
ホームページ >データベース >mysql チュートリアル >MySQL の join ステートメント アルゴリズムの深い理解 (最適化手法の紹介)
MySQL の join ステートメント アルゴリズムの深い理解 (最適化手法の紹介)

- 青灯夜游転載
- 2022-07-07 10:50:482218ブラウズ
この記事では、MySQL の join ステートメントのアルゴリズムを深く理解し、join ステートメントの最適化方法について説明します。

1. 結合ステートメントのアルゴリズム
2 つのテーブル t1 と t2 を作成します
CREATE TABLE `t2` ( `id` int(11) NOT NULL, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `a` (`a`) ) ENGINE=InnoDB; CREATE DEFINER=`root`@`%` PROCEDURE `idata`() BEGIN declare i int; set i=1; while(i<p>両方のテーブルに主キーのインデックス ID とインデックスがありますa、フィールドにインデックスがありません b。ストアド プロシージャ idata() は、テーブル t2 に 1000 行のデータを挿入し、テーブル t1</p><h3><strong>1 に 100 行のデータを挿入します。インデックス ネストループ結合</strong></h3><pre class="brush:php;toolbar:false">select * from t1 straight_join t2 on (t1.a=t2.a);
If join ステートメントを直接使用すると、MySQL オプティマイザは駆動テーブルとしてテーブル t1 または t2 を選択し、MySQL に固定接続メソッドを使用させて、straight_join を通じてクエリを実行します。このステートメントでは、t1 が駆動テーブルで、t2 が駆動テーブルです。 table 
駆動テーブル t2 のフィールド a にはインデックスがあり、結合プロセスではこのインデックスが使用されるため、このステートメントの実行フローは次のとおりです:
1. 読み取りテーブル t1 のデータ R
2 の行 データ行 R から a フィールドを取り出し、テーブル t2
3 を検索します。テーブル t2 を実行し、結果として R を含む行を形成します。セットの一部です
4。テーブル t1
の最後でループが終了するまで、手順 1 ~ 3 を繰り返します。このプロセスではインデックスを使用できます。 Index Nested-Loop Join と呼ばれるドリブン テーブルの、NLJ と省略されます

このプロセス:
1. ドライバーのフル テーブル スキャンを実行します。テーブル t1。このプロセスには 100 行のスキャンが必要です。
2. R の各行について、ツリー検索プロセスを使用して、a フィールドに基づいてテーブル t2 を検索します。構築するデータは 1 対 1 に対応しているため、各検索プロセスでスキャンされるのは 1 行だけであり、合計 100 行がスキャンされます (
3)。実行プロセス全体は 200
結合が使用されていないと仮定すると、単一のテーブル クエリのみを使用できます:
1. select * from t1 を実行してすべてを検索します。テーブル t1 のデータ。ここには 100 行あります
2. これらの 100 行のデータをループします:
- 各行からフィールド a の値を取得します R $R.a
- Execute
select * from t2 where a= $R.a - 返された結果と R を組み合わせて結果セットの行を形成します
Thisクエリ プロセスも 200 行をスキャンしましたが、合計 101 ステートメントが実行されました。直接結合と比較すると、100 のインタラクションが追加されます。また、クライアントは SQL ステートメントと結果を独自に結合する必要があります。これは、直接結合する場合ほど優れたものではありません。
駆動テーブルのインデックスが使用できる場合:
- 結合ステートメントを使用する強制するよりもパフォーマンスが優れています SQL ステートメントを実行するために複数の単一テーブルに分割するパフォーマンスが優れています
- join ステートメントを使用する場合は、小さなテーブルを駆動テーブルにする必要があります
2. 単純なネストループ結合
select * from t1 straight_join t2 on (t1.a=t2.b);
テーブル t2 のフィールド b にはインデックスがないため、t2 が照合に使用されるたびにテーブル全体のスキャンを実行する必要があります。このアルゴリズムは単純なネストループ結合と呼ばれます。
このように計算すると、この SQL リクエストはテーブル t2 を最大 100 回スキャンし、合計 100*100=100,000 行をスキャンします。
MySQL はこの単純なネストループ結合アルゴリズムは使用せず、BNL
3、ブロックネストループ結合
と呼ばれる別のアルゴリズムを使用します。駆動テーブルには使用可能なインデックスがありません。アルゴリズム フローは次のとおりです:
1. テーブル t1 のデータをスレッド メモリの join_buffer に読み取ります。このステートメントは select * で書かれているため、テーブル t1 全体がメモリに入れます
2. テーブル t2 をスキャンし、テーブル t2 の各行を取り出し、join_buffer 内のデータと比較します。結合条件が満たされている場合、そのデータは、結果セット
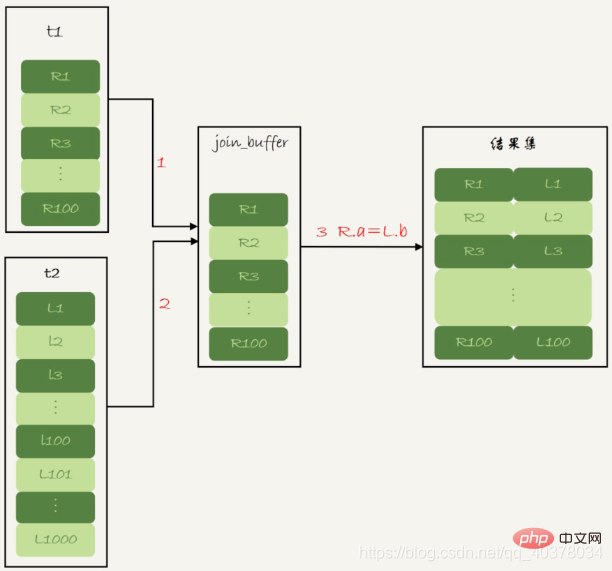

このプロセスでは、テーブル t1 とテーブル t2 の両方でテーブル全体のスキャンが実行されるため、スキャンされた合計数は行数は1100です。 join_buffer は順序付けされていない配列で構成されているため、テーブル t2 の各行に対して 100 回の判定を行う必要があり、メモリ上で必要な判定の合計回数は 100*1000=100,000 回です
クエリには Simple Nested Loop Join アルゴリズムが使用され、スキャンされる行数も 100,000 です。したがって、時間計算量の点では、これら 2 つのアルゴリズムは同じです。ただし、ブロック ネスト ループ結合アルゴリズムの 100,000 件の判定はメモリ操作であるため、はるかに高速でパフォーマンスが向上します。小さなテーブルの行数が N、大きなテーブルの行数が M であると仮定します。
1) 両方のテーブルでフル テーブル スキャンが実行されるため、スキャンされる行の総数は M N
2) メモリ内の判定の数は M ∗ N
このとき、ドライバーテーブルとして大きなテーブルを選択しても小さなテーブルを選択しても、実行時間は同じです。
join_buffer のサイズはパラメータ join_buffer_size で設定され、デフォルト値は 256k です。すべてのデータをテーブル t1 に入れることができない場合、戦略は非常に単純です。つまり、データをセグメントに入れるということです。
1)扫描表t1,顺序读取数据行放入join_buffer中,假设放到第88行join_buffer满了
2)扫描表t2,把t2中的每一行取出来,跟join_buffer中的数据做对比,满足join条件的,作为结果集的一部分返回
3)清空join_buffer
4)继续扫描表t1,顺序读取最后的12行放入join_buffer中,继续执行第2步
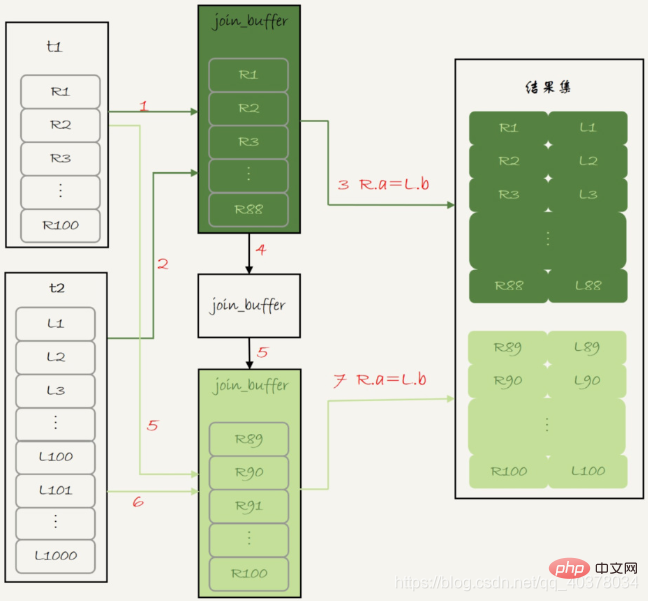
由于表t1被分成了两次放入join_buffer中,导致表t2会被扫描两次。虽然分成两次放入join_buffer,但是判断等值条件的此时还是不变的
假设,驱动表的数据行数是N,需要分成K段才能完成算法流程,被驱动表的数据行数是M 。这里的K不是常数,N越大K 就会越大,因此把K表示为λ ∗ N ,λ的取值范围是(0,1)。所以,在这个算法的执行过程中:
1.扫描行数是N + λ ∗ N ∗ M
2.内存判断N ∗ M
考虑到扫描行数,N 小一些,整个算式的结果会更小。所以应该让小表当驱动表
4、能不能使用join语句?
1.如果可以使用Index Nested-Loop Join算法,也就是说可以用上被驱动表上的索引,其实是没问题的
2.如果使用Block Nested-Loop Join算法,扫描行数就会过多。尤其是在大表上的join操作,这样可能要扫描被驱动表很多次,会占用大量的系统资源。所以这种join尽量不要用
5、如果使用join,应该选择大表做驱动表还是选择小表做驱动表
1.如果是Index Nested-Loop Join算法,应该选择小表做驱动表
2.如果是Block Nested-Loop Join算法:
- 在join_buffer_size足够大的时候,是一样的
- 在join_buffer_size不够大的时候,应该选择小表做驱动表
在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成以后,计算参数join的各个字段的总数据量,数据量小的那个表,就是小表,应该作为驱动表
二、join语句优化
创建两个表t1、t2
create table t1(id int primary key, a int, b int, index(a));
create table t2 like t1;
CREATE DEFINER = CURRENT_USER PROCEDURE `idata`()
BEGIN
declare i int;
set i=1;
while(i<=1000)do
insert into t1 values(i, 1001-i, i);
set i=i+1;
end while;
set i=1;
while(i<=1000000)do
insert into t2 values(i, i, i);
set i=i+1;
end while;
END;在表t1中,插入了1000行数据,每一行的a=1001-id的值。也就是说,表t1中字段a是逆序的。同时,在表t2中插入了100万行数据
1、Multi-Range Read优化
Multi-Range Read(MRR)优化主要的目的是尽量使用顺序读盘
select * from t1 where a>=1 and a<p>主键索引是一棵B+树,在这棵树上,每次只能根据一个主键id查到一行数据。因此,回表是一行行搜索主键索引的</p><p><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/024/5c16d719738fb23caf97d38d00c1644b-5.png" class="lazy" alt="MySQL の join ステートメント アルゴリズムの深い理解 (最適化手法の紹介)"></p><p>如果随着a的值递增顺序查找的话,id的值就变成随机的,那么就会出现随机访问,性能相对较差</p><p><strong>因为大多数的数据都是按照主键递增顺序插入得到的,所以如果按照主键的递增顺序查询,对磁盘的读比较接近顺序读,能够提升读性能</strong></p><p>这就是MRR优化的设计思路,语句的执行流程如下:</p><p>1.根据索引a,定位到满足条件的记录,将id值放入read_rnd_buffer中</p><p>2.将read_rnd_buffer中的id进行递增排序</p><p>3.排序后的id数组,依次到主键id索引中查记录,并作为结果返回</p><p>read_rnd_buffer的大小是由read_rnd_buffer_size参数控制的。如果步骤1中,read_rnd_buffer放满了,就会先执行完步骤2和3,然后清空read_rnd_buffer。之后继续找索引a的下个记录,并继续循环</p><p>如果想要稳定地使用MRR优化的话,需要设置<code>set optimizer_switch="mrr_cost_based=off"</code></p><p><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/024/5c16d719738fb23caf97d38d00c1644b-6.png" class="lazy" alt="MySQL の join ステートメント アルゴリズムの深い理解 (最適化手法の紹介)"></p><p><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/024/3833cfce76c7a34447aff9e3973bd58a-7.png" class="lazy" alt="MySQL の join ステートメント アルゴリズムの深い理解 (最適化手法の紹介)"><br> explain结果中,Extra字段多了Using MRR,表示的是用上了MRR优化。由于在read_rnd_buffer中按照id做了排序,所以最后得到的结果也是按照主键id递增顺序的</p><p><strong>MRR能够提升性能的核心在于,这条查询语句在索引a上做的是一个范围查询,可以得到足够多的主键id。这样通过排序以后,再去主键索引查数据,才能体现出顺序性的优势</strong></p><h3><strong>2、Batched Key Access</strong></h3><p>MySQL5.6引入了Batched Key Access(BKA)算法。