
ホームページ >Java >&#&チュートリアル >Java字句解析DDL再帰アプリケーションの詳細な分析
Java字句解析DDL再帰アプリケーションの詳細な分析

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-07-25 17:35:472552ブラウズ
この記事は、java に関する関連知識を提供します。主に、Java 字句解析ツールの DDL 再帰的アプリケーションの詳細な説明を紹介します。必要な友人は参照してください。一緒に見てみましょう。みんなが助けてくれることを願っています。

推奨学習: 「java ビデオ チュートリアル 」
intellij プラグイン
既成のプラグインがないため、
私たちは主に PyCharm を開発に使用していることを考慮して、jetbrains はプラグイン開発用の SDK も提供しています。 UI 追加の側面を考慮する必要はありません。
使用プロセスは非常に簡単で、DDL ステートメントをインポートして、Python に必要な Model コードを生成するだけです。
たとえば、次の DDL をインポートします:
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userName` varchar(20) DEFAULT NULL COMMENT '用户名', `password` varchar(100) DEFAULT NULL COMMENT '密码', `roleId` int(11) DEFAULT NULL COMMENT '角色ID', PRIMARY KEY (`id`), ) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8
対応する Python コードが生成されます:
class User(db.Model):
__tablename__ = 'user'
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
userName = db.Column(db.String) # 用户名
password = db.Column(db.String) # 密码
roleId = db.Column(db.Integer) # 角色ID字句解析
これは非常に簡単です。ソース ファイルとターゲット コードを注意深く比較する パターンを見つけるのは簡単です。これは、テーブル名、フィールド、フィールド属性 (主キー、型、長さなど) を解析し、最終的に変換するだけです。 Python で必要なテンプレートに追加します。
始める前は、文字列を解析するだけでとても簡単なことだと思っていましたが、実際に始めてみるとそうではなく、主に次のような問題があることがわかりました。
- ## テーブル名を識別するにはどうすればよいですか?
- 同様に、フィールド名を識別し、フィールドのタイプ、長さ、コメントを関連付ける方法も説明します。
- 主キーを識別するにはどうすればよいですか?
x = 20何によると通常、エクスペリエンスを開発する場合、このステートメントは次の部分に分かれています。
- x
は変数を表します - =
は代入記号 # を表します##20 - は割り当て結果を表します
