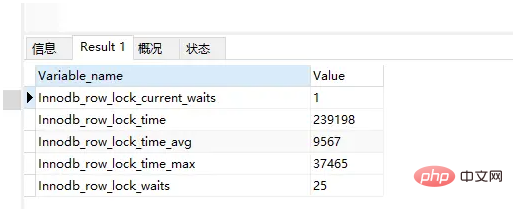
3.SHOW STATUS LIKE 'InnoDB_row_lock%'
InnoDB の行レベルのロック ステータス変数。

InnoDB の行レベルのロック ステータス変数は、ロック待機数を記録するだけでなく、合計ロック期間、毎回の平均期間、および最大期間も記録します。累積ステータス量は、現在ロックを待っている待機数を示します。各ステータス量の説明は次のとおりです:
- InnoDB_row_lock_current_waits: 現在待機しているロックの数;
- InnoDB_row_lock_time: システム起動から現在までの合計ロック時間;
- InnoDB_row_lock_time_avg: 各回の待機に費やされる平均時間;
- InnoDB_row_lock_time_max: システムの起動から現在までの最も一般的な時間の待機に費やされる時間;
- InnoDB_row_lock_waits: 開始から現在までの待機の合計数システム起動から現在まで;
これら 5 つのステータス変数のうち、より重要なものは、InnoDB_row_lock_time_avg (平均待機時間)、InnoDB_row_lock_waits (待機時間の合計数)、および InnoDB_row_lock_time (待機時間の合計) です。特に待機数が多く、各待機の長さが短くない場合は、システム内で待機が非常に多くなる理由を分析し、分析結果に基づいて最適化計画の指定を開始する必要があります。
InnoDB_row_lock_waits や InnoDB_row_lock_time_avg の値が比較的高いなど、ロックの競合が深刻であることがわかった場合は、InnoDB モニターを設定して、ロックの競合が発生しているテーブルとデータ行をさらに監視することもできます。ロック競合の理由を分析します。
4.SHOW ENGINE INNODB STATUS
SHOW ENGINE INNODB STATUS コマンドは、InnoDB モニターによって現在監視されている多くの情報を出力します。その出力は、行と列のない単一の文字列です。コンテンツは多くの小さなセクションに分かれており、各セクションは innodb ストレージ エンジンのさまざまな部分に関する情報に対応しており、その一部の情報は innodb 開発者にとって非常に役立ちます。
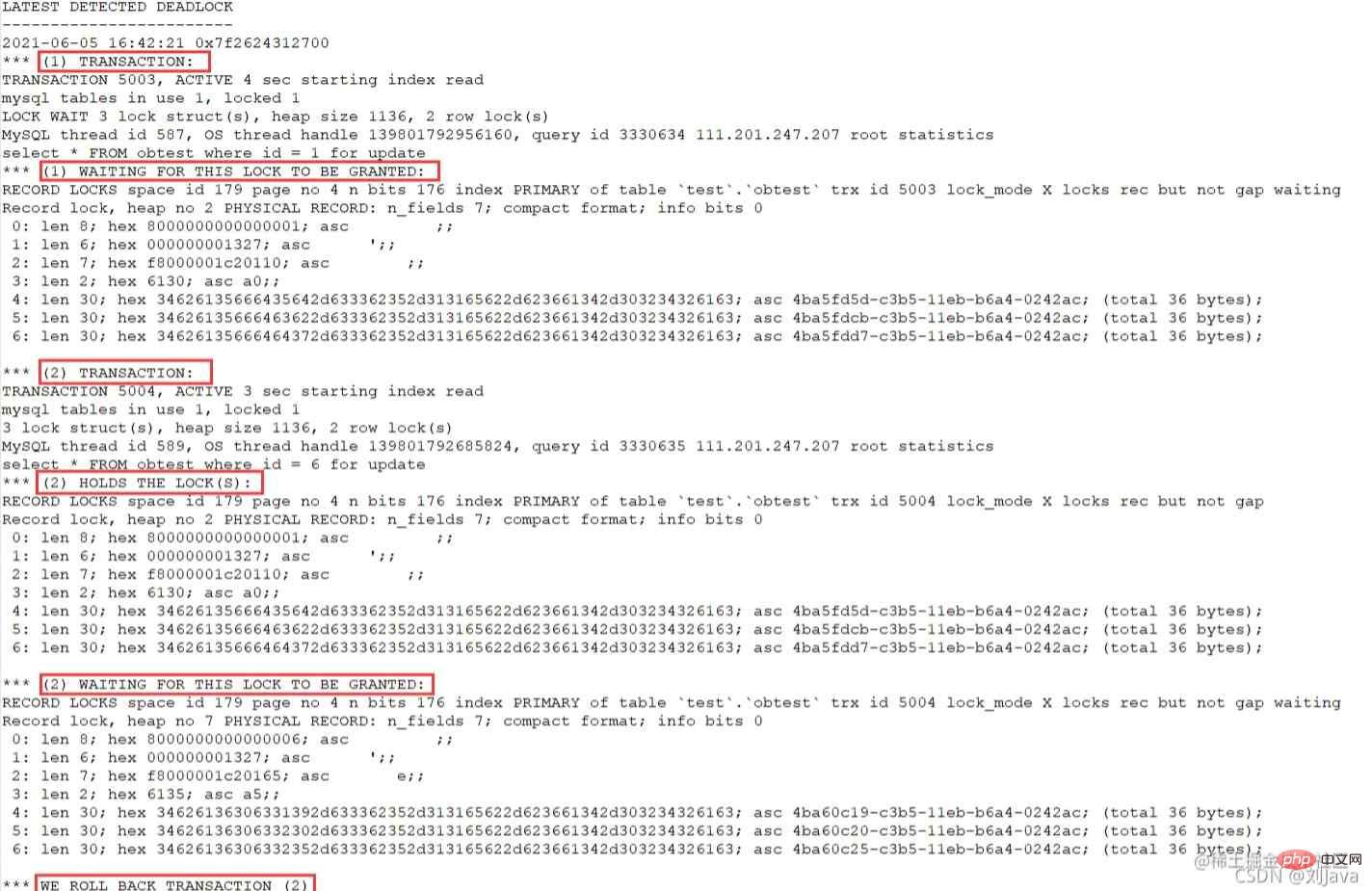
次の例に示すように、「LATEST DETECTED DEADLOCK」セクションがあり、これは最後に記録されたデッドロック情報です:
##"(1) TRANSACTION" が表示されます 最初のトランザクションに関する情報が表示されます。 - "(1) WAITING FOR THIS LOCK TO BE GRANTED" は、最初のトランザクションが待機しているロック情報が表示されます
- "(2) TRANSACTION " は 2 番目のトランザクション情報を表示します。
- 「(2) HOLDS THE LOCK(S)」 は 2 番目のトランザクションが保持しているロック情報を表示します。
- 「(2) WAITING FOR THIS LOCK TO BE」 GRANTED」は 2 番目のトランザクションを待っているロック情報を表示します。
- #最後の行は、「WE ROLL BACK TRANSACTION (2)」など、2 番目のトランザクションがロールバックされたことを示す処理結果を示します。
- 5.SHOW INDEXS
SHOW INDEXS はテーブル内のインデックス情報をクエリします: SHOW INDEXES FROM table_name;
テーブルを作成する SQL は次のとおりです:
CREATE TABLE contacts(
contact_id INT AUTO_INCREMENT,
first_name VARCHAR(100) NOT NULL comment 'first name',
last_name VARCHAR(100) NOT NULL,
email VARCHAR(100),
phone VARCHAR(20),
PRIMARY KEY(contact_id),
UNIQUE(email),
INDEX phone(phone) ,
INDEX names(first_name, last_name) comment 'By first name and/or last name'