这个BKA算法是对NLJ算法的优化</p><p>NLJ算法流程图:</p><p><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/024/3833cfce76c7a34447aff9e3973bd58a-8.png" class="lazy" alt="MySQL の join ステートメント アルゴリズムの深い理解 (最適化手法の紹介)"></p><p>NLJ算法执行的逻辑是从驱动表t1,一行行地取出a的值,再到被驱动表t2去做join</p><p>BKA算法流程图:</p><p><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/024/3833cfce76c7a34447aff9e3973bd58a-9.png" class="lazy" alt="MySQL の join ステートメント アルゴリズムの深い理解 (最適化手法の紹介)"></p><p>BKA算法执行的逻辑是把表t1的数据取出来一部分,先放到一个join_buffer,一起传给表t2。在join_buffer中只会放入查询需要的字段,如果join_buffer放不下所有数据,就会将数据分成多段执行上图的流程</p><p>如果想要使用BKA优化算法的话,执行SQL语句之前,先设置</p><pre class="brush:php;toolbar:false">set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
其中前两个参数的作用是启用MRR,原因是BKA算法的优化要依赖与MRR
3、BNL算法的性能问题
InnoDB对Buffer Pool的LRU算法做了优化,即:第一次从磁盘读入内存的数据页,会先放在old区域。如果1秒之后这个数据页不再被访问了,就不会被移动到LRU链表头部,这样对Buffer Pool的命中率影响就不大
如果一个使用BNL算法的join语句,多次扫描一个冷表,而且这个语句执行时间超过1秒,就会在再次扫描冷表的时候,把冷表的数据页移到LRU链表头部。这种情况对应的,是冷表的数据量小于整个Buffer Pool的3/8,能够完全放入old区域的情况
如果这个冷表很大,就会出现另外一种情况:业务正常访问的数据页,没有机会进入young区域。
由于优化机制的存在,一个正常访问的数据页,要进入young区域,需要隔1秒后再次被访问到。但是,由于join语句在循环读磁盘和淘汰内存页,进入old区域的数据页,很可能在1秒之内就被淘汰了。这样就会导致MySQL实例的Buffer Pool在这段时间内,young区域的数据页没有被合理地淘汰
BNL算法对系统的影响主要包括三个方面:
1.可能会多次扫描被驱动表,占用磁盘IO资源
2.判断join条件需要执行M∗N次对比,如果是大表就会占用非常多的CPU资源
3.可能会导致Buffer Pool的热数据被淘汰,影响内存命中率
4、BNL转BKA
一些情况下,我们可以直接在被驱动表上建索引,这时就可以直接转成BKA算法了
如果碰到一些不适合在被驱动表上建索引的情况,可以考虑使用临时表。大致思路如下:
select * from t1 join t2 on (t1.b=t2.b) where t2.b>=1 and t2.b<p>1)把表t2中满足条件的数据放在临时表tmp_t中</p><p>2)为了让join使用BKA算法,给临时表tmp_t的字段b加上索引</p><p>3)让表t1和tmp_t做join操作</p><p>SQL语句写法如下:</p><pre class="brush:php;toolbar:false">create temporary table temp_t(id int primary key, a int, b int, index(b))engine=innodb;insert into temp_t select * from t2 where b>=1 and b<h3><strong>5、扩展hash join</strong></h3><p>MySQL的优化器和执行器不支持哈希join,可以自己实现在业务端,实现流程大致如下:</p><p>1.<code>select * from t1;</code>取得表t1的全部1000行数据,在业务端存入一个hash结构</p><p>2.<code>select * from t2 where b>=1 and b获取表t2中满足条件的2000行数据</code></p><p>3.把这2000行数据,一行一行地取到业务端,到hash结构的数据表中寻找匹配的数据。满足匹配的条件的这行数据,就作为结果集的一行</p><p>【相关推荐:<a href="https://www.php.cn/course/list/51.html" target="_blank" textvalue="mysql视频教程">mysql视频教程</a>】</p>
以上がMySQL の join ステートメント アルゴリズムの深い理解 (最適化手法の紹介)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。