# #GE =VAL 100状態移行もう一度始める前に考えてみましょう。上記の結果では、この解析プロセスは、編集原則では「字句解析」と呼ばれます。編集原則という言葉を聞くと混乱するかもしれません(私もです)。このスクリプトでは、そのような結果を生成するための非常に単純な字句パーサーを作成できます。
VAR
が変数を表し、GE が代入を表していることがわかります。記号「=」と「VAL」は割り当て結果を表します。ここで、これら 3 つの状態を覚えることに集中する必要があります。 文字を順番に読み取って解析すると、プログラムは以下に示すようにこれらの状態を行ったり来たりします。
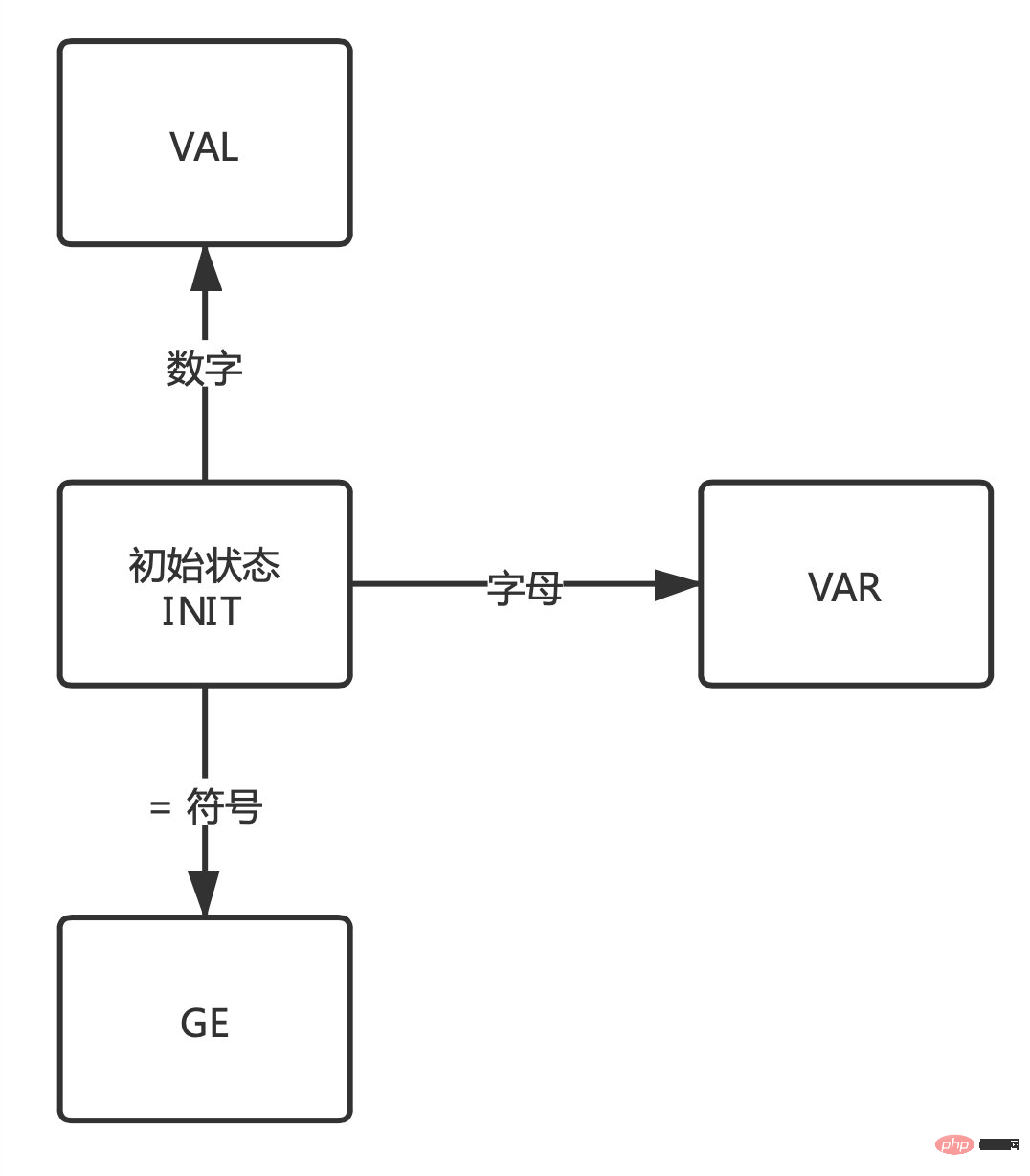 デフォルトは初期状態 。
デフォルトは初期状態 。
- 文字が文字の場合、
- VAR 状態になります。
-
文字が「=」記号の場合、GE 状態になります。
同様に、これらの状態を満たさない場合は、初期状態に戻り、再度新しい状態を確認します。 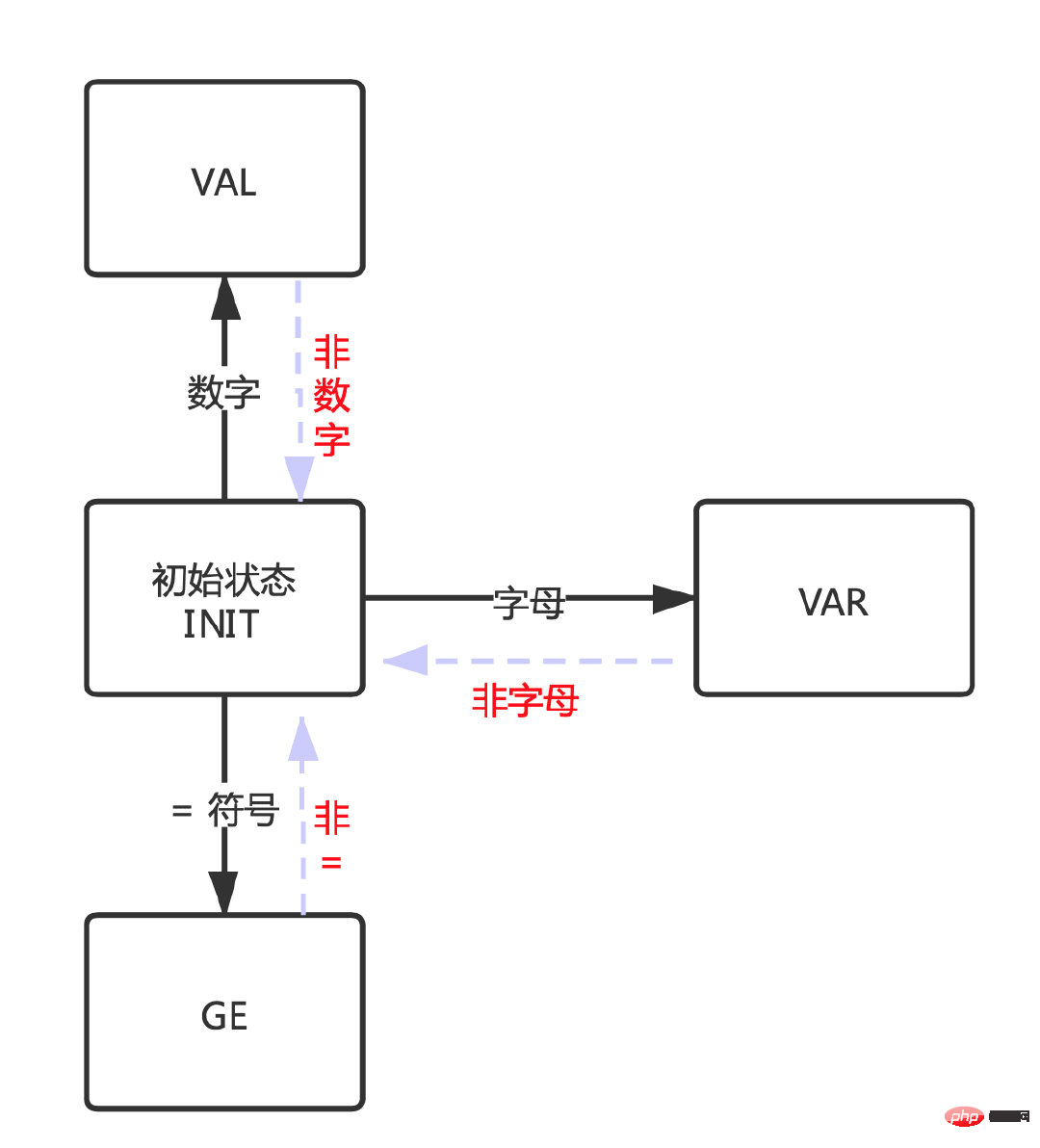
public class Result{
public TokenType tokenType ;
public StringBuilder text = new StringBuilder();
} 最初に、最終分析結果を収集する結果クラスを定義します; TokenType
図中の 3 つの状態は単純に列挙値で表されます。public enum TokenType {
INIT,
VAR,
GE,
VAL
}最初は、最初の図: 初期化状態に対応します。 現在解析されている文字の TokenType
を定義する必要があります: は、図で説明されているプロセスと一致しており、次のことを決定します。現在のキャラクターに与えられるステータスは 1 つだけです。 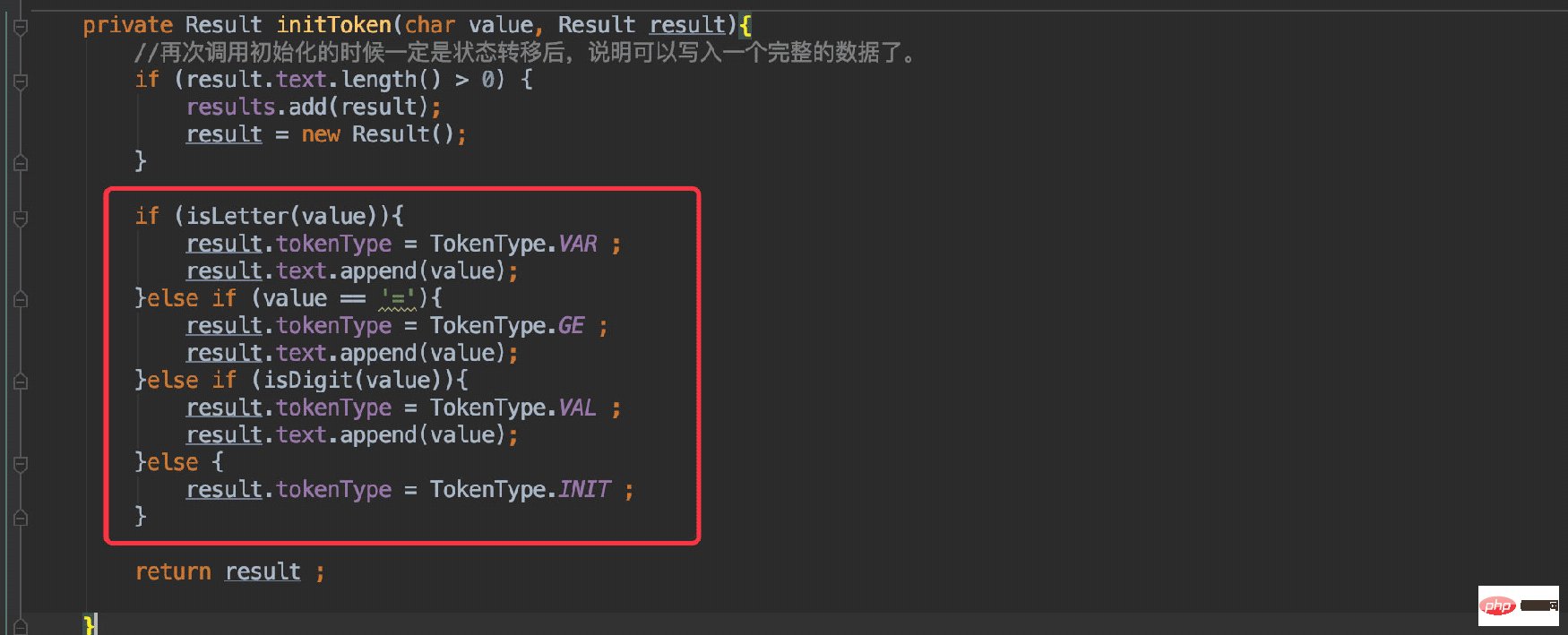
は、異なる状態に応じて異なる 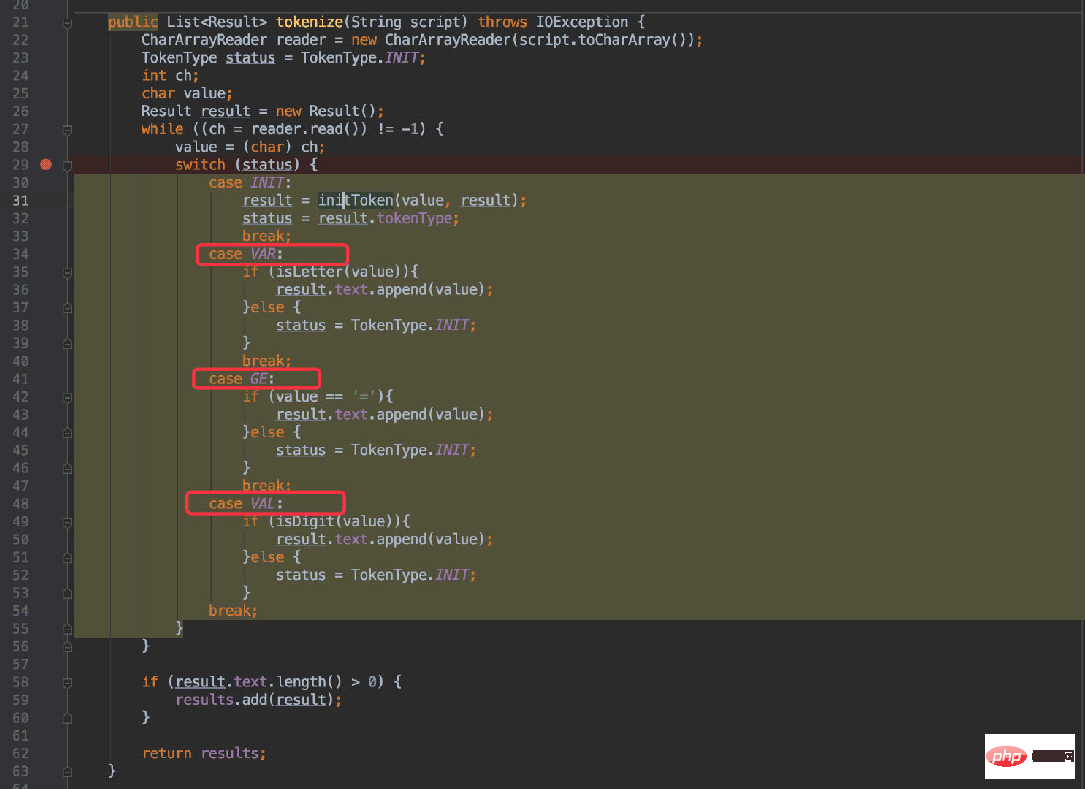 case
case
case で他の状態にジャンプするかどうかを判断します (状態は INIT 状態に入った後に再生成されます)。 例: x = 20
最初の選択肢は VAR
= が再度決定され、GE 状態になります。 スクリプトが ab = 30
最初の文字は a で、これも VAR 状態に入り、2 番目の文字は b です。したがって、行 36 を入力してもステータスは変更されず、文字 b が追加され、その後の手順は前の例と一致します。 これ以上言っても無駄です。自分で 1 つのテストを実行すると、次のことが理解できると思います。<p style="max-width:90%"><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/3b1107932145f80f7f892df40984009b-5.png" class="lazy" alt=""></p>
<p style="text-align:center"><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/3b1107932145f80f7f892df40984009b-6.png" class="lazy" alt=""></p>
<h3>DDL 解析</h3>
<p>简单的解析完成后来看看<code>DDL这样的脚本应当如何解析:
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userName` varchar(20) DEFAULT NULL COMMENT '用户名', `password` varchar(100) DEFAULT NULL COMMENT '密码', `roleId` int(11) DEFAULT NULL COMMENT '角色ID', PRIMARY KEY (`id`), ) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8
原理类似,首先还是要看出规律(也就是语法):
- 表名是第一行语句,同时以
CREATE TABLE开头。 - 每一个字段的信息(名称、类型、长度、备注)都是以 “`” 符号开头 “,” 结尾。
- 主键是以 PRIMART 字符串开头的字段,以
)结尾。
根据我们需要解析的数据种类,我这里定义了这个枚举:
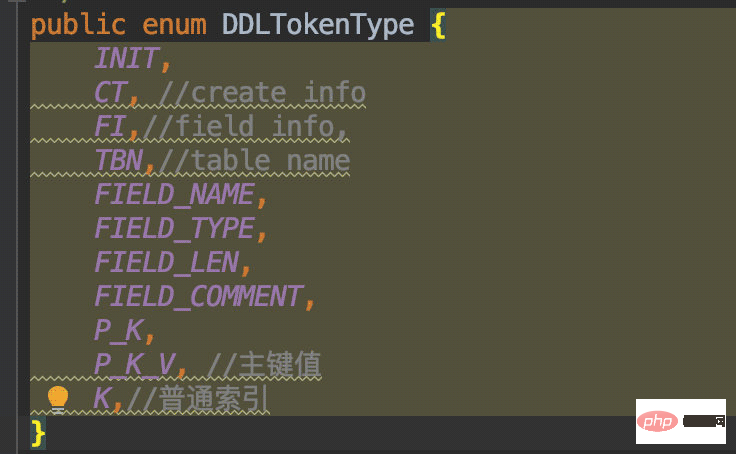
然后在初始化类型时进行判断赋值:
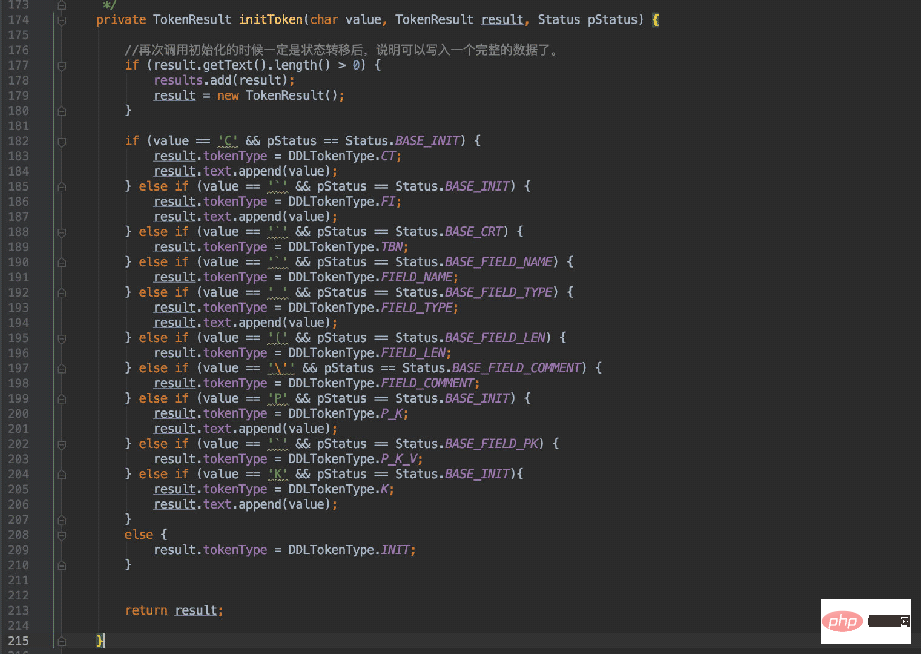
由于需要解析的数据不少,所以这里的判断条件自然也就多了。
递归解析
针对于DDL的语法规则,我们这里还有需要有特殊处理的地方;比如解析具体字段信息时如何关联起来?
举个例子:
`userName` varchar(20) DEFAULT NULL COMMENT '用户名', `password` varchar(100) DEFAULT NULL COMMENT '密码',
这里我们解析出来的数据得有一个映射关系:
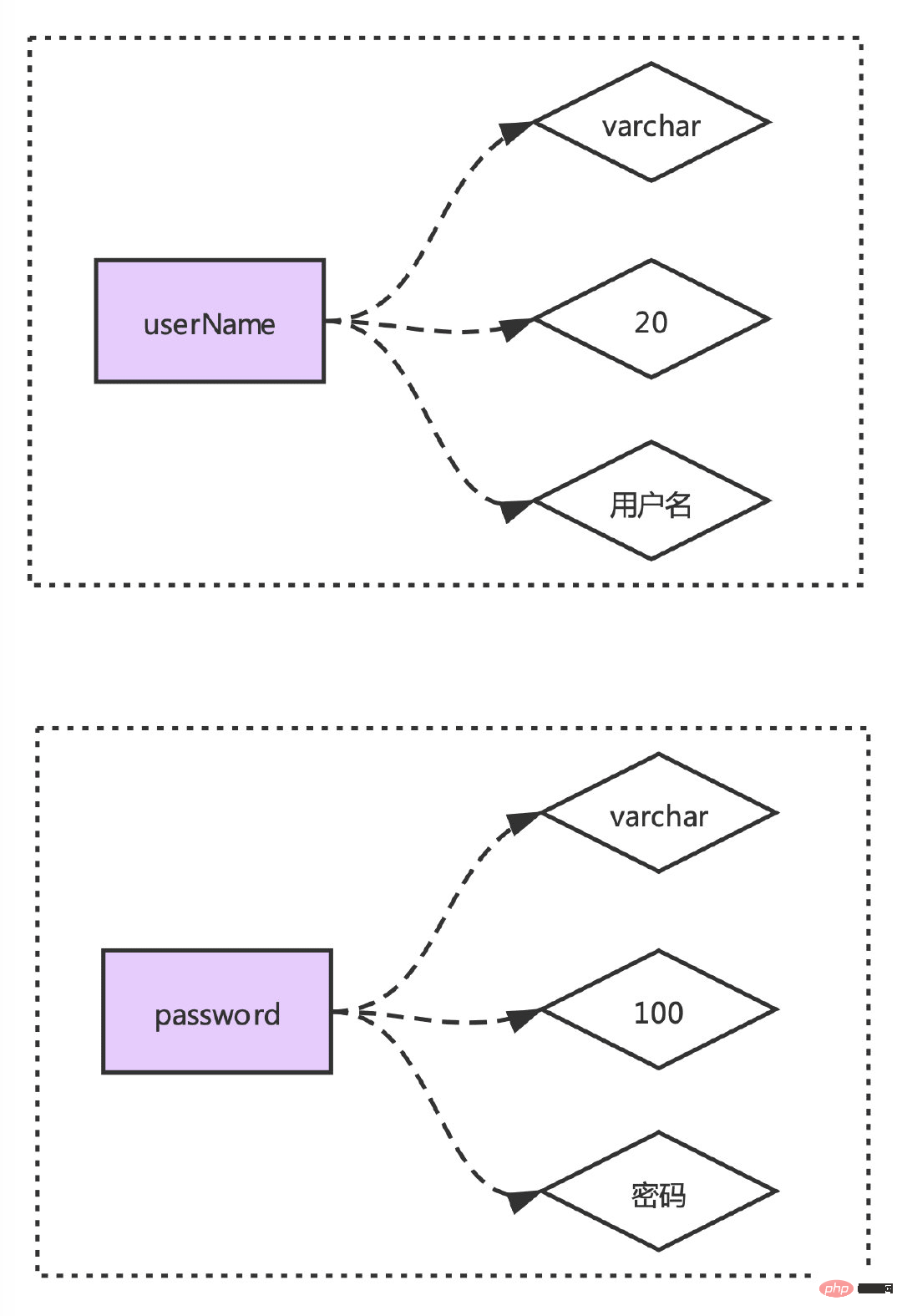
所以我们只能一个字段的全部信息解析完成并且关联好之后才能解析下一个字段。
于是这里我采用了递归的方式进行解析(不一定是最好的,欢迎大家提出更优的方案)。
} else if (value == '`' && pStatus == Status.BASE_INIT) {
result.tokenType = DDLTokenType.FI;
result.text.append(value);
}当当前字符为 ”`“ 符号时,将状态置为 “FI”(FieldInfo),同时当解析到为 “,” 符号时便进入递归处理。
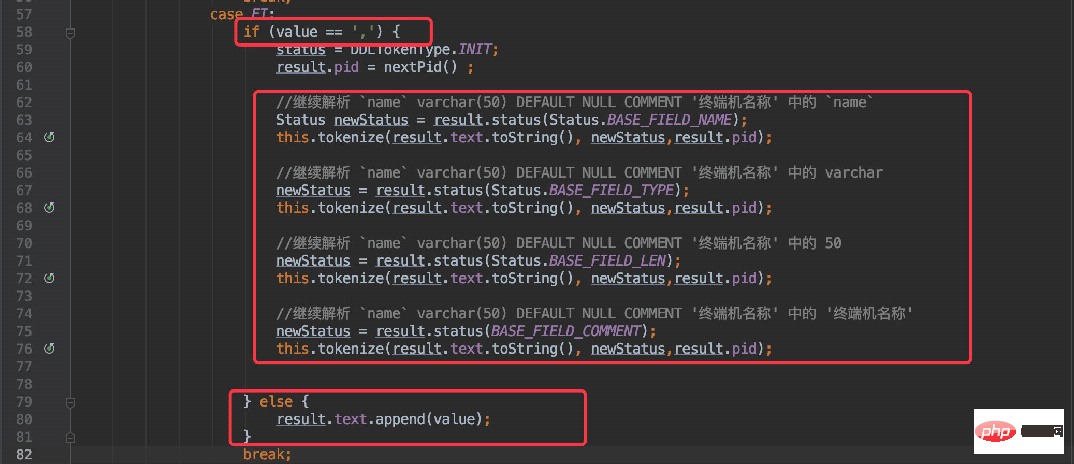
可以理解为将这一段字符串单独提取出来处理:
`userName` varchar(20) DEFAULT NULL COMMENT '用户名',
接着再将这段字符递归调用当前方法再次进行解析,这时便按照字段名称、类型、长度、注释的规则解析即可。
同时既然存在递归,还需要将子递归的数据关联起来,所以我在返回结果中新增了一个pid的字段,这个也容易理解。
默认值为 0,一旦递归后便自增 +1,保证每次递归的数据都是唯一的。
用同样的方法在解析主键时也是先将整个字符串提取出来:
PRIMARY KEY (`id`)
只不过是 “P” 打头 “)” 结尾。
} else if (value == 'P' && pStatus == Status.BASE_INIT) {
result.tokenType = DDLTokenType.P_K;
result.text.append(value);
}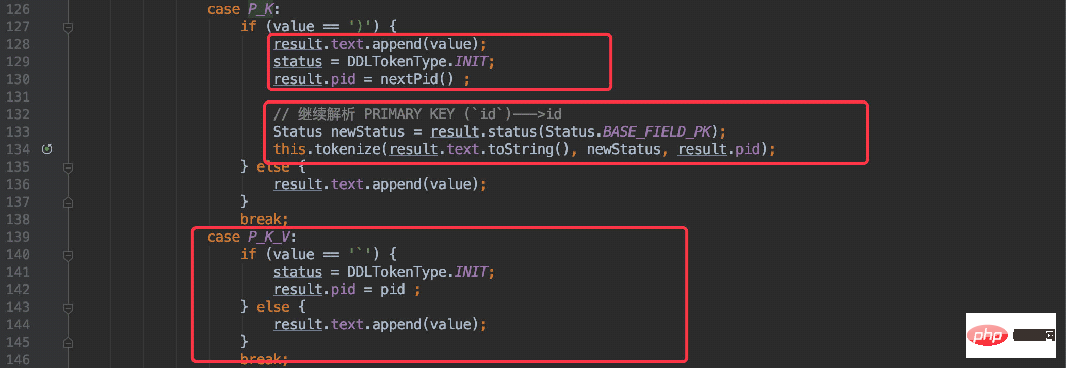
也是将整段字符串递归解析,再递归的过程中进行状态切换P_K ---> P_K_V最终获取到主键。
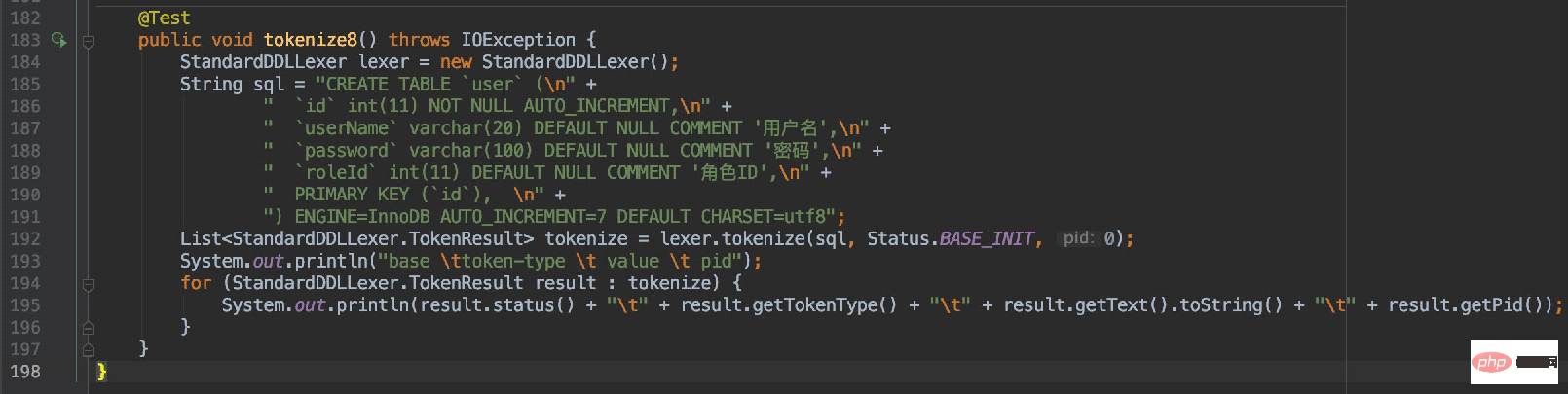
所以通过对刚才那段DDL解析得到的结果如下:
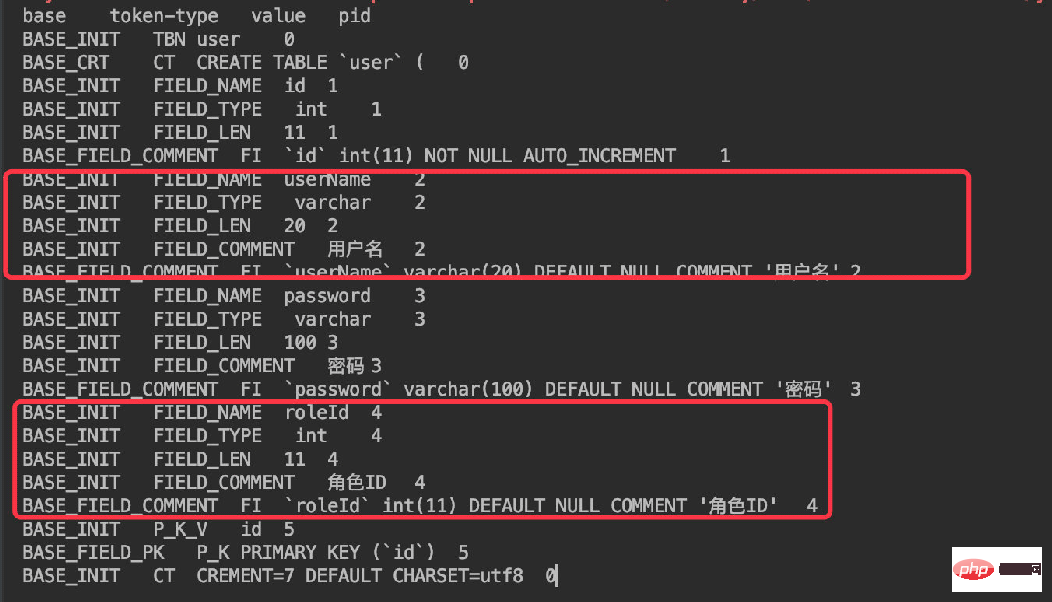
这样每个字段也通过了pid进行了区分关联。
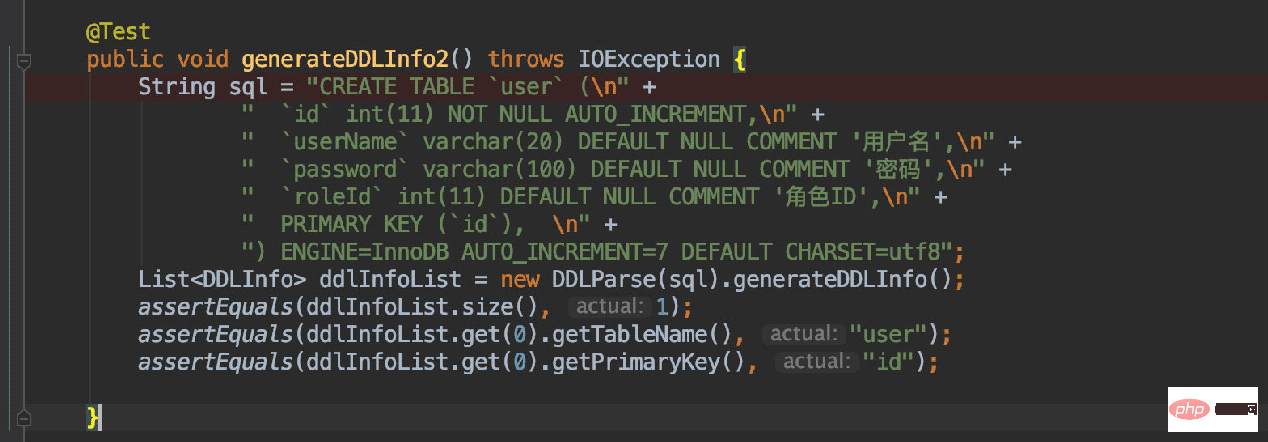
所以现在只需要对这个词法解析器进行封装,便可以提供一个简单的API来获取表中的数据了。
推荐学习:《java视频教程》
以上がJava字句解析DDL再帰アプリケーションの詳細な分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。