);ストアド プロシージャは 50,000 個のデータを挿入します:
CREATE PROCEDURE zqtest ( ) BEGIN
DECLARE
i INT DEFAULT 0;
DECLARE
j VARCHAR ( 100 ) DEFAULT 'first_name';
DECLARE
k VARCHAR ( 100 ) DEFAULT 'last_name';
DECLARE
l VARCHAR ( 100 ) DEFAULT 'email';
DECLARE
m VARCHAR ( 20 ) DEFAULT '11111111111';
SET i = 0;
START TRANSACTION;
WHILE
i < 50000 DO
IF
MOD ( i, 100 ) = 0 THEN
SET j = CONCAT( 'first_name', i );
END IF;
IF
MOD ( i, 200 ) = 0 THEN
SET k = CONCAT( 'last_name', i );
END IF;
IF
MOD ( i, 50 ) = 0 THEN
SET m = CONCAT( '', CAST( m as UNSIGNED) + i );
END IF;
INSERT INTO contacts ( first_name, last_name, email, phone )
VALUES
( j, k, CONCAT(l,i), m );
SET i = i + 1;
END WHILE;
COMMIT;
END;
Use show Index from contacts; 結果は次のようになります:
フィールドの説明:
テーブル
| テーブル名 |
|
Non_unique
| 一意のインデックスは 0 であり、他のインデックスは 1 です。主キー インデックスも唯一のインデックスです。 | |
Key_name
| インデックス名。名前が同じ場合は、同じであることを意味します。インデックスであり、それはジョイント インデックスです。各行はジョイント インデックス内の列を表します。 |
|
Seq_in_index
| インデックス内の列のシーケンス番号 (1 から始まります)。結合インデックス内の列の順序を示すこともできます。 |
|
Column_name
| インデックス列名。結合インデックスの場合は、特定のインデックスの名前です。 column |
|
Collation
| 列がインデックスにどのように格納されるか、おそらく文字の順序を意味します。 |
|
カーディナリティ
| インデックス上の異なる値の数は「カーディナリティ」と呼ばれ、区別度とも呼ばれます。ベースが大きいほど、インデックスの区別が良くなります。この値の統計は必ずしも正確であるとは限らず、修正することができますANALYZE TABLE を使用します。 |
|
Sub_part
| プレフィックス インデックス。列が部分的にのみインデックス付けされている場合、インデックス付けされた文字数。列全体の値にインデックスが付けられている場合は NULL。 |
|
Packed
| キーワードの圧縮方法。圧縮されていない場合は NULL。圧縮には通常、圧縮トランスポート プロトコル、圧縮カラム ソリューション、圧縮テーブル ソリューションが含まれます。 |
|
Null
| 列値に null を含めることができる場合、YES |
|
Index_type
| インデックス構造のタイプ、一般的なものには、FULLTEXT、HASH、BTREE、RTREE |
|
Comment、Index_comment
| Comments |
|
が含まれます。6.ALTER TABLE xx ENGINE = INNODB
インデックス構造を含むテーブルを再構築します。データの削除時に残るインデックスのページ分割とディスクの断片化を排除できます。
7.ANALYZE TABLE
テーブルを再構築するのではなく、データを変更せずにテーブルのインデックス情報を再カウントするだけであり、このプロセスでは MDL 読み取りロックが追加されます。これは、show Index from tablename; の統計インデックスのカーディナリティが異常なデータである状況を修正するために使用できます。
推奨学習: mysql ビデオ チュートリアル
以上がMySQL でのデータベース最適化のための一般的な SQL ステートメント (概要共有)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




 フィールドの説明:
フィールドの説明: